
PyTorch란
- 간편한 딥러닝 API를 제공하며 머신러닝 알고리즘을 구현하고 실행하기 위한 확장성이 뛰어난 멀티플랫폼 프로그래밍 인터페이스
- GPU에서 텐서 조작 및 동적 신경망 구축이 가능한 프레임워크
- PyTorch는 파이썬의 넘파이 라이브러리처럼 과학 연산을 위한 라이브러리로 공개되었지만 이후 발전을 거듭하면서 딥러닝 프레임워크로 발전했다.
PyTorch의 특징
GPU
-
연산 속도를 빠르게 하는 GPU를 사용하여 빠른 계산이 가능하다.
-
내부적으로 CUDA, cuDNN이라는 API를 통해 GPU를 연산에 사용할 수 있다.
-
병렬 연산에서 GPU 속도는 CPU 속도보다 훨씬 빠르므로 딥러닝 학습에서 GPU 사용은 필수이다.
텐서
- PyTorch의 데이터 형태.
- 단일 데이터 형식으로 된 자료들의 다차원 행렬이다.
PyTorch의 장점
뛰어난 확장성
- 다양한 규모의 프로젝트에 적응할 수 있도록 작업량을 처리할 수 있는 능력이 좋음
단순함(효율적 계산)
- 파이썬 환경과 쉽게 통합 가능
- 디버깅이 직관적이고 간결함
성능(낮은 CPU 활용)
- 모델 훈련을 위한 CPU 사용률이 텐서플로와 비교하여 낮다.
- 학습 및 추론 속도가 빠르고 다루기 쉽다.
동적 계산 그래프

- PyTorch는 연산을 평가하고, 계산을 실행하고, 구체적인 값을 즉시 반환하는 명령형 프로그래밍 환경을 제공함(Raschka, Liu & Mirjalili, 2022)
- 이는 계산 그래프를 사전에 구성한 후 실행하는 TensorFlow 초기 버전과 차이가 있음
PyTorch 아키텍처
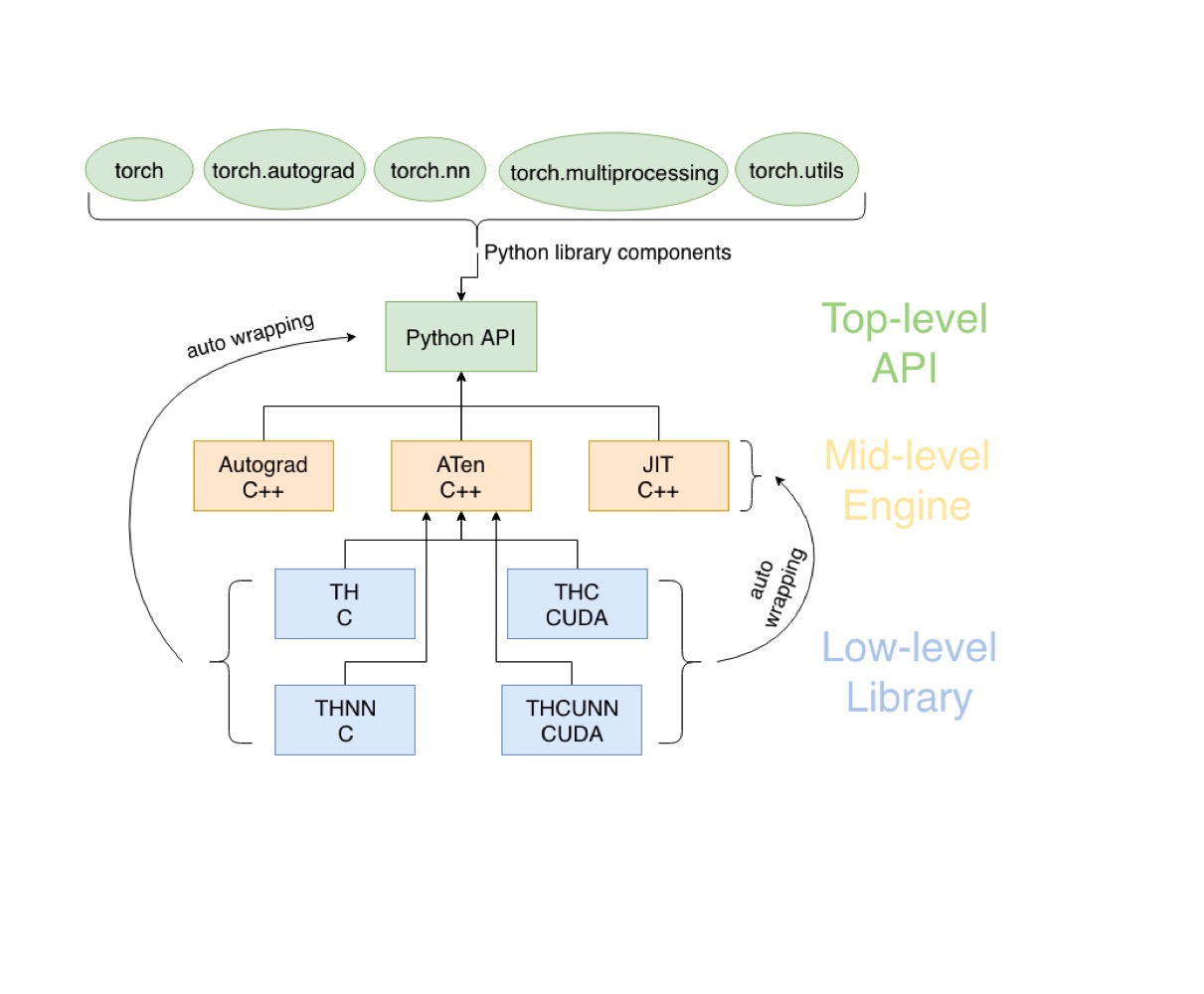
API Level
- 개발자들이 사용함
- torch.autograd = 자동 미분
- torch.nn = 뉴럴 네트워크
- torch.utils = 유틸리티
- torch.multiprocessing = 파이썬 멀티프로세싱
Engine Level
- API Level과 상호작용함
Library Level
- C = 사용자의 텐서 연산 담당
- cuda = gpu 담당
- 하드웨어와 상호작용하여 연산함
간단한 PyTorch 코드 표현
n 차원 텐서 생성 표현
# 1차원 텐서
a = torch.tensor([100, 150, 200])
# 2차원 텐서
b = torch.tensor([[30, 40, 50], [60, 70, 80]])
# 3차원 텐서
c = torch.tensor([[[255, 0, 0], [0, 255, 0]], [[0, 0, 255], [255, 255, 0]]])초기화된 Tensor를 생성하는 표현
# 길이가 5인 0으로 초기화된 1차원 Tensor
a = torch.zeros(5)
# 크기가 2x3인 0으로 초기화된 2차원 Tensor
b = torch.zeros([2, 3]) # (행, 열)
# 크기가 3x2x4인 0으로 초기화된 3차원 Tensor
c = torch.zeros([3, 2, 4]) # (행, 열, 차원)
# 길이가 3인 1로 초기화된 1차원 Tensor
d = torch.ones(3)
# 크기가 3x2인 1로 초기화된 2차원 Tensor
e = torch.ones([3, 2])
# 크기가 3x2x3인 1로 초기화된 3차원 Tensor
f = torch.ones([3, 2, 3])
# 크기와 자료형이 같은 0으로 초기화된 Tensor로 변환
g = torch.zeros_like(e) # e와 크기와 자료형이 같은 0으로 초기화된 Tensor
