Self Pre-training with Masked Autoencoders for Medical Image Classification and Segmentation
논문정리
1. ABSTRACT
-
MAE (Masked Autoencoder)는 ViT(Vision Transformer) 사전학습에 효과적임.
-
MAE는 부분적으로 마스킹된 이미지를 입력으로 받아 전체 이미지를 복원 → 문맥 집약 능력(context aggregation ability)이 생김.
의료 영상은 해부학적 구조들이 긴밀히 연결되어 있어 문맥 집약 능력이 특히 중요. -
ImageNet 규모의 의료 영상 데이터셋 부재 → 제안: Self Pre-training (목표 데이터셋(target dataset)의 학습용 데이터 위에서 ViT를 사전 학습).
결과: Self Pre-training으로 X-ray 분류, CT 다장기 분할, MRI 뇌종양 분할 모두 성능 향상.
MAE (Masked Autoencoder)
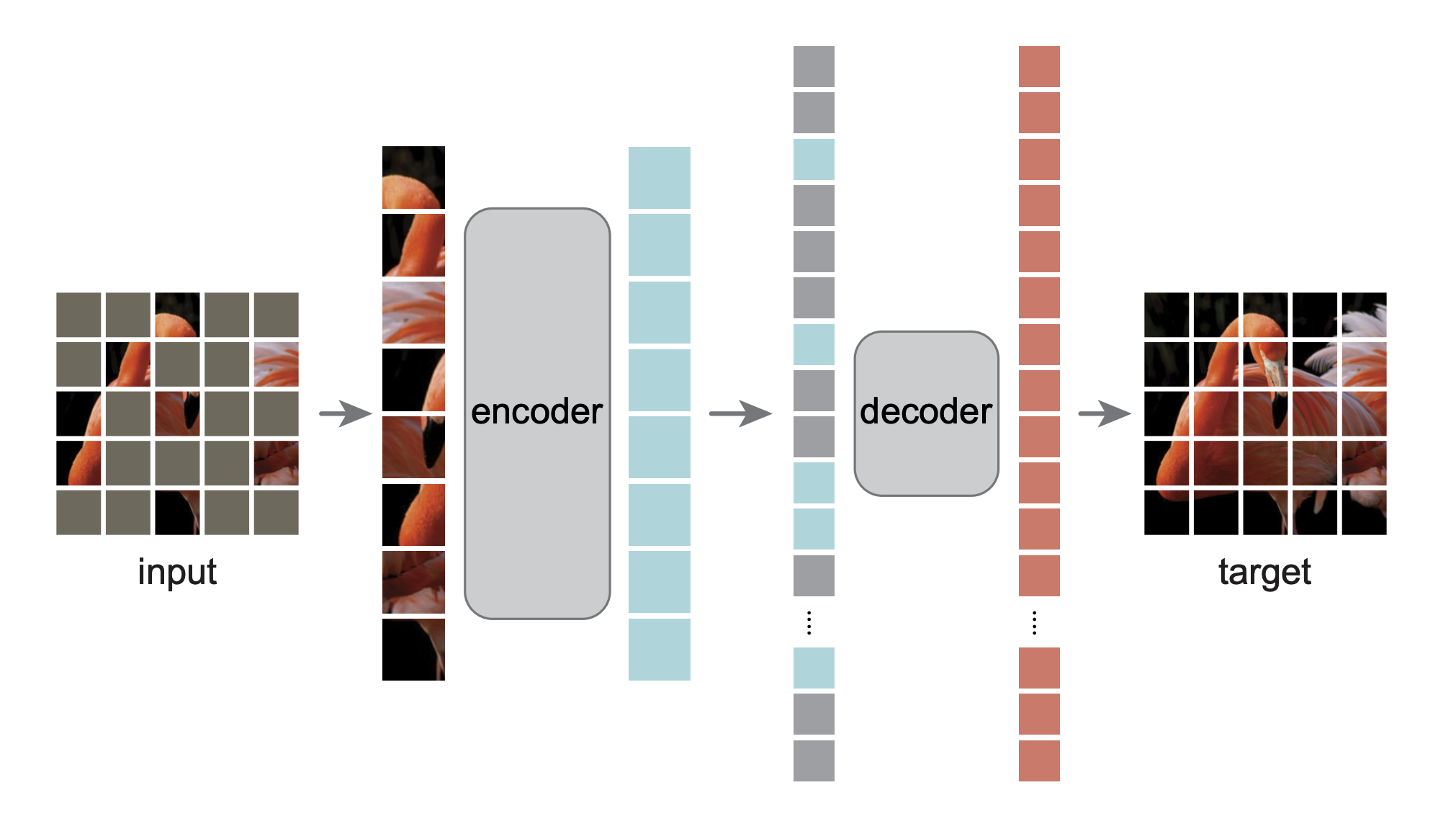
-
입력 이미지 (Input)
원본 이미지를 작은 패치(patch)로 나눕니다.
