키워드와 식별자의 인식
키워드를 reserved(예약어)로 구별하지 않는다면?
해당 세션을 설명하기전에 키워드와 식별자의 차이가 무엇인지 가볍게 설명할 것이며, 위의 내용도 참고하는 것을 권장한다.
Identifier (식별자)
-
식별자는 프로그래머가 정의한 이름으로, 프로그램 내에서 변수, 함수 , 클래스, 객체 등을 고유하게 식별하는 데 사용되며, 그저 사용자가 정의한 이름이다 라고 볼 수 있다.
-
식별자는 미리 예약된 단어가 아니며, 코드 작성 시 직접 지정이 된다.
-
int x = 10에서x는 식별자 이다.
Keyword (키워드)
-
키워드는 프로그래밍 언어에서 미리 정의되고 예약된 단어로, 특정 기능이나 동작을 수행하는 데 사용 된다.
-
키워드는 프로그래머가 식별자로 사용할 수 없다.
-
int x = 10에서int는 키워드가 된다.
키워드와 식별자를 인식하는 것은 어떤 문제점을 일으킨다. 일반적으로 if 또는 else 과 같은 키워드는 예약어이다. 마치 식별자처럼 보일지라도 식별자는 아니다. 그렇다면 두가지의 전형적인 각각의 어휘항목을 찾기 위한 방법을 2가지 소개하겠다.
1. Symbol Table(심볼 테이블)에 처음부터 설치한다.
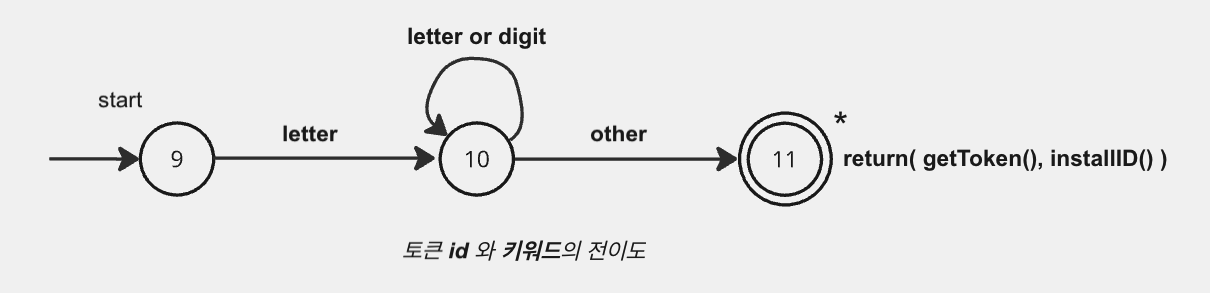
해당 그림은 정규 표현식 에서 등장한 𝑖𝑑 토큰 과 Keyword의 대한 전이도가 됩니다. 또한 전이도의 state 순서는 해당 전이도의 시각적 표현 에서 이어집니다.
심볼 테이블 항목의 어느 필드는 이 스트링이 결코 보통의 식별자가 아니고 어떤 토큰이라는 것을 나타내며 그 방법이 해당 전이도에서 사용되고 있다고 가정하겠다. 식별자를 발견할 때, installID에 대한 호출은 식별자가 심볼 테이블에 없다면 심볼 테이블에 놓고 발견된 어휘항목을 위한 심볼 테이블 항목에 대한 포인터를 반환한다. 물론 어휘 분석동안 테이블에 없는 식별자는 예약어일 수 없다. 따라서 해당 토큰은 id 가 된다.
함수 getToken은 발견된 어휘항목을 심볼 테이블에서 조사하고 이 어휘항목이 나타내는 토큰id 또는 테이블에 초기에 설정한 키워드 토큰 중 하나 을 반환한다.
구체적인 동작 과정은, 상태 9 에서 시작하여 어휘항목이 문자로 시작하는가를 검사하고 그렇다면 상태 10으로 간다. 입력 문자가 문자나 숫자인 동안은 상태 10에 머문다. 문자나 숫자가 아닌 다른 것을 보았을 때, 상태 11로 가서 발견한 어휘항목을 수락한다. 마지막 문자가 식별자의 일부가 아니므로 입력을 한 위치 뒤로 옮겨야 하고 발견한 것을 심볼 테이블에 넣고 키워드인지 또는 식별자인지를 결정한다.
[심볼테이블 -- 어휘분석기의 작동원리] 해당 페이지를 통해 실질적으로 어휘분석기가 심볼테이블을 사용하는 구조를 통해 식별자 토큰
id가 사용되는 개념을 알 수 있다. --> 수정 예정
2. 각 키워드에 대해서 별도의 전이도를 만든다.
