5주차 진도🐥
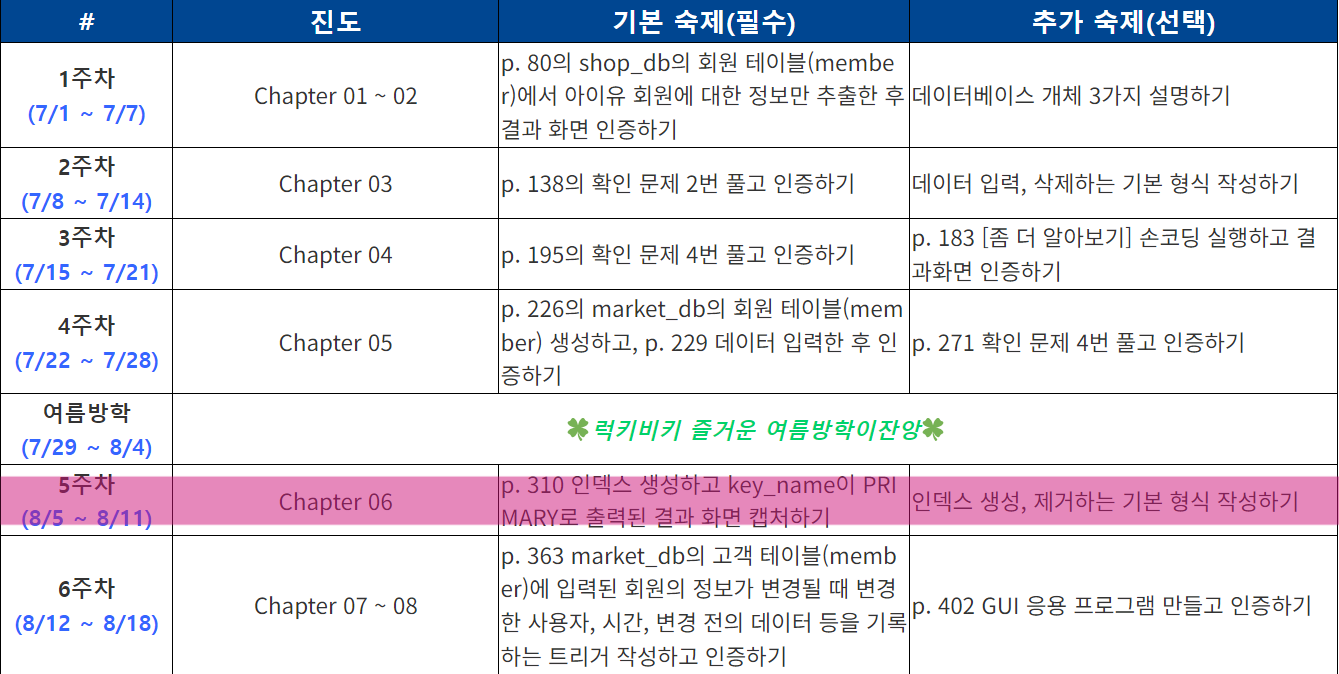
✨ 기본미션
P.301쪽 인덱스 생성하고 key_name이 primary 출력화면 캡처

✨ 추가미션
- 인덱스 생성 형식
CREATE [유니크] INDEX 인덱스 이름
ON 테이블 이름 (열이름) [오름차순|내림차순] - 인덱스 제거 헝식
DROP INDEX 인덱스 이름 ON 테이블 이름
📚공부
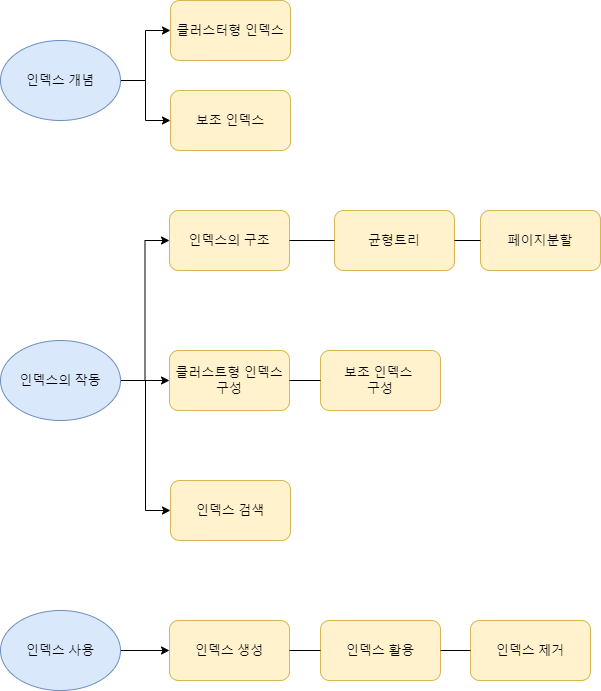
06-1 인덱스 개념을 파악하자
인덱스
- 데이터를 빠르게 찾을수 있게 도와주는 도구
인덱스 장점과 단점
| 장점 | 단점 |
|---|---|
| SELECT문 검색 속도가 빠름 | 인덱스가 공간을 차지함(테이블 크기의 10%) |
