- 프로세스와 스레드의 차이
- 프로세스 주소 공간
- PCB/Context Swiching
- 스케줄러의 종류
프로세스와 스레드의 차이
- 프로세스: 운영체제로부터 자원을 할당받은 작업의 단위
- 스레드: 프로세스가 할당받은 자원을 이용하는 실행 흐름의 단위
프로세스(Process)
프로세스라는 명칭은 낯설 수 있는데, 프로그램은 친숙하리라 생각한다.
우리가 흔히 말하는 프로그램이 실행되면 프로세스 인스턴스가 생성된다.
인스턴스가 생성된다는 의미는 프로그램 실행에 필요한 내용이 컴퓨터 메모리(Ram)에 적재된다는 뜻이다. 일반적으로 프로세스와 프로그램을 같은 개념으로 이야기할 때가 많다. 하지만 엄밀히 따지면 이 둘은 다른 개념이다.
스레드(Thread)
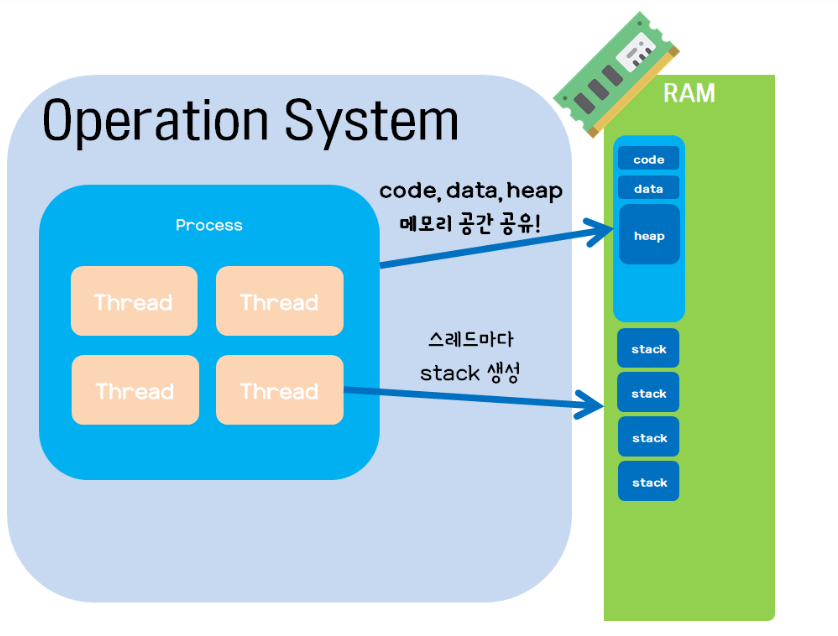
스레드는 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위를 말한다. 일반적으로 하나의 애플리케이션(프로그램)은 하나 이상의 프로세스를 가지고 있고, 하나의 프로세스는 반드시 하나 이상의 스레드를 갖는다. 즉, 프로세스를 생성하면 기본적으로 하나의 (메인)스레드가 생성되는 셈이다.
아래에서 더 자세히 알아보도록 하겠다.
프로그램 → 프로세스 → 스레드
1. 프로그램 → 프로세스
프로세스와 스레드에 대해 설명하기 전에 프로그램에 대해서 먼저 설명이 필요하다. 프로그램이라는 단어의 정의는 다음과 같다.
프로그램이란, 어떤 작업을 하기 위해 실행할 수 있는 파일 또는 프로그램으로 파일이 저장 장치에 저장되어 있지만 메모리에는 올라가 있지 않은 정적인 상태를 말한다.
- 메모리에 올라가 있지 않은: 아직 운영체제가 프로그램에게 독립적인 메모리 공간을 할당해주지 않았다는 뜻이다. 모든 프로그램은 운영체제가 실행되기 위한 메모리 공간을 할당해 줘야 실행될 수 있다.
- 정적인 상태: '정적'이라는 단어 그대로, 움직이지 않은 상태라는 뜻이다. 한마디로 아직 실행되지 않고 가만히 있다는 뜻이다.
