0. Background
- 기존의 Supervised Learning은 양질의 label 정보를 충분히 가지고 있는 데이터를 사용해야만 최적의 model을 만들 수 있었음.
- 양질의 데이터 및 label 정보를 얻는 것은 시간과 돈이 많이 필요함.
- 이러한 문제를 극복하기 위해 데이터에서 얻을 수 있는 정보를 사용해서 자체적인 label을 얻기 위해 고안된 방법이 Self-Supervised Learning
- Self-Supervised Learning 은 딥러닝 분야에서 최근 가장 핫한 토픽 중 하나
- Self-Supervised Learning은 그 자체로 분류 및 예측 task의 정확도를 높이는 것이 목적이 아님. Backbone 모델에서 더 좋은 representation(feature)을 학습하고 추출할 수 있도록 하여 차후 task에서 성능을 올리는 것이 목적.
- 이를 위한 초기 연구들은 보통 Jigsaw Puzzle나 Rotation 등의 간단한 Pretext Task를 직접 선정하여 backbone 모델을 학습시키는 것이었음.
- 최근 Self-Supervised Learning 연구 동향은 Pretext Task 없이 Contrastive Learning을 통해 학습하는 것
Backbone 모델
- 이미지의 feature를 추출하는 기본 신경망 구조
- SimCLR에서는 ResNet-50이 backbone으로 사용
representation(feature)
- backbone (예: ResNet)으로부터 나온 feature를 representation이라고도 부름
- SimCLR에서는 실제로 feature를 z가 아닌 h로 사용
task
모델이 해결하려는 실제 문제
pretext task
사전 학습용 인위적인 문제
Contrastive Learning(대조 학습)
-
학습 데이터의 쌍(pair) 사이의 관계를 학습해서 feature space 상의 구조를 정렬하는 방식
-
입력 데이터 쌍 (x₁, x₂)을 만들어서
같은 클래스를 나타내는 쌍이면 → 가까워지게
다른 클래스를 나타내는 쌍이면 → 멀어지게
1. Introduction
-
Representation을 학습한다는 것은 쉽게 말해, 인간의 간섭 없이 모델이 스스로 task에 적합한 feature들을 알아낸다는 것
-
학습과정에서 data augmentation과의 차이를 학습하고 embedding layer를 깊게 쌓음으로써 유사도를 비교하는 공간인 feature space를 더 개선하여 image representation 학습 성능을 크게 향상 시키는 데에 기여
-
중요한 사항
- 간단한 몇 개의 Data augmentation 조합이 SimCLR 구조에서 중요한 역할을 함
