Introduction
- 고화질 이미지 생성에 적합한 아키텍처이다.
- PGGAN 베이스라인 아키텍처의 성능을 향상
- Disentanglement 특성 향상
- 여러가지 정보가 얽혀있으면 컨트롤 하기 힘들다(Ex 안경, 성별)
- StyleGan은 이 얽혀있는 문제를 잘 해결 했다
- 고해상도 얼굴 데이터셋 발표

- Coarse Style이란 하나의 얼굴에 포함된 시멘틱한 부분(안경, 얼굴형 등)
관련기술
- GAN -> DCGAN(Deep Convolution Layers)
DCGAN
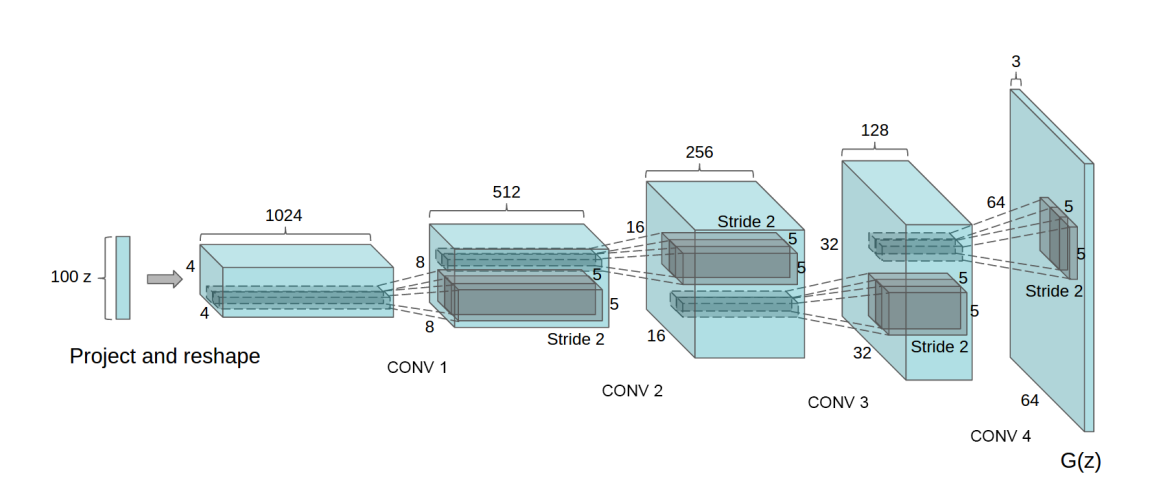
- CNN이란 반대로 레이어를 지날 때마다 채널값이 감소하고 너비와 높이를 키우는 것
-> 이미지 도메인에서 더 좋은 효과가 나왔다
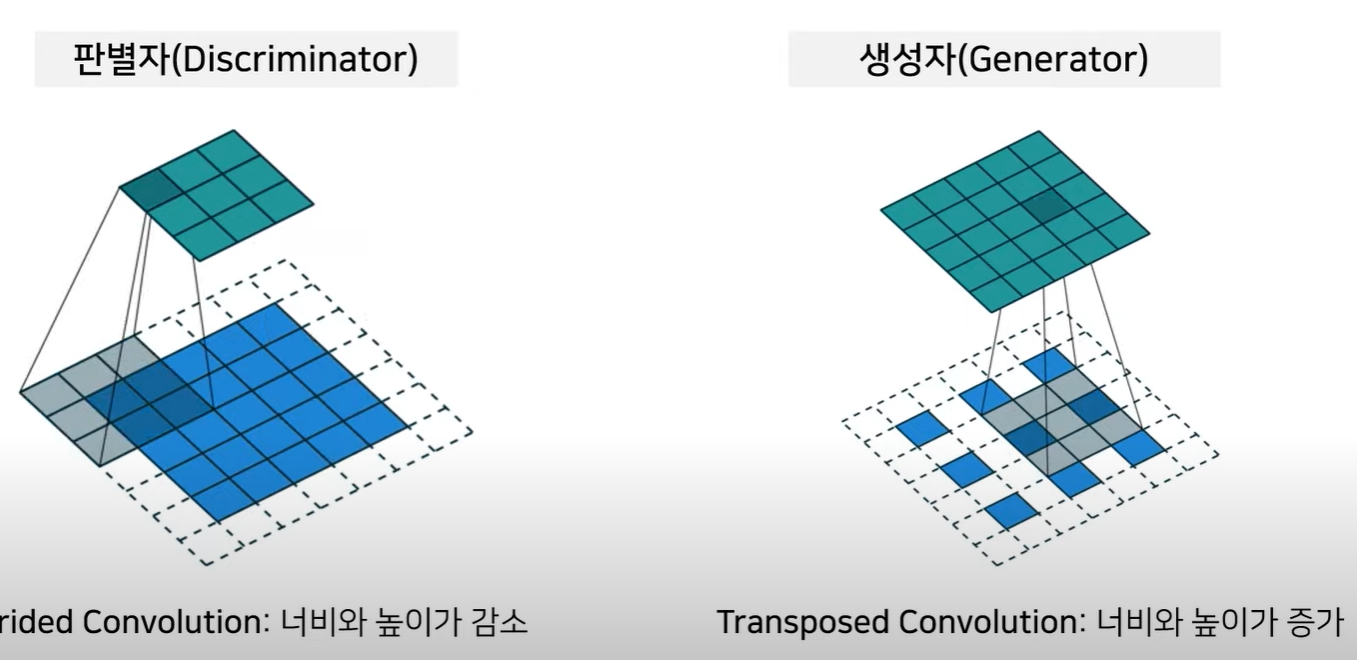
- 판별자: 너비와 높이가 감소하고 채널수가 증가
- 생성자: 너비와 높이가 증가하고 채널수가 감소