결론부터 말하자면 프로그램이라는 단어는 아직 실행되지 않은 파일 그 자체를 가리키는 말이다. 윈도우의 .exe 파일이나 MacOS의 .dmg 파일 등등 사용자가 눌러서 실행하기 전의파일을 말한다. 쉽게 말해서 그냥 코드 덩어리다.

그러면 이제 실행 파일(프로그램)에게 의미를 부여하기 위해 프로그램을 실행해보자. 프로그램을 실행하는 순간 해당 파일은 컴퓨터 메모리에 올라가게 되고, 이 상태를 동적인 상태라고 하며 이 상태의 프로그램을 프로세스라고 한다. 따라서 프로세스에 대해 정의를 내릴 때 실행되고 있는 컴퓨터 프로그램이라고 정의를 내리며, 스케줄링 단계에서의 "작업"과 같은 단어라고 봐도 무방하다고 하고 있다. 실제로 프로세스라는 단어가 작업 중인 프로그램을 의미하는 단어이기 때문이다. 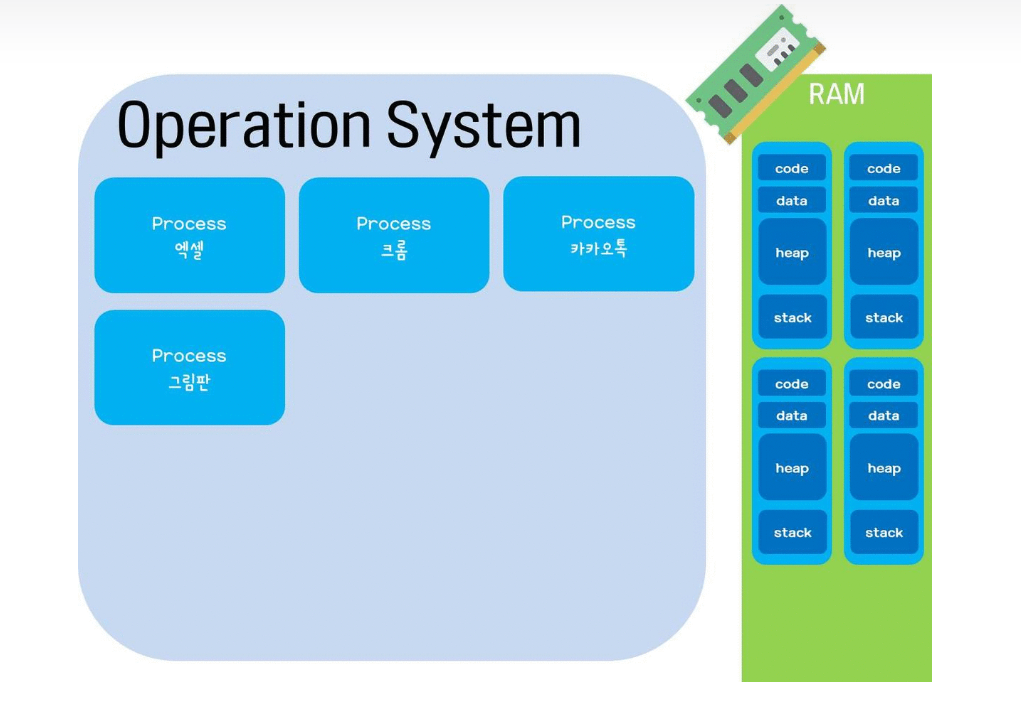
지금까지의 내용을 간단히 그림으로 표현하면 다음과 같다.

한 줄 요약: 프로그램은 코드 덩어리 파일, 메모리에 적재되고 CPU 자원을 할당받아 프로그램이 실행되고 있는 상태를 프로세스
2. 프로세스 → 스레드
과거에는 프로그램을 실행할 때 실행 시작부터 실행 끝까지 프로세스 하나만을 사용해서 진행했다고 한다. 하지만 시간이 흐를수록 프로그램이 복잡해지고 프로세스 하나만을 사용해서 프로그램을 실행하기는 벅차게 되었다. 실제로 이제는 프로그램 하나가 단순히 한 가지 작업만을 하는 경우는 없다. 그러면 어떻게 해야할까?