| → 전체시스템 성능이 향상됨 | 처음 인덱스를 만들때 시간이 오래걸림 |
| INSERT, UPDATE, DELETE 작업을 자주하면 성능이 나빠짐 |
인덱스 종류
- 클러스터형 인덱스(CLUSTERED INDEX)
- 알파벳순으로 정리 예)영어사전
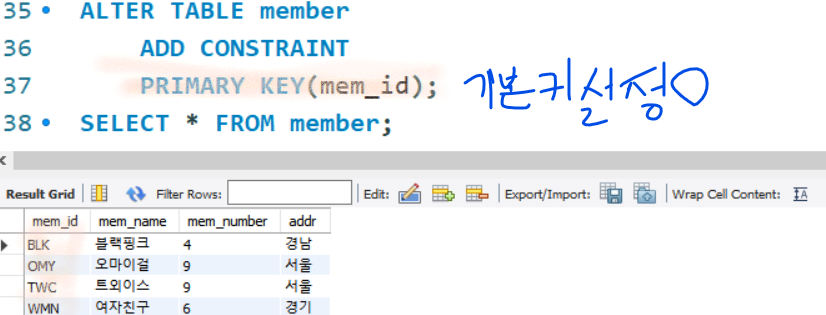
- 기본키로 만들면 자동으로 지정되는 인덱스 → 테이블에 한개만 만들수 있음
- 열을 기본키로 지정하면 열을 기준으로 자동정렬됨
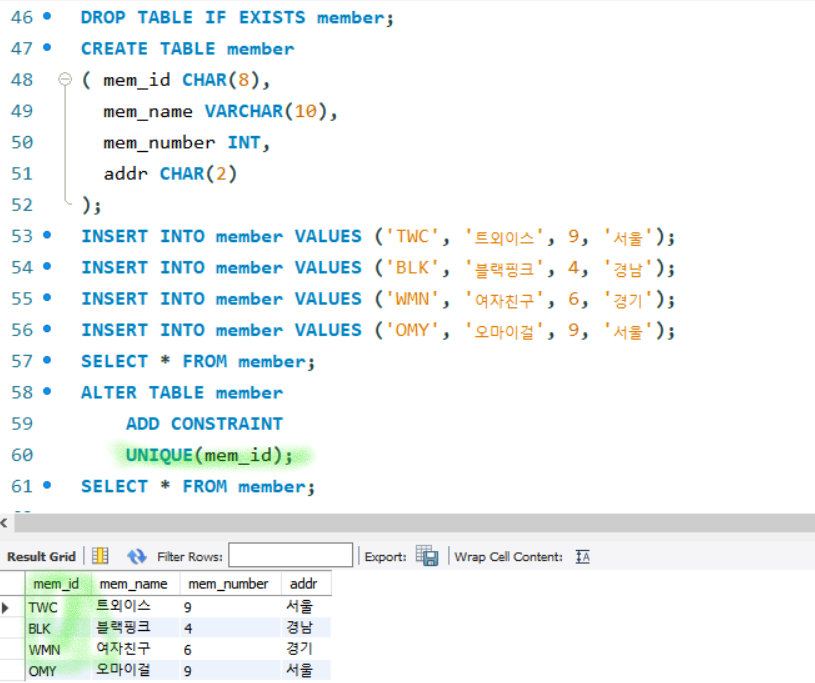
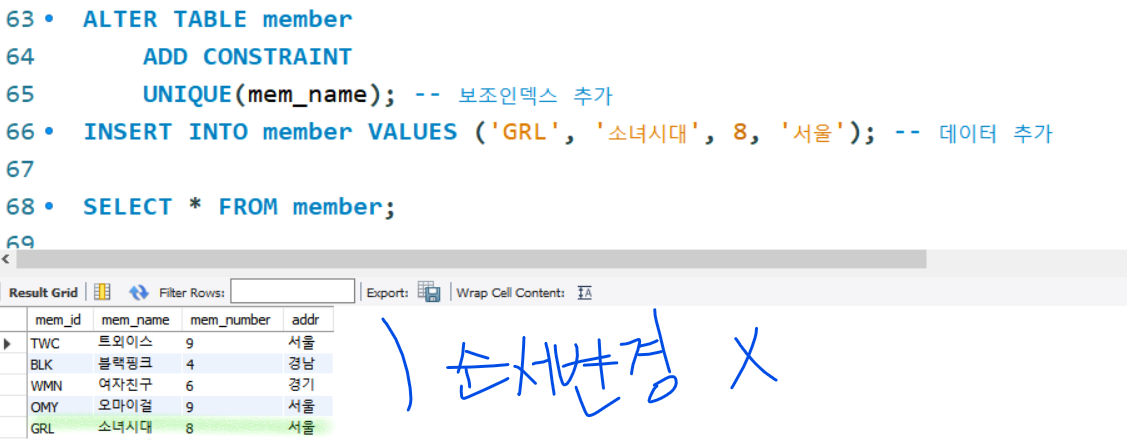
- 보조 인덱스(SENCONDARY INDEX)
- 찾아보기로 검색 예)책의 찾아보기