이 패치 중 일부는 마스킹 처리됩니다. -
인코더 (Encoder)
마스킹되지 않은 패치들만 Transformer 기반 인코더에 입력.
인코더는 이 패치들을 잠재 표현(latent representation)으로 변환합니다. -
디코더 (Decoder)
디코더는 전체 패치(마스킹된 부분 포함)를 입력받아 원래 이미지를 복원하려고 시도. -
출력 (Target)
디코더가 복원한 이미지를 원본 이미지와 비교하여 복원 손실(reconstruction loss)을 계산.
이 과정을 통해 모델은 이미지의 전역적 문맥을 학습합니다.
ViT(Vision Transformer)
- 이미지 처리에 Transformer 구조를 적용한 모델
- ViT는 사전학습이 중요하다
- ViT는 CNN과 달리 로컬 패턴(예: 엣지, 텍스처)을 자연스럽게 학습하지 못함.
- 따라서 대규모 데이터에서 사전학습(pretraining)을 해야 좋은 성능을 냅니다.
- 사전학습 후, 다운스트림 작업(분류, 탐지 등)에 파인튜닝(finetuning)을 합니다.
- MAE는 ViT 사전학습에 적합한 이유
- MAE는 ViT 구조를 그대로 사용합니다. (패치 분할 → Transformer 인코더)
- 학습 목표는 마스킹된 이미지 복원 → 이미지의 전역적(global) 문맥을 이해해야 함.
- 이 과정에서 ViT는 풍부한 시각적 표현을 학습하게 됩니다.
라벨이 필요 없으므로 대규모 비라벨 데이터로 학습 가능 → 강력한 사전학습 효과.
- 효과
- MAE로 사전학습한 ViT는 ImageNet 분류, 객체 탐지, 세그멘테이션 등에서 성능이 크게 향상.
- 특히 라벨이 부족한 상황에서 매우 유리.
2. INTRODUCTION
분할(segmentation)의 경우, 목표 대상의 고유한 특징뿐 아니라 주변 조직의 특징 역시 특정 구조를 구분하는 데 도움이 된다.
예를 들어, 뇌종양이 존재하면 주변 미세환경에서도 부종, 뇌 조직의 구조적 변화, 혈관화 증가 등의 추가적인 변화가 발생한다.
이 논문에서는 문맥 정보 학습에 대한 엄격한 요구 조건을 부여하는 것이 딥러닝 기반 의료 영상 분석의 성능을 향상시킬 수 있다고 가정
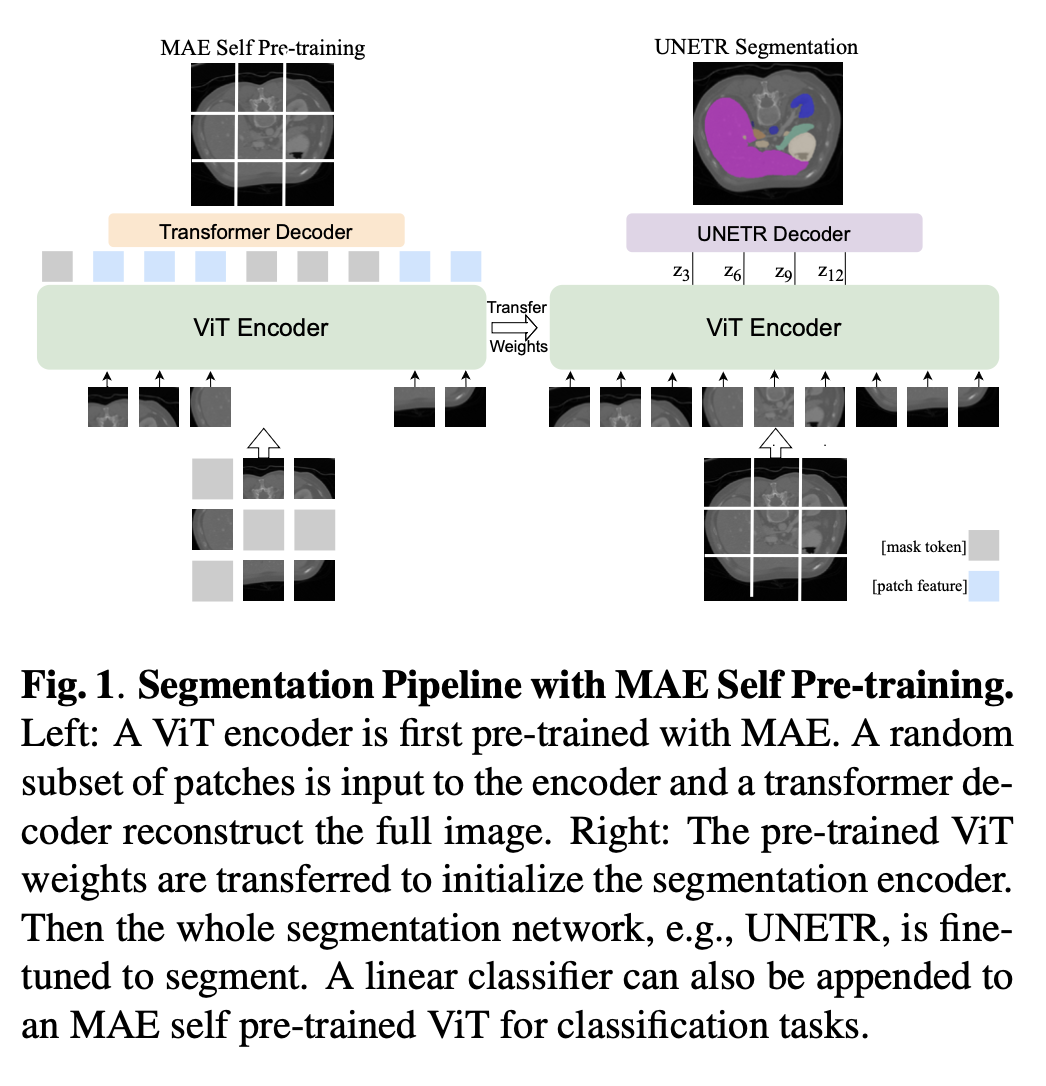
MAE Self Pre-training
- 입력 이미지 분할
- CT/MRI 이미지를 여러 개의 작은 패치로 나눔.
- 일부 패치는 mask 처리(회색 블록) 되어 encoder에는 입력되지 않음.
- ViT Encoder
- 보이는 패치만 입력으로 받아 전체 문맥(Context)을 학습.
- Encoder는 이미지의 전반적인 구조적 관계를 이해하는 표현(representation)을 학습.
- Transformer Decoder
- Encoder 출력 + mask token을 받아 마스킹된 영역을 복원(reconstruction).
- 이 과정에서 Encoder가 “부분만 보고 전체를 이해하는 능력”을 얻게 됨.