쉽게 떠오르는 방법은 "한 프로그램을 처리하기 위한 프로세스를 여러 개 만들면 되지 않을까?" 생각이 들지만 이는 불가능한 일이었다. 왜냐하면 운영체제는 안전성을 위해서 프로세스마다 자신에게 할당된 메모리 내의 정보에만 접근할 수 있도록 제약을 두고 있고, 이를 벗어나는 정보에 접근하려면 오류가 발생하기 때문이다.
그래서 프로세스와는다른 더 작은 실행 단위 개념이 필요하게 되었고, 이 개념이 바로 스레드다.
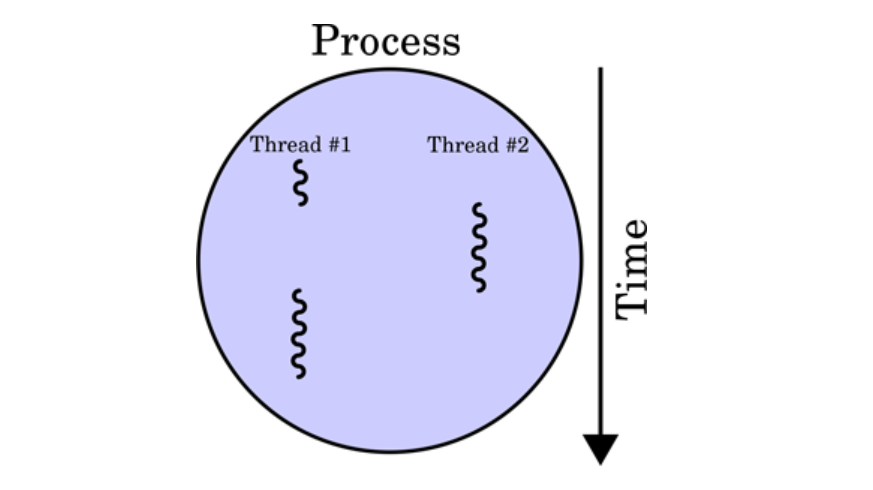
스레드는 위에서 언급한 프로세스 특성의 한계를 해결하기 위해 만들어진 개념이기 때문에 스레드의 특성은 쉽게 유추해낼 수 있을 것이다. 스레드는 프로세스와 다르게 스레드 간 메모리를 공유하며 작동한다. 스레드끼리 프로세스의 자원을 공유하면서 프로세스 실행 흐름의 일부가 되는 것이다. 아까 프로그램이 코드 덩어리라고 했는데, 스레드도 코드에 비유하자면 스레드는 코드 내에 선언된 함수들이 되고 따라서 main 함수 또한 일종의 스레드라고 볼 수 있게 되는 것이다.
한 줄 요약: 스레드는 프로세스의 코드에 정의된 절차에 따라 실행되는 특정한 수행 경로다.
