YOLO란
- You only Look Once
이미지 전체를 단 한번만 본다 - Unified
통합된 모델을 사용한다
다른 객체 탐지 모델은 다양한 전처리 모델과 인공 신경망을 결합해서 사용, YOLO는 단 하나의 인공신경망에서 전부 처리 - Real-time 객체탐지
기존의 Fast R-CNN 0.5FPS비해 YOLO는 45FPS처리
Introduction
- 단일 신경망 구조이기 때문에 구성이 단순하며 빠르다.
- 주변 정보까지 학습하며 이미지 전체를 처리하기 때문에 background error작다.
- 훈련 단계에서 보지 못한 새로운 이미지에 대해서도 검출 정확도가 높다
- 단, YOLO는 SOTA객체 검출 모델에 비해 정확도(mAP)가 다소 떨어진다
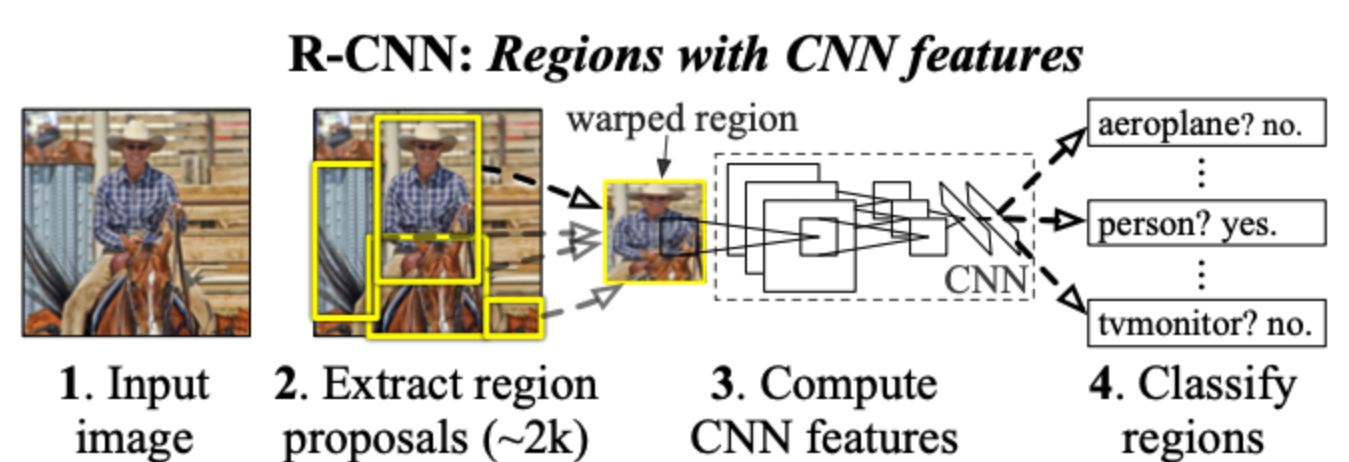
1. 먼저 이미지가 주어졌을 때 선택적 탐색 알고리즘 이용해 2000개의 리전을 생성하여 서브-이미지를 추출
2. 추출한 서브-이미지들은 매우 큰 합성곱 신경망(CNN)을 통과하여 특징을 추출하고 추출된 특징은 서포트 백터 머신(SVM)을 통해 각 리전별로 클래스 분류한다.