- 고유키로 테이블에 여러개 지정할수 있음
- 보조인덱스를 생성해도 데이터 순서 변화가 없음
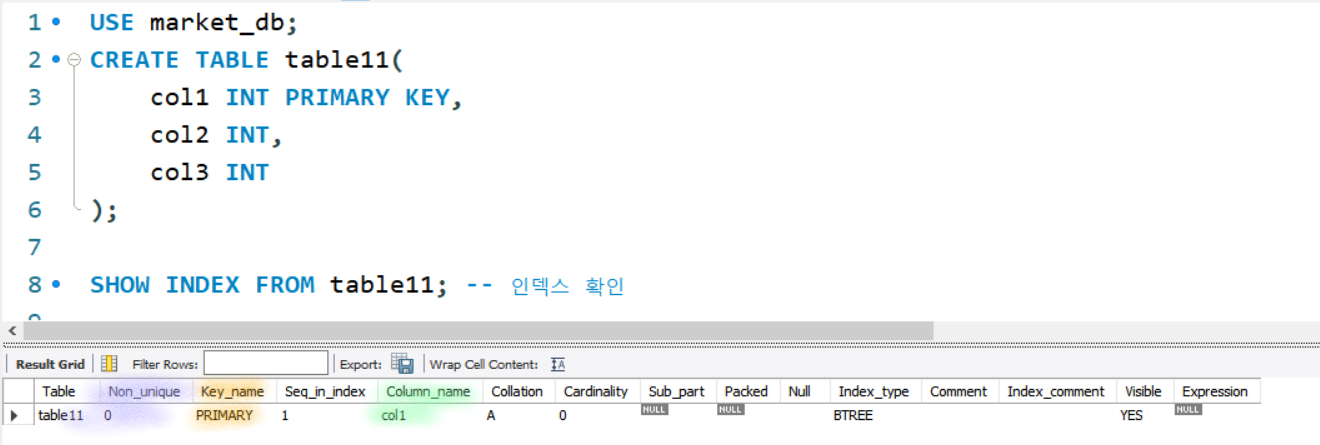
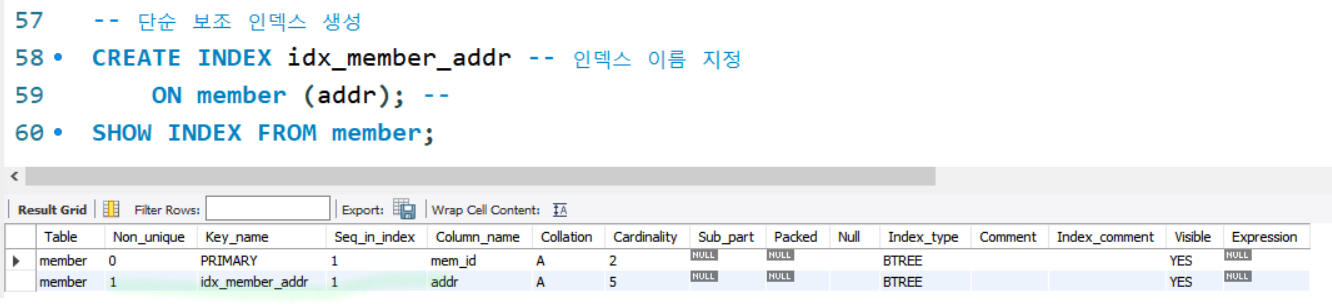
인덱스 생성
-
하나의 열에 하나의 인덱스를 생성함
-
key_name의 PRIMARY: 자동생성된 인덱스, 클러스터형 인덱스
-
Non_unique : 중복이 허용되는가? / 0은 false, 1은 true
-
key_name의 UNIQUE: 고유키로 생성되는 인덱스는 보조인덱스
-
key_name의 열이름 : 보조인덱스
-
-
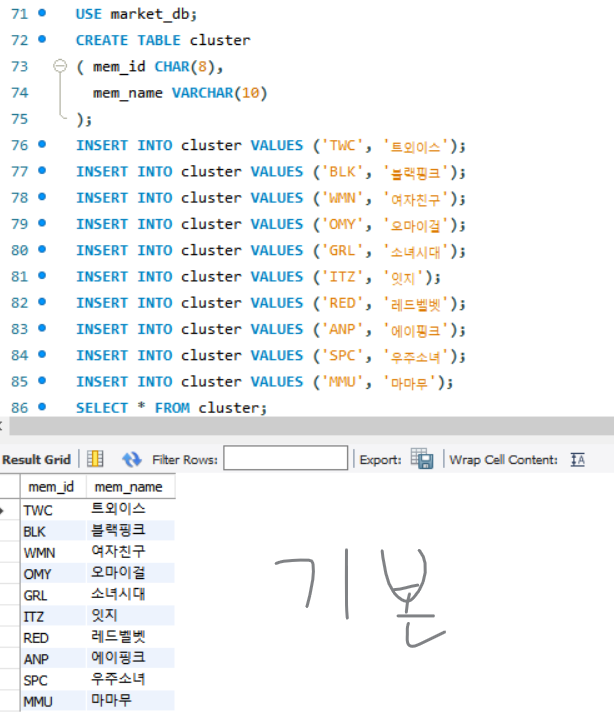