프로세스와 스레드의 작동 방식에 대한 더 자세한 설명
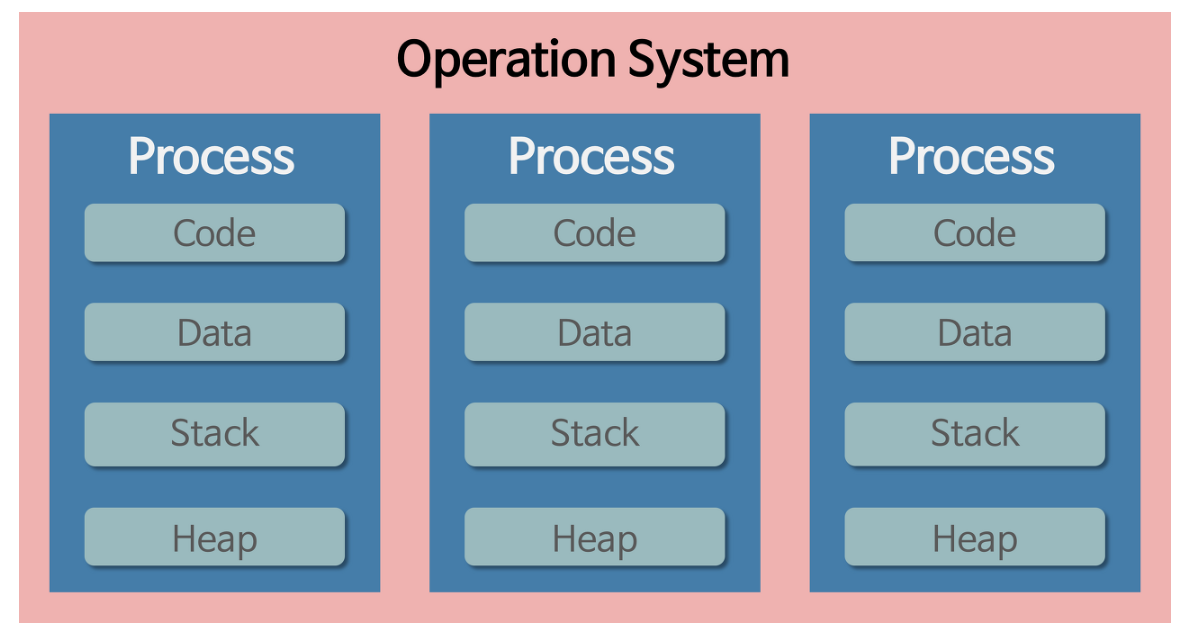
위에서 프로세스가 메모리에 올라갈 때 운영체제로부터 시스템 자원을 할당받는다고 언급했었다. 이 때 운영체제는 프로세스마다 각각 독립된 메모리 영역을, Code/Data/Stack/Heap의 형식으로 할당해 준다. 각각 독립된 메모리 영역을 할당해 주기 때문에 프로세스는 다른 프로세스의 변수나 자료에 접근할 수 없다.
이와 다르게 스레드는 메모리를 서로 공유할 수 있다고 언급했었다. 이에 대해 더 자세히 설명하자면, 프로세스가 할당받은 메모리 영역 내에서 Stack 형식으로 할당된 메모리 영역은 따로 할당받고, 나머지 Code/Data/Heap 형식으로 할당된 메모리 영역을 공유한다. 따라서 각각의 스레드는 별도의 스택을 가지고 있지만 힙 메모리는 서로 읽고 쓸 수 있게 된다.
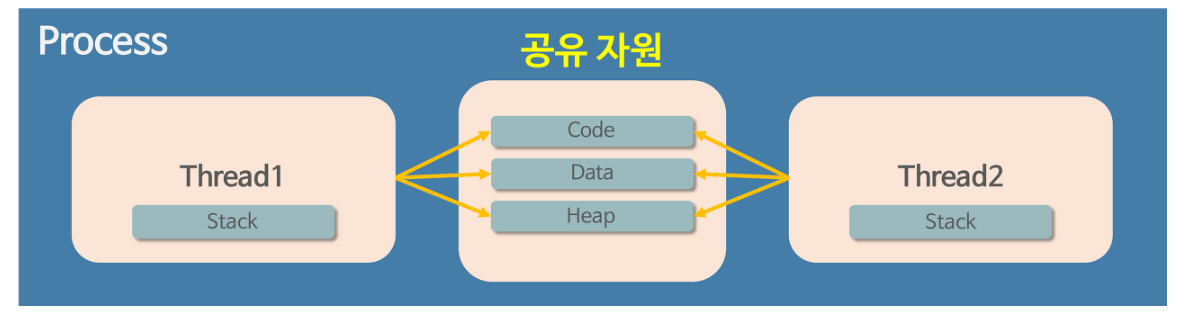
여기서 프로세스와 스레드의 중요한 차이를 하나 더 알 수 있게 된다. 만약 한 프로세스를 실행하다가 오류가 발생해서 프로세스가 강제로 종료된다면, 다른 프로세스에게 어떤 영향이 있을까? 공유하고 있는 파일을 손상시키는 경우가 아니라면 아무런 영향을 주지 않는다.