- R-CNN입력값으로 주어지는 건 이미지 하나지만 CNN을 통과하는 건 2000개의 서브-이미지이다. 즉 2000개 지난다
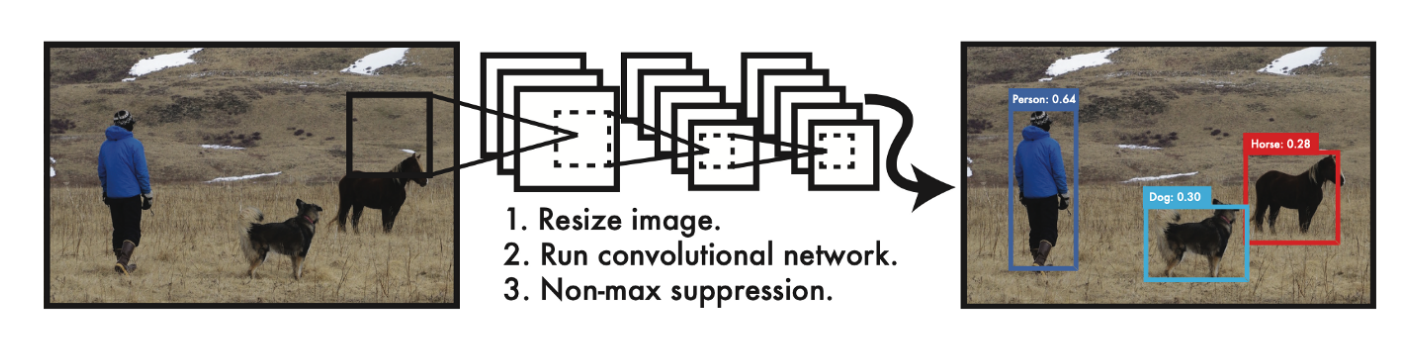
- R-CNN과 달리 합성곱 신경망을 단 한 번 통과시킨다
- 신경망의 결과로는 각 객체의 바운딩 박스와 해당 객체가 무엇인지 분류 확률을 출력한다.
논문에서는 이미지를 7x7 그리드 셀로 나눈다. 이렇게 나눈 그리드 셀 중 물체의 중앙과 가까운 셀이 객체를 탐지하는 역할을 한다.
각 셀은 바운딩 박스 B와 분류한 클래스의 확률인 C를 예측
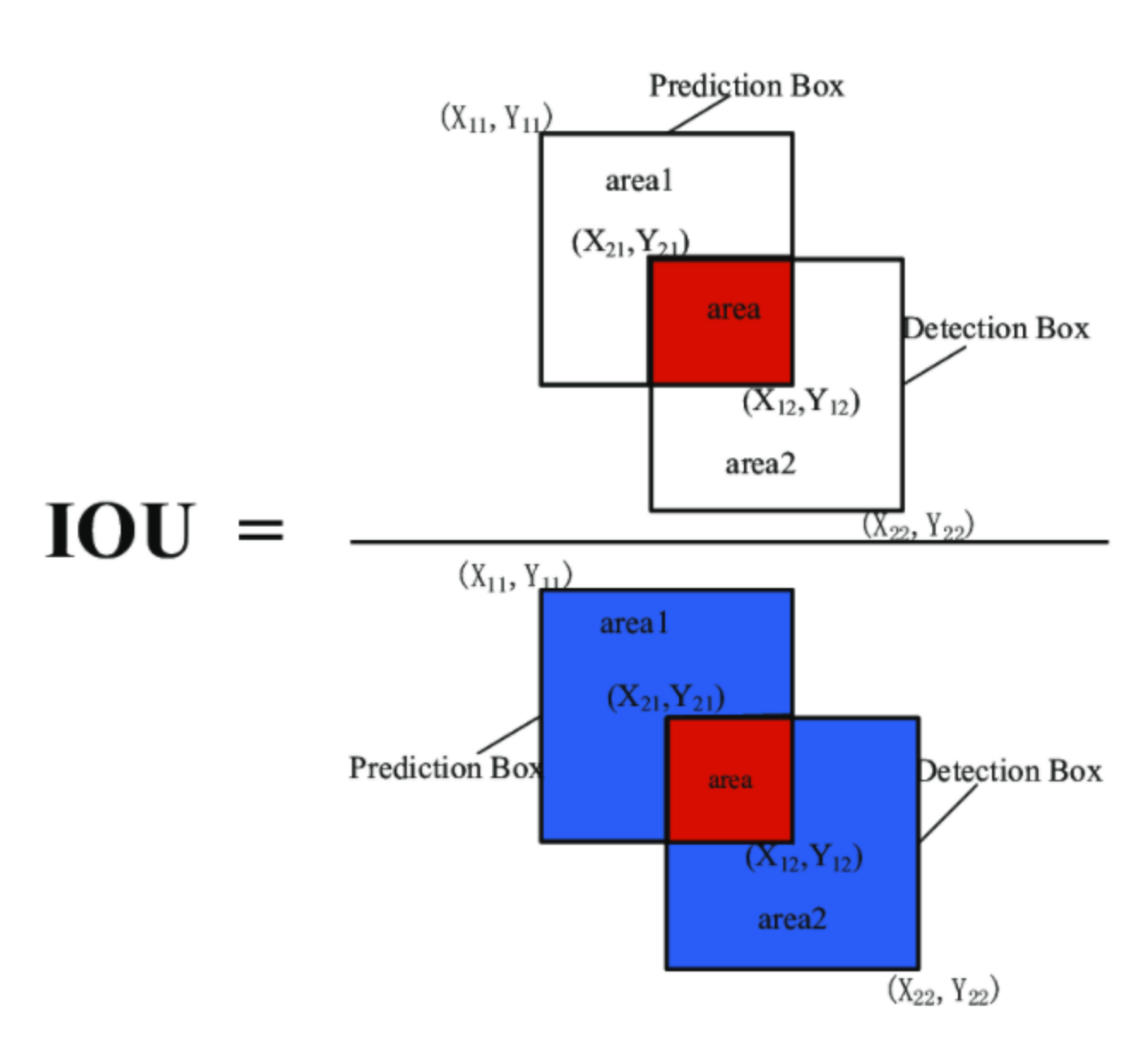
- 바운딩박스B는 x,y좌표, 가로, 세로 크기 정보와 Confidence Score(Score은 B가 물체를 영역으로 잡고 있는지와 클래스를 잘 예측했는지)수치를 가지고 있다.
