
- 인터럽트, 시스템 콜
- CPU 스케줄러
- 동기와 비동기의 차이
- Dead Lock/Race Condition
들어가기에 앞서
(싱글 코어 CPU에서) 프로세스는 항상 돌아가진 않는다. 한 번에 하나의 프로세스만 동작하는데, 이 과정에서 I/O가 발생하거나, 프로그램에 문제가 생기면 프로세스는 잠시 동작을 멈춰야 하는데, 이것을 누가 처리 해야 할까?
또한, 위에서 언급한 I/O는 실제로는 일반 프로그램이 하는 것이 아니라, 운영체제 측에서 담당해야 하는 것이다. 그런데 왜 우리는 지금까지 그런 것을 모르고 프로그래밍을 했던 것일까?
이 질문들에 대답을 하기 위해선, 우리는 인터럽트와 시스템 콜에 대해 알아야 한다.
운영체제의 동작 과정 - Dual Mode
현대 운영체제의 대부분은 Dual Mode로 작동한다. 이는 운영체제가 서로 다른 두 개의 모드로 돌아가는 것을 의미한다.
- 사용자 모드 (User Mode): 일반적인 응용프로그램이 구동되는 환경이다.
- 커널 모드 (Kernel Mode): 커널이 구동되는 환경이며, 이 모드에서는 OS 시스템에 영향을 주는 명령어를 실행할 수 있다.
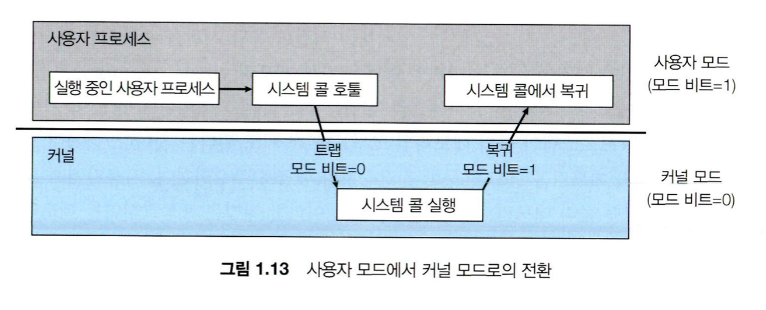
처음 운영체제가 구동되면 초기화 작업 및 부팅 과정에서 필요한 과정들을 수행하기 위해 커널 모드로 시작되지만, 곧 사용자 모드로 전환된다.
프로그램을 사용하면서 인터럽트 (Interrupt, H/W가 요청)나 트랩 (Trap, S/W가 요청하거나 오류로 인해 발생)이 발생되면 모드 비트를 0으로 전환하고, 운영체제의 모드 또한 커널 모드로 변경된다.
그렇다면, 왜 이렇게 두 모드를 분리하는 것일까? 만약 사용자 모드와 커널 모드의 구분이 없다면, 응용 프로그램이 시스템에 접근할 수 있는 길이 열리기 때문이다. 운영체제의 경우, 시스템에 영향을 끼칠 수 있는 몇몇 명령어를 특권 명령으로 지정함으로써 운영체제 자신을 보호한다. 만약 응용 소프트웨어가 해당 명령을 시행하려고 접근하게 된다면, OS 측에서 잘못된 접근으로 인식하여 트랩을 걸어 프로그램을 중단 시켜버릴 수 있다.
아래에서 본격적으로 인터럽트와 시스템 콜에 대해서 알아보도록 하겠다.
인터럽트, 시스템 콜
인터럽트(Interrupt)
CPU가 프로그램을 실행하는 도중에 예기치 않은 상황이 발생할 경우 현재 실행 중인 작업을 즉시 중단하고, 발생된 상황에 대한 우선 처리가 필요함을 CPU에게 알리는 것을 말한다. 지금 수행 중인 일보다 더 중요한 일(ex. 입출력, 우선 순위 연산 등)이 발생하면 그 일을 먼저 처리하고 나서 하던 일을 계속해야한다.
인터럽트는 크게 하드웨어 인터럽트와 소프트웨어 인터럽트로 나뉜다.
하드웨어 인터럽트
하드웨어가 발생시키는 인터럽트로, CPU가 아닌 다른 하드웨어 장치가 CPU에게 어떤 사실을 알려주거나 CPU 서비스를 요청해야 할 경우 발생시킨다. Maskable interrupt와 Non-maskable interrupt가 있다.
- Maskable interrupt
- Interrupt Mask (인터럽트가 발생하였을 때 요구를 받아들일지 말지 지정하는 것)가 가능
- 인텔 CPU에서 INTR pin으로 신호가 들어옴 - Non Maskable interrupt
- Interrupt Mask가 불가능
- 거부, 무시할 수 없음 (매우 중요함)
- 정전, 하드에어 고장 등 어쩔 수 없는 오류
- 인텔 CPU에서 NMI pin으로 신호가 들어옴
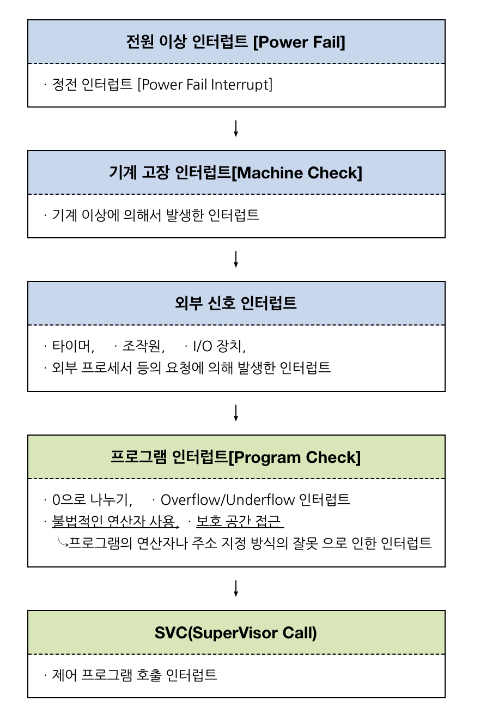
하드웨어 인터럽트가 발생하는 예
- 기계 검사 인터럽트 - 프로그램을 실행하는 도중 갑작스런 정전이나 컴퓨터 자체 내에서 기계적인 문제가 발생한 경우
- 외부 인터럽트 - 오퍼레이터나 타이머에 의해 의도적으로 프로그램이 중단된 경우
- 입출력 인터럽트 - 입출력의 종료나 입출력의 오류에 의해 CPU의 기능이 요청되는 경우
- 프로그램 검사 인터럽트 - 프로그램 실행 중 보호된 기억 공간 내에 접근하거나 불법적인 명령 수행과 같은 프로그램의 문제가 발생한 경우
소프트웨어 인터럽트
소프트웨어 인터럽트는 외부가 아닌 CPU 내부에서 자신이 실행한 명령이나 CPU의 명령 실행에 관련된 모듈이 변화하는 경우 발생한다. 프로그램 실행 중 프로그램 상의 처리 불가능한 오류나 이벤트를 알리기 위한 경우 발생하는데, 이를 트랩(Trap) 또는 예외(Exception)이라 부른다. 또한 프로그램 내에서 특별한 서비스를 요구하거나 감시(supervisor)를 목적으로 의도적으로 프로그램이 발생시킨 특별한 명령어에 의해 발생되기도 한다.
소프트웨어 인터럽트가 발생하는 예
1. 프로그램 검사 인터럽트 (Program check interrupt)
- 존재하지 않는 메모리 주소에 접근
- 나눗셈에서 0으로 나누고자 하는 경우
- SVC (Supervisor Call: 감시 프로그램 호출) 인터럽트
- 사용자가 프로그램을 실행시키거나 supervisor을 호출하는 동작을 수행하는 경우
- 프로그래머에 의해 코드로 짜인 감시 프로그램을 호출하는 방식
인터럽트 하는 이유
주변 장치와 입출력 장치는 CPU나 메모리와 달리 인터럽트 라는 메커니즘을 통해 관리된다. 그 이유는 입출력 연산이 CPU 명령 수행 속도보다 현저히 느리기 때문이다.
운영체제를 악덕 사장님, CPU를 비싼 월급 주고 데려온 고급 인력이라고 생각해보자. 악덕 사장 입장에서는 비싼 돈으로 들여온 만큼 고급 인력이 쉬지 않고 일해서 돈 값을 했으면 좋겠다고 생각할 것이다. 그런데 아주 오래걸리는 입출력 연산을 CPU가 매번 기다린다면 비싼 돈 주고 모셔온 CPU를 백분 활용하지 못해 운영체제 사장님은 화가 날 것이다. CPU가 입출력 처리를 기다리며 쉬는 꼴을 못보는 운영체제 사장님은 연산 결과가 나올 때 까지 다른 일을 시킨다. 그리고 입출력 직원에게 자신의 업무가 완료되면 그때 CPU에게 작업 완료를 알리라고 일러둔다. CPU가 다시 해당 작업을 이어서 할 수 있도록 한다. 여기서 입출력 직원이 CPU에게 작업 완료를 알려주는 것이 인터럽트이다.
인터럽트 우선순위
인터럽트 벡터
- 여러가지 인터럽트에 대해 해당 인터럽트 발생시 처리해야 할 루틴(ISR)의 주소를 보관하고 있는 공간
- 대부분의 CPU들은 인터럽트 벡터 테이블을 가지고 있음
- 인텔x86에서는 이를 IDT(Interrupt Descriptor Table)이라고 한다.
인터럽트 서비스 루틴 (ISR)
- 인터럽트 핸들러 Interrupt handler라고 함
- 인터럽트가 접수되면 각각의 인터럽트에 대응하여 특정 기능을 처리하는 기계어 코드 루틴 (커널이 실행)
ex) 키보드 자판을 눌러 키보드 인터럽트가 발생하면 이에 해당하는 인터럽트 서비스 루틴이 실행됨
인터럽트 발생 처리 과정
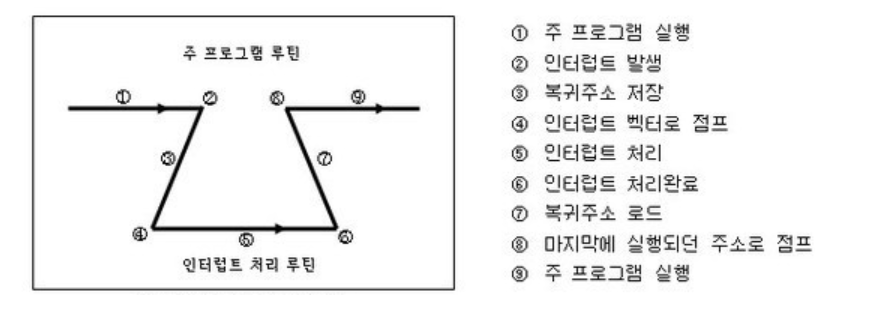
주 프로그램이 실행되다가 인터럽트가 발생했다.
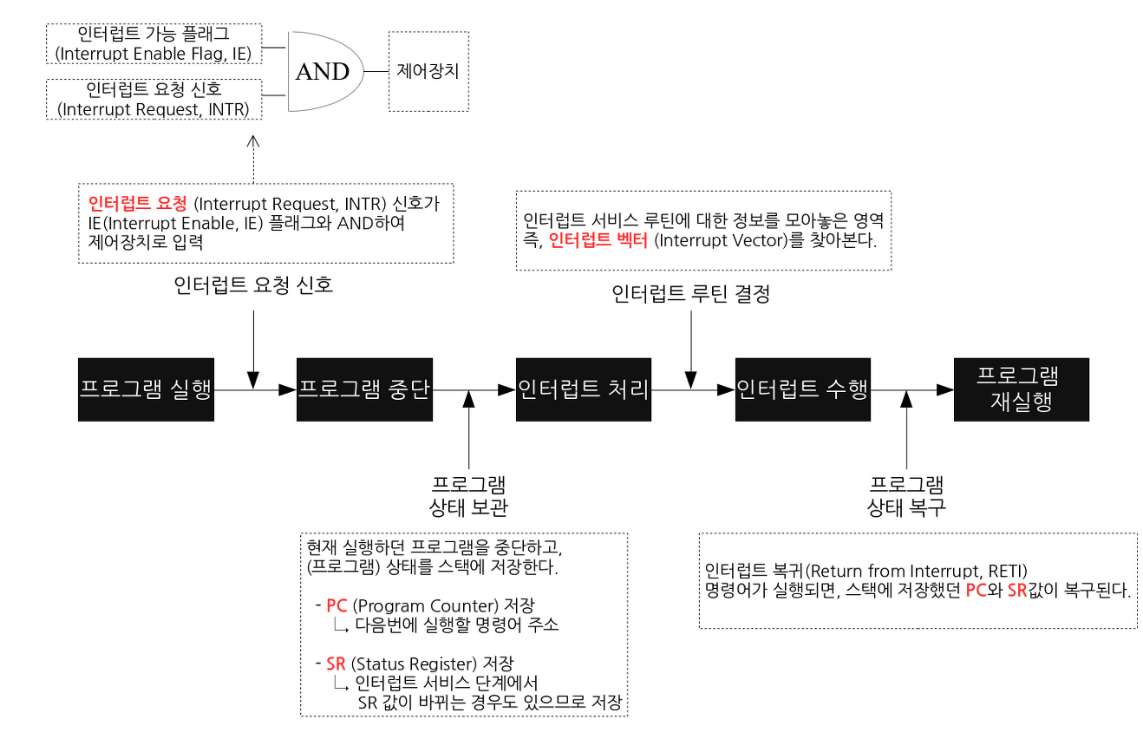
현재 수행 중인 프로그램을 멈추고, 상태 레지스터와 PC 등을 스택에 잠시 저장한 뒤에 인터럽트 서비스 루틴으로 간다. 잠시 저장하는 이유는, 인터럽트 서비스 루틴이 끝난 뒤 다시 원래 작업으로 돌아와야 하기 때문이다.
만약 인터럽트 기능이 없었다면, 컨트롤러는 특정한 어떤 일을 할 시기를 알기 위해 계속 체크를 해야 한다. 이를 폴링(Polling)이라고 한다.
폴링을 하는 시간에는 원래 하던 일에 집중할 수가 없게 되어 많은 기능을 제대로 수행하지 못하는 단점이 있다.