# 크기와 자료형이 같은 1로 초기화된 Tensor로 변환
h = torch.ones_like(b) # b와 크기와 자료형이 같은 1로 초기화된 Tensor
# 0~1 사이의 연속균등분포에서 추출한 난수로 초기화
i = torch.rand(3) # 1차원의 크기가 3인 텐서
j = torch.rand([2, 3]) # 1차원은 2, 2차원의 크기가 3인 텐서
# 표준정규분포에서 추출한 난수로 초기화
k = torch.randn(3)
l = torch.randn([2, 3])
# 크기와 자료형이 같은 연속균등분포 난수 Tensor
m = torch.rand_like(k)
# 크기와 자료형이 같은 표준정규분포 난수 Tensor
n = torch.rand_like(i)
# 지정된 범위 내에서 초기화 된 Tensor
o = torch.arange(start = 1, end = 11, step = 2)초기화 되지 않은 Tensor 생성
# 초기화 되지 않은 Tensor
q = torch.empty(5)
# 초기화 되지 않은 Tensor에 다른 데이터로 수정하는 표현
q.fill_(3.0) # 메모리 주소는 변경되지 않음Tensor의 요소를 반환하거나 계산하는 함수
l = torch.tensor([[1, 2, 3], [3, 4, 5]])
# Tensor의 모든 요소들 중 최소값을 반환하는 함수 코드 표현
torch.min(l)
# Tensor의 모든 요소들 중 최대값을 반환하는 함수 코드 표현
torch.max(l)
# Tensor의 모든 요소들의 합을 계산하는 함수 코드 표현
torch.sum(l)
# Tensor의 모든 요소들의 곱을 계산하는 함수 코드 표현
torch.prod(l)
# Tensor의 모든 요소들의 평균을 계산하는 함수 코드 표현
torch.mean(l)
# Tensor의 모든 요소들의 표본 분산을 계산하는 함수 코드 표현
torch.var(l)
# Tensor의 모든 요소들의 표본표준편차를 계산하는 함수 코드 표현
torch.std(l)Tensor의 특성을 확인하는 메서드
# Tensor의 차원의 수를 확인하는 코드 표현
l.dim()
# Tensor의 크기(모양)을 확인하는 코드 표현
l.size
l.shape #(메서드가 아닌 속성)
# Tensor에 있는 요소의 총 개수를 확인하는 코드 표현
l.numel()Tensor 복제
x = torch.tensor([1, 2, 3, 4, 5, 6, 7])
z = x.clone()
z = x.detach().clone()과 .detach()와 차이점
- clone 메서드는 복사한 텐서를 새로운 메모리에 할당함. 따라서 복사 대상 텐서의 값이 변해도 복사한 텐서의 값이 변하지 않는 deepcopy임
- detach 메서드는 텐서를 복사하지만 복사 대상 텐서와 메모리를 공유함. 그래서 기존 텐서의 값이 변하면 복사한 텐서의 값도 따라서 변하게 됨
CUDA Tensor
코드
# Tensor가 현재 어떤 디바이스에 있는지 확인
a = torch.tensor([1, 2, 3])
a.device()
# CUDA 기술을 사용할 수 있는 환경인지 확인
torch.cuda.is_available()
# CUDA device 이름을 확인
torch.cuda.get_device_name(device = 0)
# Tensor를 GPU에 할당
b = torch.tensor([1, 2, 3, 4, 5]).to('cuda')
b = torch.tensor([1, 2, 3, 4, 5]).cuda()
# GPU에 할당된 Tensor를 CPU Tensor로 변환
c = b.to(device = 'cpu')
c = b.cpu()참고

Vamos🔥🔥🔥🔥🔥