- Representation과 Contrastive loss 사이의 non-linear transformation이 representation 성능을 향상 -> ResNet이 뽑은 feature (representation)를 바로 contrastive loss에 넣는 것보다,
한 번 비선형 함수(MLP 등)를 거쳐서 넣는 게 feature 성능이 더 좋다 - Contrastive learning은 batch size와 training step(또는 epoch)이 클 때 효과적임
embedding
원본 데이터를 수치화된 의미 공간으로 매핑하는 과정
Contrastive loss
비슷한 쌍은 가깝게, 다른 쌍은 멀게” 학습하기 위한 손실 함수
SimCLR에서는 NT-Xent (Normalized Temperature-scaled Cross Entropy) Loss를 사용
2. Method
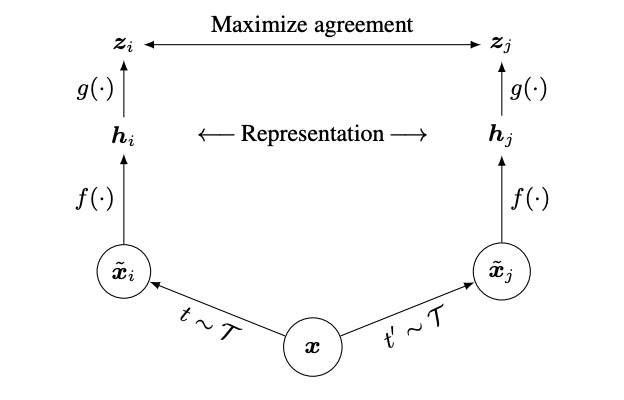
SimCLR contrastive learning의 전체 framework를 나타내는 그림
T : Data augmentation 종류 (RandomResizeCrop, Random Color distortion, Gaussian Blur)
t,t′ : Random sampling된 Data augmentation 기법
xi,xj : Augmentation된 이미지
f(⋅) : Base Encoder (ResNet-50)
hi,hj : ResNet-50 output에서 Global Average Pooling(GAP) 된 vector
- feature map은 3차원 (7×7 공간, 2048 채널)이라서 classifier나 projection head에 넣기 어려움
- GAP : 각 채널마다 공간 평균을 내서 1개의 숫자로 줄이는 연산
즉, [7×7×2048] → [1×1×2048] → 2048차원 벡터로 압축
g(⋅) : non-linear representation을 적용하는 Projection head (Two-layer MLP)
zi,zj : Projection head 통과 후 생성된 vector
Contrastive loss function : zi,zj간의 NT-Xent Loss
2-1. Training
Training
- Batch size: 256 ~ 8192
- LARS optimizer 사용 : 많은 Batch size 학습을 감당하기 위해
- Aggregating BN mean and variance over all devices -> 멀티 GPU 학습 중에 BatchNorm(BN)의 평균과 분산을 GPU 전체에서 모아서 계산
Dataset
- ImageNet 2012
Evaluation
- Linear Evaluation Protocol : representation까지의 parameter를 freeze하고 linear layer 하나만 추가하여 supervised learning, evaluation 진행