UNETR Segmentation 단계
- 사전학습된 ViT Encoder 활용
- 앞서 MAE로 학습한 Encoder weight를 segmentation 모델의 backbone으로 가져옴.
- 즉, Encoder는 이미 “의료 영상의 문맥적 특징”을 잘 파악할 수 있는 상태임.
- UNETR Decoder 연결
- ViT Encoder의 여러 단계 출력(z3, z6, z9, z12)을 U-Net처럼 skip connection 구조에 연결.
- Decoder가 이를 이용해 segmentation 맵을 생성.
- Fine-tuning
- 전체 네트워크(Encoder + Decoder)를 segmentation 데이터셋에서 파인튜닝.
- 이렇게 하면 초기부터 좋은 표현으로 시작하기 때문에 학습 효율과 성능이 개선됨.
요약:
이 그림은 1단계(마스크 복원 Self Pre-training) → 2단계(Segmentation Fine-tuning)의 전체 파이프라인을 보여줍니다.
- Pre-training: MAE로 “문맥 기반 표현” 학습.
- Downstream task: 해당 Encoder를 가져와 segmentation 또는 classification 수행.
정리
-
의료 영상 분석은 주변 구조와의 관계까지 고려해야 정확도 향상 가능.
예: 흉부 X-ray에서 폐 질환 분류 시 심장·종격동의 변화도 참고 필요. -
종양 분할 시 주변 부종, 구조 변형, 혈관화 증가 등이 단서가 됨.
-
최근 Self-Supervised Learning (SSL) 발전 → Masked Image Modeling (MIM) 전략이 ViT 학습에 효과적임.
MAE는 단순하면서도 효과적인 MIM 방법. -
본 연구 목표
MAE 기반 self pre-training 패러다임을 의료 영상 분석에 제안 -> MAE 사전학습을 다운스트림 과제와 동일한 데이터셋의 학습(train) 세트에서 수행 = Self pre-training
Self pre-training은 적절한 사전학습용 데이터를 구하기 어려운 다양한 상황에서 유용할 수 있으며, 사전학습과 파인튜닝 간의 데이터 불일치(domain discrepancy) 문제를 피할 수 있다.
세 과제에 적용
1. 흉부 X-ray 질환 분류 (CXR14 데이터셋)
2. CT 다장기 분할 (BTCV 데이터셋)
3. MRI 뇌종양 분할 (BraTS, Medical Segmentation Decathlon)
결과
1. MAE self pre-training이 무작위 초기화(random initialization)보다 의료 영상 분류와 분할 성능을 크게 향상
2. 모든 데이터셋에서 ImageNet 기반 사전학습보다 더 뛰어난 성능을 달성
3. METHODOLOGY
Vision Transformer (ViT)
입력 이미지를 패치 단위로 나누어 sequence로 변환.
포지션 임베딩 추가.