그런데 스레드의 경우는 다르다. 스레드는 Code/Data/Heap 메모리 영역의 내용을 공유하기 때문에 어떤 스레드 하나에서 오류가 발생한다면 같은 프로세스 내의 다른 스레드 모두가 강제로 종료된다.
본문에서 언급했듯 스레드를 코드(프로세스) 내에서의 함수(스레드)에 빗대어 표현해보면 이해하기 쉬워진다. 코딩을 해 본 경험이 있다면, 코드 내 어떤 함수 하나에서 Segmentation Fault 등의 오류가 발생한 경험이 있을 것이다. 이 오류가 어떤 함수에서 발생했든 간에 해당 코드는 다른 함수 모두에 대한 작업을 중단하고 프로세스 실행을 끝내버린다.
그렇다면 왜 이런 방식으로 메모리를 공유할까?
스레드는 본문 맨 위에서 "흐름의 단위"라고 말했는데, 정확히는 CPU 입장에서의 최소 작업 단위가 된다. CPU는 작업을 처리할 때 스레드를 최소 단위로 삼고 작업을 한다. 반면 운영체제는 이렇게 작은 단위까지 직접 작업하지 않기 때문에 운영체제 관점에서는 프로세스가 최소 작업 단위가 된다.
여기서 중요한 점은 하나의 프로세스는 하나 이상의 스레드를 가진다는 점이다. 따라서 운영체제 관점에서는 프로세스가 최소 작업 단위인데, 이 때문에 같은 프로세스 소속의 스레드끼리 메모리를 공유하지 않을 수 없다.
멀티태스킹, 멀티스레드는 무엇일까?
멀티태스킹이란, OS를 통해 CPU가 작업하는데 필요한 자원(시간)을 프로세스 또는 스레드간에 나누는 행위를 말한다. 즉, 하나의 운영체제 안에서 여러 프로세스가 실행되는 것을 의미한다. 멀티태스킹은 자칫하면 여러 프로세스가 동시에 실행되는 것처럼 보이지만 자세한 원리를 알아보면 그렇지 않다. 다음 그림과 같이 운영체제(OS)를 통해 여러 프로세스를 실행하고 관리할 수 있다.  이를 통해 여러 응용 프로그램을 동시에 열고 작업할 수 있다는 장점이 있다. 음악을 들으면서 웹서핑을 하고 메신저의 메시지를 확인할 수 있는 이유는 모두 멀티태스킹 덕분이다.
이를 통해 여러 응용 프로그램을 동시에 열고 작업할 수 있다는 장점이 있다. 음악을 들으면서 웹서핑을 하고 메신저의 메시지를 확인할 수 있는 이유는 모두 멀티태스킹 덕분이다.