- Pr(Object)xIOU인데 Pr(Object)는 바운딩 박스 안에 물체가 존재할 확률이다.(만약 배경을 잡게된다면 Pr(Object)는 0이므로 Score은 0이다)
- IOU는 학습데이터의 바운딩 박스와 예측한 바운딩 박스가 일치하는 정도를 나타낸다
- 클래스 확률 C는 그리드 셀 안에 있는 그림의 분류 확률을 나타낸다 기호로는 Pr(Class_i|Object)로 표현하며 B가 배경이 아닌 객체를 포함하는 경우의 각 클래스의 조건부 확률

네트워크 구조
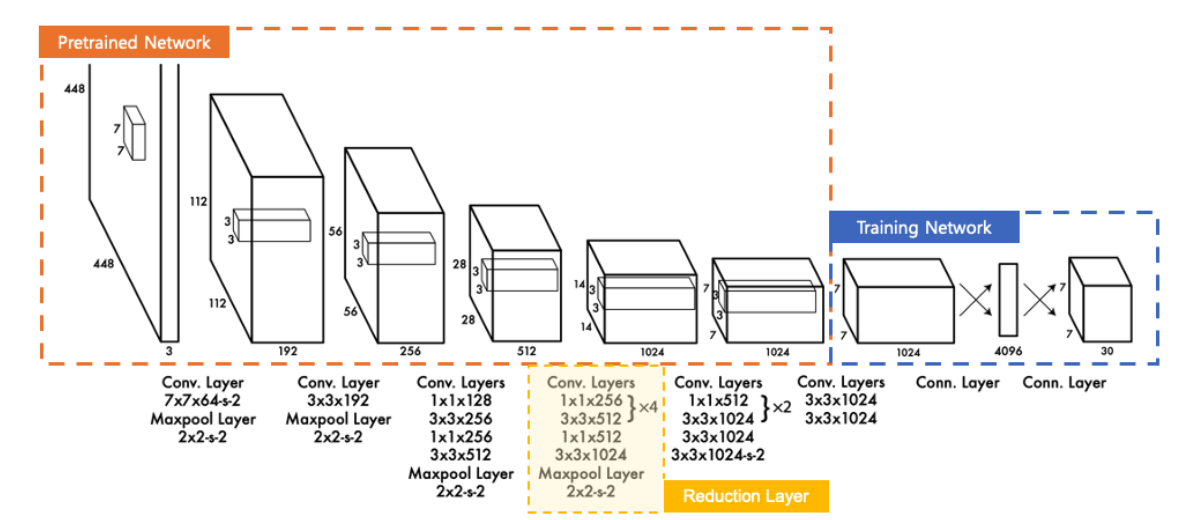
- 24개의 Convolutional Layer와 2개의 Fully-Connected Layer)로 연결된 구조를 사용
Pre-trained Network
- 주황색 테두리 20개의 Conv Layer로 구성
Reduction Layer
- 네트워크는 깊을 수록 더 많은 특징을 학습하기 때문에 정확도가 높아지는 경향이 있다
- 하지만 Conv Layer를 통과할 때 사용하는 Filter연산이 수행시간을 많이 잡아 먹기 때문에 쌓는데 부담이 된다.