Transformer block(Attention + MLP)으로 학습.
사전학습 시엔 sine-cosine positional embedding 사용.
MAE Self Pre-training
입력 이미지를 랜덤하게 마스킹 (일부 패치만 encoder 입력).
Encoder: 보이는 패치만으로 representation 학습.
Decoder: mask token + encoder feature로 마스킹된 영역 복원.
Loss: MSE, 단 마스크된 영역만 복원.
Downstream Tasks
Classification: ViT + Linear Classifier (multi-label → BCE loss).
Segmentation: UNETR(Transformer 기반 U-Net 구조) decoder 추가.
사전학습된 encoder weight로 초기화 후 fine-tuning.
2.1 Preliminary: Vision Transformer (ViT)
Backbone으로 ViT 사용 (pre-training, downstream 공통).
구성 요소:
-
Patch Embedding: 3D 볼륨 이미지를 작은 패치 단위로 나눠 시퀀스로 변환.
입력:
𝑥∈𝑅𝐻×𝑊×𝐷×𝐶x∈R
H×W×D×C
출력: Flatten된 패치 시퀀스 → 선형 프로젝션으로 임베딩. -
Position Embedding: 위치 정보를 유지하기 위해 임베딩 추가.
일반적으로 learnable 1D embedding 사용.
그러나 실험적으로 학습 가능한 1D embedding은 MAE 복원에 방해 → 대신 sine-cosine embedding 사용.
다운스트림 작업에서는 sine-cosine으로 초기화 후 학습. -
Transformer Block: Multi-Head Self-Attention(MSA)와 MLP 블록 반복.
2.2 Self Pre-training with Masked Autoencoders (MAE)
Encoder (ViT): 입력 이미지를 패치로 분할 → 일부는 마스킹, 일부만 encoder 입력.
Encoder는 보이는 패치들로부터 전체 문맥적 표현을 학습.
Decoder (Transformer): Encoder 출력 + mask token 입력 → 원래 마스크된 영역 복원.
Decoder는 사전학습에만 사용, downstream에서는 제거됨.
Loss Function:
Reconstruction loss (MSE).
전체 이미지를 복원하는 게 아니라 mask된 영역만 예측 → 성능 더 좋음.
Normalized pixel/voxel 값이 raw 값보다 더 나은 학습 목표.
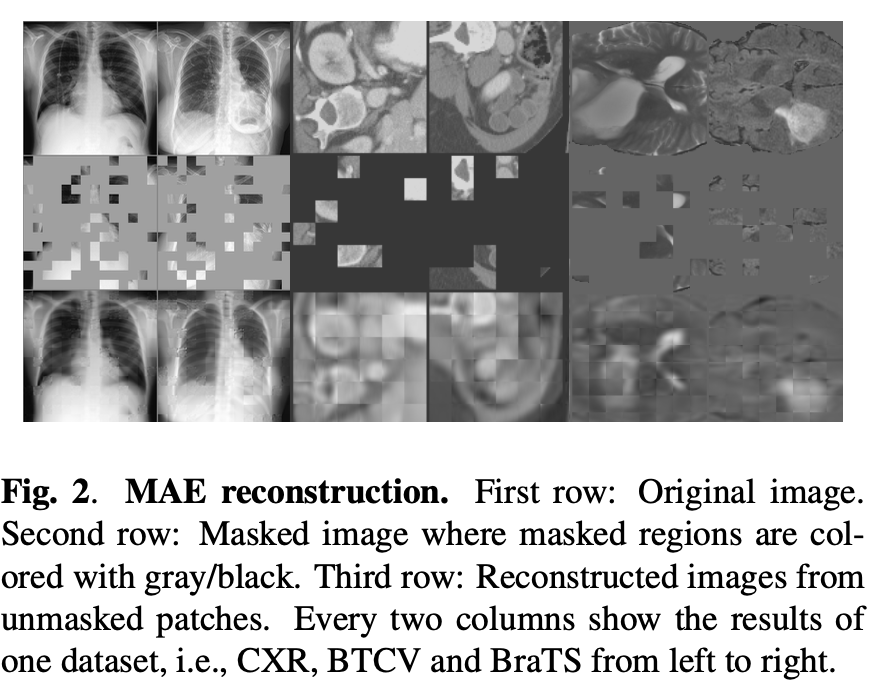
구성
첫 번째 줄 (First row): 원본 이미지 (Original image).
Chest X-ray, Abdominal CT, Brain MRI (왼쪽 → 오른쪽).
두 번째 줄 (Second row): 마스킹된 이미지 (Masked image).
이미지 일부 패치가 회색/검은색으로 가려져 있음.
Encoder는 이 보이는 일부 패치만 입력으로 받아 학습.
세 번째 줄 (Third row): 복원된 이미지 (Reconstructed image).
Encoder+Decoder가 마스킹된 영역을 추론해 채운 결과.