즉, 컨트롤러가 입력을 받아들이는 방법(우선순위 판별 방법)에는 두가지가 있다.
- 폴링 방식
사용자가 명령어를 사용해 입력 핀의 값을 계속 읽어 변화를 알아내는 방식
인터럽트 요청 플래그를 차례로 비교하여 우선순위가 가장 높은 인터럽트 자원을 찾아 이에 맞는 인터럽트 서비스 루틴을 수행한다. (하드웨어에 비해 속도 느림)
-
인터럽트 방식
MCU 자체가 하드웨어적으로 변화를 체크하여 변화 시에만 일정한 동작을 하는 방식- Daisy Chain
- 병렬 우선순위 부여
인터럽트 방식은 하드웨어로 지원을 받아야 하는 제약이 있지만, 폴링에 비해 신속하게 대응하는 것이 가능하다. 따라서 실시간 대응이 필요할 때는 필수적인 기능이다.
즉, 인터럽트는 발생시기를 예측하기 힘든 경우에 컨트롤러가 가장 빠르게 대응할 수 있는 방법이다.
인터럽트 발생 처리 과정 - 예시
프로세스 A 실행 중 디스크에서 어떤 데이터를 읽어오라는 명령을 받았을 때
- 프로세스 A는 system call을 통해 인터럽트를 발생시킴
- CPU는 현재 진행중인 기계어 코드를 완료
- 현재까지 수행중이었던 상태를 해당 프로세스의 PCB (Process Control Block)에 저장 → 수행중이던 메모리 주소, 레지스터 값 등등
- PC (Program Counter, IP)에 다음 실행할 명령의 주소 저장
- 인터럽트 벡터를 읽고 ISR 주소값을 얻어 ISR (Interrupt Service Routine)으로 점프하여 루틴을 실행
- 해당 코드 실행
- 해당 일을 다 처리하면 저장했던 프로세스 상태 복구
- ISR의 끝에 IRET 명령어에 의해 인터럽트가 해제
- IRET 명령어가 실행되면, 대피시킨 PC 값을 복원하여 이전 실행위치로 복원
IRET (Interrupt Return) 명령어: 이전 태스크로 다시 돌아가는 어셈블리 명령어. ISR의 마지막 명령어이다.
인터럽트와 특권 명령
명령어의 종류
CPU가 수행하는 명령에는 일반 명령과 특권 명령이 있다.
일반 명령은 메모리에서 자료를 읽어오고, CPU에서 계산을 하는 등의 명령이고 모든 프로그램이 수행할 수 있는 명령이다.
특권 명령은 보안이 필요한 명령으로 입출력 장치, 타이머 등의 장치를 접근하는 명령이다. 특권 명령은 항상 운영체제만이 수행할 수 있다.
Kernel mode vs User mode
운영체제는 하드웨어적인 보안을 유지하기 위해 기본적으로 두가지 operation을 지원한다. kernel mode는 운영체제가 CPU의 제어권을 가지고 명령을 수행하는 모드로 일반 명령과 특권 명령 모두 수행할 수 있다.
하지만 user mode는 일반 사용자 프로그램이 CPU 제어권을 가지고 명령을 수행하는 모드이기 때문에 일반 명령만을 수행할 수 있다.
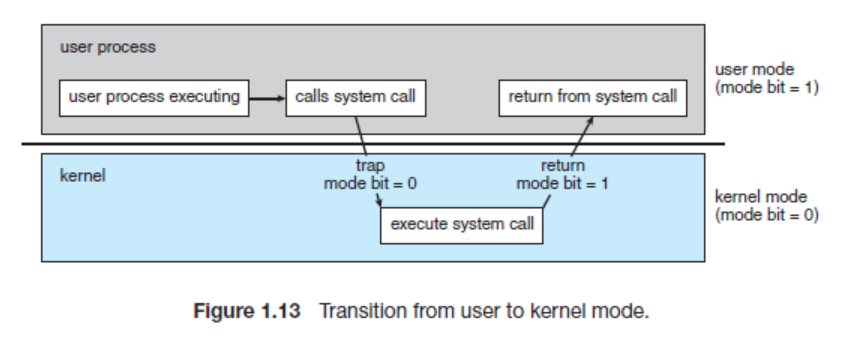
위의 예시에 이어서 Process A가 프로그램 명령 수행 중에 디스크 입출력 명령을 읽은 경우를 생각해보자. 사용자 프로그램은 입출력 장치에 접근하는 명령을 수행할 수 없다. user mode에서 특권 명령을 수행할 수 없기 때문이다. 이런 경우에 사용자 프로그램은 운영체제에게 시스템 콜을 통해 특권 명령을 대신 수행해달라고 요청한다. 시스템 콜은 주소 공간 자체가 다른 곳 (kernel의 code 영역)으로 이동해야 하므로 프로그램이 인터럽트 라인에 인터럽트를 세팅하는 명령을 통해 이루어진다.
시스템 콜은 커널 영역의 기능을 사용자 모드가 사용 가능하게, 즉 프로세스가 하드웨어에 직접 접근해서 필요한 기능을 사용할 수 있게 해준다.
CPU가 인터럽트 라인을 검사하고 인터럽트가 발생한 것을 감지하게 된다. 현재 수행중인 사용자 프로그램을 잠시 멈추고 CPU의 제어권을 운영체제에게 양도한다. (Kernel mode) 그리고 이 때 하드웨어적으로 모드 비트가 1에서 0으로 자동으로 세팅되어 특권 명령을 수행할 수 있게 된다.
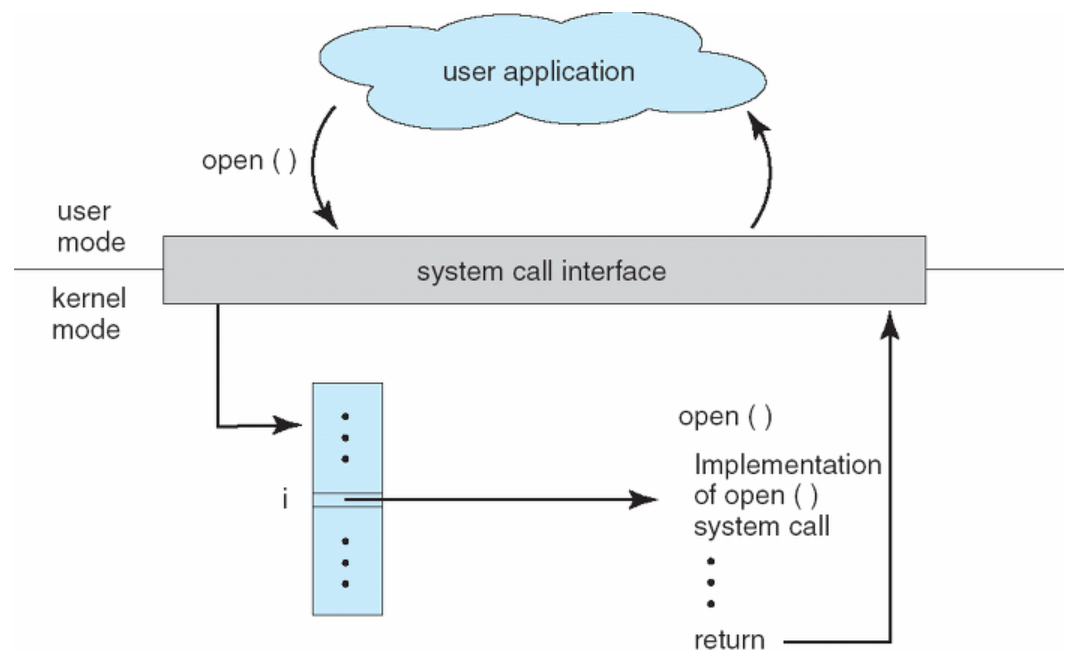
System Call
앞에서 운영체제는 커널 모드(Kernel Mode)와 사용자 모드(User Mode)로 나뉘어 구동된다고 했다. 운영체제에서 프로그램이 구동되는데 있어 파일을 읽어 오거나, 파일을 쓰거나, 혹은 화면에 메시지를 출력하는 등 많은 부분이 커널 모드를 사용한다. 시스템 콜은 이러한 커널 영역의 기능을 사용자 모드가 사용 가능하게, 즉 프로세스가 하드웨어에 직접 접근해서 필요한 기능을 사용할 수 있게 해당 작업을 수행할 권한을 주는 것이다.
그렇다면 권한은 왜 필요한 것일까? 그 이유는 해커가 피해를 입히기 위해 악의적으로 시스템 콜을 사용하는 경우나 초보 사용자가 하드웨어 명령어를 잘 몰라서 아무렇게 함수를 호출했을 경우에 시스템 전체를 망가뜨릴 수도 있기 때문이다. 따라서 이러한 명령어들은 특별하게 커널 모드에서만 실행할 수 있도록 설계되었고, 만약 유저 모드에서 시스템 콜을 호출할 경우에는 운영체제에서 불법적인 접근이라 여기고 trap을 발생시킨다.
그렇다면 다음과 같은 의문이 들 수도 있겠다.
자원도 요청하고, 서비스도 요청하고... 그러면 요청할 수 있는 종류가 많지 않나? 이걸 어떻게 구분할 수 있을까?
시스템 콜의 동작 과정은 다음과 같다.
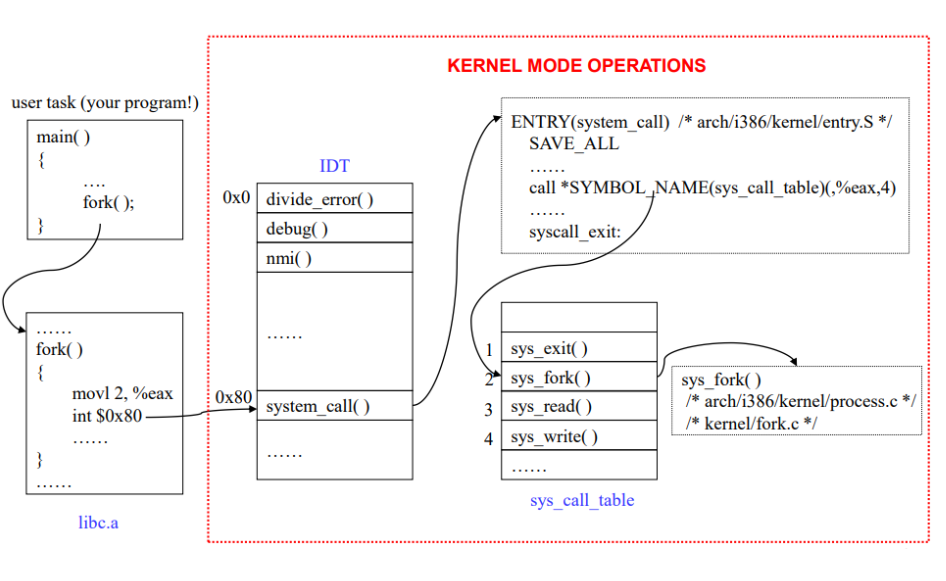
- 응용 프로그램에서 시스템 콜을 호출하면, (일반적으로는 API 형태로 Wrapped 되어 있기 때문에 우리는 의식하지 않고 사용함) 0x80 인터럽트가 발생한다.
- IDT (Interrupt Descripter Table; 인터럽트의 종류를 판단하기 위해 사용함)에서 0x80은 system_call() 이기 때문에, 커널이 시스템 콜과 관련된 동작을 수행한다.
하지만 그림에서도 보면 알 수 있지만, 시스템 콜의 종류는 정말 다양하기 때문에, 우리가 어떤 시스템 콜을 수행해야 하지? 라는 질문에 답하기 위해서는 추가적인 매개변수가 필요할 것이다.
그렇다면 매개변수를 어떤 식으로 전달해야 할까?
-
매개변수를 레지스터에 담는다.
→ 매개변수가 레지스터의 수 보다 많은 경우가 존재하므로 적합하지 않은 방법이다. -
매개변수를 연속적(블록) 또는 불연속적(테이블 사용)으로 메모리에 담은 뒤, 주소를 레지스터에 담는다.
→ 크기에 제한이 없으므로 많이 사용된다. -
스택에 매개변수를 담는다.
→ 이 경우, 스택에 담긴 모든 데이터를 레지스터에 옮기고 스택에 원소를 담아야 하기 때문에, 결과적으로 첫 번째 방법과 큰 차이가 없다.
CPU 스케줄링
먼저 스케줄링이 무엇이고, 왜 이런 것이 필요한지 알아보도록 하자. 사실 이번 글 뒷부분에서 언급할 여러 가지 스케줄링 알고리즘을 달달달 외우는 것보다 어쩌면 스케줄링이 왜 필요한지 그 이유를 아는 것이 더 중요할 수 있다.
스케줄(Schedule)이라는 단어에서 알 수 있듯, 운영체제에서 말하는 스케줄링은 운영체제가 CPU의 자원을 어떤 프로세스에게 할당해 줄 지 그 일정을 짜는 것이라고 이해하면 쉽다. 이전 글에서 언급했던 대로 프로세스 간의 Context Switching 과정은 많은 자원 손실을 발생시킨다. 따라서 이 일정을 어떻게 짰는지에 따라 CPU의 자원을 얼마나 효율적으로 사용하게 되는지가 결정된다. 한 마디로 스케줄링은 운영체제 입장에서 매우 중요한 과정이라고 할 수 있다.
Context Switching
본격적으로 스케줄링에 대해 설명하기 전에 Context Switching에 대해 알고 가야 할 필요가 있다. 단어 하나하나 생각해보자. Switch라는 단어의 뜻을 안다면 Context라는 단어를 모른다고 하더라도 일단 "Context를 Switching(교체, 전환)하는 것"이라고 생각할 수 있다. 그럼 Context는 뭘까? 흔히들 '문맥'이라는 단어로 번역하는데 여기서는 이렇게 번역하는 것이 좋은 방법이 아니다.
운영체제에서 말하는 Context는 문맥이 아니라 CPU가 프로세스를 실행하기 위한 (프로세스에 대한) 정보를 말한다. 더 자세히 말하면 Context는 현재 프로세스의 상태, 프로세스가 다음에 실행할 명령어, 레지스터 값, 프로세스 번호 등의 정보를 담고 있으며 이는 운영체제의 PCB (Process Control Block)에 저장된다.
