사용용도

1. inversion
2. Facial frontalization
3. Inpainting
4. Multi-modal conditional image synthesis(Sketch)
5. Multi-modal conditional image synthesis(Segmentaion Map)
6. Super-resolution
StyleGAN2 Inversion
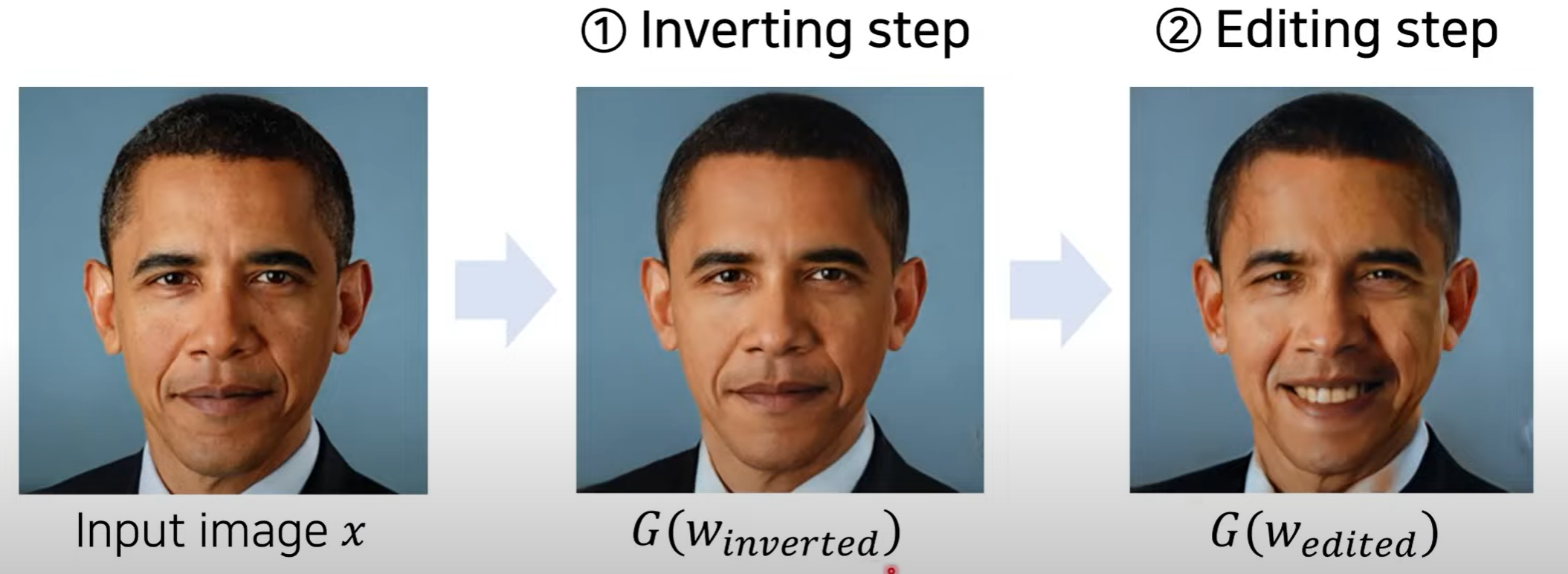
- w를 업데이트하여 유사한 이미지를 만드록
- w를 수정하여 이미지를 변경할 수 있다
Latent Space 종류
W Space(1x512)
- w벡터 하나에 대해서만 최적화가 진행 되기 떄문에 특정 이미지에 완벽히 맞는 latent vector를 찾는것은 아니기에 특정한 이미지와 조금 다르지만 보다 일반적인 특성을 가지고 있다
-> manipulation에서는 w 벡터로만 하는것이 더 좋은 결과가 나올 수 있다
W+ space(18x512)
- 직접적으로 18개의 레이어의 벡터를 업데이트하므로, 이미지 x에 더욱 가까운 inversion이 가능
Pixel2StylePixel
- pixel space -> style space -> pixel space
- 실제 이미지를 W+에서 직접적으로 인코더 가능
- 사전 학습된 StyleGAN Generator를 사용하여 image-to-image translation을 할 수 있는 방법 제안