실제 원본과는 약간 다르지만, 전체적인 구조는 잘 복원됨.
의미
MAE는 이미지의 75% 이상을 가려도 나머지 정보로 전체를 추론할 수 있다는 걸 보여줌.
복원 품질이 완벽하진 않지만, 중요한 건 Decoder 품질이 아니라 Encoder가 문맥적 표현을 학습하는 것.
의료 영상에서 문맥 이해가 중요한 이유:
X-ray → 폐 질환은 주변 심장/종격동 구조까지 보고 추론 가능.
CT → 장기의 위치 관계, 형태적 연속성을 학습.
MRI → 종양뿐만 아니라 주변 뇌 조직의 변화를 함께 파악.
✅ 요약:
이 그림은 MAE가 일부 패치만 보고 전체 이미지를 재구성하는 과정을 시각적으로 보여주며, 이를 통해 Encoder가 풍부한 문맥 표현(contextual representation)을 학습함을 증명합니다.
2.3 Architectures for Downstream Tasks
Classification:
ViT encoder + Linear classifier head.
Chest X-ray는 multi-label 분류이므로 BCE loss 사용.
Segmentation (UNETR 기반):
MAE 사전학습된 ViT encoder + 랜덤 초기화된 UNETR decoder.
구조: U-Net처럼 encoder의 여러 resolution feature를 decoder에 skip-connection.
Encoder representation을 reshape → spatial dimension 복원 → upsampling & concat으로 세부 segmentation 맵 생성.
📌 요약 정리:
ViT를 backbone으로 쓰되, MAE를 통해 mask 복원 pre-training → 문맥 이해 능력 강화.
Pre-training: Encoder+Decoder(MAE), Loss는 MSE(masked 부분만).
Downstream: Encoder weight를 가져와서 분류(Linear) 또는 분할(UNETR) head 연결.
4. EXPERIMENTS AND RESULTS
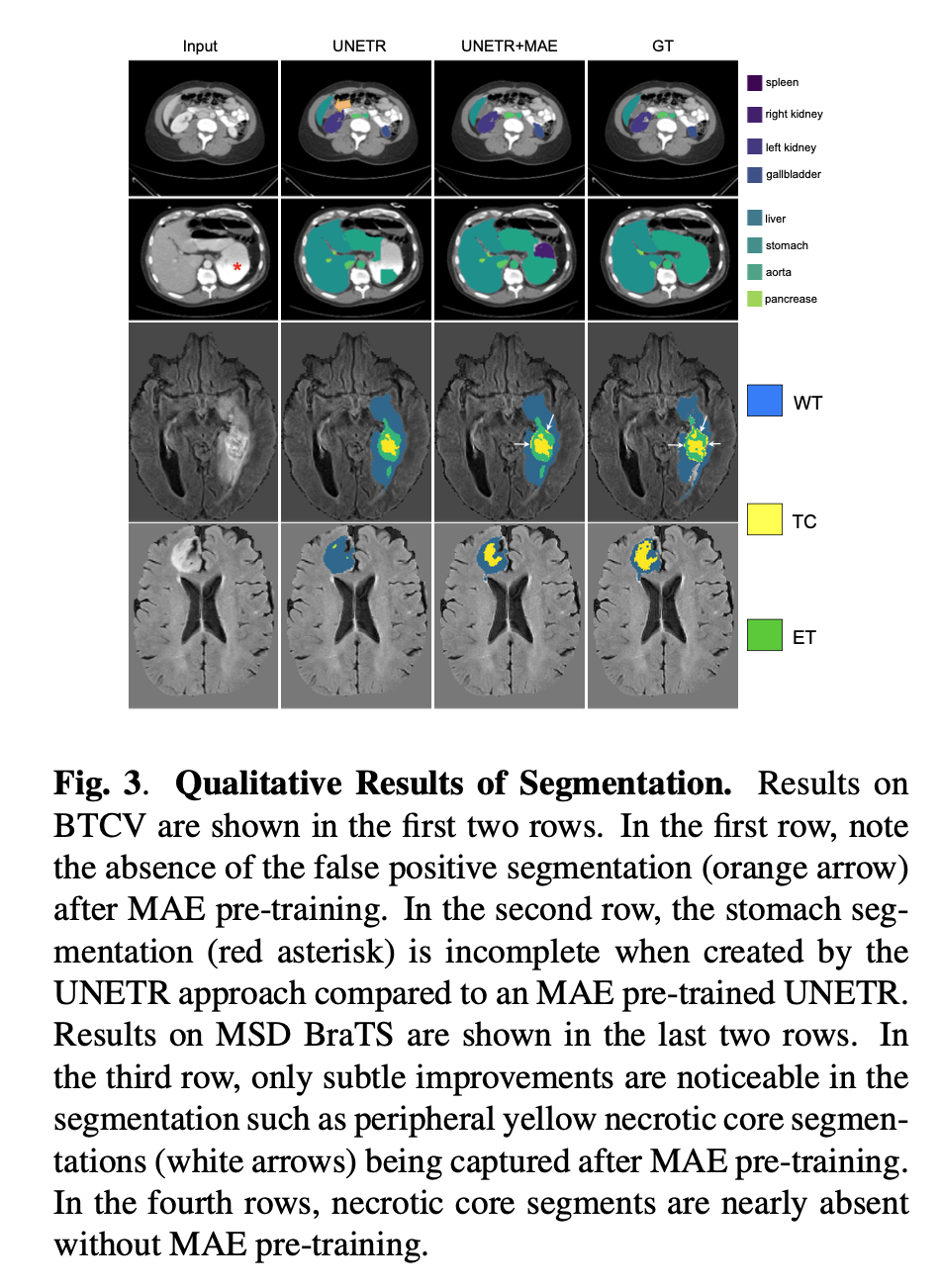
1️⃣ BTCV (Abdomen CT, 첫 두 줄)
첫 번째 줄:
UNETR에서는 잘못된 false positive segmentation(주황색 화살표)이 존재.