-> self-supervised로 학습된 feature extractor(=Backbone)는 고정(freeze)시키고,
그 위에 Linear classifier 하나만 붙여서 supervised task (예: 분류)를 수행해보는 평가 방법
Layer, classifier?
Layer
- 딥러닝 모델을 구성하는 기본적인 구성요소
ex) Linear layer ,Convolutional layer, ReLU, BatchNorm, Dropout 등 - 모든 classifier는 layer
classifier
- 모델의 맨 끝에 위치해서 입력된 feature를 class로 구분하는 역할
- 보통은 Linear layer + softmax 조합으로 이루어짐
- 모든 layer가 classifier는 아님
3. Data Augmentation for Contrastive Representation Learning

간단한 몇 개로 구성된 Data Augmentation 기법 선택이 매우 중요했다고 함
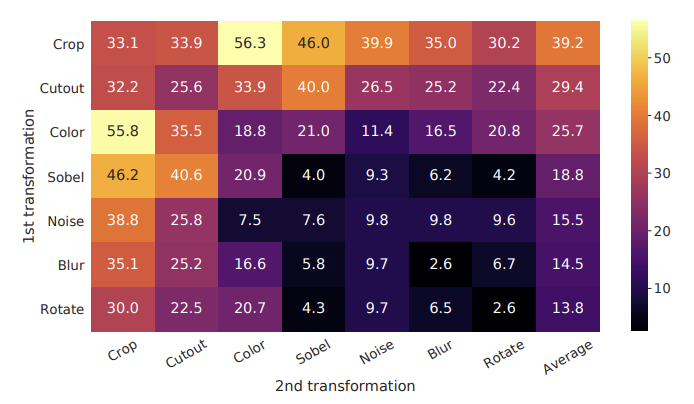
Random cropping, Random color distortion, Gaussian blur 만을 사용하였을 때 가장 성능이 좋음
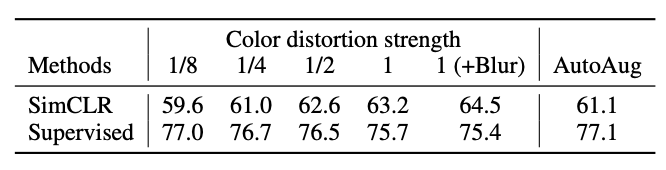
색상 왜곡 강도를 높일수록 정확도가 증가 + Gaussian blur를 추가했을때 가장 높은 성능을 보였음 -> Contrastive learning에서는 강한 색상 변형이 매우 중요
4.Architectures for Encoder and Head
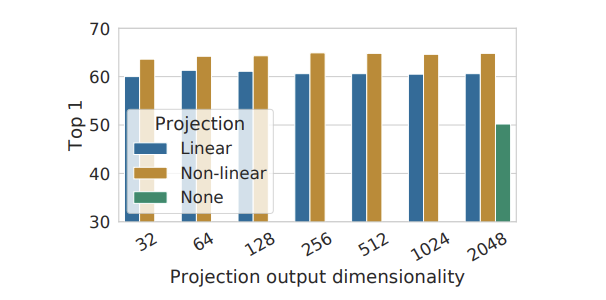
Non-linear projection head > linear projection head > None
5. Loss Function and Batch Size

Loss Function 중 NT-Xent (Normalized Temperature-scaled Cross Entropy)의 성능이 가장 높았음
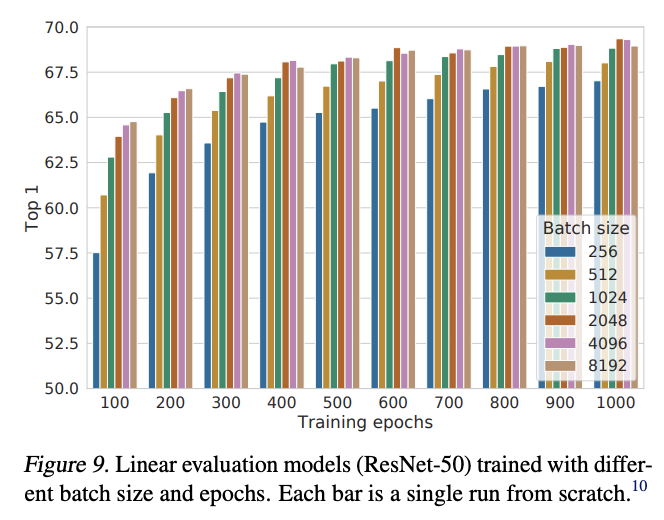
Batch Size를 매우 키우는 것이 더 좋은 성능을 보이고 있다. 이는 batch size를 매우 늘릴 경우 그 안에서 충분한 양의 negative sample을 뽑을 수 있기 때문이라고 추론해 볼 수 있다.
6. Comparison with State-of-the-art
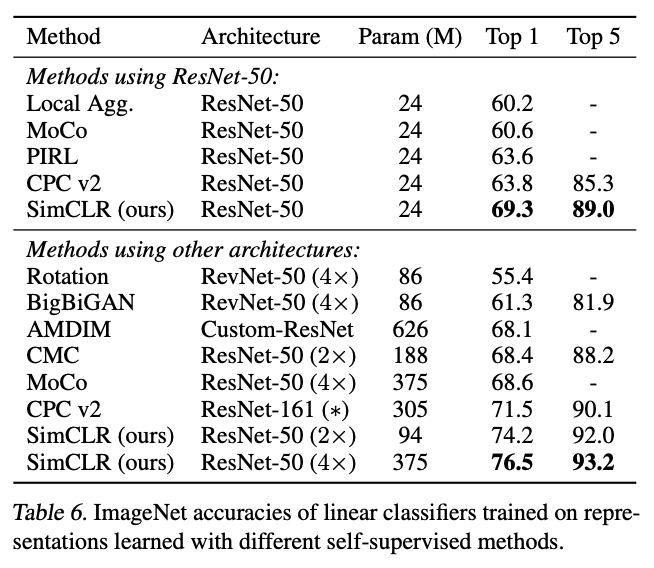
여러 Self-Supervised model과의 Linear evaluation 결과를 비교하였을 때, Architecture 별로 ResNet-50을 사용한 결과와 더 깊은 구조를 사용했을 때의 결과 모두 SimCLR에서 가장 뛰어난 성능을 보인다.