멀티 스레드란 하나의 애플리케이션을 여러 개의 스레드로 구성하여 하나의 스레드가 하나의 작업을 처리하도록 하는 것이다. 일반적으로 멀티스레드를 사용하는 이유는 사용자와 상호작용하는 애플리케이션에서 단일 스레드로 Network 또는 DB와 같은 긴 작업(Long-running task)을 수행하는 경우 해당 작업을 처리하는 동안 사용자와 상호작용이 불능인 상태가 될 수 있기 때문이다. 다음 그림을 보면 두개의 스레드가 서로에게 방해주지 않고, 각자 할 일을 하는 것을 볼 수 있다. 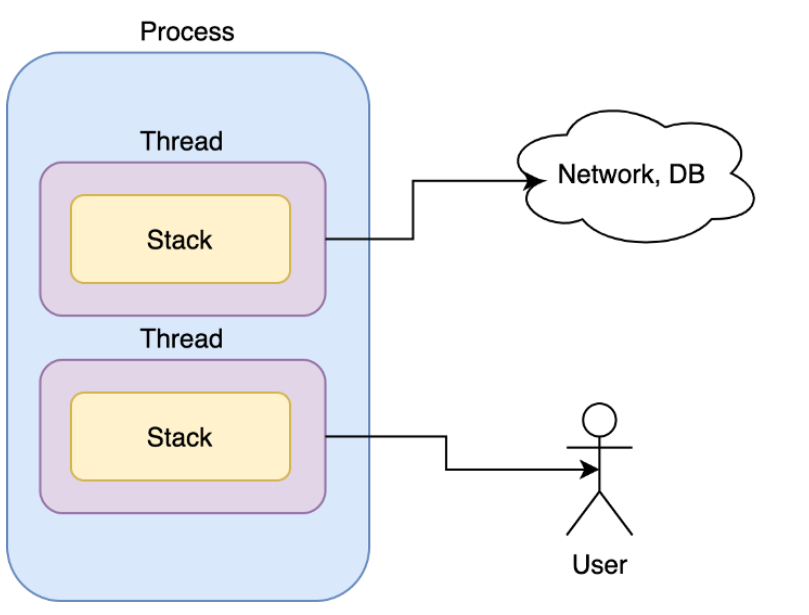
멀티태스킹이 하나의 운영체제 안에서 여러 프로세스가 실행되는 것이라면, 멀티스레드는하나의 프로세스가 여러 작업을 여러 스레드를 사용하여 동시에 처리하는 것을 의미한다.
멀티스레드의 장단점은 다음과 같다.
멀티스레드의 장점
1. Context-Switching할 때 공유하고 있는 메모리만큼의 메모리 자원을 아낄 수 있다.
2. 스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신의 부담이 적어서 응답 시간이 빠르다.
3. 프로세스를 할당하는 것보다 스레드를 할당하는 것이 비용이 적다.
4. 멀티 프로세서 구조에서 각각의 스레드가 다른 프로세스에서 병렬로 수행될 수 있다.
멀티 스레드의 단점
1. 스레드 하나가 프로세스 내 자원을 망쳐버린다면 모든 프로세스가 종료될 수 있다.
2. 자원을 공유하기 때문에 필연적으로 동기화 문제가 발생할 수밖에 없다.
3. 구현 및 테스트, 디버깅이 어렵다.
4. 너무 많은 스레드 사용은 오버헤드를 발생시킨다.
프로세스 간의 Context-Switching 시에는 많은 자원 손실이 발생한다. 그러나 스레드 간의 Context-Switching에서는 메모리를 공유하고 있는 만큼 부담을 덜 수 있다.
멀티스레드의 장단점에서 꼭 짚고 넘어가야 할 점이 바로 동기화 문제다. 주로 Synchronization Issue라고 하는데, 여러 개의 스레드가 동일한 데이터 공간(Critical Section)을 공유하면서 이들을 수정한다는 점에서 필연적으로 생기는 문제이다. 이에 대해 자세히 설명하면 다음과 같다.
멀티스레드를 사용하면 각각의 스레드 중 어떤 것이 어떤 순서로 실행될 지 그 순서를 알 수 없다. 만약 A 스레드가 어떤 자원을 사용하다가 B 스레드로 제어권이 넘어간 후 B 스레드가 해당 자원을 수정했을 때, 다시 제어권을 받은 A 스레드가 해당 자원에 접근하지 못하거나 바뀐 자원에 접근하게 되는 오류가 발생할 수 있다.
이처럼 여러 스레드가 함께 전역 변수를 사용할 경우 발생할 수 있는 충돌을 동기화 문제라고 한다. 멀티 프로세스의 프로그램은 문제가 생기면 해당 프로세스가 중단되거나 중단 시키고 다시 시작하면 된다. 하지만 멀티 스레드 방식의 프로그램에서는 하나의 스레드가 자신이 사용하던 데이터 공간을 망가뜨린다면, 해당 데이터 공간을 공유하는 모든 스레드를 망가뜨릴 수 있다. 또한, 스케줄링은 운영체제가 자동으로 해주지 않기 때문에 프로그래머가 적절한 기법을 직접 구현해야 하므로 프로그래밍할 때 멀티스레드를 사용하려면 신중해야 한다.