- 시멘틱 벡터를 담고 있는 laten백터를 만들고 수식처럼 사용 가능하다
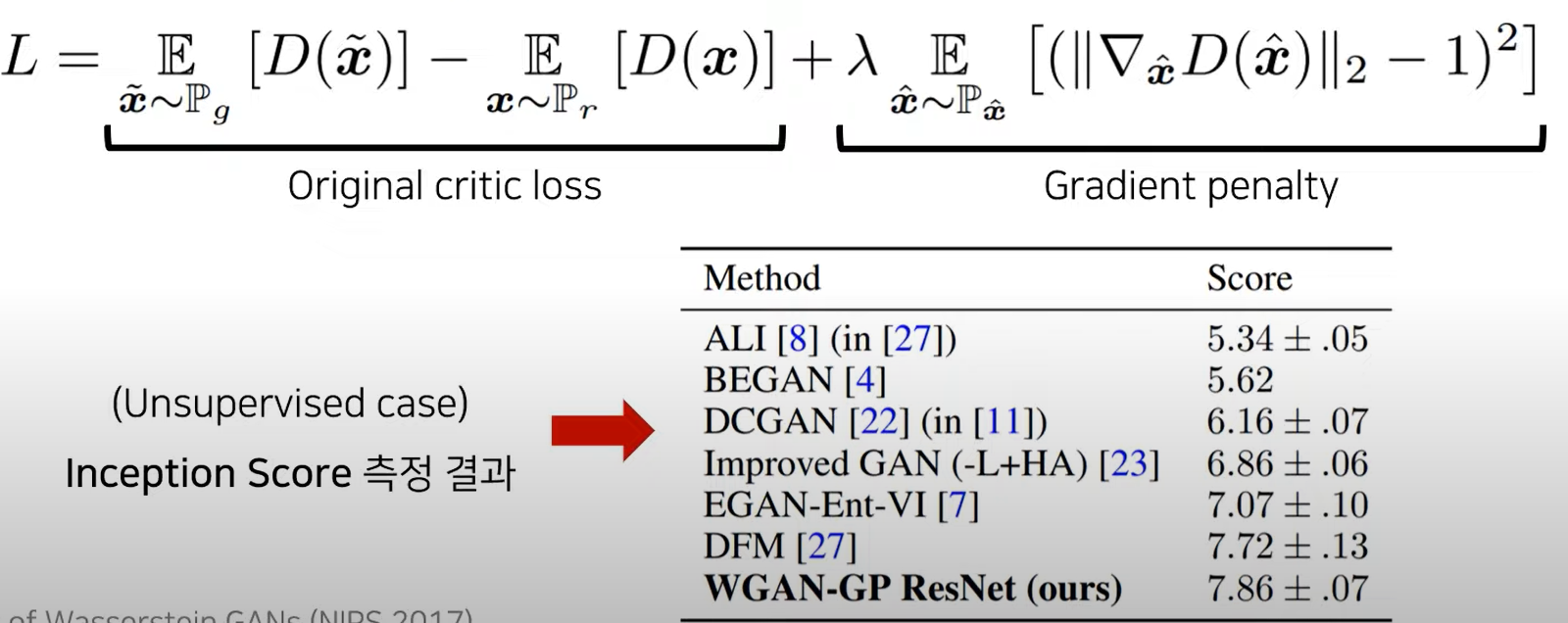
WGAN-GP
- 1-Lipshichtz 조건을 만족하도록 하여 안정적인 학습 유도
- gradient penalty이용하여 WGAN의 성능 개선
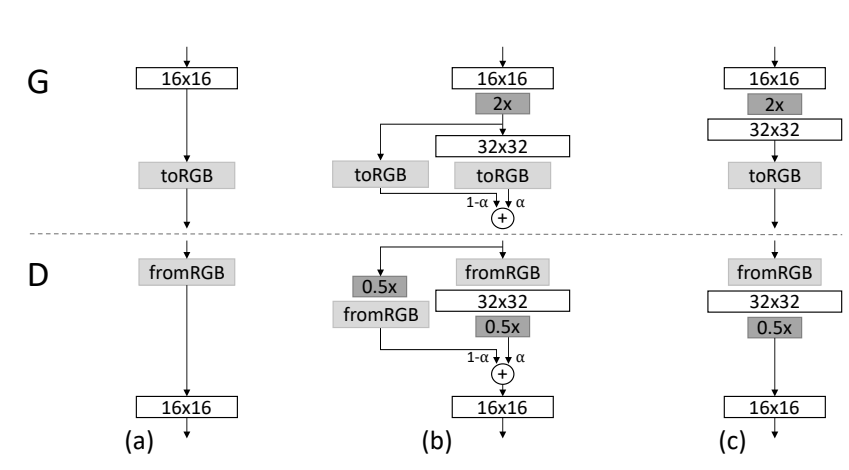
PGGAN
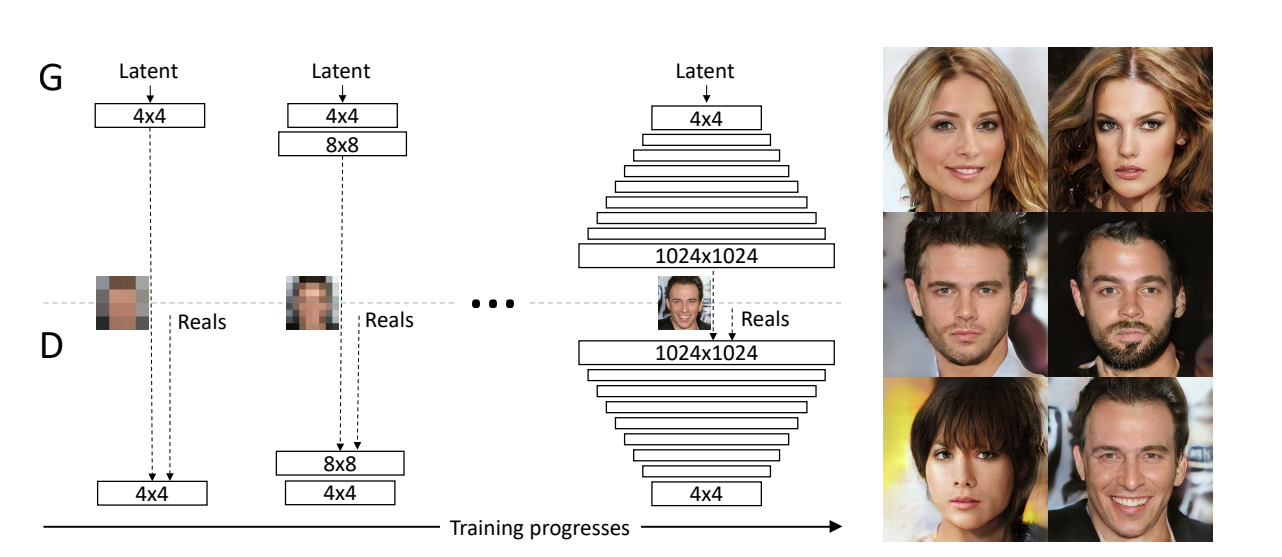
- 학습 과정에서 레이어를 추가
- 처음부터 레이어를 만들어 놓고 학습시키는 것이 아닌
- 점진적으로 레이어를 증가 시키면서 학습시킨다
- 고해상도 이미지 학습 성공
- 학습의 속도 빨라짐
- 한계점
- 이미지 특징 제어가 어려움 -> Style Gan이 해결
StyleGAN
핵심아이디어
MappingNetwork
- 기존 특정차원 z도메인에서 하나의 Latent Z 벡터 샘플링하고 네트워크에 넣는다
-> 하지만 특징이 잘 분리되지 않는다.
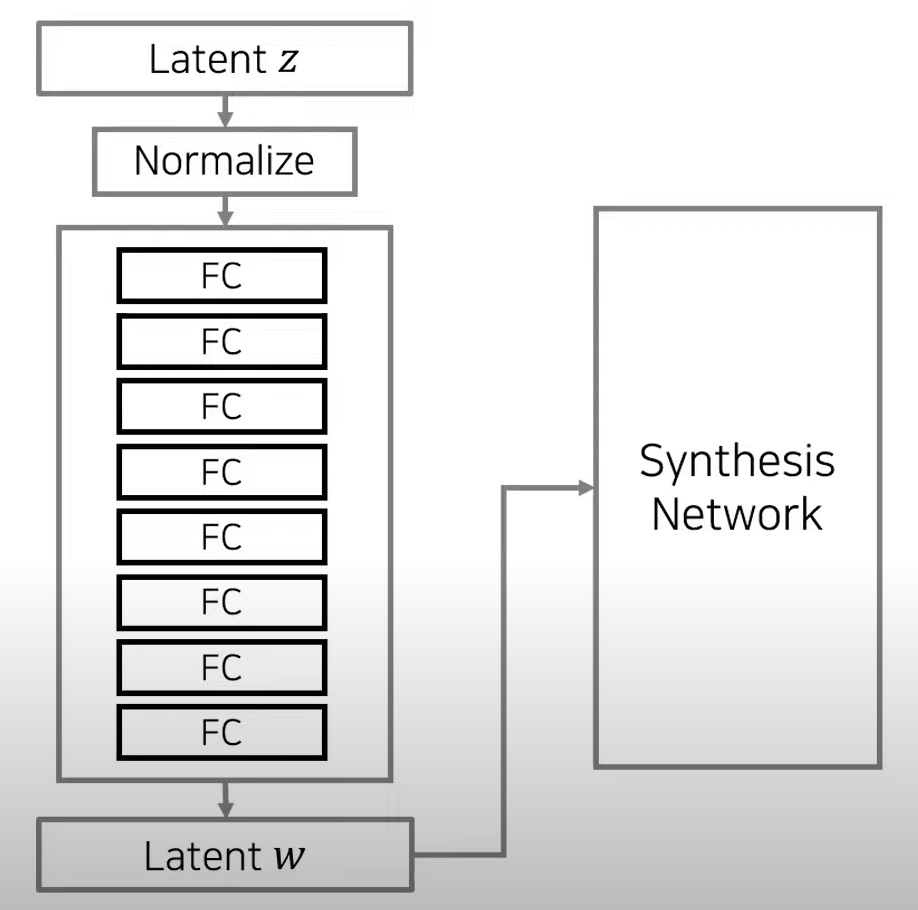
- 512차원의 z도메인에서 w도메인으로 매핑을 수행
- a를 세로를 남성과 여성 가로를 머리 짧고 길고했을 경우
- 남성이 머리 길었을 경우가 없다
- 샘플링한 z도메인에서 바로 사용할 경우 엮여있는데
- w도메인으로 매핑하고 사용하면 좋은 결과를 낼 수 있다
AdaIN
- 다른 원하는 데이터로부터 스타일 정보를 가져와 적용할 수 있다
- 학습시킬 파라미터가 필요 없다(감마, 베터 필요 없음)
- feed-forward 방식의 style transfer네트워크에서 사용된다
-> styleGan은 styleTransfer의 Adain에서 아이디어를 가져온것이다. - 하나의 이미지를 생성할 때 여러개의 스타일 정보가 레이어를 지날 때 입혀질 수 있다
- batch norm과 비교했을 때 정규화가 Instance단계로 수행 된다
-> batch norm은 하나의 배치에 포함된 모든 이미지를 채널마다 수행
-> Instance norm은 하나의 이미지를 채널단위로 수행
Style Modules 모듈
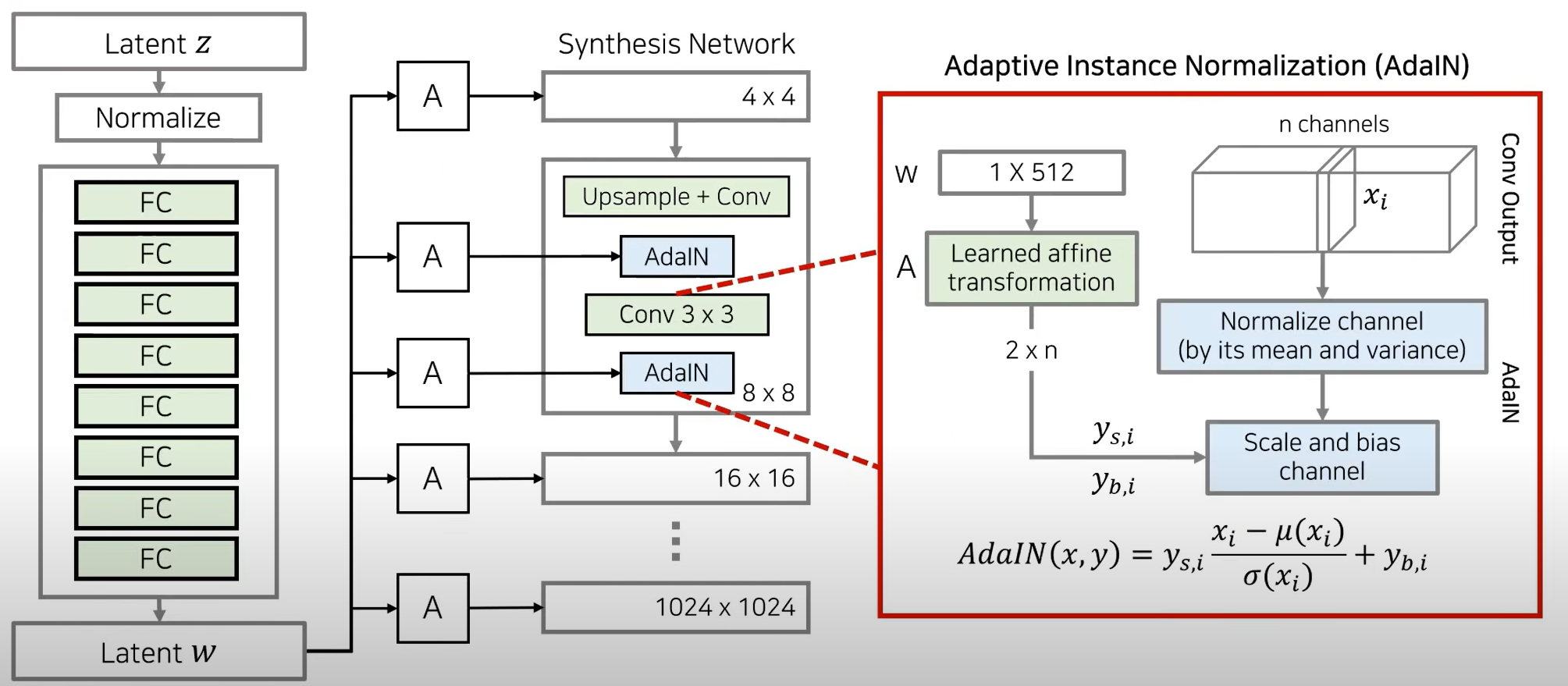
- Latent W가 실제 네트워크에 들어간다 Adain에 들어갈 수 있는 스타일 정보가 될 수 있도록 한다
- Adain앞쪽에서 conv 결과가 나왔을 떄(n개의 채널로 구성된 텐서라고 가정) 각각의 featuremp을 Xi라 하자
- W를 Learned affine transformation을 통해 각 채널당 2개의 스타일 정보를 만든다
- 각각의 feature map에 대해서 정규화된 값에 대하여 얼마만큼 스케일링하고 bias를 더할지