이전 글에서도 언급했듯이 멀티 프로세스 환경에서는 여러 프로세스가 동시에 실행되는 것처럼 보인다. 이 환경에서는 필연적으로 프로세스 간 CPU 자원 할당 이동이 일어날 수 밖에 없다. 이 이동 과정을 Context Switching이라고 하며, CPU는 기존 할당된 프로세스의 Context를 저장하고, 새로 자원을 할당할 프로세스의 Context로 교체하는 과정을 거치면서 자원을 새로운 프로세스에게 할당하게 된다. 여기서 주의해야 할 점이 있다. Context Switching 중에는 CPU의 자원이 어떤 프로세스에게 할당된 상태가 아니기 때문에 CPU가 아무 일도 하지 못한다. 따라서 Context Switching 과정이 너무 자주 발생하면 오히려 CPU 성능이 떨어지게 된다.
운영체제가 왜 있는걸까? 결국 운영체제는 컴퓨터가 효율적으로 일을 하게 만들기 위한 시스템이다. 그런데 방금 위에서 Context Switching 과정이 너무 자주 발생하면 오히려 CPU 성능이 떨어지게 된다고 언급했었다. 이 말은 바로 Context Switching 과정을 쓸데없이 자주 반복하지 않도록 하고, 필요한 순간에 적절하게 하도록 하는 알고리즘이 필요하다는 뜻이다. 그리고 이 알고리즘을 사용하는 주체가 바로 운영체제 스케줄러다.
이해하기 쉽도록 설명하기 위해 어쩌면 잘못 설명했을 수도 있는 부분에 대해 보충설명 하도록 하겠다. Context Switching 중에는 CPU의 자원이 어떤 프로세스에게 할당된 상태가 아니라고 했는데, 사실 할당이라는 단어를 썼지만 정확히는 프로세스가 점유 중이지만 사용 중은 아닌 상태다. 특정 프로세스에 의해 CPU 자원이 점유되고는 있는데, Context Switching 중이기 때문에 실제로 사용되는 프로세스가 없는 상태인 것이다. CPU가 아무 일도 하지 못한다는 것은 결국 CPU 자원을 아무 프로세스도 사용하지 못한다는 말이고 이는 오버헤드가 발생되었다는 뜻이다.
스케줄링 알고리즘에 대해 얘기하기 전에 스케줄러의 상태와 분류에 대해서부터 알아보겠다.
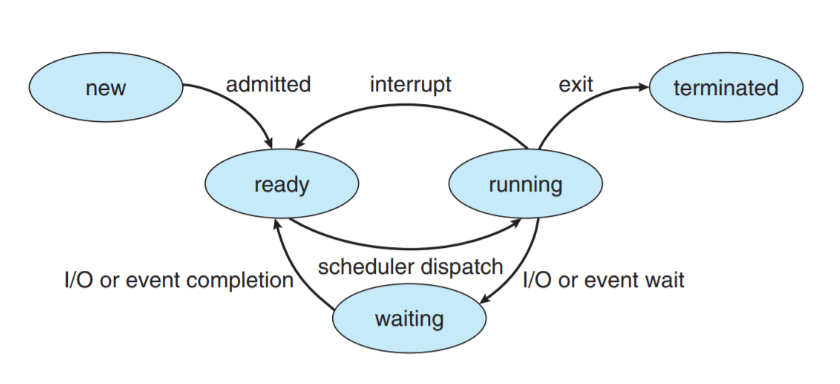
프로세스의 상태
프로세스는 각자의 상태를 갖고 있다. 프로세스가 현재 동작중일 수도 있고, CPU에게 작업이 할당되기 전까지 대기할 수도 있고, 아니면 앞에서 설명한 인터럽트에 놓일 수도 있기 때문이다.
각각의 상태는 PCB에 저장된다.
- New: 프로세스가 생성 중
- Running: 명령어들이 실행되고 있음
- Waiting: 프로세스가 이벤트를 대기하고 있음 (입출력 완료/신호 수신)
- Ready: 프로세스가 CPU에 스케줄링 되기를 대기 중
- Terminated: 프로세스가 종료 됨
스케줄러의 분류
스케줄러는 크게 장기, 단기, 그리고 중기로 분류할 수 있다.
-
장기 스케줄러 (Long-Term Schedular)
- 어떤 프로세스를 Ready Queue에 삽입할지 결정하는 역할을 한다.
- 프로그램을 가져와 커널에 등록하면 프로세스가 되는데, 어떤 프로그램을 가져와 등록할지 결정하는 역할을 한다.
- 일반적으로 수십 초 ~ 분 단위로 호출되기 때문에 속도가 느려도 괜찮다.
- 전체적으로 메모리에 올라오는 프로세스의 수를 조절하는 역할을 한다. -
단기 스케줄러 (Short-Term Schedular)
- Ready 상태에 있는 프로세스 중 어떤 프로세스를 CPU에 할당할 지 결정하는 역할을 한다.
- 이후 설명할 스케줄링 알고리즘은 대부분 단기 스케줄러에 적용된다.
- ms 단위로 빈번하게 호출되기 때문에 속도가 빨라야 한다. -
중기 스케줄러 (Medium-Term Schedular)
- 장기 스케줄러와는 반대로 역으로 메모리에 적재된 프로세스를 내린다.
사실 요즘은 단기 스케줄러만 있다. 이후에 설명할 Virtual Memory가 발달한 이후 메모리의 크기에 제약이 없어졌고, 그래서 최근 운영체제는 그냥 모든 프로세스를 전부 메모리에 적재한다.
따라서 이후 설명할 스케줄링의 경우, 단기 스케줄러에 초점을 맞춰 설명할 것이다.
스케줄링 알고리즘의 종류
Context Switching을 할 때 새로 자원을 할당할 프로세스는 누가 결정할까? 자원을 달라는 프로세스는 엄청 많을텐데, 어떤 프로세스에게 자원을 얼만큼 주어야 효율적으로 일할 수 있을까? 앞서 말했듯 이를 결정하는 정책을 만드는 것을 스케줄링이라고 한다. 프로세스 간 우선순위를 두고, Context Switching을 할 때 우선순위가 가장 높은 프로세스에게 CPU 자원을 할당해 주는 것이다. 이 우선순위를 결정하는 방법은 크게 두 가지로 분류할 수 있는데, 지금부터 그것들에 대해 알아보도록 하겠다.
비선점 스케줄링 vs 선점 스케줄링
비선점 스케줄링
비선점 스케줄링의 특징은 아래와 같다.
어떤 프로세스가 CPU를 점유하고 있다면 해당 프로세스의 작업이 완료될 때까지 다른 프로세스는 CPU를 사용할 수 없음.
프로세스가 CPU를 놓아주는 시점까지 스케줄링이 일어나지 않는다. 프로세스 일괄처리에 적합하고 Context Switching을 최소화할 수 있다는 장점이 있다. 다만 긴급히 처리되어야 할 프로세스가 처리되지 못할 수 있다는 문제점이 발생할 수 있다.
비선점 스케줄링의 종류
-
FCFS (First Come First Service)
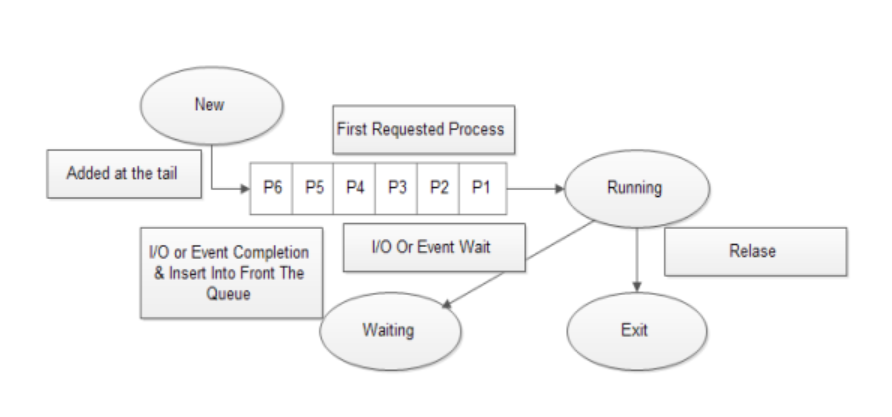
프로세스가 Ready Queue에 도착한 순서대로 CPU에 할당하는 방식이다. 작업 완료 시간을 예측하기 용이하다는 장점이 있다. 그러나 CPU 처리 시간이 길지만 덜 중요한 작업이, CPU 처리 시간이 짧고 더 중요한 작업을 기다리게 할 수도 있다. 이 상태를 호위 상태(콘보이 이펙트; Convoy Effect)라고 한다. -
SJF (Shortest Job First)
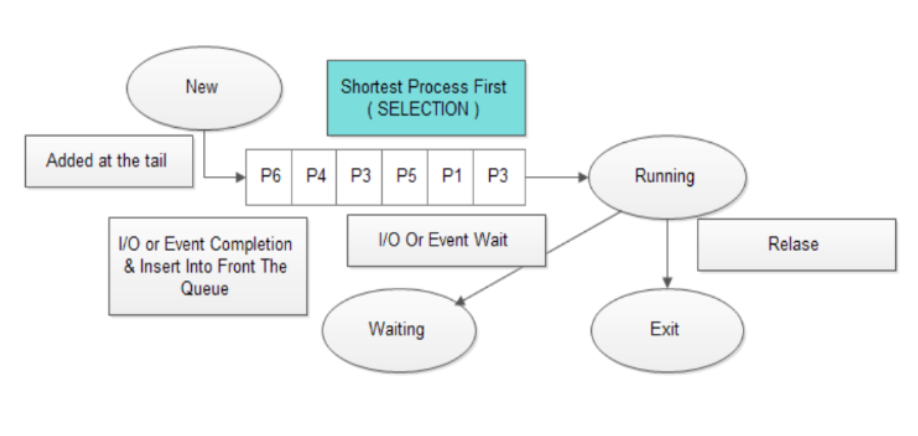
프로세스를 CPU 처리 시간이 짧은 순서대로 CPU에 할당하는 방식이다. 모든 방식을 통틀어 평균 대기 시간을 가장 짧게 만드는 방식으로 알려져 있다. 그러나 CPU 처리 시간이 긴 프로세스는 전체 시스템 성능 향상을 위해 희생하며 계속 Ready Queue의 뒤로 밀려나기 때문에 무한정 기다려야 하는 상황이 발생할 수 있다. 이 상태를 기아 상태 (스타베이션; Starvation)이라고 한다. -
HRN (Highest Response Ratio Next)
SJF 스케줄링 방식에서 발생할 수 있는 기아 상태를 해결하기 위해 고안된 방식이다. 우선순위를 단순히 CPU 처리 시간으로 결정하지 않고, Ready Queue에서 대기한 시간까지 고려하여 결정한다. 대부분 우선순위를 ((대기 시간 + CPU 처리 시간) / CPU 처리 시간)으로 결정한다. 이처럼 기다린 시간에 비례하여 우선순위를 높이는 기법을 에이징(Aging) 기법이라고 한다.
HRN 스케줄링 방식이 선점일 경우엔 우선순위가 높은 다른 프로세스들이 너무 자주 생기기 때문에 Context Switching이 자주 발생한다. 이에 따라 스케줄러의 일이 너무 늘어나기 때문에 HRN 스케줄링 방식은 비선점 방식으로 이루어진다.
지금까지의 설명만 읽어봤다면 FCFS 스케줄링 방식을 사용할 하등의 이유가 존재하지 않는 것처럼 보인다. HRN 스케줄링 방식이 다른 비선점 스케줄링 방식에 비해 이상적으로는 훨씬 우월해 보이기 때문이다. 그러나 SJF, HRN 등의 방식을 사용하기 어려운 이유가 있는데, 현실적인 상황에서는 프로세스마다 CPU 처리 시간이 얼마나 걸릴지 알 수 있는 방법이 없기 때문이다. 이는 아래에서 설명할 SRT 스케줄링 방식에서도 동일하게 적용되는 부분이다.
- 우선순위 (Priority)
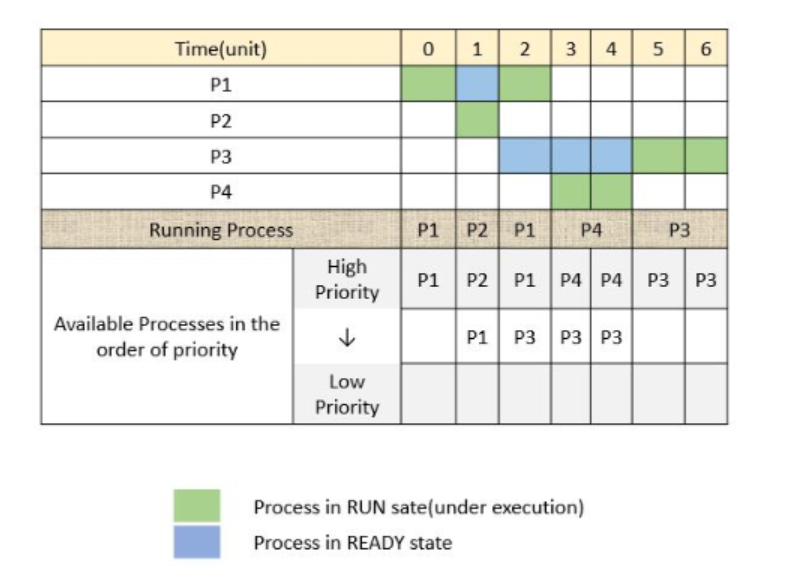
대기 중인 프로세스들에게 우선순위를 부여하여 우선순위가 높은 순서대로 처리한다. 선점형으로도 구현할 수 있으며 여기서도 에이징 기법이 사용된다. 왜나하면 우선순위가 낮은 프로세스에게 기아 상태가 생길 수 있기 때문이다. 우선순위는 정적 혹은 동적으로 부여될 수 있다. 동적으로 부여할 경우 구현이 복잡하고 오버헤드가 많다는 단점이 있으나, 시스템의 응답속도를 증가시킨다. 정적의 경우는 이 반대다.