- ResNet,GoogleNet기법 제안 오렌지색 테두리가 GoogleNet기법 응용하여 연산량을 감소하면서 층을 깊게 쌓는 방식 이용
Training Network
- 파란색 영역으로 Pre-trained Network에서 학습한 feature를 이용하여 Class probability와 Bounding box 학습하고 예측하는 네트워크이다
- 예측 모델은 SxS(Bx5+c)개의 파라미터 결과를 출력
PASCALVOC 데이터 셋은 20개의 클래스를 제공하기 때문에 C의 값 20
배경
- 기존의 Object Detection은 single window, regional proposal methods 등을 통해 바운딩 박스 잡은 후
탐지된 바운딩 박스에 대해 분류 수행하는 2stage방식- 파이프라인이 복잡 학습가 예측이 느려지고 최적화 느려짐
- YOLOv1은 하나의 컨볼루션 네트워크를 통해 대상의 위치와 클래스를 한번에 예측
- 학습 파이프라인이 기존의 detection 모델들에 비해 간단하기 때문에 학습과 예측의 속도가 빠르다
- 모든 학습 과정이 이미지 전체를 통해 일어나기 때문에 단일 대상의 특징뿐 아니라 이미지 전체의 맥락을 학습
- 대상의 일반적인 특징을 학습하기 때문에 다른 영역으로 확장에서도 뛰어난 성능 보임
모델 구조