- 입력이미지(Pixel Space) -> PSP인코더 -> W+ space -> 사전 학습된 StyleGAN2 -> 결과 이미지(pixel space)
pSp 아키텍처
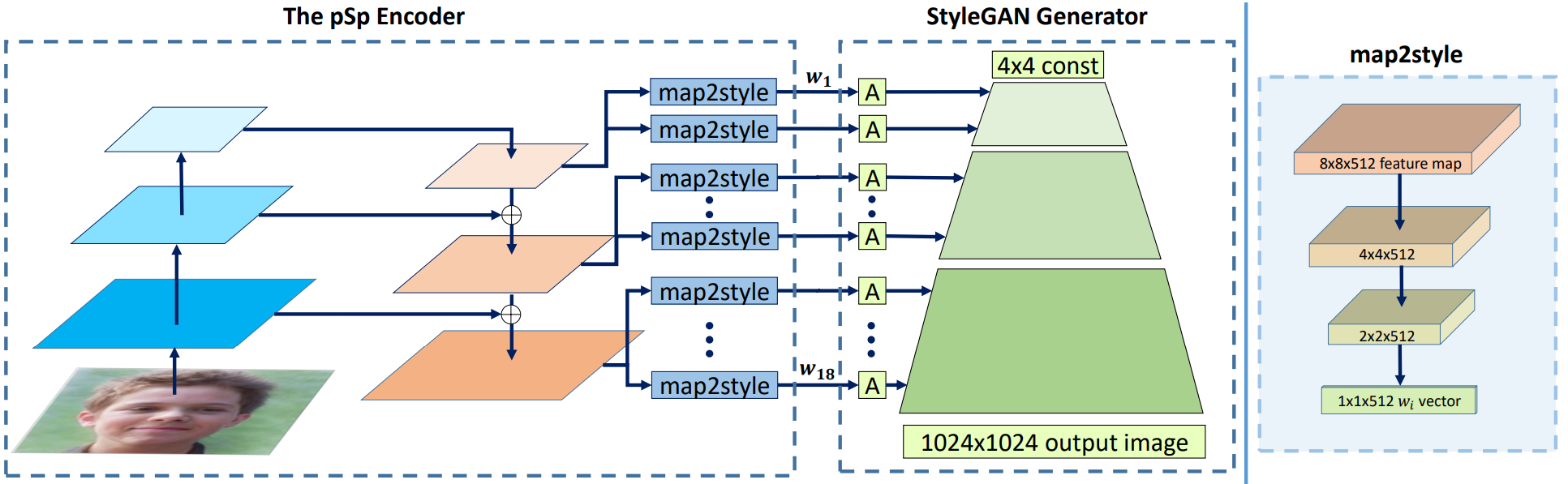
- StyleGAN은 사전학습된 네트워크이므로 업데이트 하지 않음
- Input이미지를 CNN 사용과 비슷하게 하지만 다른점은 마지막 layer만 사용하는 것이 아닌 모든 레이어에서의 특징을 뽑아낸다
- lateral connection(residul같은) 앞쪽에서 사용한 feature map의 정보가 뒤쪽에서도 적용되어 높은 품질의 시멘틱 feature를 추출
- 특정 사물의 위치는 컨브연산 수행 뒤에도 어느정도 위치의 정보를 갖고 있다
-> 해상도가 낮은 부분의 high level feature은 coarse style로 매핑(적절한 latent vector를 찾을 수 있다)
Map2Style
- feature Map을 스타일 정보로 mapping시켜줄 수 있는 네트워크
-> 1by512차원 벡터로 매핑
Feature Pyramid Networks(FPN)
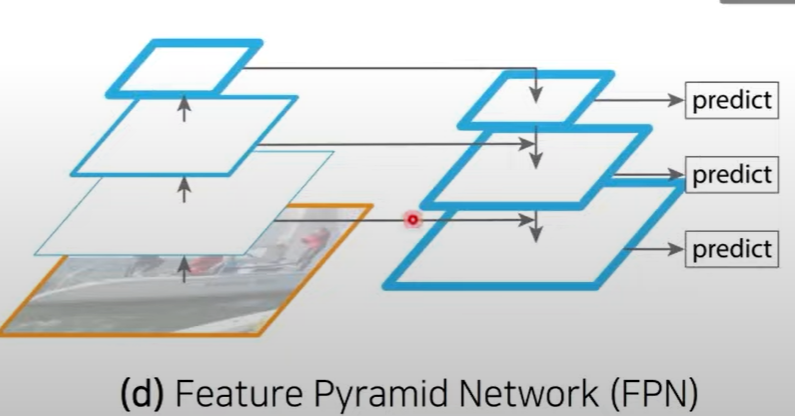
- residual방식을 사용하여 앞에 있는 feature의 정보를 집어넣을 수 있어
semantic정보를 보다 효율적으로 추출 가능
pSp프레임 워크