y는 스타일 정보 -> stastics를 바꾸기 위해 이루어짐 - 정규화를 통해 mean과 various값을 바꿔주고 이 과정 자체가 스타일트랜스퍼라고 할 수 있다
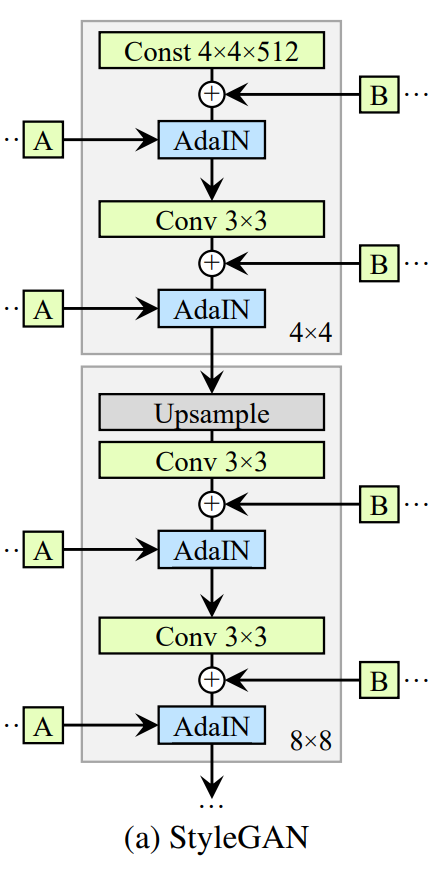
- 각각의 block들은 두개의 covolution layer와 두개의 adain layer을 지닌다
- 너비와 높이를 증가시키기 위해 Upsample을 하고 conv수행 -> 이런식으로 해상도 증가
- Adain은 conv연산 수행 결과를 처리할 목적으로 사용
- Adain에는 스타일 정보가 들어간다
과거의 입력 방법 바꿈
- 기존에는 laten벡터를 input에 바로 넣어서 실행했다면
- styleGan에서는 각각의 레이어를 지나는 과정에서 적용이 가능하다
Stochastic Variation
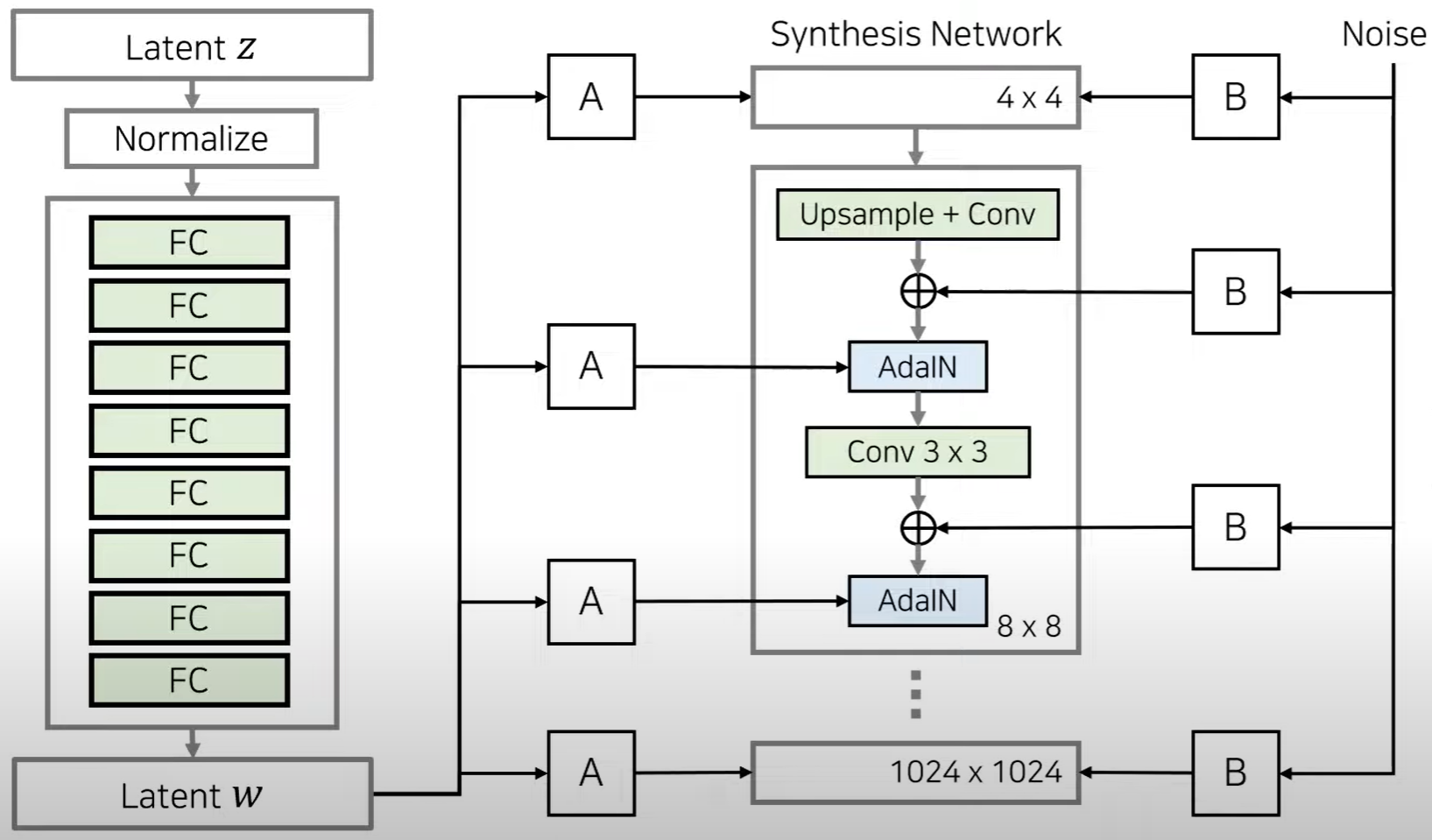
- 다양한 확률적인 측면을 컨트롤
- 별도의 Noise인풋을 넣어서 각각의 레이어에 노이즈의 정보가 들어갈 수 있도록 한다.
- Adain레이어 지나가기 전에 노이즈를 적용
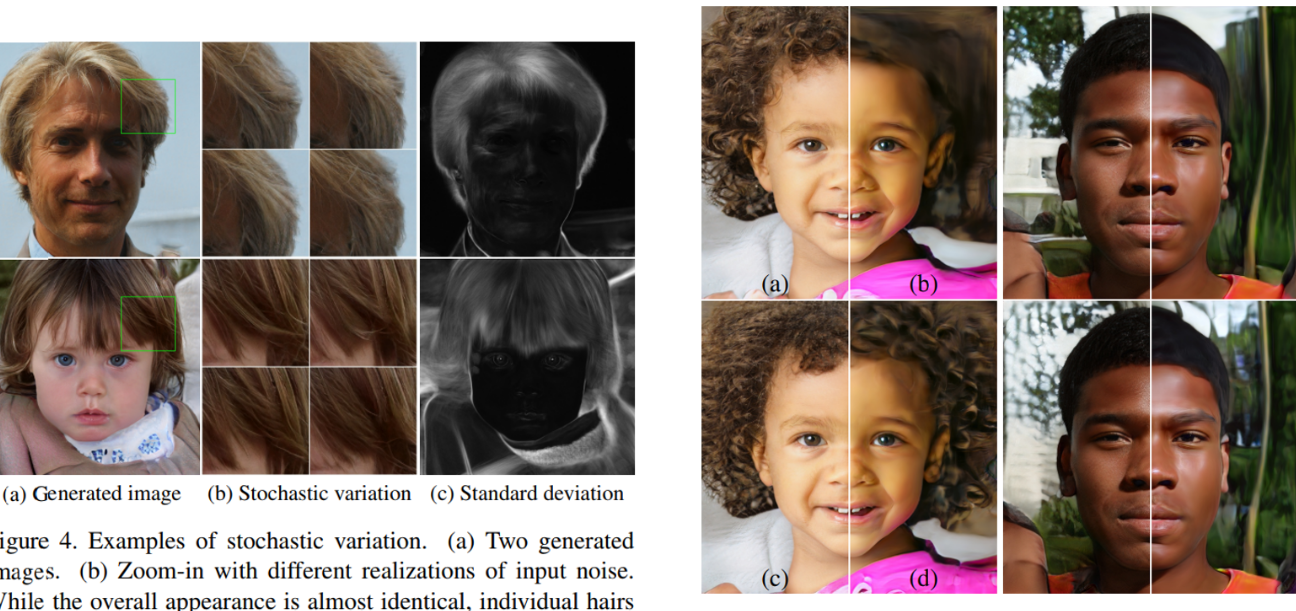
- 스타일: high-level global attribute
- 얼굴형, 포즈, 안경의 유무 등
- 노이즈: stochatic variation
- 주근깨(freckle), 피부 모공(skin pore)
- Coarse noise : 큰 크기의 머리 곱슬거림, 배경 등
- Fine noise : 세밀한 머리 곱슬거림 배경 등
a : 모든 레이어에 노이즈 적용
b : 노이즈 적용하지 않음
c : Fine layer 적용
d : coarse layer 적용
Style Mixing(Mixing Regularization)
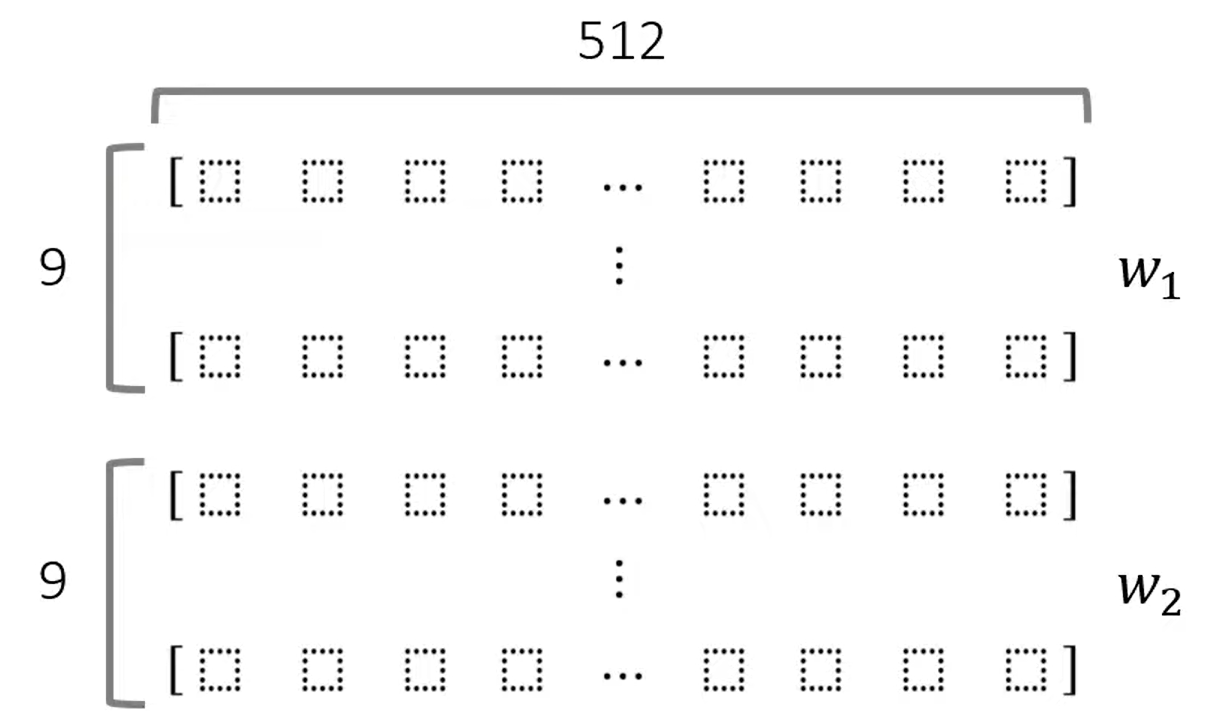
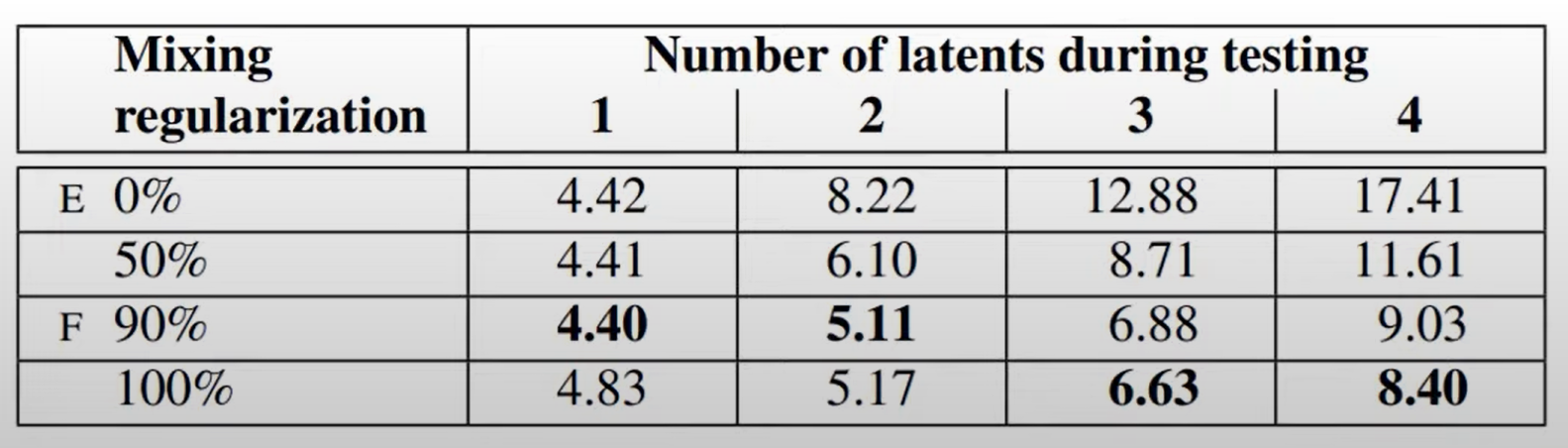
- 인접한 레이어 간의 스타일 상관관계를 줄입니다
- 구체적인 Mixing Regularization방법 설명
1) 두 개의 입력 벡터를 준비
2) crossover 포인트를 설정- 특정 포인트를 기점으로 위쪽은 하나의 벡터 아래쪽은 다른 벡터를 사용
- 위와 같이 위9개는 w1 벡터 아래 9개는 w2벡터를 사용하고
- 각 레이어의 상관관계를 줄이기 위해
3) 크로스오버 이전은 w1, 이후는 w2를 사용
- 스타일은 각 레이어에 대하여 localized 된다 ->상관관계를 줄일 수 있다
StyleGAN
- PGGAN에서 Laten z를 w에 매핑시키고 noise를 넣어주는 것을 스타일겐이라 한다
- 더욱 Linear하고 덜 entangled하다
Latent Vector Meaning of StyleGAN