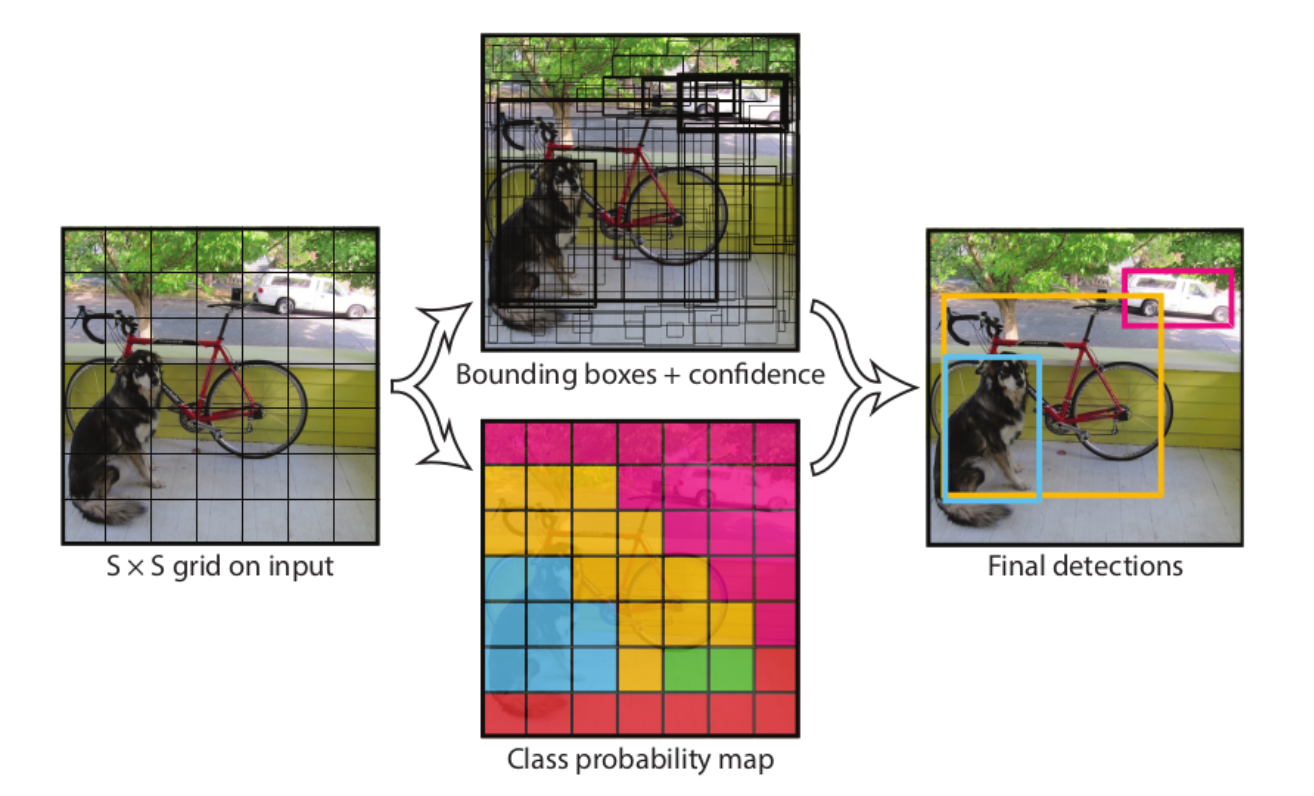
- Bounding Box Coordinate과 Classification를 동일 신경망 구조를 통해 실행하는 통합인식(Unified Detection)을 구현한다
- 이미지를 SXS의 그리드로 분할(논문에서 7x7)
- 이미지 전체를 신경망에 넣고 특징 추출을 통해 예측 텐서 생성
(예측 텐서는 그리드 별 테두리상자 정보, 신뢰 점수, 분류 클래스 확률포함) - 그리드 별 예측 정보를 바탕으로 테두리 상자 조정 및 분류 작업 수행
- 각각의 그리드 셀은 B개의 Bounding Box와 각 Bounding Box에 대한 Confidence-Score가진다 Pr(Object)xIOU
- 각각의 Grid cell은 C개의 Conditional Class Probability가진다
- 각각의 Bounding box는 x,y좌표 w,h,confidence를 가진다.
(x,y는 Bounding box중심점을 의미 grid cell범위에 대한 상대값)
Yolov1 Network
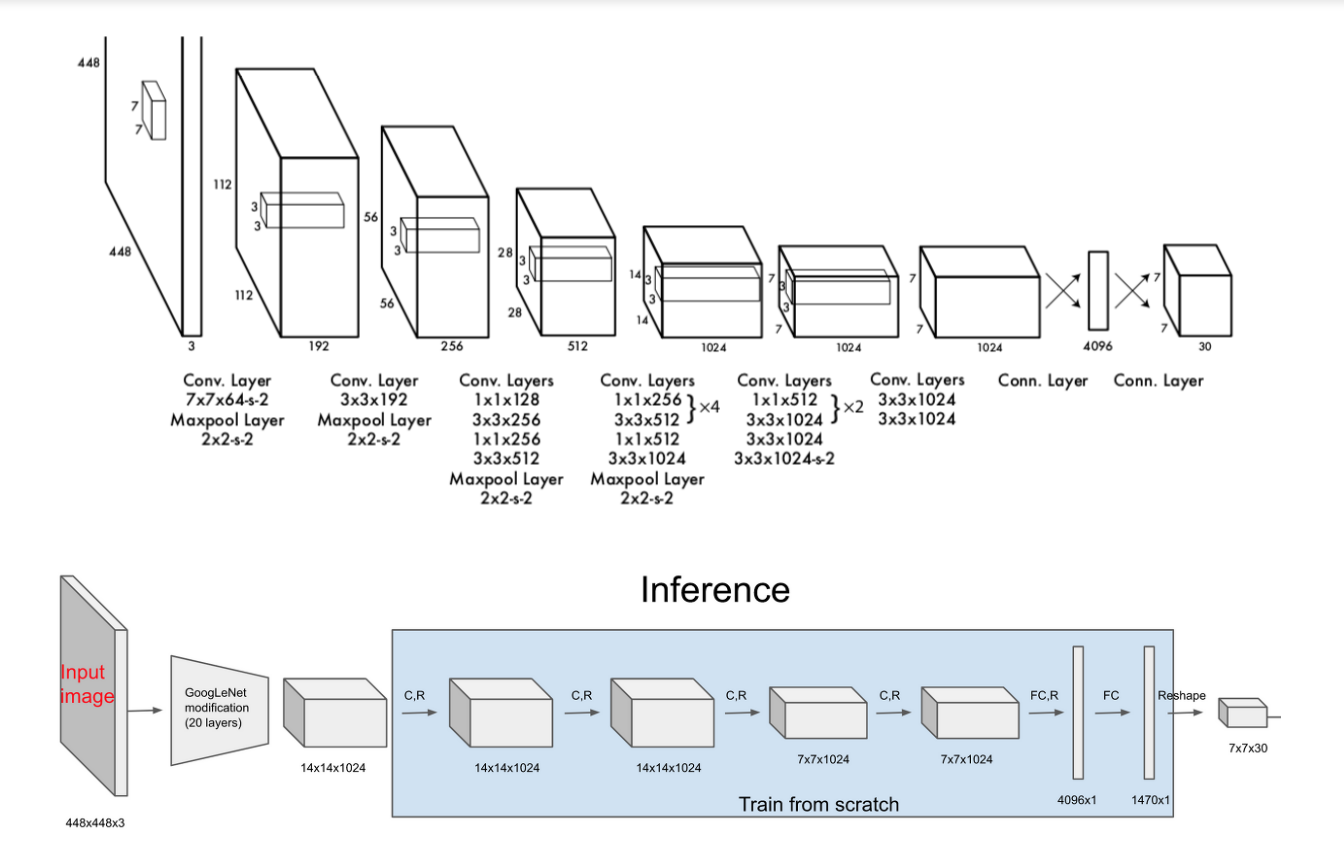
- Inception 블럭 대신 단순한 224x224 크기의 ImageNet Classification으로 pretrain을 진행했습니다.