MAE pre-training을 거친 UNETR은 이 오류가 사라짐 → 더 정확한 장기 분할.
두 번째 줄:
UNETR은 위(stomach) 영역 분할이 불완전 (빨간 별표).
UNETR+MAE는 훨씬 더 완전하게 위를 분할.
👉 결론: MAE pre-training 덕분에 오탐 감소, 장기 분할 정확도 향상.
2️⃣ BraTS (Brain Tumor MRI, 마지막 두 줄)
세 번째 줄:
UNETR은 종양 주변(peripheral) 세부적인 종양 핵(yellow necrotic core, 흰색 화살표)을 놓침.
UNETR+MAE는 이 작은 부분까지 포착 → 더 정밀한 segmentation.
네 번째 줄:
UNETR은 괴사 핵(necrotic core) 분할이 거의 없음.
UNETR+MAE는 해당 영역을 더 잘 탐지.
👉 결론: MAE pre-training은 종양 내부 구조(코어, 주변부)까지 더 정확히 분할.
✅ 요약
BTCV (CT 다장기 분할):
False positive 감소.
위(stomach) 같은 작은 장기 분할 성능 향상.
BraTS (MRI 뇌종양 분할):
종양 내부 구조(괴사 코어, 주변부)까지 더 잘 포착.
기존 UNETR보다 더 세밀하고 안정적인 분할 성능.
즉, MAE self pre-training → 단순 수치 향상뿐 아니라, 실제 시각적 분할 품질도 개선됨을 보여주는 그림입니다.

왼쪽 블록 (Method 비교)
UNETR (기본 모델)
UNETR + ImageNet Pre-training
UNETR + MAE Self Pre-training
👉 세 가지 방법의 뇌종양 분할 성능 비교 (DSC↑ = Dice Score, HD95↓ = Hausdorff Distance 95).
오른쪽 블록 (Ablation Study)
Mask ratio (마스크 비율) & Pre-training Epochs 변화에 따른 평균 DSC 결과.
Mask ratio = 입력 이미지에서 가리는 비율.
📊 주요 결과
1️⃣ Method 비교 (왼쪽)
UNETR 기본: Avg DSC = 77.40, HD95 = 7.78
UNETR + ImageNet: 약간 향상 → Avg DSC = 77.78, HD95 = 7.38
UNETR + MAE: 가장 높음 → Avg DSC = 78.91, HD95 = 7.22
👉 결론: MAE self pre-training이 ImageNet 기반 pre-training보다 효과적.
2️⃣ 세부 클래스별 (WT, ET, TC)
WT (Whole Tumor): MAE = 90.84 (최고)
ET (Enhancing Tumor): MAE = 63.88 (최고)
TC (Tumor Core): MAE = 82.00 (최고)
👉 모든 세부 종양 영역에서 MAE가 우세.
3️⃣ Ablation Study (오른쪽)
Mask Ratio 효과:
87.5% → Avg DSC 77.14 (낮음)
75% → Avg DSC 78.14 ~ 78.43 (보통)
50% → Avg DSC 78.42 (500 epoch), 83.2 (10k epoch)
25% → Avg DSC 78.71 (500 epoch), 83.18 (10k epoch)
12.5% → Avg DSC 78.91 (500 epoch), 83.52 (10k epoch, 최고 성능)
👉 의료 영상에서는 낮은 mask ratio (12.5%~25%)가 최적, 자연 이미지처럼 75% 이상 마스킹은 오히려 성능 저하.
Epoch 효과:
Pre-training을 오래 할수록 성능이 향상되지만, 40k epoch에서는 오히려 성능 하락 (과적합) 발생.