StyleGAN 정보가 입력되는 레이어 위치에 따라서 해당 스타일에 미치는 영향력의 규모가 다르다
- Coarse Style: 세밀하지는 않지만 전반적인 시멘틱 피쳐를 바꿀 수 있는 스타일
- Middle Style: 헤어스타일 눈뜬 유무등 좀더 세밀하게
- Fine Style : 색상 등 좀더 세밀한것을 다룬다
-> 위 4개의 레이어는 이미지B의 벡터를 아래 14개는 이미지A의 벡터를 사용
앞의 4개의 레이어는 나중에 결과 레이어를 거치면서 만들어질 수 있기 때문에 결과 이미지에 많은 영향이 미치는 부분이 적용
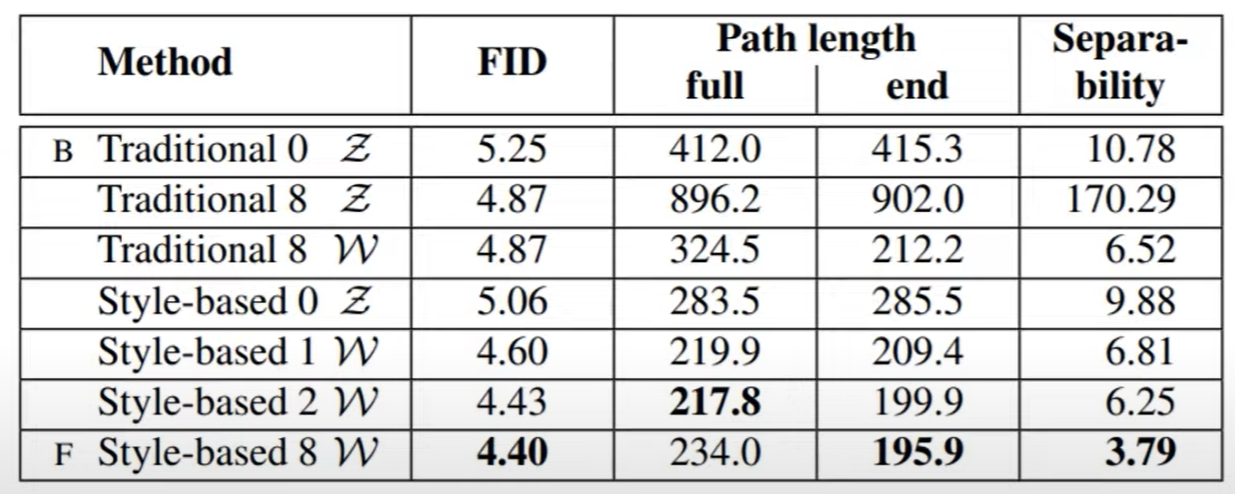
성능지표
Ecaluation:FID값 비교/분석