이후 448x448 이미지를 input image로 받아 24개의 Conv Layer 중 앞의 20개의 컨볼루션 레이어는 고정한 채 뒷 단의 4개의 레이어와 2개의 Fully Connected Layer만 object detection task에 맞게 학습하게 됩니다.
이후 예측 텐서(Prediction Tensor)를 뽑아내게 됩니다. 이것을 바탕으로 디텍션 및 분류작업을 수행하게 됩니다.
Prediction Tensor(7x7x30)
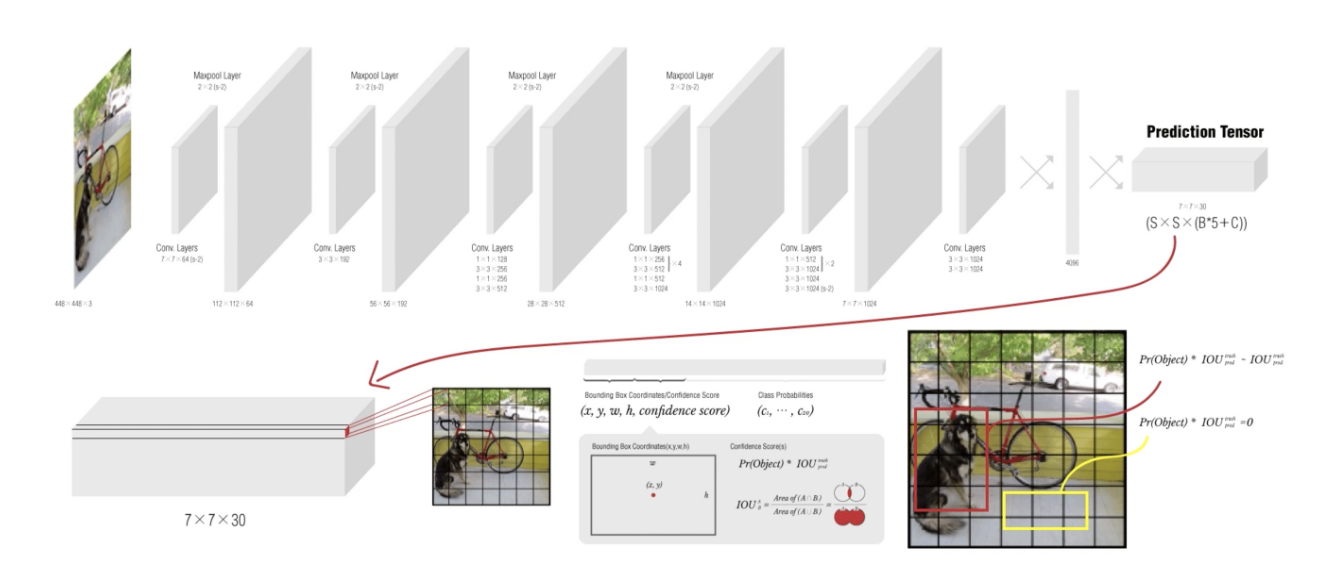
- Conv Layer, FC Layer통과한 Prediciton Tensor 피쳐맵이다
- R-CNN

안녕하세요