
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
(Karen Simonyan∗ & Andrew Zisserman+Visual Geometry Group, Department of Engineering Science, University of Oxford)
ILSVRC 2014년 대회에서 2등을 차지한 모델로, 모델의 깊이가 성능에 어떤 영향을 미치는지 보여준다. VGG 이전의 모델들은 8 layers정도의 깊이였던 반면, VGGNet은 이보다 훨씬 깊은 16 layers를 이용하여 깊이가 깊어질수록 모델의 성능이 향상되는 것을 확인할 수 있다. (하지만 무작정 모델을 깊게 만드는 것이 성능 향상을 보장하는 것은 아니다!)
Architecture
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3 × 3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16–19 weight layers.
The convolution stride is fixed to 1 pixel; the spatial padding of conv. layer input is such that the spatial resolution is preserved after convolution, i.e. the padding is 1 pixel for 3 × 3 conv. layers. Spatial pooling is carried out by five max-pooling layers, which follow some of the conv. layers (not all the conv. layers are followed by max-pooling). Max-pooling is performed over a 2 × 2 pixel window, with stride 2.
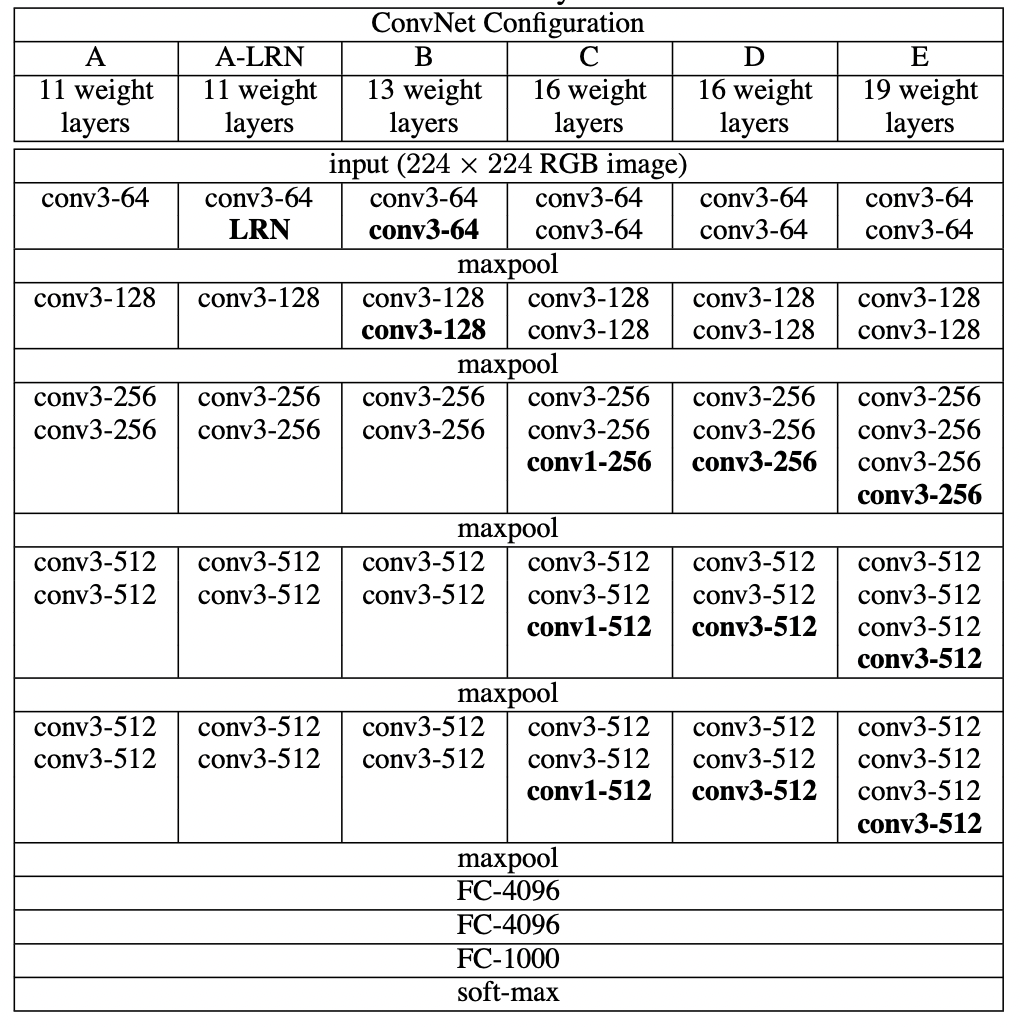
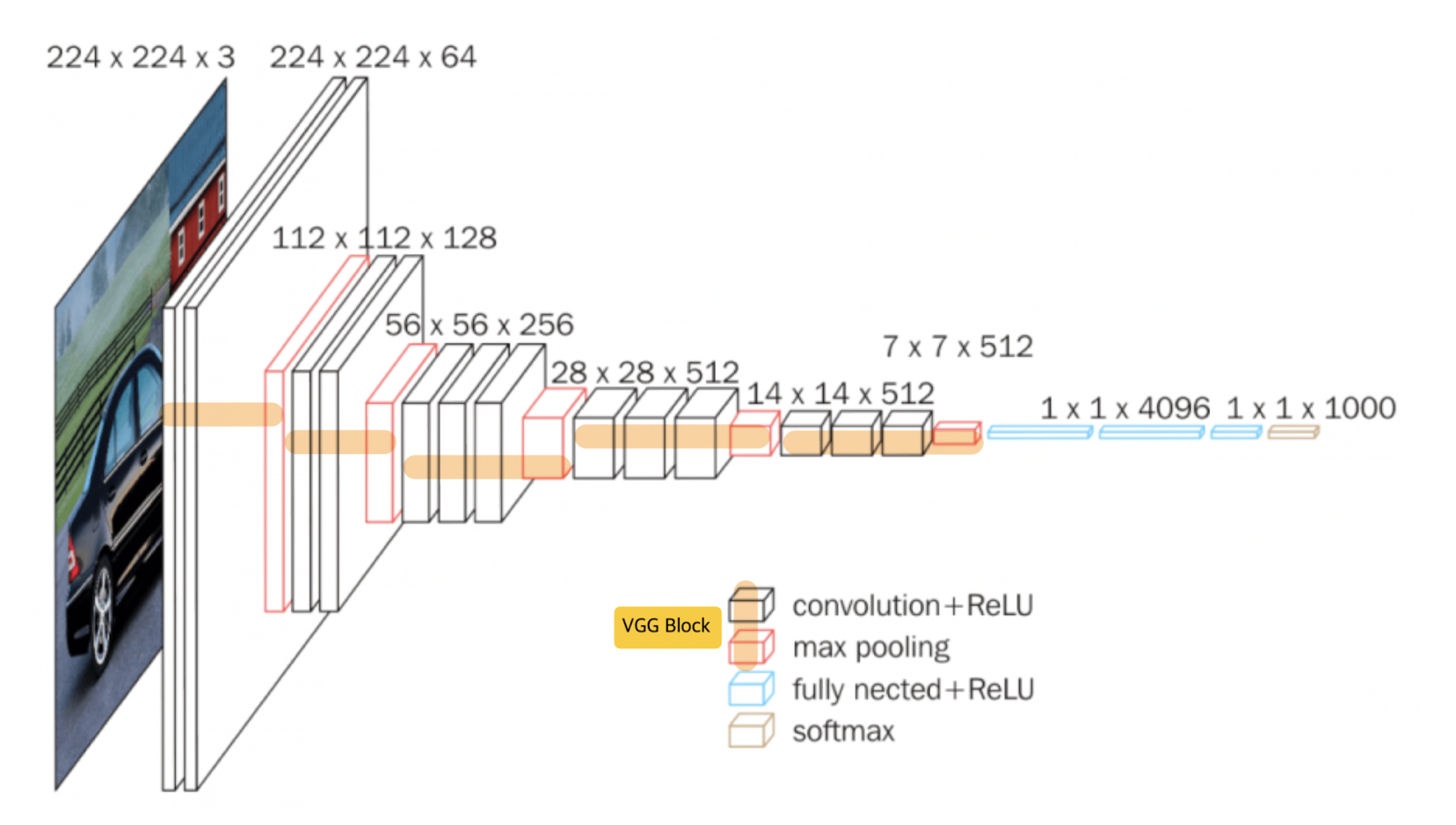
- input image 크기 = 224*224
- 13 convolution layers + 3 fc layers (VGG16)
- 3*3 크기의 convolution filters
- ReLU activation function
- 2*2 max pooling
- max pooling을 한 번 진행할 때마다 image의 크기가 1/2으로 감소 - VGG block = convolution layers + max pooling
- VGG block에서는 '1) 몇 개의 conv layers를 사용할지, 2) filter를 몇 개 사용할지' 결정
VGGNet의 핵심
Receptive field
: 출력 layer의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
-convolution layer를 사용 할수록 1 pixel이 가지고 포함하고 있는 원본 이미지의 범위가 커짐.
- 첫 번째 3*3 conv layer
1 pixel이 원본 이미지의 3*3 pixel의 정보를 가지고 있음 - 두 번째 3*3 conv layer
1 pixel이 원본 이미지의 layerdml 5*5 정보를 가지고 있음 - 세 번째 3*3 conv layer
1 pixel이 원본 이미지의 layerdml 7*7 정보를 가지고 있음
7 *7 filter 1개 vs 3*3 filter 3개
- 각각의 convolution 연산이 수행될 때마다 ReLU 함수가 적용된다.
비선형성 증가 - 학습 파라미터의 수 감소
7*7 filter 1개 적용 시, 학습 파라미터의 수는 49개인 반면, 3*3 filter 3개 적용 시 필요한 학습 파라미터의 수는 27개이다.
실습 코드 자료
https://www.youtube.com/watch?v=ACmuBbuXn20