A) PGGAN 베이스라인
B) Bilinear up / downsampling operations
C) Mapping Network + Adain
D) Input 레이어로 학습된 4x4x512 상수 텐서 사용
E) 노이즈 입력
F) Mixing Regularization
Disentanglement관련 두 가지 성능 측정 지표
-
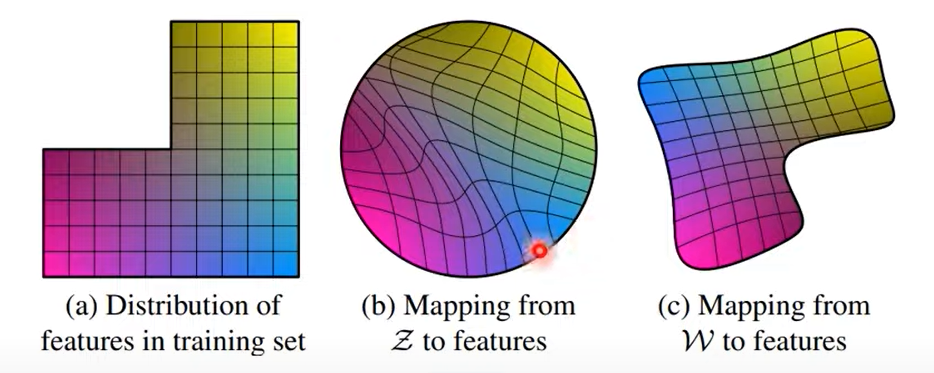
w 공간(space)이 z공간보다 이상적인 성질을 가지고 있습니다.
-
Path Length: 두 벡터를 보간(interpolation)할 때 얼마나 급격하게 이미지 특징이 바뀌는지
-
Separability: latent space에서 attributes가 얼마나 선형적으로 분류될 수 있는지 평가
-> FID말고도 두가지의 성능지표에서도 좋은 결과가 나왔다
Latent Vecotr Interpolation
- 두 개의 latent codes를 보간(interplation)하는 방법
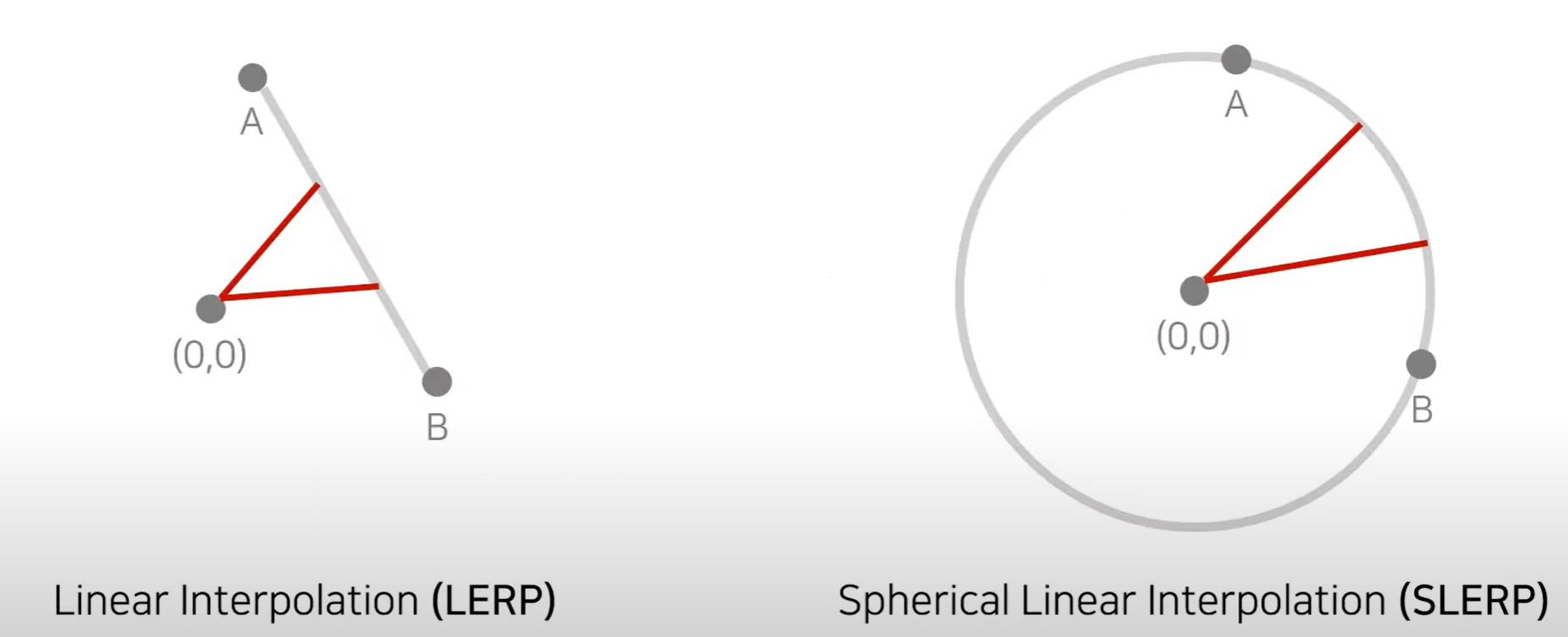
Perceptual Path Length
- 두 개의 latent codes를 보간(interpolation)할 때 얼마나 급격하게(부드럽지 않게) 바뀌는지 체크한다.
- 지점 t와 t+e 사이에서의 VGG특징(feature)의 거리가 얼마나 먼지 계산 가능
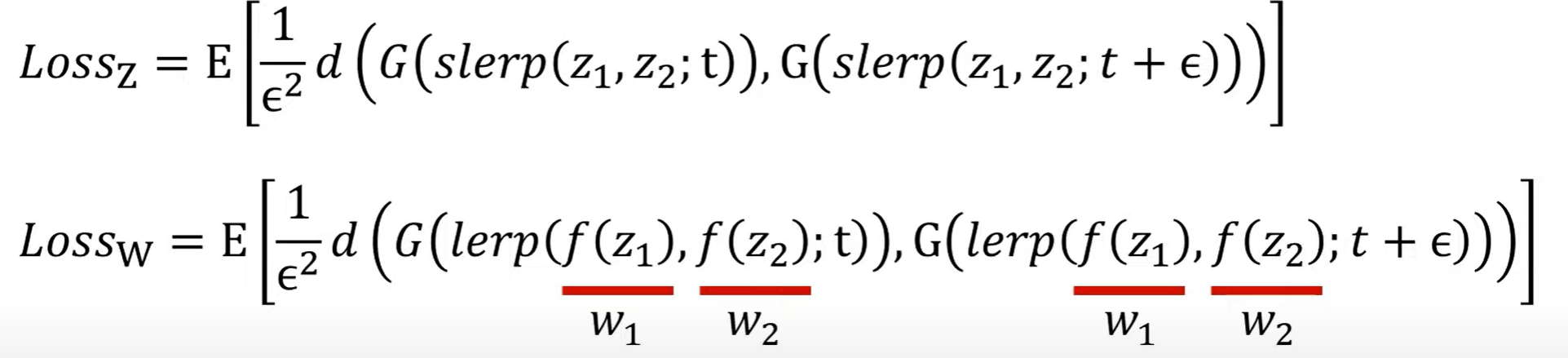
- e는 작은 상수
- 로스z는 z1과 z2를 보간하여 사용 , t+E를 통해 두개의 결과 이미지를 만들어내고 사전학습된 VGG네트워크에 넣어서 특징간의 거리가 얼마나 먼지를 계산
-> 다양한 특징들이 얽혀있어서 안경을 쓰지않은 여성과 안경을 쓰지 않은 남성을 보간했을 때 안경이 생겼다 사라지는 경우 Perceptual Path Length가 크게 나온다
-> 의도한 sementic linear하게 잘 바뀌는지 측정하는 지표
Linear Separability
-
CelebA-HQ: 얼굴마다 성별(gender) 등의 40개의 binary attributes가 명시되어 있는 데이터셋
- 이를 이용해 40개의 분류(classification) 모델을 학습한다.
-
하나의 속성(attribute)마다 200,000개의 이미지를 생성하여 분류 모델에 넣습니다.
- 이후에 confidence가 낮은 절반은 제거하여 100,000개의 레이블이 명시된 latent vector를 준비
- 이렇게 준비된 100,000개의 데이터를 학습 데이터로 사용
-
매 attribute마다 linear SVM모델을 학습
- 이때 전통적인 GAN에서는 z, Style GAN에서는 w를 이용
-
각 linear SVM 모델을 활용하여 다음의 값을 계산
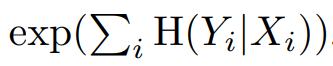
추가적인 실험 결과