선점 스케줄링
선점 스케줄링의 특징은 아래와 같다.
어떤 프로세스가 CPU를 점유하고 있을 때 우선순위가 높은 다른 프로세스가 점유를 빼앗아 CPU를 점유할 수 있음.
프로세스의 I/O 요청, I/O 응답, Interrupt 발생, 작업 완료 등의 특별한 상황에서 스케줄링이 발생한다. 긴급히 처리되어야 할 프로세스를 처리할 수 있다는 장점이 있지만 비선점 스케줄링 방식에 비해 Context Switching이 자주 일어날 수 있다는 단점이 있다.
SRT (Shortest Remaining Time)
SJF 스케줄링 방식을 선점 스케줄링 방식으로 변경한 기법이다. SJF 스케줄링 방식과 마찬가지로 프로세스를 CPU 처리 시간이 짧은 순서대로 CPU에 할당하는 방식이다. 위에서 설명했던 SJF 방식과 동일해 보이지만, 선점 스케줄링 방식이기 때문에 CPU를 점유 중인 프로세스보다 남은 CPU 처리 시간이 짧은 프로세스가 Ready Queue에 들어올 경우 새로 들어온 프로세스가 기존 프로세스의 CPU 점유를 빼앗아 점유할 수 있다.
우선순위 (Priority)
SJF와 SRT의 관계와 마찬가지로 비선점 우선순위 스케줄링 방식의 선점 방식인 선점 우선순위 스케줄링 방식이 있다.
라운드로빈 (Round-Robin)
FCFS 스케줄링 방식에 선점 스케줄링 방식과 Time Quantum 개념을 추가한 방식이다. 각 프로세스마다 CPU를 연속적으로 사용할 수 있는 시간에 제한을 두고, 이 시간을 Time Quantum이라고 한다. 어떤 프로세스가 CPU를 사용한 시간이 Time Quantum만큼 지나면 이 프로세스로부터 CPU 자원을 회수하고, 이 프로세스를 Ready Queue의 가장 뒤로 보내는 것이다.
라운드로빈 스케줄링 방식에선 Time Quantum을 얼마로 둘 지 잘 결정해야 한다. 만약 Time Quantum이 너무 크다면, CPU 처리 시간이 긴 프로세스가 CPU를 오래 점유하며 정작 다른 프로세스들은 이 프로세스의 작업이 끝날 때까지 기다려야 하기 때문에 결국 FCFS 스케줄링 방식에서 발생하던 호위 상태가 또 발생하기 때문이다. 그렇다고 Time Quantum을 너무 작게 두면, Context Switching이 너무 자주 발생하기 때문에 오버헤드가 커진다.
다단계 큐 (Multi-Level Queue)
프로세스를 어떤 프로세스냐에 따라서 여러 종류의 그룹으로 나누고, 그룹마다 Queue를 두는 방식이다. 한 마디로 Ready Queue를 여러 개로 나누어 사용하는 방식이다. 각각의 Queue마다 서로 다른 스케줄링 방식을 적용할 수도 있다. 이 방식에 대해서 이해하려면 먼저 Foregroud Queue와 Backgroud Queue에 대해서 알고 가야 한다.
운영체제는 프로세스를 분류할 때 사용자와 직접 상호작용하는 프로세스와 백그라운드에서 돌아가는 프로세스의 중요도를 다르게 분류한다. 사용자와 직접 상호작용하는 프로세스는 빠르게 처리되어야 하고, 백그라운드에서 일괄 처리되는 프로세스의 경우 덜 빠르게 처리되어도 괜찮다고 분류하는 것이다. 사람들은 대부분 지금 내가 보고 있는 프로세스와의 상호작용이 빠르게 처리되기를 바라지 일단 켜두고 오래 방치한 프로세스와 상호작용 하느라고 내가 보고 있는 프로세스에 렉이 걸리는 상황을 바라지는 않는다.
따라서 사용자와 직접 상호작용하는 프로세스가 모인 Foreground Queue에는 응답 시간을 줄이기 위해 라운드로빈 스케줄링 방식을 적용하고, 백그라운드에서 돌아가는 프로세스가 모인 Background Queue에는 응답 시간이 큰 의미가 없기 때문에 FCFS 스케줄링 방식을 적용하는 등 각 Queue마다 운영체제가 가장 적절하다고 판단하는 방식을 사용하게 된다.
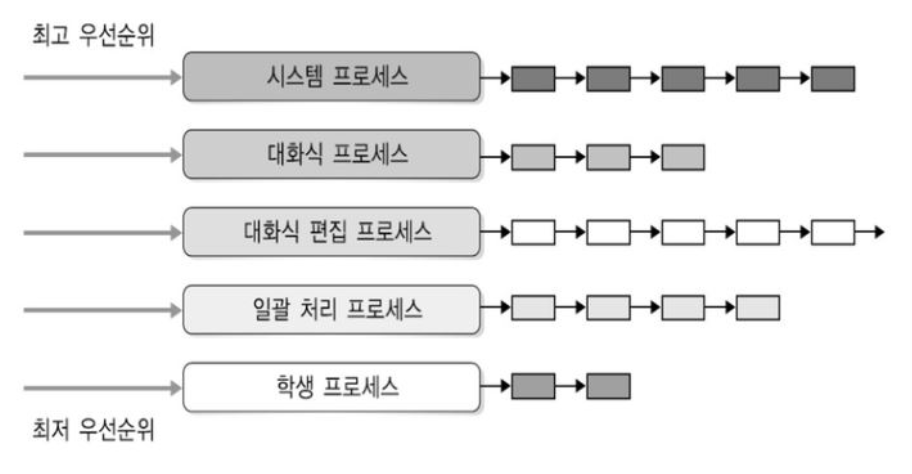
위 사진을 예로 들어 이해해보자. 위 사진에서 대화형 프로세스를 담기 위한 Foreground Queue에는 라운드로빈 스케줄링 방식을 적용하고, 프로세스 일괄처리가 필요한 Background Queue에는 일괄처리에 적합하다고 했던 비선점 방식 중 하나를 적용하면 될 것이다.
다만 다단계 큐 스케줄링 방식은 여러 개의 Queue를 사용하기 때문에 고려해야 할 점이 하나 더 생긴다. 바로 어떤 Queue에 얼마나 CPU를 오래 할당할 지 결정하는 스케줄링이 필요하게 된다. 이 스케줄링은 크게 두 가지 정도를 떠올릴 수 있다.
고정 우선순위 (Fixed Priority)
Queue마다 우선순위를 두는 방식이다. 우선순위가 높은 Queue에 처리해야 할 프로세스가 남아 있다면, 무조건 그 Queue에 남아 있는 프로세스를 처리한 뒤에 다음 우선순위의 Queue를 서비스한다. 이 방식은 사용자가 직접 원하는 프로세스에 CPU 자원을 우선 할당하기 때문에 좋아 보이지만 SJF 스케줄링 방식처럼 결국 우선순위가 낮은 Queue에 있는 프로세스는 무한정 기다려야 하는 상황이 발생할 수 있다. 모두들 기억하겠지만 이런 상태를 기아 상태라고 한다.
타임 슬라이스 (Time Slice)
고정 우선순위 스케줄링 방식에서 기아 상태가 발생할 수 있기 때문에 이를 해결하고자 생긴 스케줄링 방식이다. 운영체제가 Time Slice를 두고, 이 시간 비율에 따라서 각각의 Queue를 서비스하게 된다. 예를 들어 CPU 자원의 75%는 Foregroud Queue, 25%는 Background Queue를 서비스하는 데 할당할 수 있다.
다단계 피드백 큐 (Multi-Level Feedback Queue)
다단계 피드백 큐 스케줄링 방식은 다단계 큐 스케줄링 방식에 에이징 기법을 적용한 방식이다. 다단계 피드백 큐 스케줄링 방식에서는 다단계 큐 스케줄링 방식과 다르게 프로세스가 다른 큐로 이동할 수 있다. 우선순위가 낮은 큐에서 너무 오래 기다린 프로세스의 우선순위를 점점 올려서 우선순위가 높은 큐로 옮겨주는 방식이다. 이를 통해 다단계 큐 고정 우선순위 스케줄링 방식에서 발생할 수 있었던 기아 상태를 어느 정도 해결할 수 있게 된다.
결론
이렇게 스케줄링이 왜 필요한지부터, 실제로 스케줄링이 어떤 방식으로 진행되는지까지 알아보았다. 지금까지 배운 내용을 요약해보자.
우리는 컴퓨터를 사용할 때 수 많은 프로세스를 동시에 실행하게 된다. CPU는 한 번에 한 가지 작업만 처리할 수 있기 때문에, 이 프로세스들을 동시에 처리하(는 것처럼 보이게 하)기 위해 CPU는 어떤 프로세스에게 얼마나 많은 자원을, 얼마나 긴 시간 동안 할당해야 할 지 결정해야 한다. 프로세스를 빠르게 번갈아 처리해서 마치 동시에 프로세스가 실행되는 것처럼 보이게 하기 위해서다. 이를 결정하기 위한 방식, 즉 CPU 스케줄링 방식은 비선점, 선점 방식으로 분류할 수 있는 수많은 방식이 존재한다.
이전 포스팅에서 멀티스레드의 스케줄링은 운영체제가 처리하지 않기 때문에 프로그래머가 직접 동기화 문제에 대응할 수 있어야 한다고 언급했었다. 그러나 CPU 스케줄링은 멀티스레드와 다르게 운영체제가 사용자도 모르는 사이 자동으로 진행하는 작업이다. 이전 포스팅과 이번 포스팅 모두를 잘 이해했다면, 멀티프로세스와 멀티스레드의 원리적 차이부터 왜 프로세스와 스레드라는 방식으로 메모리를 공유하는지까지 어느 정도 알게 되었으리라 생각한다.
스레드 스케줄링
그런데, 결국 스레드도 스케줄링 해야 하지 않을까? 식제 작업을 수행하는 단위는 스레드이니 말이다.
스레드는 어떻게 스케줄링할까? 사실 스레드 스케줄링은 라이브러리에 의해 실행되기 때문에, 위에서 이야기한 스케줄링 알고리즘을 OS단에서 적용하지 않는다. 즉, OS는 커널 스레드만 신경쓰면 될 문제이다.
이 경우 스레드 라이브러리는 사용자 수준 스레드를 사용 가능한 범위에서 스케줄링 한다. 즉, 동일한 프로세스에 속한 스레드들이 CPU를 경쟁하기 때문에 스케줄링 기법을 PCS (Process-contention score; 프로세스-경쟁 범위)라고 한다. 그러나 스케줄링 한다고 해서 실제로 실행된다는 소리는 아니다. 왜냐하면 커널 스레드를 물리적인 CPU로 배정하기 위해 또 다른 스케줄링을 진행해야 하기 때문이다. 커널이 어떤 스레드를 스케줄 할 지 결정하기 위해선 SCS (System-contention score; 시스템-경쟁 범위)를 사용한다.
당연히 싱글 스레드 환경이라면 SCS만 사용할 것이다. 또한, PCS는 우선순위에 따라 행해지는 것이 일반적이나, 유저에 의해 우선순위가 조정될 수 있고 대부분의 스레드는 라이브러리 권한이 없다.
멀티코어 스케줄링
지금까지의 스케줄링은 CPU가 1개일때의 이야기이다. 만약에 CPU가 여러개라면? 그럴때는 부하 공유 (Load Sharing)이 가능해진다. 물론 스케줄링 문제는 이것까지 고려해야 하기 때문에 매우 복잡해진다.
크게 두 가지 방법으로 나누어본다면, 하나는 비대칭 다중 처리 (Asymmetric Multiprocessing)라고 하여 하나의 처리기를 주 서버라고 부르고, 이것으로 하여금 모든 스케줄링 결정과 I/O, 그리고 다른 시스템의 활동을 취급하게 하는 것을 말한다. 다만 주 서버에 문제가 생기면 전체 시스템에 병목현상이 발생할 수 있다.
다른 하나는 대칭 다중 처리 (Symmetric Multiprocessing, SMP)라고 하는데, 이 방식에서는 각자 독자적으로 스케줄링 한다. 모든 프로세스는 공동의 Ready Queue에 있거나 각 프로세서 마다의 Ready Queue에 있어야 한다. 다만 이 경우엔 동시에 여러 프로세서가 공동 Ready Queue에 접근하는 일이 없도록 잘 프로그래밍 되어야 한다.
현대적인 OS는 모두 SMP를 지원한다.
멀티코어의 경우 스케줄링이 조금 더 복잡해진다. 메모리 멈춤 (Memory Stall)이라고 하여 프로세서가 메모리를 접근할 때 데이터의 가용을 기다리면서 대기 시간이 길어지는 것인데, 이는 캐시 미스를 포함한 다양한 원인 때문에 발생한다. 그래서 이를 해결하기 위해 각 코어에 여러개의 하드웨어 스레드를 할당하고 스레드가 번갈아가면서 실행되는 방식을 도입했다.
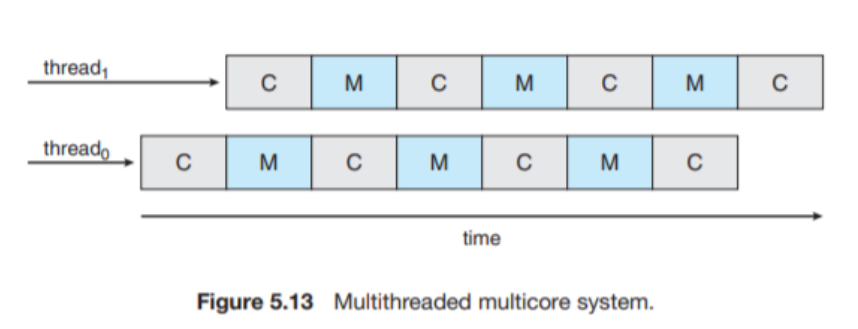
일반적으로 프로세서를 멀티스레딩화 하는데에는 두 방법이 있다. 하나는 Stall이 발생할 때까지 한 프로세서에서 실행되다가 긴 대기 시간이 발생하면 명령어 파이프라인을 정리하고 채우는 방식이고, 다른 하나는 명령어 주기의 경계처럼 세밀한 부분에서 교환을 시키는 방법이다.