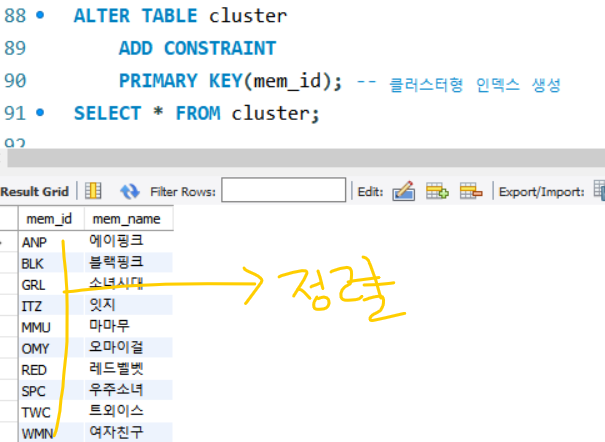
클러스터형 인덱스 생성
- 클러스터형 인덱스 변경
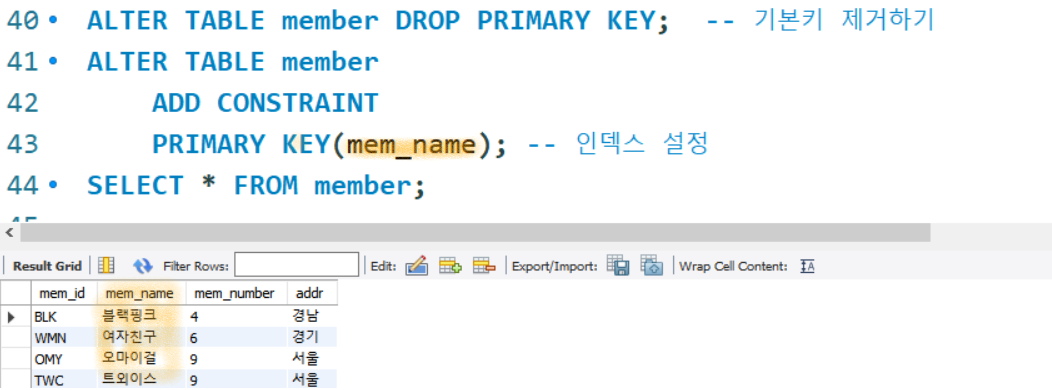
- 클러스터형 인덱스 변경
-
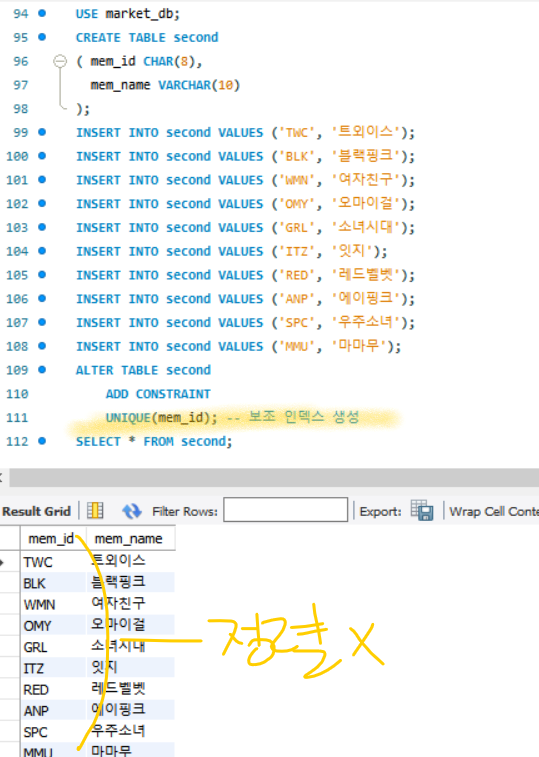
보조 인덱스 생성
06-2 인덱스 내부작동
균형트리
- 인덱스는 균형트리 형식으로 되어있음
- 균형트리는 루트-중간-리프로 구성된 데이터 구조
- 노드(NODE) : 데이터가 저장되는 공간
- 루트노드 : 상위 노드, 모든 노드들의 출발점
- 중간노드 : 루트노드와 리프노드 가운데 있는것
- 리프노드 : 가장 마지막 노드
- MySQL 페이지 = 노드
- 최소한은 저장단위(16Kbyte)