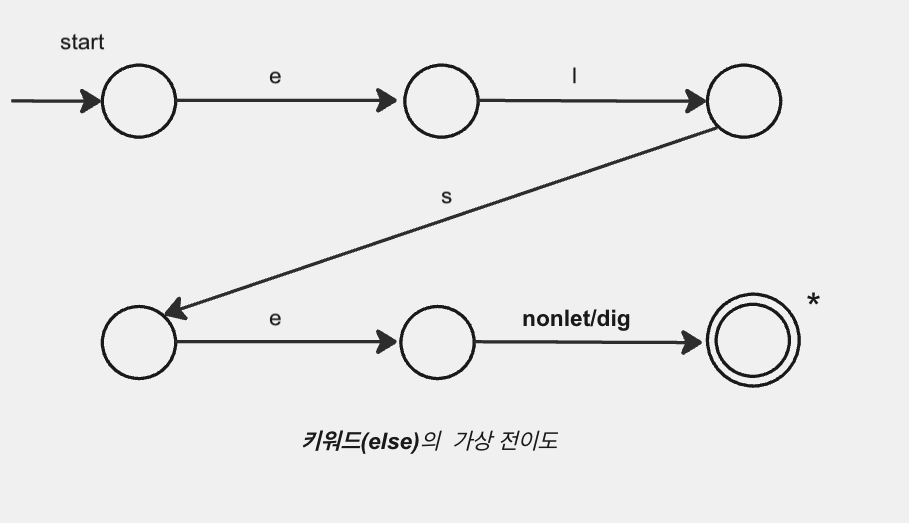
키워드 else 의 별도의 전이도를 이와 같은 그림으로 표현하였다. 이러한 전이도는 키워드의 각 연속된 문자를 본 후의 상황을 나타내는 상태. 비문자-또는-숫자(즉 식별자가 계속될 수 없는 문자)에 대한 테스트로 구성된다. 특히 식별자가 끝났다는 것을 검사하는 것이 필요하다. 그렇지 않으면 정확한 토큰이 반환되지 않을 수 있다.
id토큰에 해당되는elsewhere와 같은 어휘항목이 키워드의 일부분을 접두사로 가질때, 위 내용이 제대로 구성되지 않는다면 토큰else를 반환하게 될 것이다.
우리가 이런 접근 방법을 채택하여 어휘항목이 2가지 패턴에 부합할 때 예약어 토큰이 id에 유리하도록 인식할 수 있도록 토큰들에 우선순위를 정해야 한다. 나의 벨로그 문서에서는 이와 같은 접근 방법에 대해서는 다루지 않을 것이다.
두가지 접근 방법의 각 장단점
심볼 테이블 설치 방식
- 키워드는 심볼 테이블을 반드시 조회하여 확인하는 작업이 추가적으로 필요하다.
- 별도의 키워드 전이도는 만들지 않아도 된다.
- 심볼 테이블만 수정하면 쉽게 기술을 확장할 수 있으며 구현 자체도 심볼 테이블만 초기화 신경쓰면 되어서 단순하다.
독립적인 키워드 전이도 방식
- 각 키워드에 대한 전용 전이도가 모두 필요해진다.
- 새로운 키워드 추가 시 전반적인 전이도 설계를 확인할 필요가 있으며, 구현 시 키워드 전이도에 대한 설계와 관리가 필요하다.
- 전이도를 사용하기에 키워드 확인이 심볼 테이블 설치 방식보다 빠르게 확인 가능하다.
두가지 접근 방법의 대한 선택은, 구현하려는 컴파일러의 성능 요구사항과 키워드 복잡성에 따라 심볼 테이블 방식 또는 전이도 방식을 선택할 수 있다.
하지만 심볼 테이블에 키워드를 설치하는 방식에서 별도의 키워드 전이도가 필요하지 않으며, 모든 단어는 일반 식별자 전이도를 통해 처리되며, 키워드 여부는 심볼 테이블 조회를 통해 결정되는 전자의 방식이 구현이 단순하고 확장성이 후자보다 훨씬 뛰어나 주로 선택된다.