동기&비동기 vs 블로킹&논블로킹 들어가기 전에
이 개념들을 처음 접하거나 컴퓨터 공학에 대해 잘 모르는 사람은 이 개념들이 서로 연관이 있는 것으로 오해하기 쉽다. 아무래도 동기와 블로킹, 비동기와 논블로킹의 작동 매커니즘이 더 직관적이기 때문에 많은 사람들이 이 개념들을 같은 것 혹은 비슷한 것으로 오해하고 있는데, 이 두가지 개념은 서로 전혀 다른 곳에 초점을 맞춘 개념들이므로 서로 직접적인 관련을 거의 없다고 봐도 된다. 단지 조합하여 사용되는 것 뿐이다.
동기와 비동기는 프로세스의 수행 순서 보장에 대한 매커니즘이고 블로킹과 논블로킹은 프로세스의 유휴 상태에 대한 개념으로 완전한 별개의 개념이다.

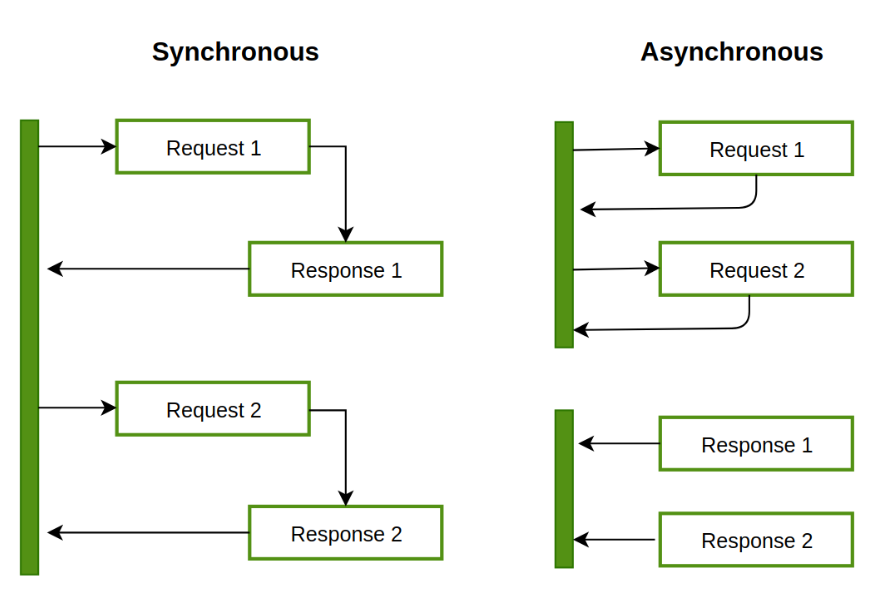
동기(Synchronous)& 비동기(Asynchronous)
동기와 비동기는 처리해야 할 작업들을 어떠한 "흐름" 으로 처리할 것인가에 대한 관점이다. 즉, 호출되는 함수의 작업 완료 여부를 신경쓰냐에 따라, 함수 실행/리턴 순차적인 흐름을 따르느냐, 안따르느냐가 관심사이다.

동기
호출하는 함수 A가 호출되는 함수 B의 작업 완료 후 리턴을 기다리거나, 바로 리턴 받더라도 미완료 상태라면 작업 완료 여부를 스스로 계속 확인하며 신경쓰면 Synchronous
(* 함수 A가 함수 B를 호출한 뒤, 함수 B의 리턴값을 계속 확인하면서 신경쓰는 것)
비동기
함수 A가 함수 B를 호출할 때 콜백 함수를 함께 전달해서, 함수 B의 작업이 완료되면 함께 보낸 콜백 함수를 실행한다.
함수 A는 함수 B를 호출한 후로 함수 B의 작업 완료 여부에는 신경쓰지 않는다. Asynchronous
블로킹(Blocking) vs 논블로킹(Non-Blocking)
블로킹과 논블로킹은 처리되어야 하는 (하나의)작업이 전체적인 작업의 "흐름"을 막느냐 안막느냐에 대한 관점이다. 즉, 제어권이 누구한테 있느냐가 관심사이다.

Blocking
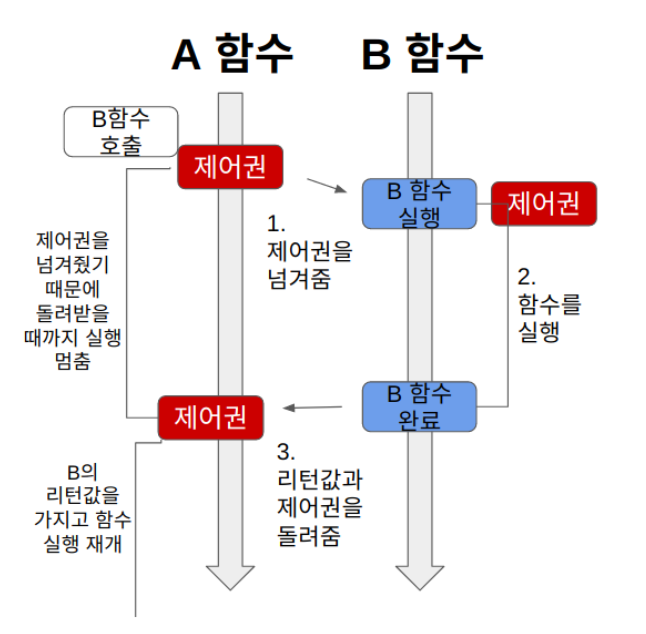
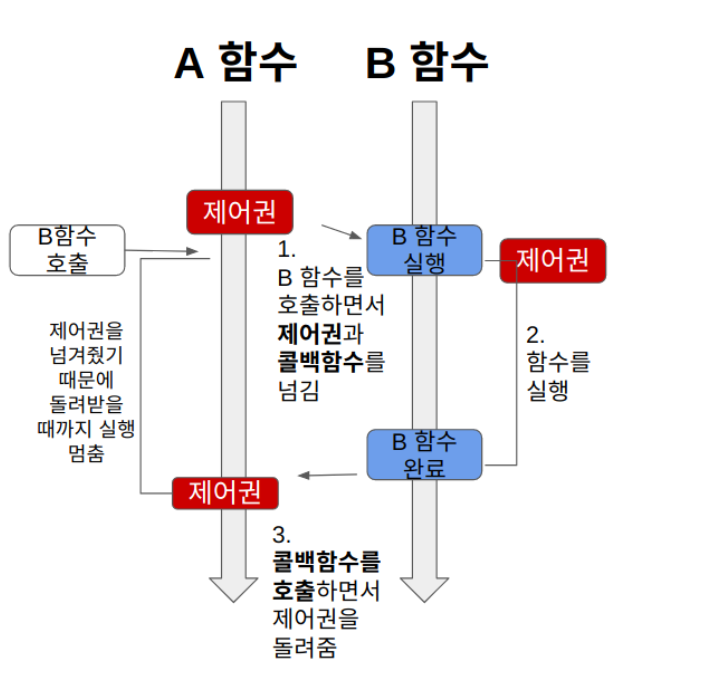
A 함수가 B 함수를 호출하면 제어권을 A가 호출한 B 함수에 넘겨준다.
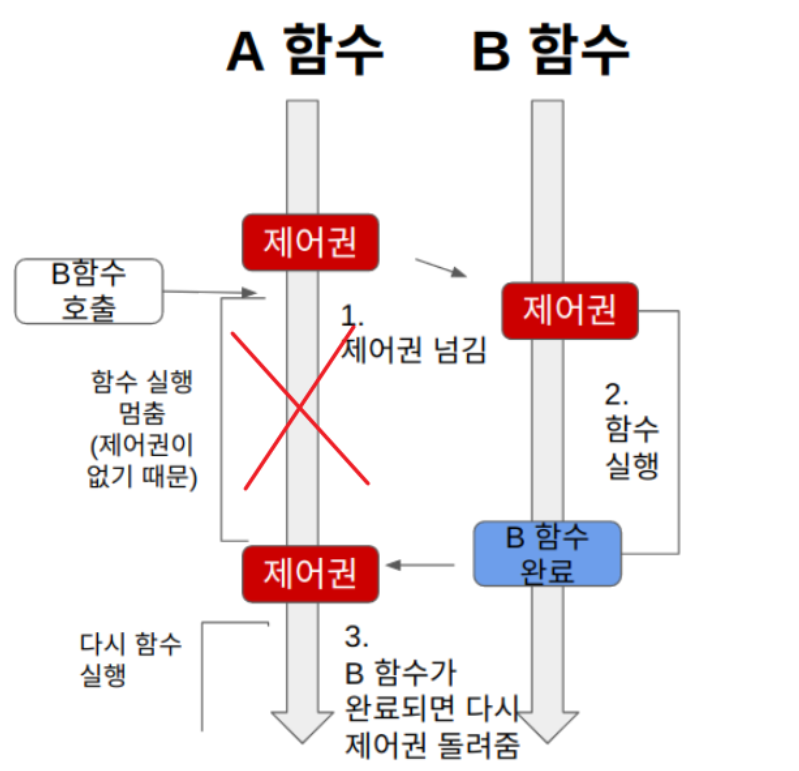
1. A 함수가 B 함수를 호출하면 B에게 제어권을 넘긴다.
2. 제어권을 넘겨받은 B는 열심히 함수를 실행한다. A는 B에게 제어권을 넘겨주었기 때문에 함수 실행을 잠시 멈춘다.
3. B 함수는 실행이 끝나면 자신을 호출한 A에게 제어권을 돌려준다.
Non-Blocking
A 함수가 B 함수를 호출해도 제어권은 그대로 자신이 가지고 있는다.
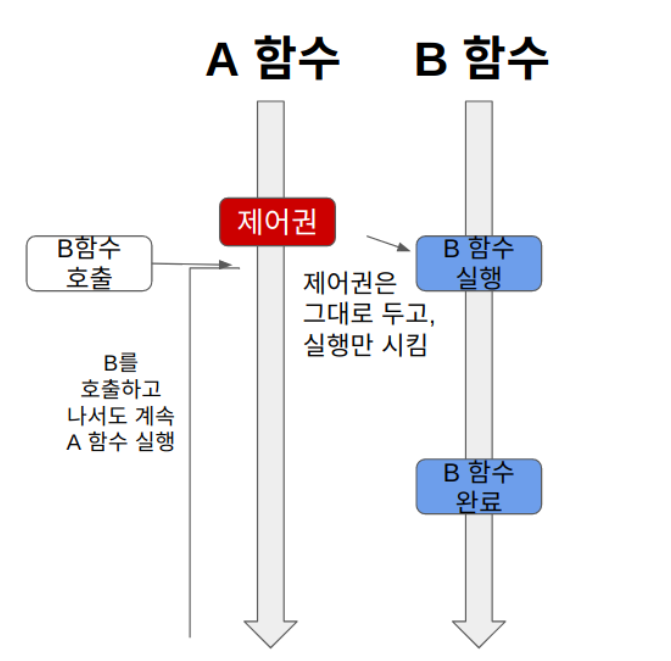
1. A 함수가 B 함수를 호출하면, B 함수는 실행되지만, 제어권은 A 함수가 그대로 가지고 있는다.
2. A 함수는 계속 제어권을 가지고 있기 때문에 B 함수를 호출한 이후에도 자신의 코드를 계속 실행한다.
동기&비동기 + 블로킹&논블로킹 조합
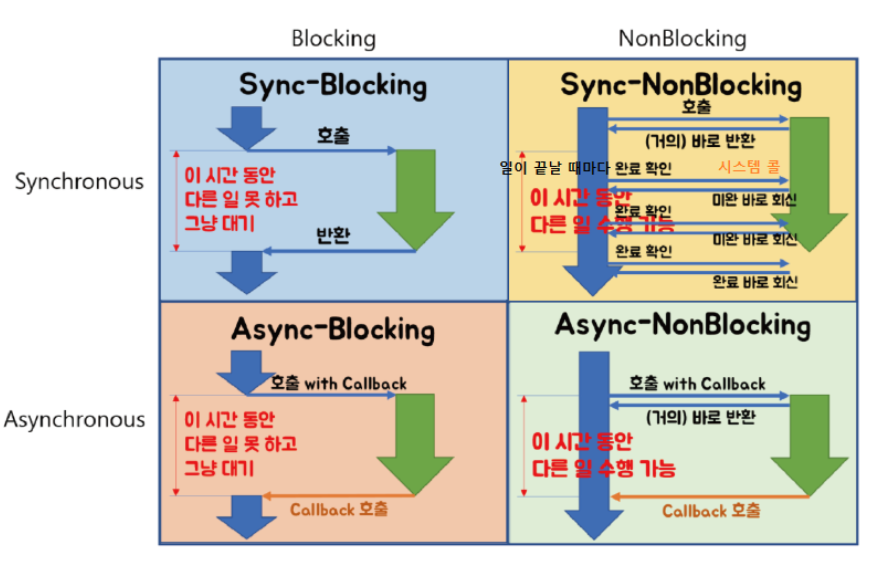
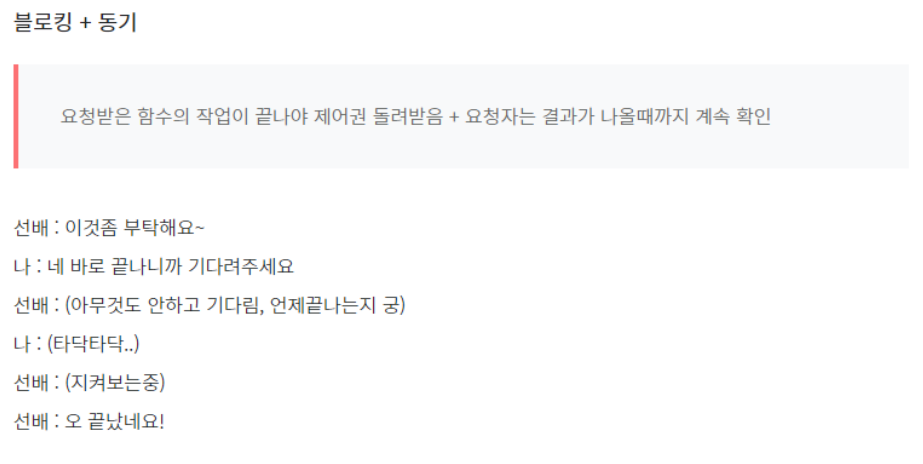
1. Sync + Blocking
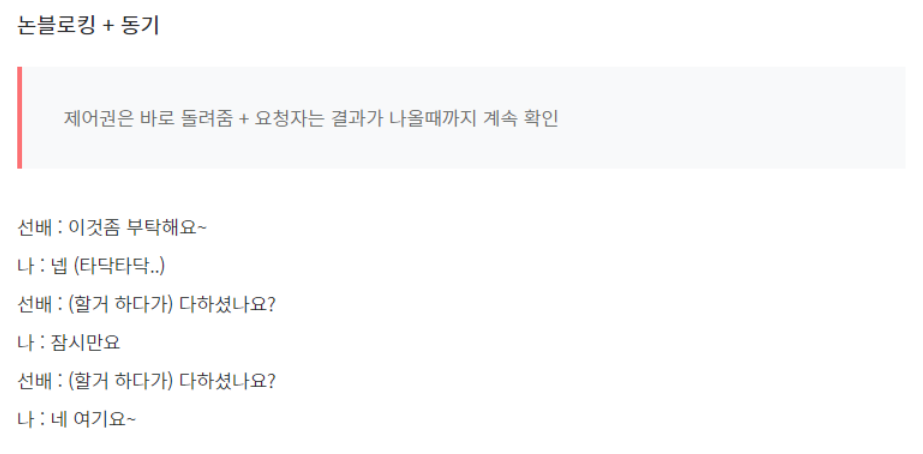
함수 A는 함수 B의 리턴값을 필요로 한다. (동기)
그래서 제어권을 함수 B에게 넘겨주고, 함수 B가 실행을 완료하여 리턴값과 제어권을 돌려줄 때까지 기다린다. (블로킹)

2. Sync + Nonblocking
A 함수는 B 함수를 호출한다.