-
동일한 세팅으로 추가 실험
- LSUN Bedroom 데이터셋
- LSUN Car 데이터셋
-
Coase styles 변화
- 카메라 구도
-
Middle styles 변화
- 특정 가구
-
Fine style 변화
- 세밀한 색상, 재질 등
논문리뷰
Abstract

- 생성자에 더 초점을 뒀으며, 기존 스타일트랜스퍼를 응용
- 높은 단계의 속성(포즈, 특징)을 잘 분리
- 하나의 스타일을 만들 때 여러개의 스타일을 조합해서 만들어진 결과물
- 확률적 다양함을 고려(컨뷰레이어 지나면서 노이즈 데이터를 입력하고 하나의 데이터가 다양한 방식으로 바뀔수 있게 만듦)
- traditional distribution qualitymetrics -> FID(Gan 분야에서 생성자 성능을 판단하는 척도) 개선된 결과 나왔다
- disentangles 특징들이 얽혀있지 않다.(안경부분만 수정하는데 성별까지 바뀌는 등 연관되지 않은 특징이 변경될 수 있다)
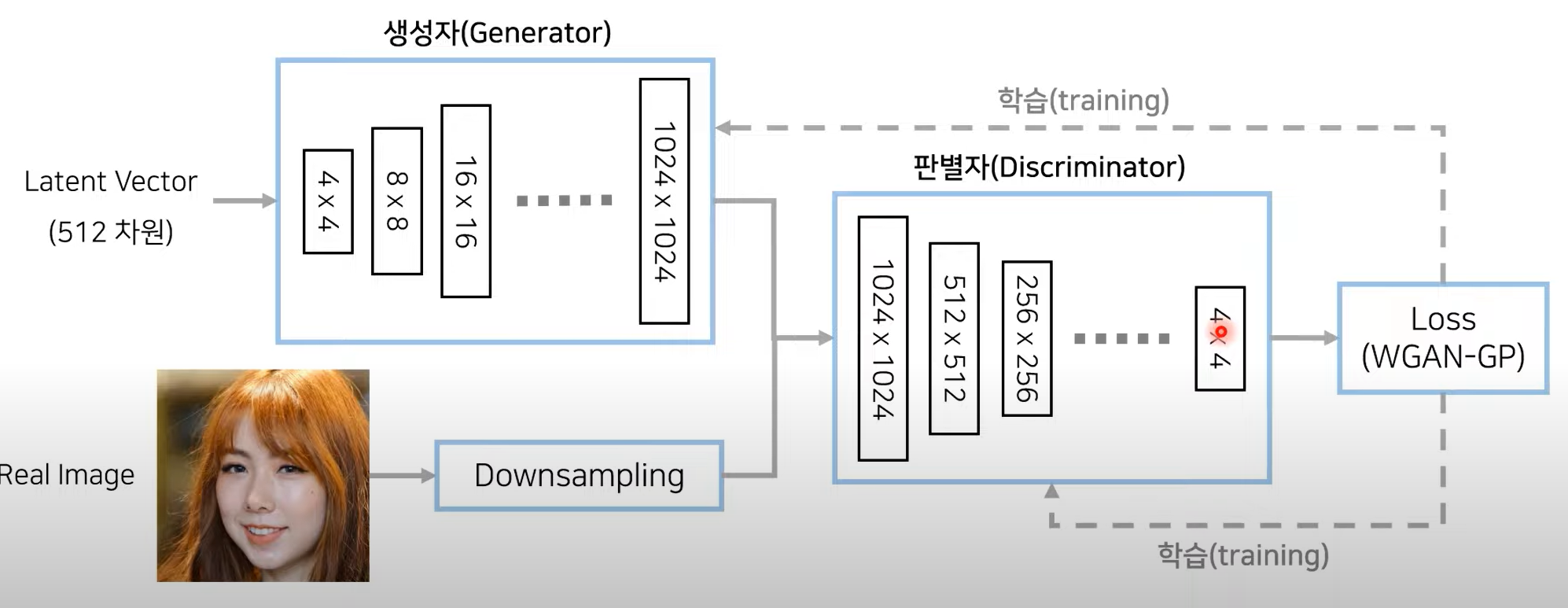
- 1024 x 1024고해상도 얼굴 이미지 데이터셋 배포함
Introduction

- 생성자의 동작방식은 아직까지도 세부적으로 이해 불가, 확률다양성 부분도 마찬가지
- latent space 생성자의 입력으로 들어가는 latent벡터 부분도 연구가 필요
- 주로 두개의 latent 벡터 사이에서 interpolations 수행
-> 정말로 생성자가 보간을 통해 이미지를 잘 생성했는지 판단이 힘들다

- 해상도의 크기를 키워가는 과정에서 여러 스타일을 적용해서 이미지를 만듦
-> 해상도의 크기는 키우고 채널이 줄어들면서 하나의 결과 이미지 생성

- 확률적 다양성 개선 부분 또한 이미지 생성자를 개선하여 나온 결과
- 판단자와 로스함수 부분에는 관여하지 않았다

- latent code를 latent intermediate space에 넣고 그곳에서 생성자에 넣을 수 있게 바꾼다 -> 심오한 효과를 낼 수 있다
- latent 벡터는 트레인닝데이터의 밀도함수에 따를 수 밖에 없기에 정규분포에서 노이즈를 샘플링한 후에 입력으로 넣게 되면 얽힘이 발생
- intermediate latent space에 넣게 되면 의존관계가 없어져 얽힘문제 해결
- Perceptual path length(보간과정에서 자연스러운 이미지)와 linear separability(선형적 분리)를 평가지표로 사용
Style-based generator