- 실질적으로 인코더 부분인 E(.)를 학습하여 W+ space의 vector를 찾는다.
-> w space에서는 finer details의 표현이 어렵다 - E(x)인코더를 거친 결과가 w헷 평균적인 얼굴의 벡터와 더해 생성자에 들어간다
-> 초기얼굴을 평균에서 시작하게 하여 잔차를 구하기 쉽게 한다(평균과의 차이를 구한다)

- 이미지 공간에서 pixel값이 유사해지도록 하는 것보다 feature간의 거리를 좁히는 것이 보다 좋은 기울기 얻게하여 퀄리티를 높임
- R(x) 두사람의 얼굴이 얼마나 다른지 거리를 구할 수 있다
-> 람다를 조정하여 로스값구하고 적용 가능
StyleGAN Inversion 성능
-
pSp를 한 번 학습하고 나면 한 번만 forward연산을 수행하면 된다

-
한번의 forward의 인코딩 성능면에서 psp가 가장 좋은 결과 나온다
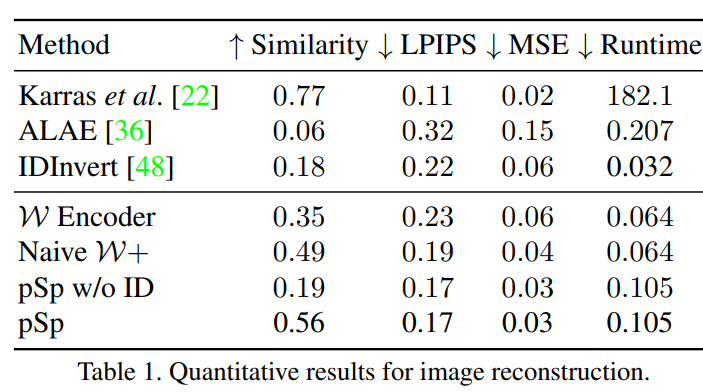
- 성능과 속도면에서 가장 좋은 결과 나온다

- perceptual loss계열의 loss만 사용하는 것보다 ArcFace네트워크 기반의 loss를 이용할 때 facial identity를 유지하기에 더욱 효과적
Face Frontalization