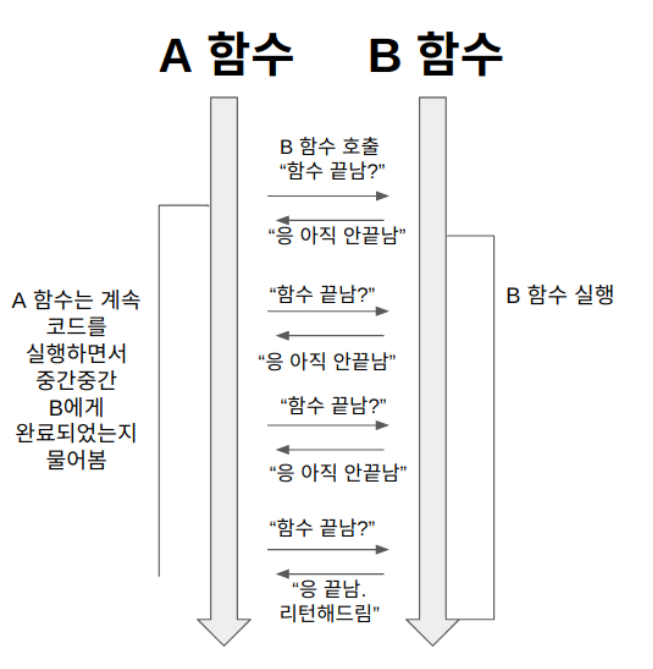
이 때 A 함수는 B 함수에게 제어권을 주지 않고, 자신의 코드를 계속 실행한다. (논블로킹) 그런데 A 함수는 B 함수의 리턴값이 필요하기 때문에, 중간중간 B 함수에게 함수 실행을 완료했는지 물어본다. (동기)

3. Async + Nonblocking
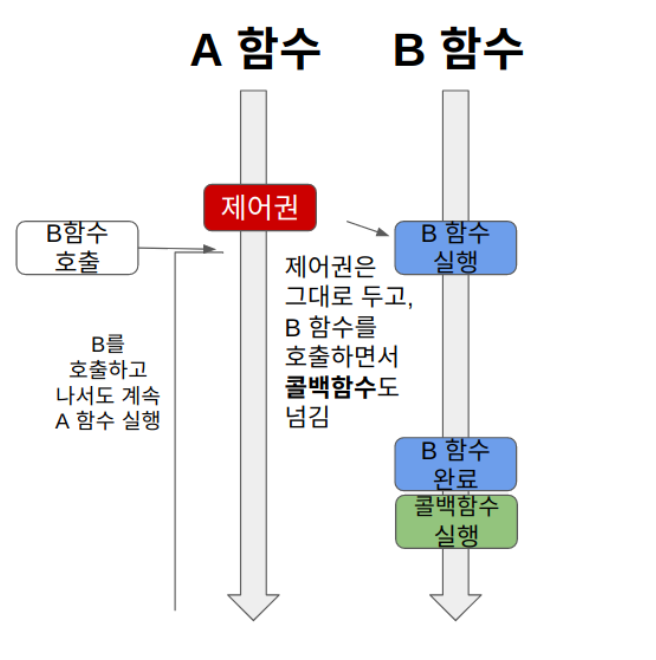
A 함수는 B 함수를 호출한다.
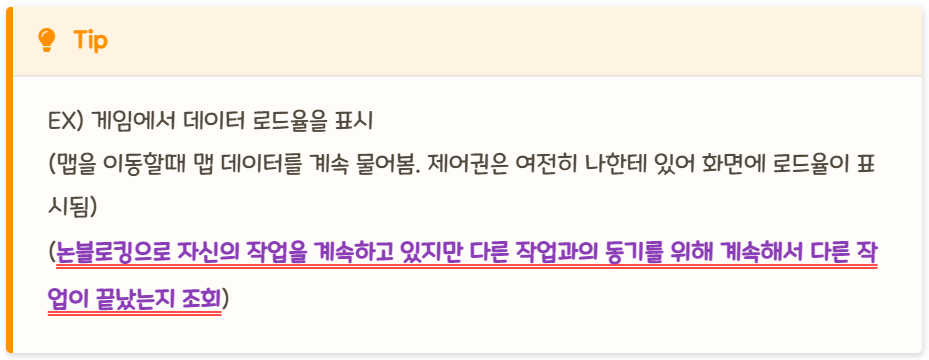
이 때 제어권을 B 함수에 주지 않고, 자신이 계속 가지고 있는다. 따라서 B 함수를 호출한 이후에도 멈추지 않고 자신의 코드를 계속 실행한다. (논블로킹)
그리고 B 함수를 호출할 때 콜백 함수를 함께 준다. B 함수는 자신의 작업이 끝나면 A 함수가 준 콜백 함수를 실행한다. (비동기)

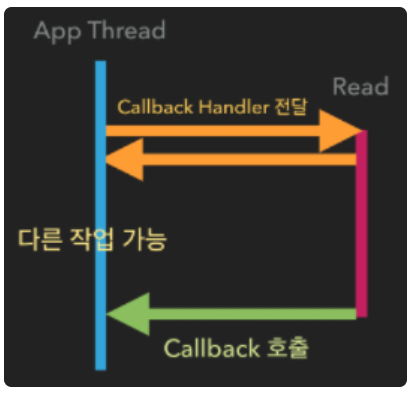
4. Async + Blocking
Async + Blocking의 경우는 사실 잘 마주하기 쉽지 않다. 그냥 넘어가도 된다.
A 함수는 B 함수의 리턴값에 신경쓰지 않고, 콜백함수를 보낸다. (비동기)
그런데, B 함수의 작업에 관심없음에도 불구하고, A 함수는 B 함수에게 제어권을 넘긴다. (블로킹) 따라서, A 함수는 자신과 관련 없는 B 함수의 작업이 끝날 때까지 기다려야 한다.
코드로 보는 동기&비동기 + 블로킹&논블로킹 조합
1. Sync - Blocking
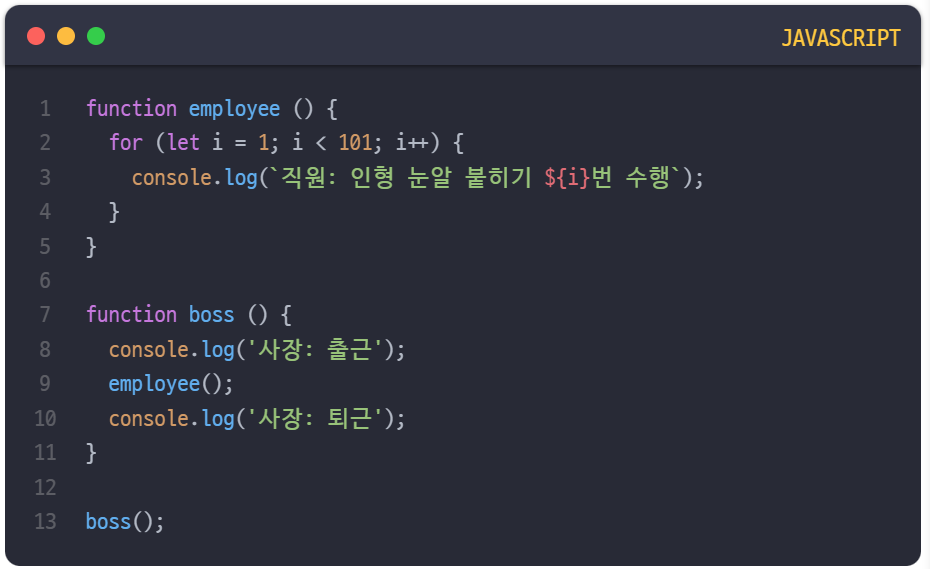
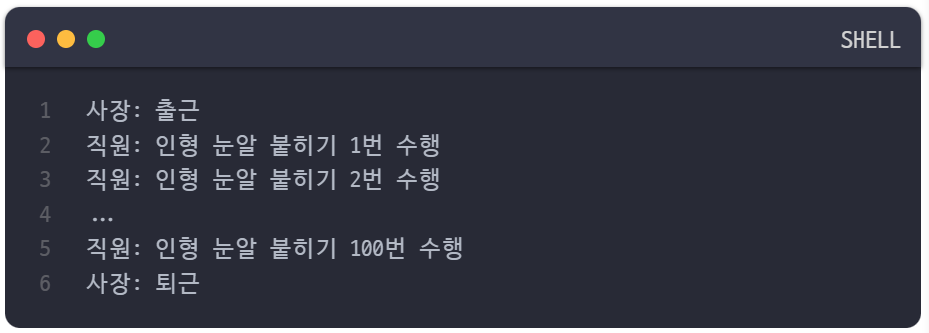

모든 인형의 눈알을 다 붙이기 전까지 퇴근은 없다.
상위 프로세스인 boss 함수는 출근 작업을 수행한 뒤 하위 프로세스인 employee 함수에게 인형 눈알 붙이기 작업을 요청하고 있고, 이 인형 눈알 붙이기 작업이 완료되고 나서야 boss 함수는 퇴근 작업을 수행한다.
쉽게 말해서 작업을 시킨 놈인 상위 프로세스는 작업을 하는 놈인 하위 프로세스가 종료될 때까지 절대 퇴근할 수 없다는 것이다.
이 예제와 같이 동기 방식과 블로킹 방식을 함께 사용하는 매커니즘은 일반적으로 사람들이 동기 방식이라고 하면 가장 먼저 떠올리는 방식이고 직관적으로 이해하기도 쉬운 편이다.
그렇다면 이 예제와 같이 동기적인 작업의 흐름을 유지하면서 employee 함수가 인형의 눈알을 붙이는 동안 boss 함수가 다른 일을 할 수도 있을까?
2. Sync - Nonblocking
물론 할 수 있다. 뭐가 어찌됐건 동기라는 것은 작업들이 순차적인 흐름을 가지고 있다는 것을 의미하기 때문에, 이 전제만 지켜진다면 나머지는 어떻게 지지고 볶든 간에 동기 방식이라는 것은 변하지 않기 때문이다.
그래서 동기 == 블로킹이라고 말할 수 없는 것이다.
JavaScript의 제너레이터를 사용하면 작업의 순서를 지키면서도 상위 프로세스가 다른 작업을 하도록 만들 수 있다.