- 기존과 달리 latent code에서 생성자에게 바로 입력을 하는 것이 아닌 레이어를 지날 때 마다 스타일을 넣어주기에 처음에 하나의 학습된 하나의 상수 이미지가 들어간다
- 정규분포나 균등분포등 노이즈를 샘플링하는 것이아닌 non-linear 메핑을 통한 w벡터가 들어간다
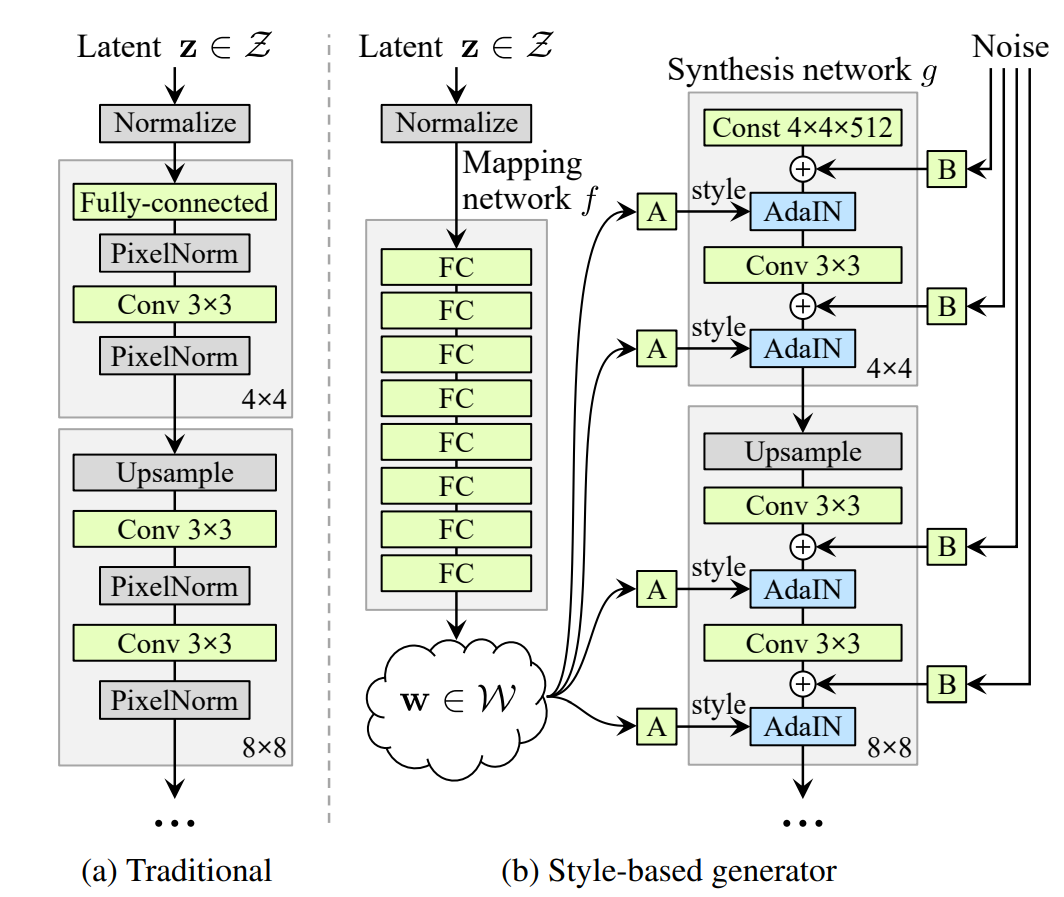
- 기존과 달리 메핑을 시켜주고 뽑은 w벡터를 각각의 블럭마다 두번씩 affine transfer을 시켜준다
- 확률적 다양성을 위해 Noise벡터 또한 한블럭마다 두개 넣어준다
- styleTransfer은 Adain이라는 정규화레이어를 사용
-> 입력받은 스타일 stastics를 피쳐의 stastics로 바꿀 수 있게 한다
스케일링과 바이어스 적용 - Noise정보는 featureMap에 따라 적용해야 하므로 featureMap에 따라 커질 수 있다

- Input latent를 W로 매핑하여 w space의 벡터로 바꿔주고 Affine trasformation를 지나고 Adain레이어를 지나 컨블루션레이어를 거친 결과를 보여준다
- mapping network는 8개의 레이어로 이루어져 512차원의 인풋을 다른 차원W의 아웃풋으로 바꿔준다
- 네트워크 구조는 PGGAN을 사용
- 파라미터 수는 크게 늘지 않았으면서 성능은 개선됐다

- Adain은 feed-foward 방식의 스타일트랜스포머에서 효과적으로 쓰인다
-> 하나의 이미지의 스타일을 가져와 adain을 거쳐 다른 이미지의 feature stastic을 변경

- 수식에 스케일링과 바이어스를 추가하여 feature space에서 feature stastic을 변경가능 x가 컨텐트 이미지 y가 스타일 이미지
- 고정된 상수 인풋값을 xi라 할 수 있고 블럭단위로 스타일이 적용되는것은 y라고 보면 된다
- Adain은 batch nomarlization과 비슷하지만 한 채널당 한 이미지에 대해서 정규화를 수행 즉, 한 채널에 속해 있는 전체 이미지에 대해서 수행하는지 아니면 한 채널에 속해 있는 한 이미지에 대해서만 수행하는지의 차이이다
-> style transfer에서 가장 좋은 결과가 나왔기에 사용한다
-> style transfer에 사용한 adain을 사용하기에 style이라는 용어를 사용

- 확률적 다양성을 위해 노이즈를 featureMap에 비례하여 들어간다
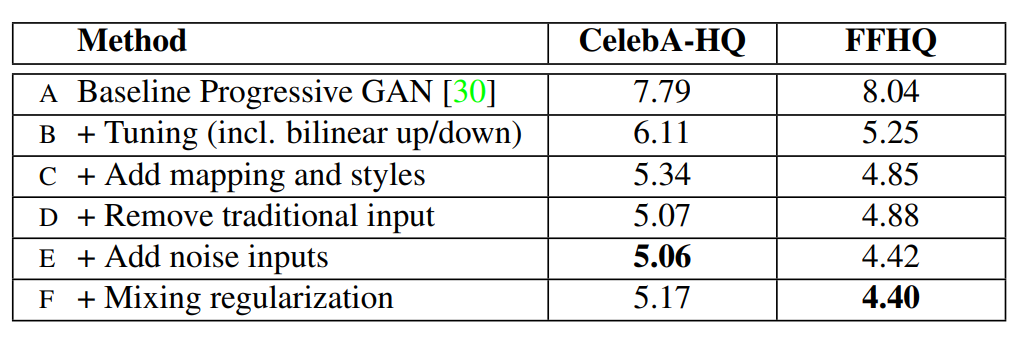
- 각각의 기능을 추가했을 때 성능 개선한걸 보여준다
- CelebA-HQ와 FFHQ는 고화질 얼굴 데이터 셋이다
Quality of generated images

- A는 PGGAN을 사용
- B는 보간의 메소드를 바꾸고, 오랜 트레이닝과 하이퍼파라미터 변경을 하여
- C는 MappingNetwork와 AdaIN을 추가하여 성능 개선
- D는 4x4x512 고정된 텐서에서 시작하여 latent를 레이어마다 입력

- E는 noise를 입력하여 mixing reqularization사용

- 모든 부분은 WGAN 로스함수를 사용해서 실험을 하였다

- truncation trick을 사용하였다
-> 샘플링할 때 그러한 이미지가 평균에 잘 나올 수 있도록 w latent벡터에 truncation 벡터를 적용 (좋은 결과를 뽑아야하는 경우 사용) - probably densty가 높은 부분에서 샘플링을 수행하면 더 좋은 결과 모든 이미지에서 수행하게 된다면 그렇지 않은것도 많이 나온다 그러므로 latent space에서 중간에 가까운 값이 될 수 있도록 잘라내어 사용하는 것
prior art

- 기존에서는 판별자에 초점을 뒀었는데 생성자에 초점을 둔 방법이 있었지만 본 논문과 같은 것은 없었다
Properties of the style-based generator

-
스타일의 특정 부분을 바꾸는 것은 이미지의 특정 양상을 바꾸는 영향을 끼친다
-> localization이라고 한다 -
Adain은 각각의 채널에 정규화를 수행하기 때문에 featureMap마다 정규화 수행 매번 convolution 연산 이후에 정규화를 하기에 서로 다른 특징을 나타내게 분리된다
-> 각각의 스타일은 하나의 convolution에 적용되고 Adain연산을 통해 덮어쓰기가 된다
Style mixing

- 지역화를 잘하기 위해서 사용
- 두개의 latent벡터가 있을 때 하나의 latent벡터만을 뽑아서 사용하는 것이 아니라 두개를 뽑아 섞어서(crossover Point) 사용
-> crossover point: 앞쪽 레이어는 w1 뒤쪽레이어 w2사용
즉, 두 벡터간 interpolation을 하는 것이 아닌 앞쪽레이어는 벡터1 뒤쪽은 벡터2를 쓰는 방식을 하여 인접한 스타일끼리 상관관계를 갖지 않도록 한다(그림 블록1, 블록2)