✅ 요약
MAE self pre-training > ImageNet pre-training > Random init
모든 종양 영역(Whole, Enhancing, Core)에서 MAE가 최고 성능 달성
낮은 mask ratio (12.5%~25%) + 충분한 pre-training epoch (~10k) 조합이 최적.
너무 많은 epoch (40k)는 오히려 성능 저하 (overfitting).
Datasets
ChestX-ray14: 112,120장의 X-ray (multi-class 분류).
BTCV: 30명 환자의 복부 CT, 13개 장기 annotation (8개 장기 평가).
BraTS (MSD): 484명의 멀티모달 MRI, 종양 분할.
Implementation
Backbone: ViT-B/16
Optimizer: AdamW
Pre-training epoch: CXR14 (800), BTCV (10k), BraTS (500)
Augmentation: crop, flip, normalize
Results
ChestX-ray 분류
ViT scratch: mAUC 74.4%
ImageNet pretrained: 80.7%
MAE self pre-training: 81.5%
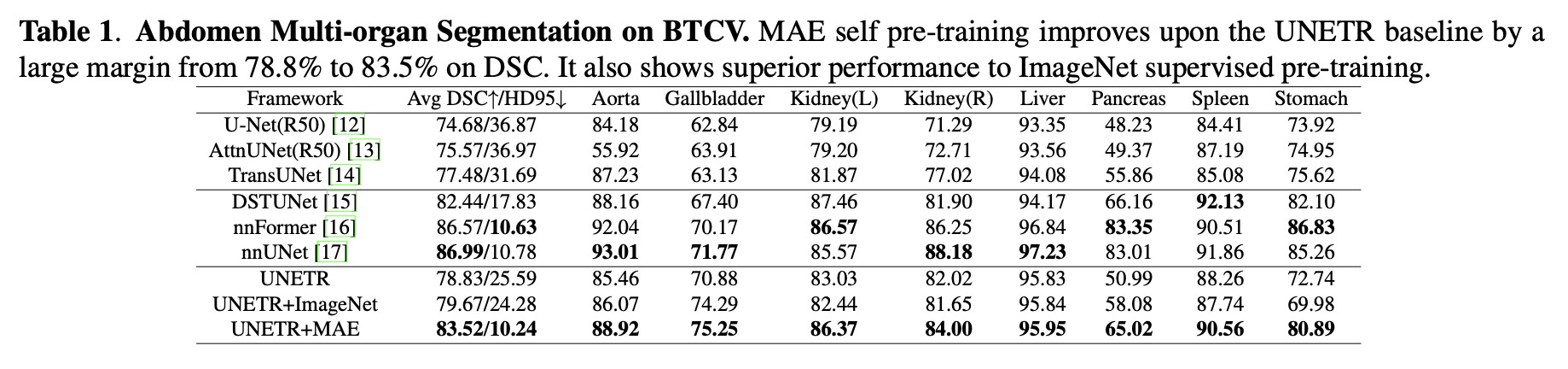
BTCV 다장기 CT 분할
UNETR baseline: DSC 78.8%
ImageNet pretrained: 79.7%
MAE self pre-training: 83.5% (큰 향상)
BraTS 뇌종양 MRI 분할
UNETR baseline: DSC 77.4%
ImageNet pretrained: 77.8%
MAE self pre-training: 78.9%
Ablation Study
마스크 비율: 자연 영상(MAE 논문)에서는 75% 이상이 최적이지만, 의료 영상에서는 낮은 비율(12.5%)이 더 성능 좋음.
Pre-training epoch: 적당히 길수록 좋지만 너무 길면 과적합.
3.1 Datasets and Implementation Details
ChestX-ray14 (CXR14):
11만 개 이상의 흉부 X-ray (32,717 환자).
Train/val 80%, test 20%.
Metric: multi-class AUC.
BTCV (Abdomen CT, 다장기 분할):
30명 CT, 13개 장기 라벨링.
18개 학습, 12개 검증.
Metric: 평균 Dice Similarity Coefficient (DSC), 95% Hausdorff Distance (HD).
BraTS (MSD Brain Tumor Segmentation):
484개 multi-modal MRI (FLAIR, T1w, T1-Gd, T2w).
라벨: edema, enhancing tumor, necrotic/non-enhancing core.
Metric: DSC, 95% HD.
Train 80%, Validation 20%.
Implementation:
PyTorch + MONAI.
Backbone: ViT-B/16.
Optimizer: AdamW.
Patch size: 16×16 (2D), 16×16×16 (3D).
Data Preprocessing:
CXR14: 히스토그램 균등화, 랜덤 crop (224×224).
BTCV: intensity clipping, normalization, 랜덤 crop (96³).
BraTS: instance-wise normalization, 랜덤 crop (128³).
MAE Pre-training:
LR=1.5e-4, weight decay=0.05, cosine schedule.
Epochs: 800 (CXR), 10k (BTCV), 500 (BraTS).
Batch size: 256 (CXR), 6 (BTCV, BraTS).