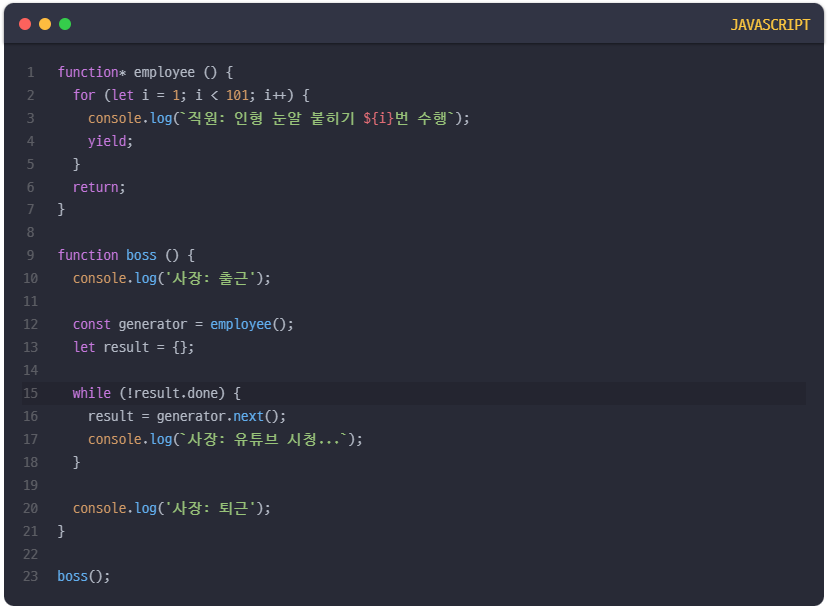
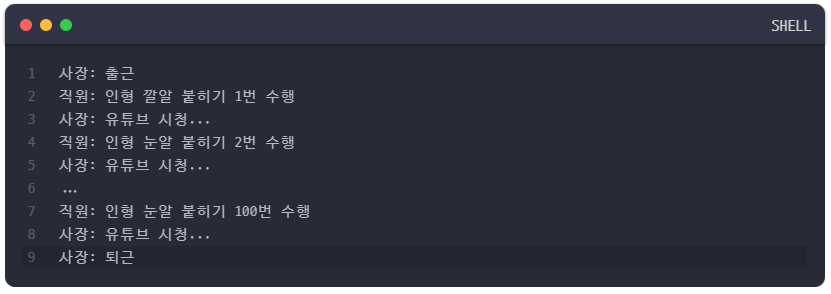
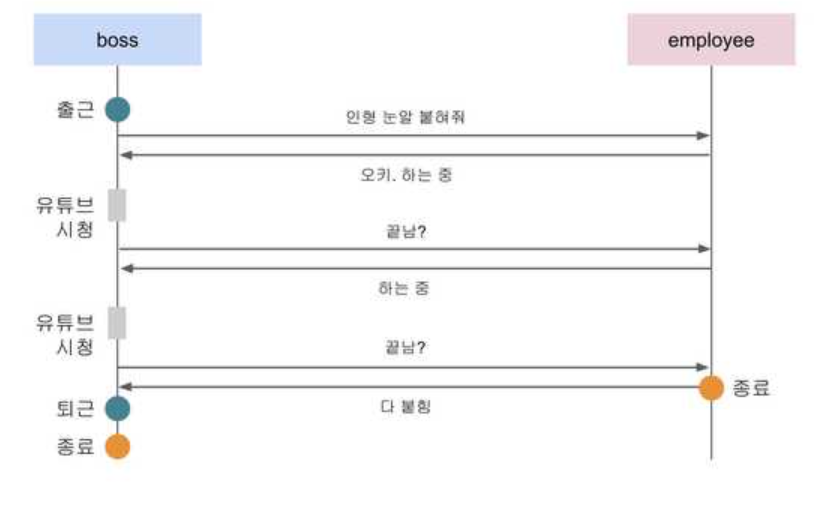
이 예제를 보면 상위 프로세스인 boss 함수는 출근한 후 하위 프로세스인 employee를 호출하여 인형 눈알 붙이기 작업을 시키고 주기적으로 이 작업이 끝났는지를 검사하고 있다.
그리고 아직 작업이 끝나지 않았다면 자신 또한 열심히 유튜브 시청을 수행하는 것을 볼 수 있다. 이 코드는 분명히 동기적인 흐름을 가지고 진행하고 있지만 boss 함수 또한 중간중간 자신의 작업을 수행하고 있으므로 블로킹이 아니라 논블로킹 방식을 사용하고 있는 것이다.
이 예제에서도 동기&블로킹 방식과 마찬가지로 boss 함수는 employee 함수의 작업이 끝나기 전까지는 절대 퇴근할 수 없다. 작업의 순서가 지켜지고 있는 것이다. 즉, 동기 방식이라는 것은 작업의 순차적인 흐름만 지켜진다면 블로킹이든 논블로킹이든 아무 상관이 없다고 할 수 있다.
3. Async - Nonblocking
비동기 방식과 논블로킹 방식을 조합한 방법은 우리에게 굉장히 익숙한 방식이다.
비동기 방식이기 때문에 상위 프로세스는 하위 프로세스의 작업 완료 여부를 따로 신경쓰지 않는다. 이후 하위 프로세스의 작업이 종료되면 스스로 상위 프로세스에게 보고를 하든 아니면 다른 프로세스에게 일을 맡기든 할 것이다.
그리고 논블로킹 방식이기 때문에 상위 프로세스는 하위 프로세스에게 일을 맡기고 자신의 작업을 계속 수행할 수도 있다.
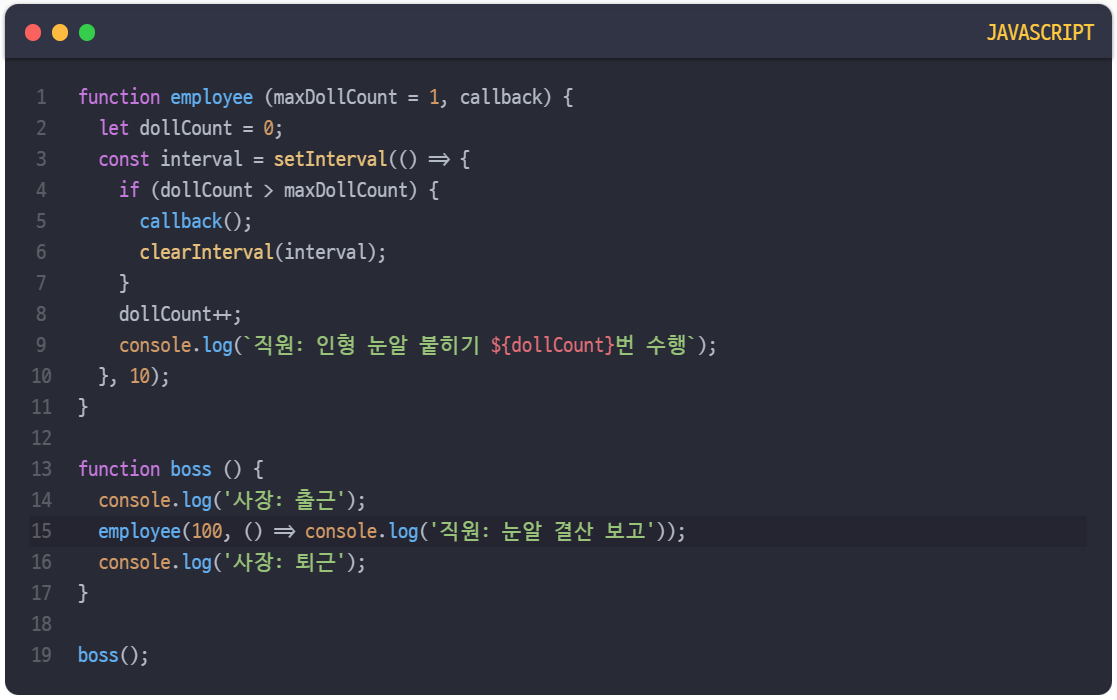
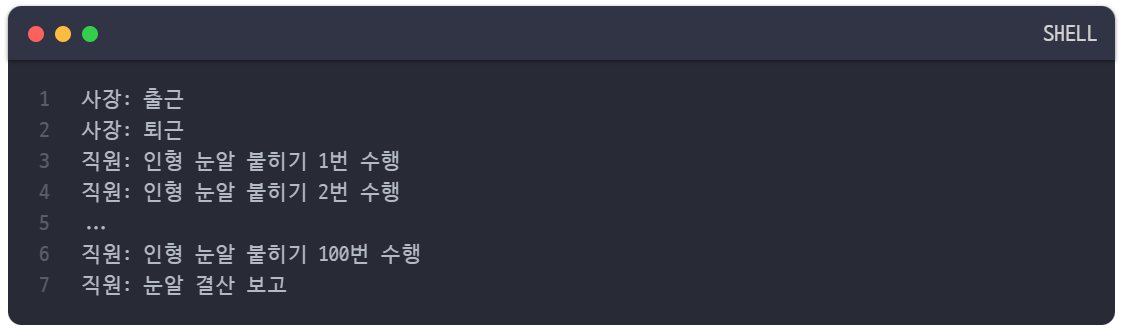
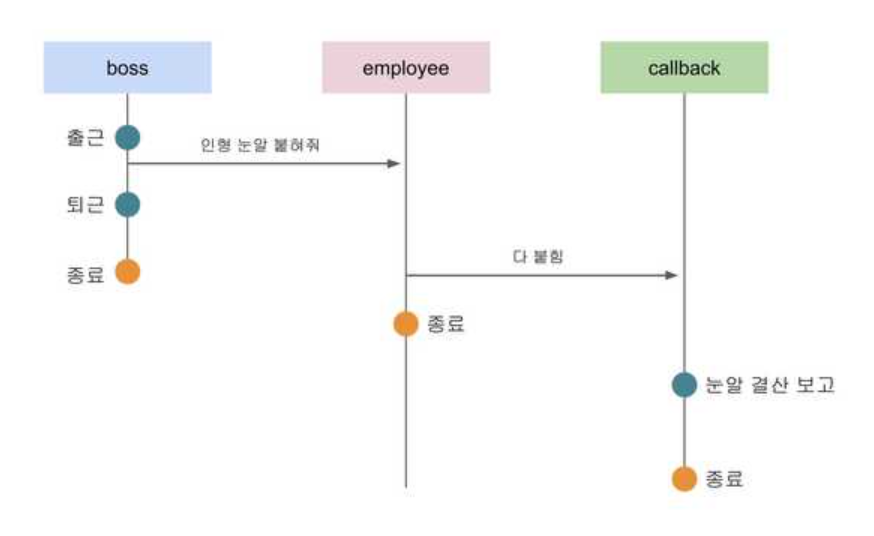
이 예제를 보면 boss 함수는 employee 함수에게 인형 눈알 100개를 붙이라고 지시한 후 자신은 바로 퇴근해버렸다. 상위 프로세스인 boss 함수는 employee 함수의 작업이 언제 끝나는지 관심이 없으며, 작업의 완료 신호는 콜백으로 넘겨진 눈알 결산 보고 작업이 대신 받아서 처리하고 있다.

동기/비동기, 블로킹/논블로킹 요약
동기/비동기 = 요청받은 함수가 작업을 완료했는지를 체크해서 순차적 흐름의 차이
동기: 요청자가 요청받은 함수의 작업이 완료되었는지 계속 확인 (여러 함수들이 시간을 맞춰 실행됨)
비동기: 요청자는 요청 후 신경X, 요청받은 함수가 작업을 마치면 알려줌 (함수들의 작업 시작/종료 시간이 맞지 않을수도)
블로킹/논블로킹 = 요청받는 함수가 제어권(함수 실행권)을 언제 넘겨주느냐의 차이
블로킹: 요청받는 함수가 작업을 모두 마치고 나서야 요청자에게 제어권을 넘겨줌 (그동안 요청자는 아무것도 하지않고 기다림)
논블로킹: 요청받은 함수가 요청자에게 제어권을 바로 넘겨줌 (그동안 요청자는 다른 일을 할 수 있음)
Dead Lock/Race Condition
Dead Lock (교착 상태)
두 개 이상의 프로세스나 스레드가 서로 자원을 얻지 못해서 다음 처리를 하지 못하는 상태이다. 즉, 무한히 다음 자원을 기다리게 되는 상태로 시스템적으로 한정된 자원을 여려 곳에서 사용하려고 할 때 발생한다.
데드락이 발생하는 경우
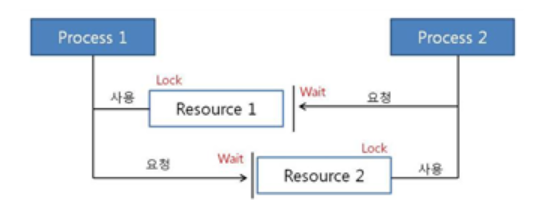
프로세스 1과 2가 자원1, 2를 모두 얻어야 한다고 가정해보자.
t1: 프로세스1이 자원1을 얻음 / 프로세스2가 자원2를 얻음
t2: 프로세스1은 자원2를 기다림 / 프로세스2는 자원1을 기다림
이처럼 현재 서로 원하는 자원이 상대방에게 할당되어 있어서 두 프로세스는 무한정 wait 상태에 빠진다. 이것이 바로 DeadLock이다.
멀티 프로그래밍 환경에서 한정된 자원을 얻기 위해 서로 경쟁하는 상황이 발생한다. 한 프로세스가 자원을 요청했을 때, 동시에 그 자원을 사용할 수 없는 상황이 발생할 수 있다. 이때 프로세스는 대기 상태로 들어간다. 대기 상태로 들어간 프로세스들이 실행 상태로 변경될 수 없을 때 "교착 상태"가 발생한다.
데드락 (DeadLock) 발생 조건
아래 4가지 경우가 모두 성립해야 데드락이 발생한다. 하나라도 성립하지 않으면 데드락 문제 해결이 가능하다.
1. 상호 배제(Mutual exclusion)
자원은 한번에 한 프로세스만 사용할 수 있다.
2. 점유 대기(Hold and wait)
최소한 하나의 자원을 점유하고 있으면서 다른 프로세스에 할당되어 사용되고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 존재해야 한다.
3. 비선점(No preemption)
다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없다.
4. 순환 대기(Circular wait)
프로세스의 집합에서 순환 형태로 자원을 대기하고 있어야 한다. 즉, 자원을 기다리는 프로세스 간에 사이클이 형성되어야 한다.
ex) 프로세스 p0, p1, ..., pn이 있을 때 p0은 p1을 기다리고 p1은 p2를 기다리고, ..., pn은 p0을 기다린다.
데드락 (DeadLock) 처리
교착 상태를 예방 & 회피
1. 예방(prevention)
교착 상태 발생 조건 중 하나를 제거하면서 해결한다. 그러나 이 방법은 효율성과 처리량을 감소시키고, Starvation이 발생할 수 있다.
- 상호배제 부정: 여러 프로세스가 공유 자원 사용
- 점유대기 부정: 프로세스가 자원을 요청할 때 다른 어떤 자원도 가지고 있지 않도록 해야 한다. 따라서 프로세스를 시작할 때 모든 필요한 자원을 할당받게 하거나, 자원이 필요한 경우 보유하고 있던 자원을 모두 반납하고 다시 요청하는 방식을 이용할 수 있다.
- 비선점 부정: 프로세스가 어떤 자원을 기다려야 하는 경우 점유하고 있던 자원을 반납한다. 그리고 모든 필요한 자원을 얻을 수 있을 때 그 프로세스는 다시 시작된다.
- 순환대기 부정: 자원의 타입에 따라 프로세스마다 할당 순서를 정하여 정해진 순서대로만 자원을 할당한다.
2. 회피(avoidance)
Deadlock Avoidance는 Deadlock이 발생할 가능성이 있는 경우엔 아예 자원을 할당하지 않는 방식이다. 가장 단순하고 일반적인 모델은 프로세스들이 필요로 하는 각 자원별 최대 사용량을 미리 선언하도록 하는 방법이다.
먼저 다음 두 용어를 정의하자.