-> psp는 R&R의 3DMM fitiing과 같은 추가적인 module 없이 frontalization을 수행할 수 있으며, 속도가 빠르다
- target image를 랜덤으로 flip한다
-> 모델이 fixed frontal pose로 수렴 할 수 있도록 한다 - L id loss의 가중치는 높이고 L2와 Llpips의 값은 낮춘다
Conditional Image Synthesis
Face From Sketh
- 입력 : conditioned image,
- 출력 : target real image
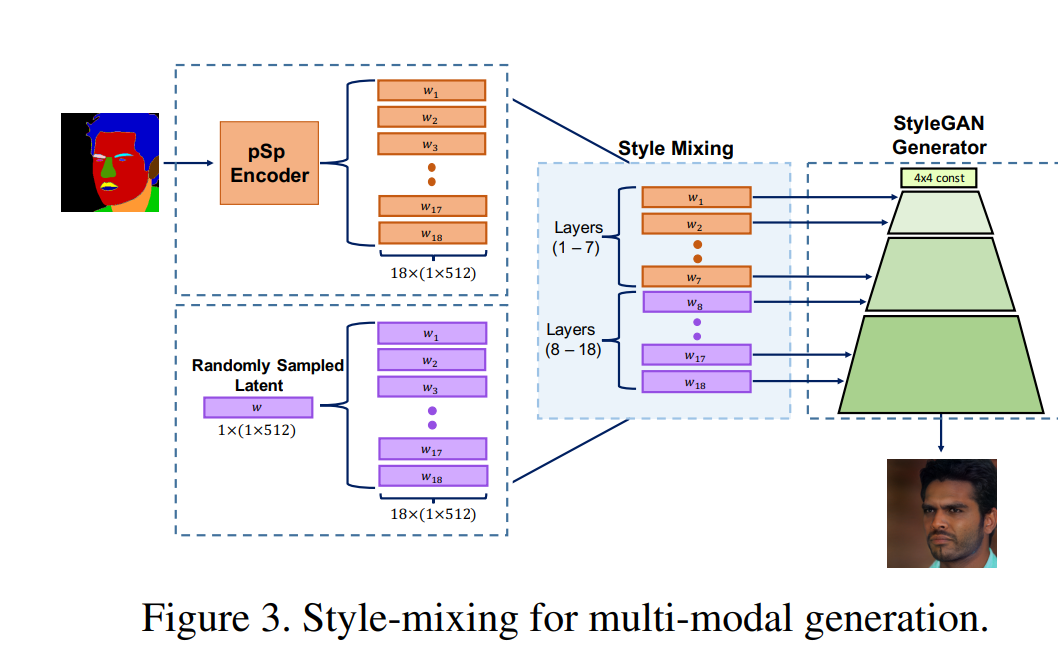
- Multiple image를 만들 떄는 fine styles에 대해 다양한 랜덤 vector에 적용
-> 조건 이미지를 psp인코더를 지나고 latent vector를 구하고 위쪽 coarse부분만 뽑아 넣어주고 fine 부분은 렌덤하게 넣어준다(세밀한 정보를 다양하게 갖는다)

- 전통적인 optimization 방식에서는 input이 StyleGan domain에 없는 상황에서 conditional image synthesis를 해결하기 어렵다
-> psp는 가능
Face From Semantic Segmentation Maps

Super resolution

Inpainting

그외 도메인

- FFHQ 제외하고도 AFHQ Cat 및 AFHQ Dog 데이터 세트에 대해 진행 했을 때도 좋은 결과
- 사람 얼굴 이미지가 아니므로 Lid를 제외한 다른 loss들을 적절히 사용하여 인코더 학습
- pSp는 사전학습된 StyleGan2가 필요하지만 StyleGan2-ADA사용하여 적은 데이터로 학습
단점

- 손모양이나 배경 details 같은 요소를 보존하는 것은 쉽지 않은 작업
결론
- w+ space에 mapping하는 네트워크다
- 추가적인 optimization이 필요하지 않으므로 한번의 forward로 이미지 만들 수 있다
-> 속도가 빠르다
- 추가적인 optimization이 필요하지 않으므로 한번의 forward로 이미지 만들 수 있다
- pSp 아키텍처를 크게 변경하지 않고 다양한 application에 적용 가능

안녕하세요