Self-supervised 외에 transfer learning, semi-supervsied learning에 대한 실험에서도 우수한 성능을 보이고 있다.
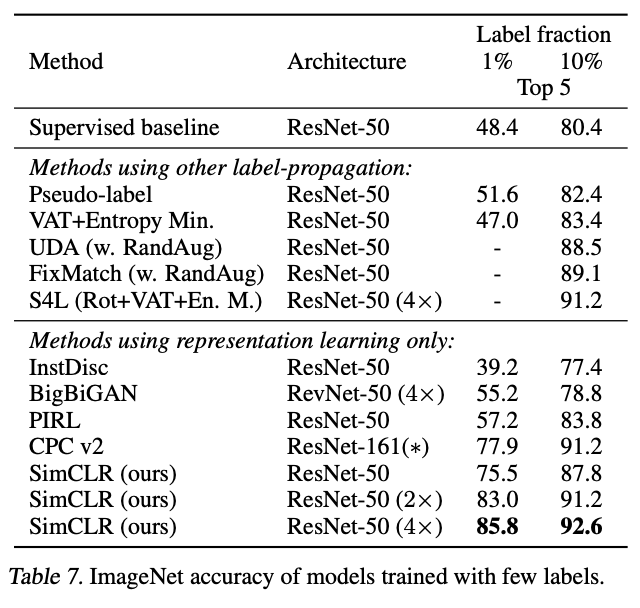
Semi-supervised learning에 대한 실험 결과
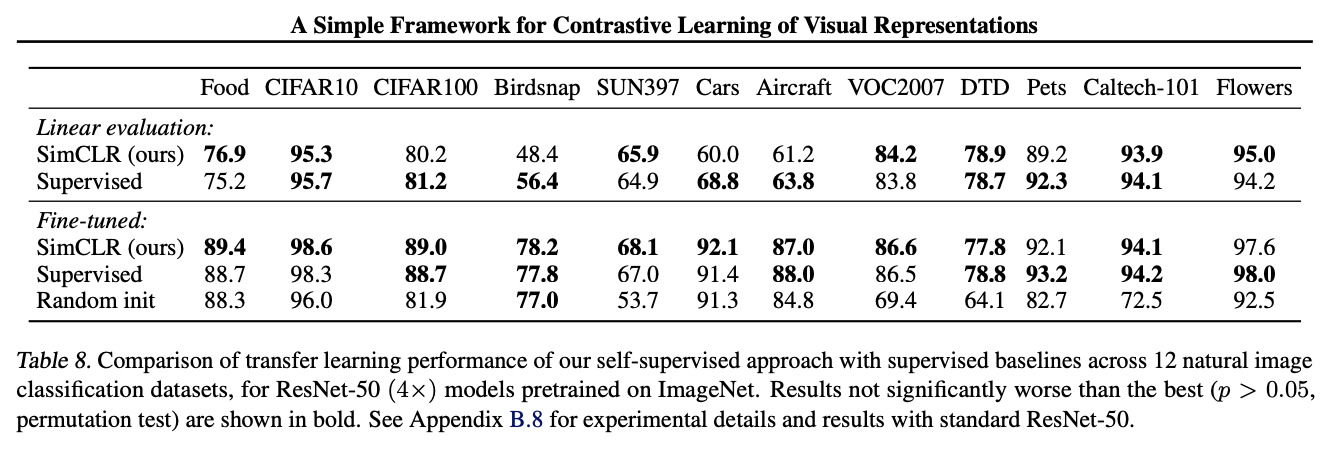
Transfer learning에 대한 실험 결과
7. Related Work
Handcrafted pretext tasks
Contrastive visual representation learning
8. Conclusion
Self-supervised Learning Simple framework로 Self-supervised learning, Semi-supervised learning, Transfer learning의 성능을 크게 개선하였다.
Supervised learning과는 다른 augmentation과 non-linear projection head를 제안하였다.
Representation을 학습하는 것으로 Supervised learning 수준의 성능을 달성하였다.
기존의 Pretext task를 활용하지 않고 Memory Bank 또한 필요로 하지 않는다.