- Safe Sequence: 프로세스의 sequence <P1, P2, ..., Pn>이 있을 때, Pi의 자원 요청이 '가용 자원 + 모든 Pj(j<i)의 보유 자원'에 의해 충족되는 경우 sequence를 safe 하다고 말한다.
safe state: 시스템 내의 프로세스들에 대한 Safe Sequence가 존재하는 상태
만약 시스템이 Safe state에 있으면 Deadlock이 발생하지 않는다. 하지만 Unsafe state에 있으면 Deadlock이 발생할 수 있다. 따라서, Deadlock Avoidance는 시스템이 Unsafe state에 들어가지 않는 것을 보장하는 것이다.
두 경우의 Avoidance 알고리즘이 있는데, 각 자원 타입마다 하나의 인스턴스가 존재하는 경우 자원 할당 그래프 알고리즘을 사용하고, 여러 인스턴스가 존재하는 경우 Banker's 알고리즘을 사용한다.
- Resource Allocation Graph Algorithm (자원 할당 그래프 알고리즘)
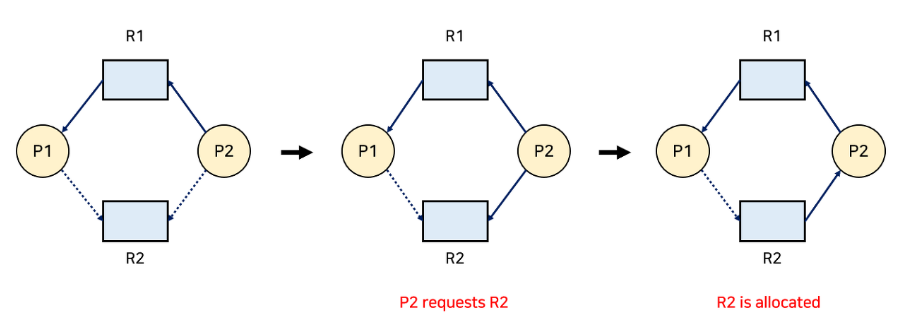
점선으로 표시된 간선(Claim edge)은 프로세스가 자원을 미래에 요청할 수 있음을 의미한다. 그리고 해당 자원을 요청하는 경우 실선(Request edge)으로 바뀌게 된다. 자원을 할당받으면 방향이 반대인 간선(Assignment edge)이 된다. 만약 자원을 다 쓰고 반납하게 되면 다시 Claim edge로 바뀐다.
Deadlock을 피하는 방법은, Request edge가 Assignment edge로 변경될 때 점선을 포함하여 사이클이 생기지 않는 경우에만 요청된 자원을 할당한다.
- 은행원 알고리즘 (Banker's Algorithm)
여러 인스턴스가 존재하는 경우에는 사이클만으로 판단할 수 없다. Banker's Algorithm은 dijkstra가 고안한 알고리즘이며, 이는 프로세스가 자원을 요청할 때마다 수행된다.
<가정>
- 모든 프로세스는 자원의 최대 사용량을 미리 명시한다.
- 프로세스가 요청 자원을 모두 할당받은 경우 유한 시간 안에 자원들을 다시 반납한다.
기본적인 개념은, 자원을 요청할 때 safe 상태를 유지하는 경우에만 할당한다. 즉, 어떤 자원의 할당을 허용하는지에 관한 여부를 결정하기 전에 미리 결정된 모든 자원들의 최대 가능한 할당량을 가지고 시뮬레이션해서 safe state에 들 수 있는지 여부를 검사한다. 다시 말해, 대기중인 다른 프로세스들의 활동에 대한 교착 상태 가능성을 미리 조사하는 것이다. 만약 그런 프로세스가 없다면 unsafe 상태인 것이다. 할당받은 프로세스가 종료되면 모든 자원을 반납하고, 모든 프로세스가 종료될 때까지 이 과정을 반복한다.
어떤 자원 한 가지에 대해서 은행원 알고리즘 시뮬레이션을 해보자.
처음에 시스템이 총 12개의 자원을 가지고 있다고 가정해보자.
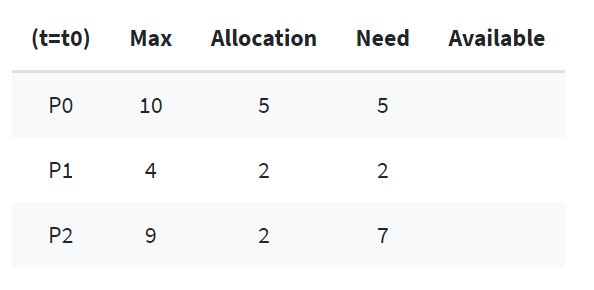
p0~p2는 프로세스이고, Max는 각 프로세스마다 최대 자원 요청량, Allocation은 현재 프로세스에 할당 중인 자원의 양, Need는 남은 필요한 자원의 양(Max-Allocation)이다.
현재 t0일 때 프로세스에 할당된 자원의 합은 5+2+2=9개이다. 따라서 현재 Available 자원은 12-9=3개이다.
여기서 Safe sequence를 찾아보려고 한다. 순서가 <P1, P0, P2> 일 때 안전 순서를 만족한다.
P1은 2개가 이미 할당되어 있고, 2개를 추가적으로 할당받기를(Need) 기다리고 있다. 현재 Available 자원은 3개이므로, 이 중에 2개를 P1에게 할당해 준다. → 현재 Available은 3-2=1개- 실행이 끝난
P1은 자신에게 할당되어 있던 자원 4개를 모두 반납한다. → 현재 Available은 1+4=5개 - 현재 Available 자원이 5개이고, 이를 P0에게 모두 할당해 주면 P0도 실행 가능해진다. → 현재 Available은 5-5=0개가 된다.
- 실행이 끝난
P0은 자신에게 할당되어 있던 자원 10개를 모두 반납합니다. → 현재 Available은 0+10=10개 - 마지막으로
P2에게 자원 7개를 할당해준다. → 현재 Available은 10-7=3개 - 실행이 끝난
P2는 자신에게 할당되어 있던 자원 9개를 모두 반납한다 → 현재 Available은 3+9=12개
이렇게 자원의 부족함 없이 올바르게 할당하여 모든 프로세스가 실행을 할 수 있다.
만약 여기에서 P2 프로세스가 처음에 자원을 하나 더 할당받고 있었다면 (즉, 2개가 아니라 3개) 운영체제가 가지고 있는 Available 자원은 12-(5+2+3)=2개였을 것이다.
이 상황에서는 처음에 P1에게 2개를 모두 주고, P1이 실행이 끝나고 자원을 모두 반납해도 Available 자원은 2+2=4개 뿐이므로, 이 자원으로는 나머지 P0이나 P2 프로세스를 해결해 줄 수 없다. (모두 4개보다 많은 양의 자원을 필요로 하고 있으므로)
따라서, P0과 P2는 자원을 할당받기를 계속 기다려야 할 것이다.
운영체제가 사전에 P2 프로세스가 자원을 하나 더 요청했을 때 할당해 주지 않고, P1이 먼저 끝나게 한다면 데드락이 발생하지 않았을 것이다. 그러므로 은행원 알고리즘을 사용해서 자원 할당량을 사전에 파악하고 데드락을 회피할 수 있도록 하면 될 것이다.
그러나 은행원 알고리즘의 경우, 이처럼 미리 최대 자원 요구량을 알아야 하고, 할당할 수 있는 자원 수가 일정해야 하는 등 사용에 있어 제약조건이 많고, 그에 따른 자원 이용도 하락 등 단점도 존재한다.
교착 상태를 탐지 & 회복
Deadlock이 발생했는지는 Deadlock을 미리 회피하는 방법과 유사하게 확인할 수 있다. 그래프를 통해서 사이클이 생겼는지를 확인하거나, 총 요청 자원의 수가 남은 자원의 수보다 적은 프로세스가 존재하지 않는다는 것을 이용하여 확인할 수 있다.
그렇다면 Deadlock을 해결하기 위해 어떤 프로세스를 종료시켜야 할까? 여기에는 몇가지 판단 기준이 있다.
- 프로세스의 중요도
- 프로세스가 얼마나 오래 실행됐는가
- 얼마나 많은 자원을 사용했는가
- 프로세스가 작업을 마치기 위해 얼마나 많은 자원이 필요한가
- 프로세스가 종료되기 위해 얼마나 많은 자원이 필요한가
- 프로세스가 batch인가 interactive인가
해결하는 방법으로는 프로세스를 종료시키거나 자원을 선점하는 방법이 있다. 프로세스를 종료시킬 때는 Deadlock에 빠진 모든 프로세스를 종료하거나, Deadlock이 해결될 때까지 한 번에 한 프로세스씩 종료시킬 수 있다.
자원을 선점할 땐 어떤 프로세스를 종료시킬지 결정(Selceting a victim)하고, Deadlock이 발생하기 전 상태로 돌아가(Rollback) 프로세스를 재시작한다. 이때 동일한 프로세스가 계속해서 victim으로 선정되는 경우 Starvation이 발생할 수도 있다. 이는 Rollback된 횟수를 저장함으로써 해결할 수 있다.
3. Deadlock Ignorance
Deadlock이 일어나지 않는다고 생각하고 아무런 조치도 취하지 않는 방식이다.
그 이유는, Deadlock이 매우 드물게 발생하기 때문에 Deadlock에 대한 조치 자체가 더 큰 오버헤드일 수 있기 때문이다. 따라서 만약 시스템에 Deadlock이 발생한 경우, 시스템이 비정상적으로 작동하는 것을 사람이 느낀 후 직접 프로세스를 죽이는 등의 방법으로 대처한다. 이 방식은 UNIX, Windows 등 대부분의 범용 운영체제가 채택하는 방식이다.
경쟁 상태(Race Condition)
경쟁 상태는 공유 자원에 대해 여러 프로세스가 동시에 접근할 때, 결과값에 영향을 줄 수 있는 상태를 말한다. 동시 접근 시 자료의 일관성을 해치는 결과가 나타난다.
임계 영역(Critical Section)
예를 들어, 통장에 돈이 100만원 있다고 가정해보자. 지난 달에 친구에게 빌렸던 50만원을 갚으려고 이체를 하고 있다. 계좌번호와 금액을 입력하고 송금 버튼을 눌렀다. 그런데, 오늘 마침 카드값 70만원이 빠져나가는 날이다. 정말 우연히 친구에게 보내는 이체와 카드 값 이체가 동시에 일어났다. 두 이체가 통장에 있는 잔액을 확인했을 때 100만원이어서 두 이체 모두 성공했다면 은행에 비상이 걸리고, 이런 일이 반복된다면 은행은 곧 파산할 것이다.
이처럼 통장에 동시에 접근하게 되면 곤란한 문제가 생길 수 있다. 통장에 아무나 접근하지 못하게 보호를 해야된다. 통장처럼 보호되어야 하는 부분을 Critical Section(임계 영역) 이라고 한다. Critical Section에 접근하려면 각 프로세스의 code segment에 공유 데이터에 접근하는 코드를 사용한다.
Race Condition이 발생하는 경우
1. 커널 작업을 수행하는 중에 인터럽트 발생
- 문제점: 커널 모드에서 데이터를 로드하여 작업을 수행하다가 인터럽트가 발생하여 같은 데이터를 조작하는 경우 → 사용자 프로세스는 해당 프로세스에 할당 받은 메모리에만 존재할 수 있지만 커널은 서로 다른 프로세스가 공유하기 때문에 발생
- 해결법: 커널 모드에서 작업을 수행하는 동안, 인터럽트를 disable 시켜 CPU 제어권을 가져가지 못하도록 한다.
2. 프로세스가 'System Call'을 하여 커널 모드로 진입하여 작업을 수행하는 도중 Context Switching'이 발생할 때
- 문제점: 프로세스1이 커널모드에서 데이터를 조작하는 도중, 시간이 초과되어 CPU 제어권이 프로세스2로 넘어가 같은 데이터를 조작하는 경우 (프로세스2가 작업에 반영되지 않음)
- 해결법: 프로세스가 커널모드에서 작업을 하는 경우 시간이 초과되어도 CPU 제어권이 다른 프로세스에게 넘어가지 않도록 한다.
3. 멀티 프로세서 환경에서 공유 메모리 내의 커널 데이터에 접근할 때
- 문제점: 멀티 프로세서 환경에서 2개의 CPU가 동시에 커널 내부의 공유 데이터에 접근하여 조작하는 경우
- 해결법: 커널 내부에 있는 각 공유 데이터에 접근할 때마다, 그 데이터에 대한 lock/unlock을 하는 방법이 있다. → 매 순간 그 데이터에 접근하는 프로세스는 1개
Race Condition 해결을 위한 충족 조건 3가지
1. Mutual Exclusion (상호 배제)
어떤 프로세스가 임계 영역을 수행 중이면 다른 모든 프로세스들은 그 임계 영역에 들어가지 못하게 막는 것이다.
2. Progress (진행)
임계 영역에 들어간 프로세스가 있지 않은 상태에서 임계 영역에 들어가려는 프로세스가 있으면 들어가게 해주어야 한다. 즉, 임계 영역에 있는 프로세스 외에는 다른 프로세스가 임계 영역에 진입하는 것을 방해하면 안된다.
3. Bounded Waiting (한정 대기)
기아(starvation) 상태를 방지하기 위해 프로세스가 임계 영역에 들어가려고 요청한 후부터 다른 프로세스들이 임계 영역에 들어가는 횟수에 한계가 있어야 한다. 임계 영역에 한 번 들어갔다 나온 프로세스는 다음에 들어갈 때 제한을 준다.
Reference
https://huistorage.tistory.com/111
https://doh-an.tistory.com/31
https://oizys.tistory.com/4
https://velog.io/@raejoonee/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C%EC%9D%98-CPU-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%A7%81
https://velog.io/@klm03025/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-Context-Switching%EC%8A%A4%EC%BC%80%EC%A5%B4%EB%A7%81
https://rebro.kr/177
https://zangzangs.tistory.com/115
https://evan-moon.github.io/2019/09/19/sync-async-blocking-non-blocking/#%EB%8F%99%EA%B8%B0-%EB%B0%A9%EC%8B%9D--%EB%85%BC%EB%B8%94%EB%A1%9D%ED%82%B9-%EB%B0%A9%EC%8B%9D
