
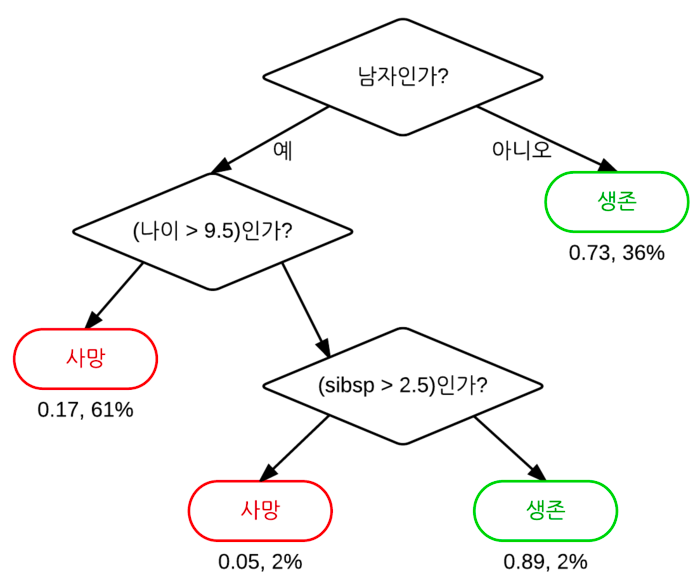
의사결정트리는 일련의 분류 규칙을 통해 데이터를 분류, 회귀하는 지도학습 모델 중 하나이다. 특정기준(질문)에 따라 데이터를 구분하는 모델이다. 스무고개를
결정트리에서 질문이나 정답을 노드(Node)라고 부르고 맨 처음 분류 기준을 Root Node라고 하고, 중간 분류 기준을 Intermediate Node라고 하고, 맨 마지막 노드를 Terminal Node 혹은 Leaf Node라고 한다.
프로세스

데이터를 구분할 수 있는 질문을 기준으로 나눈다.

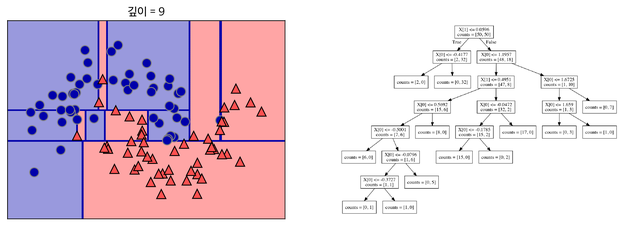
또다시 질문으로 기준을 나눈다. 이것을 지나치게 많이하면 아래처럼 오버피팅이 된다. 결정트리에 아무 파라미터를 주지 않고 모델링하면 오버피팅이 된다.
가지치기(Pruning)
오버피팅을 막기 위해 가지치기(Pruning)라는 기법을 사용함. 최대 깊이나 터미널 노드의 최대 개수 혹은 한 노드가 분할하기 위한 최소 데이터 수를 제한하는 것.
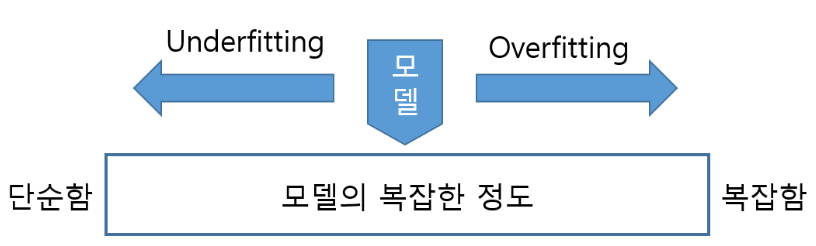
Overfitting(과학습)
모델의 파라미터들을 학습 데이터에 너무 가깝게 맞췄을 때 발생하는 현상이다. -> 불필요한 잡음, 데이터를 과도하게 모델에 반영한 상태
Underfitting
학습 데이터가 모자라거나 학습이 제대로 이루어지지 않아서, 트레이닝 데이터에 가깝게 가지 못한 경우 -> 필요한 데이터를 충분히 모델에 반영하지 못한 상태
코드구현
from sklearn.tree import DecisionTreeClassifier # sklearn에서 DecisionTree 모델을 불러옴
from sklearn.datasets import load_breast_cancer # sklearn에서 dataset을 불러옴.
# -> 유방암 데이터를 불러옴
from sklearn.model_selection import train_test_split # sklearn에서 train_test_split -> train set, test set을 분리 할 수 있음
cancer = load_breast_cancer() # cancer 변수에 불러온 유방암 데이터를 저장함데이터를 train셋, test셋으로 분리하는 이유 : 머신러닝 모델에 train 데이터를 100% 학습시킨 후 test 데이터에 모델을 적용했을 때 성능이 생각보다 안나옴(Overfitting), Overfitting을 방지하는 것은 전체적인 모델 성능을 따져보았을 때 매우 중요한 프로세스 중 하나임.
Validation 셋으로 학습한 모델을 평가함
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify = cancer.target, random_state = 42
) # train셋, test셋으로 나눔. x는 독립변수, y는 종속변수가 된다.
# x_train은 train에서 독립변수, y_train은 train에서 종속변수가 된다.arrays : 분할시킬 데이터를 입력 (Python list, Numpy array, Pandas dataframe 등..)
test_size : 테스트 데이터셋의 비율(float)이나 갯수(int) (default = 0.25)
train_size : 학습 데이터셋의 비율(float)이나 갯수(int) (default = test_size의 나머지)
random_state : 데이터 분할시 셔플이 이루어지는데 이를 위한 시드값 (int나 RandomState로 입력)
shuffle : 셔플여부설정 (default = True)
stratify : 지정한 Data의 비율을 유지한다. 예를 들어, Label Set인 Y가 25%의 0과 75%의 1로 이루어진 Binary Set일 때, stratify=Y로 설정하면 나누어진 데이터셋들도 0과 1을 각각 25%, 75%로 유지한 채 분할된다.
tree = DecisionTreeClassifier(random_state = 0)
# random_state : 난수 seed 설정 (난수 : 정의된 범위내에서 무작위로 추출된 수, seed : 시작 숫자)
tree.fit(X_train,y_train)
print("훈련 세트 정확도 : {:.3f}".format(tree.score(X_train, y_train)))
print("테스트 세트 정확도 : {:.3f}".format(tree.score(X_test, y_test)))
# >> 훈련 세트 정확도 : 1.000
# >> 테스트 세트 정확도 : 0.937