Abstract
- 기존 모델은 사실적인 대상 이미지를 생성할 수 있지만 소스 이미지의 구조를 유지하기 어렵다
- 여러 도메인의 대용량 데이터에 대한 생성 모델을 학습하려면 많은 시간과 자원 필요
Method
베이스라인
StyleGAN2-ADA + Freeze D
- 사실적인 이미지를 생성하지만 소스 도메인의 구조는 유지 하지 않는다.
FreezeSG
- 소스 이미지의 구조를 유지하는데 효과적
- Generator의 초기 레이어뿐만 아니라 스타일 벡터의 초기 레이어도 구조를 유지하는데 중요
-> freeze styleVector & Generator

Layer Swapping
- LS 적용 시 생성 이미지는 FreezeG or Freeze+ADA 보다 소스 이미지에 더 높은 유사성 갖는다.
단) generator의 저해상도 레이어의 가중치를 고정시켰기에 저해상도층 레이어를 swapping했을 경우 의미있는 결과를 내기 힘들다
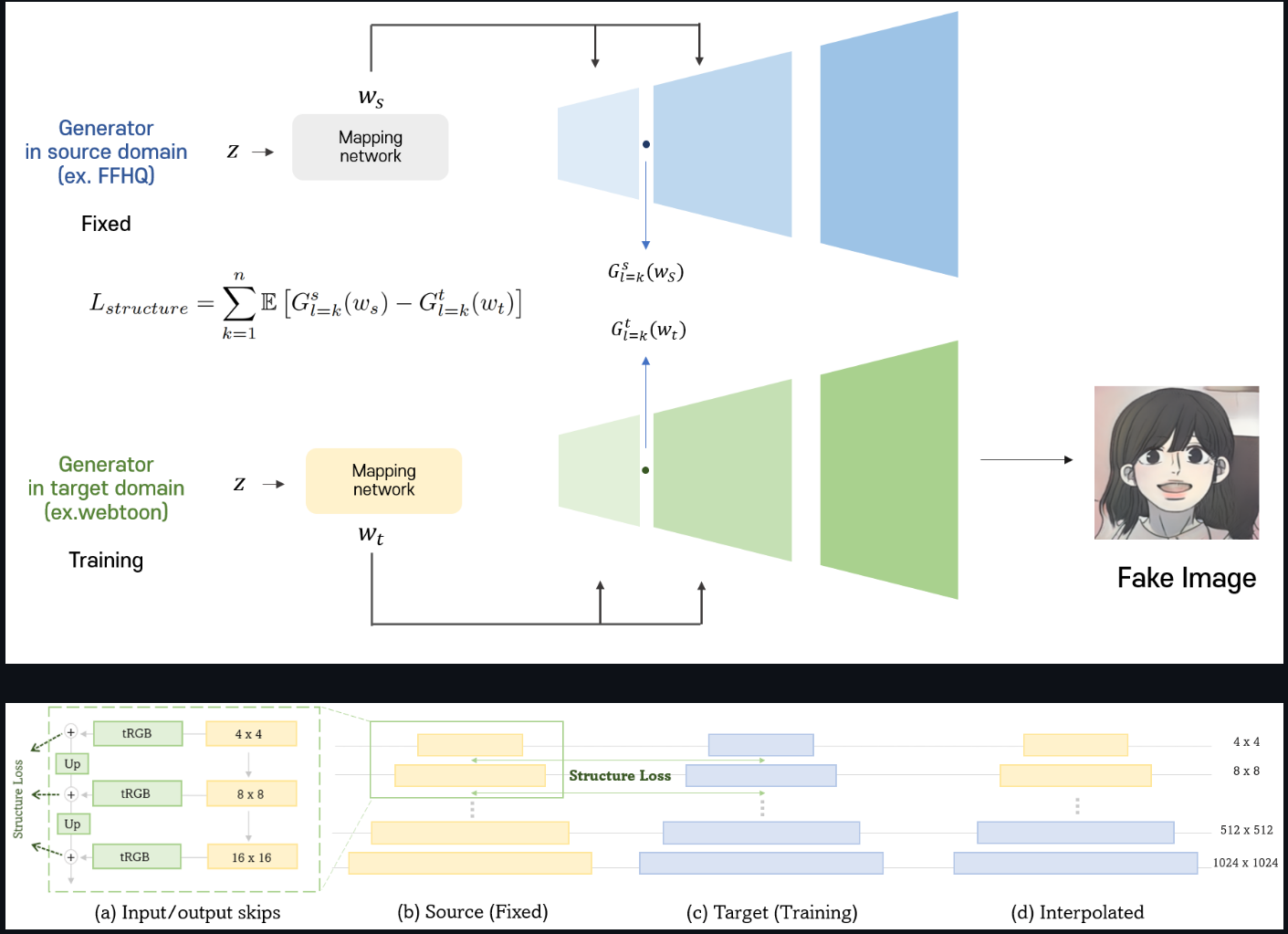
Structure Loss
- 이미지의 구조는 저해상도 이미지에서 결정된다
- 생성 된 이미지가 소스 도메인의 이미지와 유사하도록 저해상도 레이어의 값에 Sturcture Loss 적용
-> 소스 Genrator의 RGB 출력이 훈련 중에 target Generator의 RGB출력과 유사한 값을 갖도록 미세 조정
Application: Change Facial Expression/Pose
- SaFa
- StyleCLIP
- StyleMixing

안녕하세요