실제 실행 예제의 완성
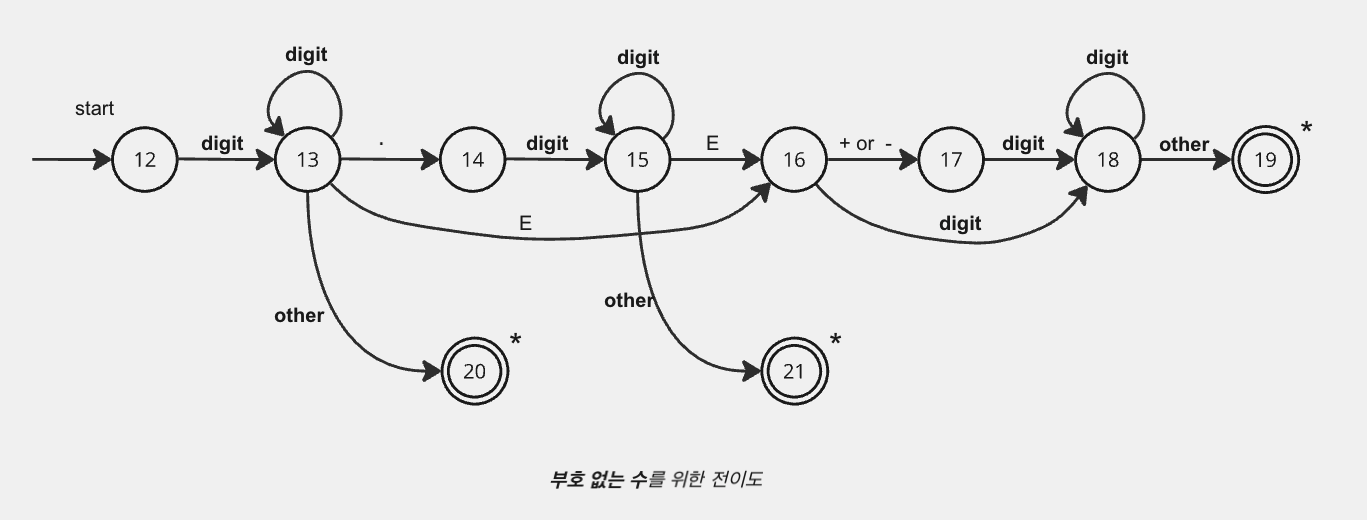
지금까지 보여진 전이도와는 다른 가장 복잡한 형태의 전이도이다. 해당 그림은 토큰 number를 위한 전이도이다. 상태 12에서 시작하여 숫자를 본다면 상태 13으로 간다. 상태 13에서 임의의 숫자를 반복적으로 읽을 수 있다. 그러나 숫자,소수점 또는 E이외의 다른 것을 본다면 정수 형태의 수를 읽은 것이다.
123, 456, 5432, 12345678 과 같은 숫자는 상태 20으로 전이하며 토큰 number 와 상수 테이블에 대한 포인터가 반환된다.
대신에 상태 13에서 소수점을 본다면 소수를 얻게 되며 상태 14로 들어가게 된다. 상태 14로 들어가서 1개 이상의 부가적인 숫자를 찾는다. 상태 15가 이러한 목적으로 사용 된다. 만약 E를 본다면, 지수를 얻는다. 지수의 인식은 상태 16에서 상태 19까지 이루어진다. 상태 15에서 만약 E 또는 숫자 이외의 다른 것을 본다면 소수 끝에 도달 한 것이고 발견한 어휘항목은 상태 21을 통해서 반환한다.
여백을 위한 전이도
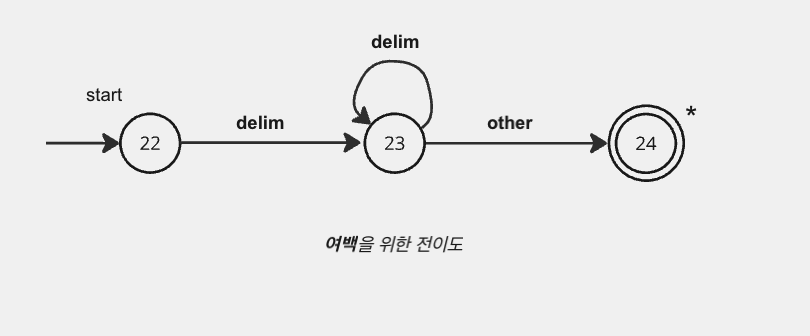
마지막 전이도는 여백을 위한 전이도이다. 이 전이도에서는 1개 이상의 여백을 찾는다. 여백은 전형적으로 공백,탭,새줄 문자와 언어 설계에 의해서 토큰의 일부로 생각되어지지 않는 일부 문자들이다.
상태 24에서 연속적인 여백 문자가 찾아졌고 비여백문자가 따른다는 것에도 유의하여야 한다. 비여백 문자에서 시작하도록 입력을 뒤로 물리지만, 파서에 아무것도 반환하지 않는다. 오히려 여백문자를 발견한 후에 어휘 분석기를 재시작하여야 한다.
어휘 분석기의 관점에서 여백 문자는 의미 있는 토큰을 반환하지 않으므로, 이를 처리한 후 다음 유효한 문자를 새롭게 분석하기 위해 초기 상태로 돌아가는 동작(재시작)이 필요합니다.
