Abstract
- adaptive discriminator augmentation 알고리즘 제안
- 수 천장의 이미지만 있어도 학습 가능
Instroduction
-
현대의 GAN은 일반적으로 수 만, 수 십 만 장에 해당하는 이미지 데이터셋 요구
-> 작은 데이터셋은 Discriminator가 과적합 됨(G에게 주는 feed back이 무의미)
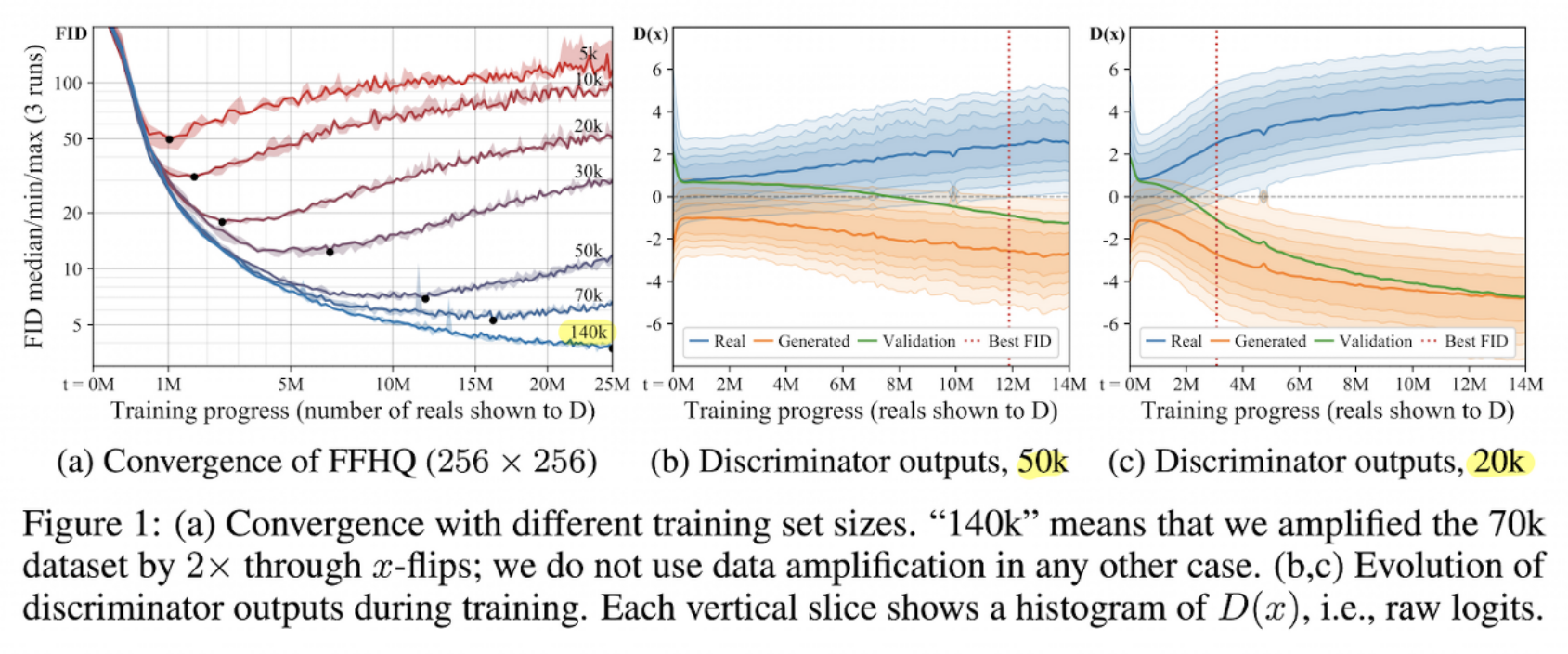
-
140k를 제외한 나머지 데이터셋의 경우(14만장 이하) FID는 어느 순간 증가
-> a,b,c 다 과적합 현상 나타남

- 증강 확률 p에 따라 discrimator가 보는 이미지가 달라진다
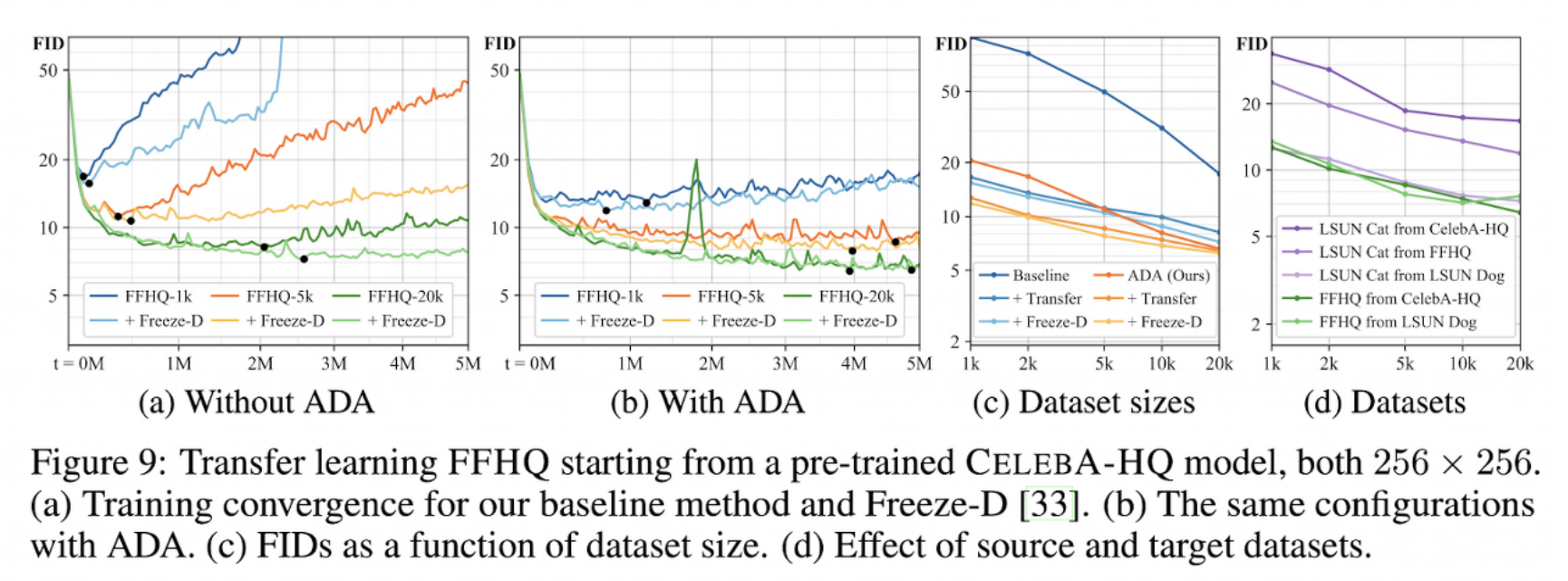
- ADA를 사용할 경우 5천장 이상에서는 과적합이 일어나지 않았다
증강 알고리즘
- flip, 회전 , 병진이동, 스케일링, 임의 회전, 비율을 다르게 한 스케일링, rgb noise주기, 일부 잘라내기 등 다양한 증각 기법 사용
즉) 소량의 이미지셋으로 D의 과적합을 막을 수 있다

안녕하세요
응원해요