Fine-tuning:
Layer-wise LR decay=0.75, DropPath=0.1.
LR: 1e-3 (CXR), 8e-4 (BTCV), 4e-4 (BraTS).
Batch size: 동일 (256, 6, 6).
3.2 Results
(1) MAE Reconstruction
Fig. 2: 마스크 비율 75%.
결과: 원본 → 마스크 → 복원 순서.
복원된 visible patch는 다소 blur하지만, masked 영역은 잘 복원.
목표는 reconstruction 품질 자체가 아니라 문맥적 표현 학습.
(2) Abdomen Multi-organ Segmentation (BTCV)
Baseline UNETR: 78.8% DSC.
UNETR+ImageNet: 79.7%.
UNETR+MAE: 83.5% (큰 향상).
적은 데이터(N=30)에서도 효과적 → 소규모 의료 데이터에서 MAE의 잠재력 입증.
목표는 SOTA가 아니라 MAE self pre-training의 효과성 증명.
(3) Brain Tumor Segmentation (BraTS, MSD)
Baseline UNETR: 77.4% DSC / 7.78mm HD95.
UNETR+ImageNet: 77.8% / 7.38mm.
UNETR+MAE (mask=12.5%) → 78.9% / 7.22mm.
개선폭은 크진 않지만 안정적 성능 향상.
(4) Ablation Study (Mask Ratio & Epochs)
Pre-training Epochs: 길게 학습하면 성능이 좋아지지만, 너무 오래하면 오히려 과적합으로 성능 하락.
Mask Ratio: 자연 이미지에서는 높은 비율(75% 이상)이 효과적이지만,
의료 영상 segmentation은 낮은 mask 비율 (12.5% ~ 25%)이 가장 좋은 성능.
이유: 의료 영상은 구조적·문맥적 정보가 제한적이므로 지나치게 많이 가리면 복원이 어려움.
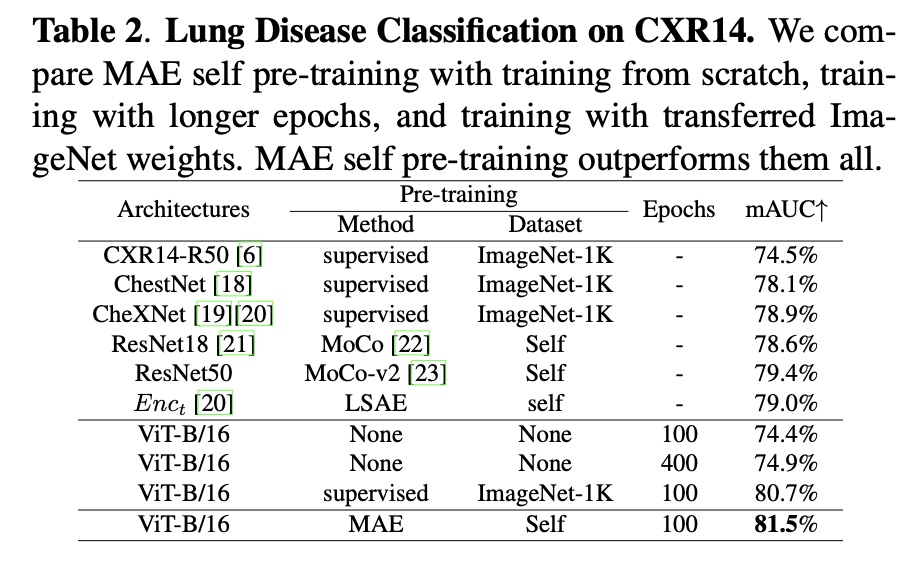
(5) Lung Disease Classification (CXR14)
ViT scratch (100 epoch): 74.4% mAUC.
ViT scratch (400 epoch): 74.9%.
ViT + ImageNet pretrain: 80.7%.
ViT + MAE self pretrain: 81.5%.
결과: ViT는 사전학습 없이 성능이 낮지만, MAE self pre-training은 ImageNet pre-training보다도 우수.
✅ 요약:
BTCV CT segmentation → 큰 성능 향상 (78.8% → 83.5%).
BraTS MRI segmentation → 소폭 향상 (77.4% → 78.9%).
ChestX-ray14 classification → ImageNet 사전학습보다도 우수 (80.7% → 81.5%).
Ablation: 의료 영상은 낮은 mask ratio가 효과적.
5. CONCLUSION
- MAE Self Pre-training은 의료 영상 분석에서 무작위 초기화, ImageNet 사전학습 모두를 능가하는 성능을 보임.
특히 ImageNet 사전학습보다 소규모 데이터셋 환경에서 효과적임을 입증. - 2D (X-ray)뿐 아니라 3D (CT, MRI) 영상에도 적용 가능.
- 향후 예후 예측, 임상 결과 분석 같은 고차원적 의료 AI 작업으로 확장 가능.