- 1건 데이터입력 하는데 1페이지가 필요한
- 루트 페이지/리프 페이지
- 균형트리 검색
- 루트페이지 부터 검색함
- 균형트리 사용시
- 데이터 검색(SELECT) → 속도가 향상됨
- 데이터 변경작업(INSERT, UPDATE, DELETE) → 페이지 분할로 성능이 나빠짐
클러스터형 인덱스 구성하기
- 클러스터형 인덱스 : 루트페이지, 리프페이지로 구성됨
- 인덱스 페이지의 리프페이지 = 데이터 자체
보조 인덱스 구성하기
- 보조인덱스는 데이터페이지를 만들지 않음
- 리프페이지에 "페이지번호+#위치"를 기록함
인덱스에서 검색하기
- 클러스터형 인덱스가 보조인덱스보다 빠름
06-3 인덱스 실제 사용
인덱스 생성
-
CREATE INDEX로는 보조인덱스를 생성함
CREATE [유니크] INDEX 인덱스 이름
ON 테이블 이름 (열이름) [오름차순|내림차순] -
DATA_LENGTH : 클러스트 인덱스의 크기. Byte단위
-
INDEX_LENGTH : 보조인덱스 크기

-
NON_UNIQUE : 1은 중복 허용 함. 0은 중복 허용 안함
-
ANALYZE TABLE : 보조인덱스 적용을 위해 테이블 분석을 해야함

-
CREATE UNIQUE INDEX ON : 고유보조 인덱스 생성. 중복없는 경우만 지정이 가능 but 현재 중복값이 없다고 지정하면 안됨
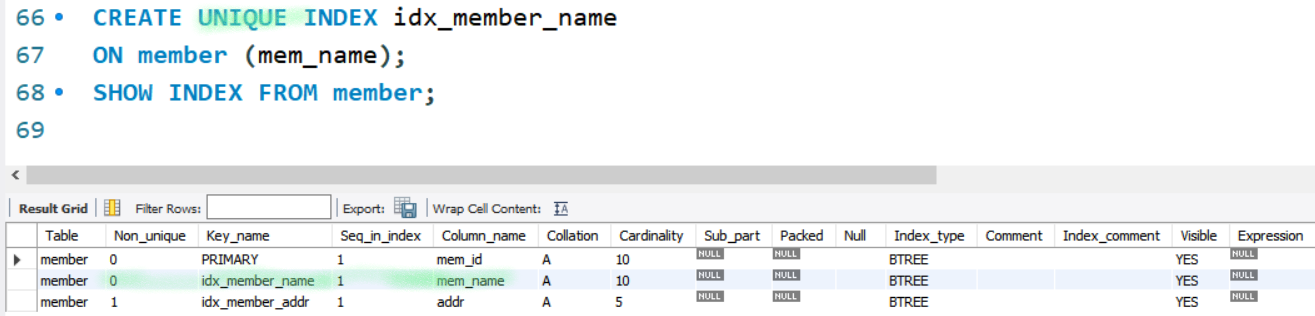
-
중복데이터가 많은 열에 인덱스를 생성하는것은 성능만 나빠지게 함
인덱스 활용
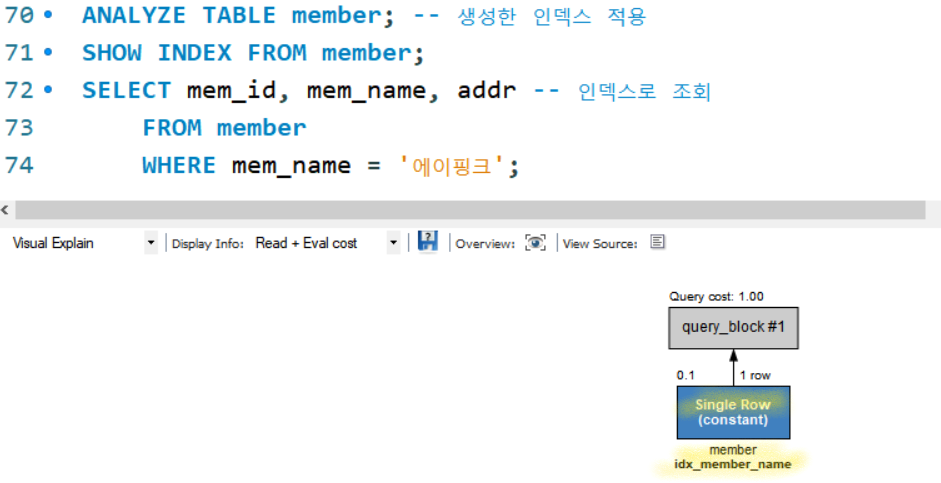