- interpolation이 아닌 mixing을 통해 source A와 B의 특정 latent 벡터를 뽑아서 사용
- Coarse style은 앞의 저해상도 레이어에서 부터 적용하기 때문에 큰 영향력을 끼친다 즉, 시멘틱한 영향을 끼친다
- middleStyle은 눈뜬 여부, 헤어스타일 등
- Fine style은 뒤쪽 레이어에서 사용되어 이미지의 색상에 적용
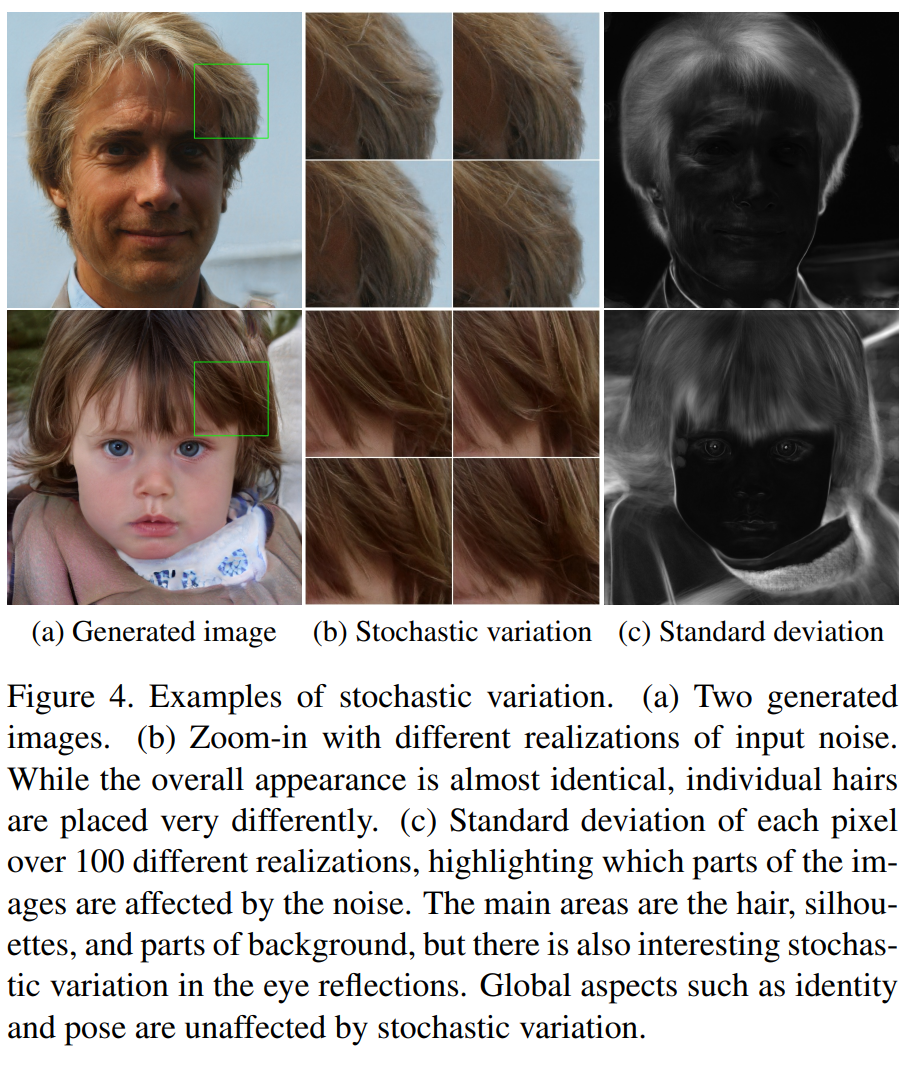
- noise벡터를 바꾼 결과 전반적으로 비슷하지만 머리카락의 위치같은 것이 다르다
- 스타일 정보가 같더라도 노이즈 정보는 매번 다르게 들어오게 하여 포즈나 아이덴티티는 확률적 변화에 영향을 끼치지 않는다

- 노이즈의 적용에 따라 변화를 보여준다
- a는 노이즈 적용 b는 노이즈 적용 x
- c는 fine layer적용 d는 coarselayer적용
- c는 작은 스케일에
- d는 큰 부분에 영향끼침

- 노이즈의 적용이 하이레벨에 영향을 끼치지 않고 적용이 가능하다
Separation of global effects from stochasticity

- 노이즈는 대수롭지 않은 확률적 변화에 영향을 끼친다
Disentanglement studies

- latent space가 여러개의 linear space로 구성됐을 때 disentangle하다고 한다
- linear하기에 두개의 벡터를 뽑아서 보간을 했을 때 의도한 부분만 바뀌게 할 수 있다
- 전통적인 방식은 정규분포에서 latent벡터를 뽑아서 분리하기 힘들었다
- W 벡터를 매핑한 후에 사용하여 disentangle하게 한다
-> w벡터는 고정된 분포에 따라서 샘플링 되지 않고 메핑 네트워크 f를 사용하기에 예기치 않은 entangle을 막을 수 있다
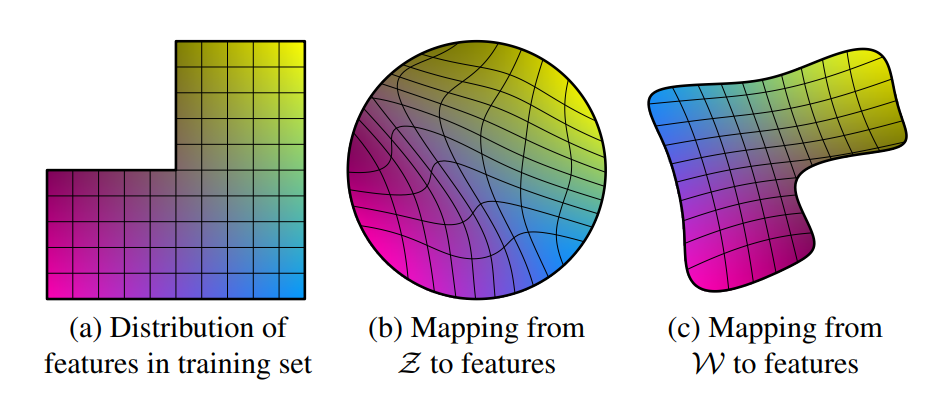
- 가우시안 분포(정규 분포)에서 뽑아 사용하면 메핑을 정규분포에서 뽑은 z에 맞추기에 entangle하게 된다
- b의 중간 부분을 보간하게 된다면 출력이 얽혀서 나올 수 있다
- c의 경우 w로 매핑을 하여 가우시안 분포에 따르지 않아도 되기에 disentangle하다
- 기존의 latent code자체를 입력으로 넣어 평가하는 것은 본 네트워크에 적용하기 힘들어 percpetual path length와 를 평가 지표로 사용
Perceptual path length

- 두개의 벡터를 보간할 때 급격하게 변화하지 않고 부드럽게 변화하는지 판단할 수 있다

-
z1과 z2를 보간할 때 얼마만큼의 비율로 수행할지를 t(0~1의 값)로 명시 얼마나 섞을지 명시
-
e(작은 값)를 통해 바로 근처를 뽑아 서로의 perceptual거리를 계산하여 얼마만큼 feature상에 변화가 있었는지 판단
즉, 값이 작으면 급격한 변화가 없다(이상한 이미지로 변화할 확률 적다)

-
latent 벡터 z는 가우시안(정규분포)에서 샘플링 하기에 보간할 때 spherical interpolation(구면을 사용하여 중간값을 찾을 수 있게) 사용

- w는 선형 보간을 사용
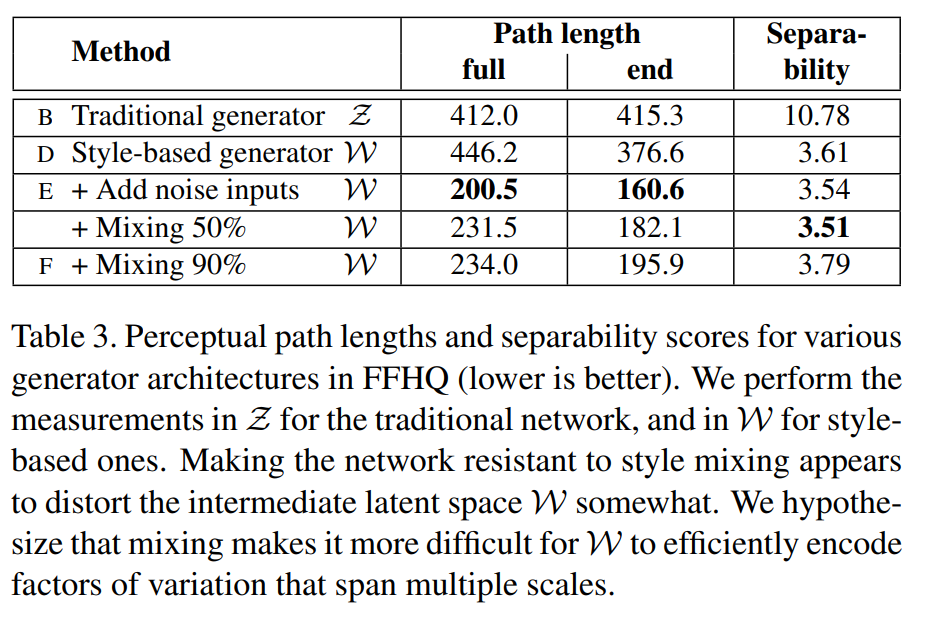
- w로 매핑 했을 때 더 좋은 결과
- Mixing을 했을때 어느정도 왜곡이 생길 수 있어 값이 크게 나온다
Linear separability

- 선형 분류기를 학습시키고 엔트로피를 계산하여 latent 벡터가 얼마나 선형적인 위치에 있는지 확인
- 판단하기 위해 보조네트워크를 사용했는데 학습에 CelebA-HQ데이터 셋을 사용
- CelebA-HQ는 남성인지 여성인지 웃고있는지 웃고있지 않은지 등 binary한 정보를 40개 가지고 있다
-> 이 binary한 정보를 가지고 선형 분류기가 학습되었다 - confidence를 제거하여 각각의 특징을 많이 가지고 있는 이미지를 사용하여
1시간30분 부터