- single row / index range scan: 인덱스로 결과를 얻었다는 의미
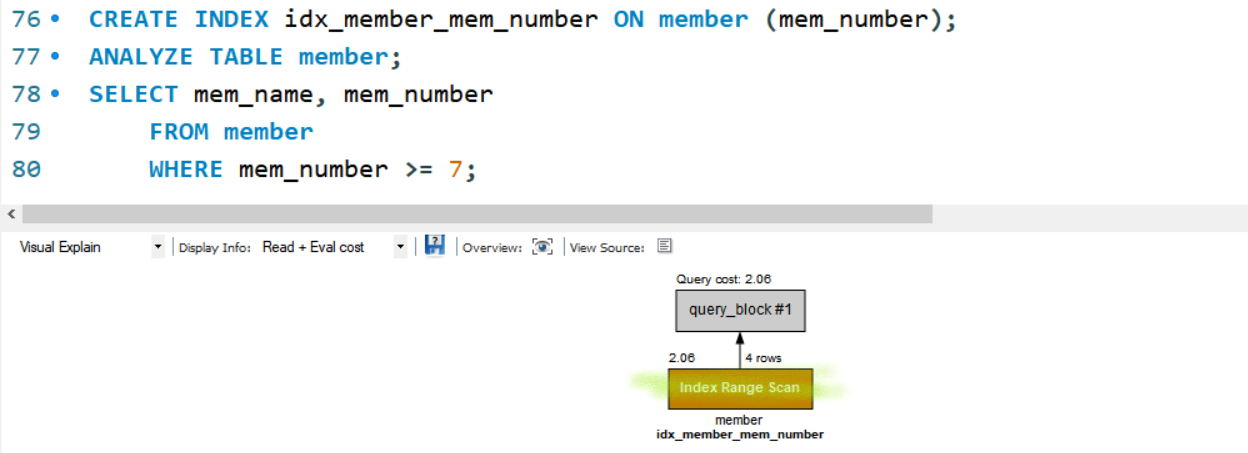
- full table scan : 인덱스가 있어도 인덱스보다 전체 검색이 낫다고 MySQL이 판단할 경우 전체를 검색함
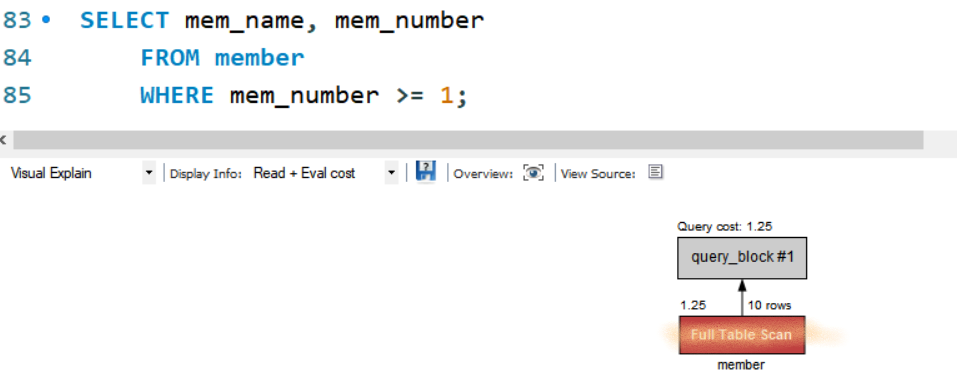 ]
] - WHERE문 연산이 있을경우 인덱스를 사용하지 않음
인덱스 제거
-
기본키, 고유키로 생성된 인덱스는 "DROP INDEX"로 제거 못함 → ALTER TABLE문으로 제거해야함
DROP INDEX 인덱스 이름 ON 테이블 이름
-
제거 순서 : 보조 인덱스 제거 → 클러스터형 인덱스 제거