정말 다른 프로세스의 정보에는 접근할 수 없을까?
지금까지는 안 된다고 했지만 사실 프로세스가 다른 프로세스의 정보에 접근하는 것이 가능하다. 사실 지금 우리가 사용하는 대부분의 컴퓨터 프로그램을 생각해 보면 다른 프로그램에 있는 정보를 가져오는 경우를 심심치 않게 볼 수 있다.
프로세스 간 정보를 공유하는 방법에는 다음과 같은 방법들이 있다. 다만 이 경우에는 단순히 CPU 레지스터 교체뿐만이 아니라 RAM과 CPU 사이의 캐시 메모리까지 초기화되기 때문에 앞서 말했듯 자원 부담이 크다.
- IPC(Inter-Process Communication)을 사용한다.
- LPC(Local inter-Process Communication)을 사용한다.
- 별도로 공유 메모리를 만들어서 정보를 주고받도록 설정해주면 된다.
멀티 프로세스
멀티 프로세스란 하나의 애플리케이션을 여러 개의 프로세스로 구성하여 각 프로세스가 하나의 작업을 처리하도록 하는 것이다.
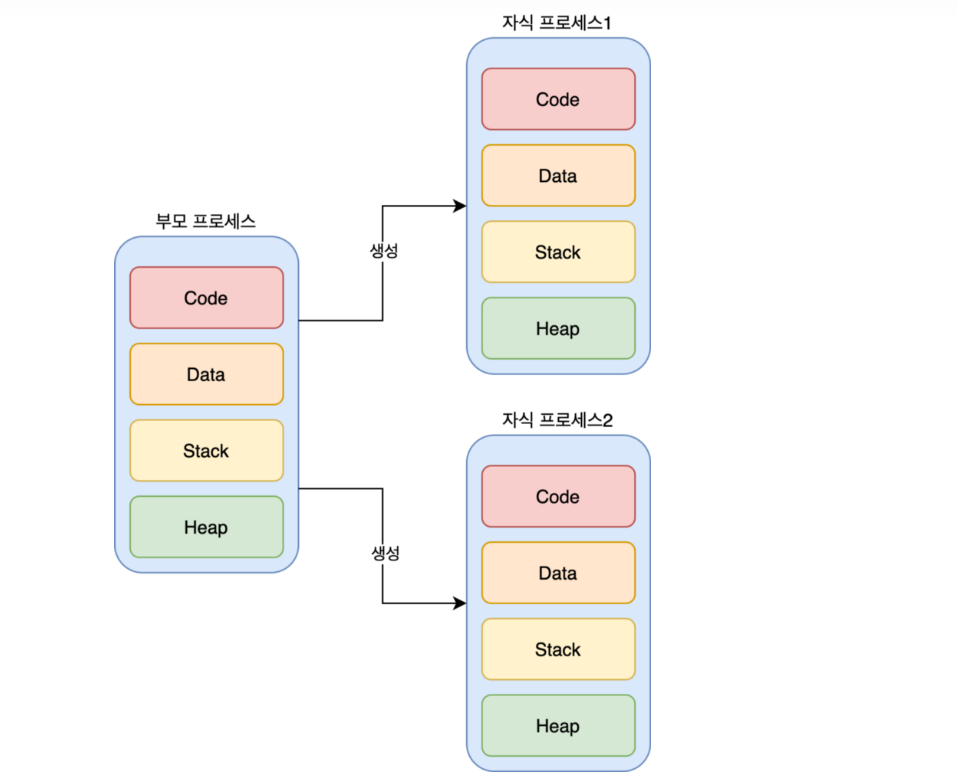
멀티 프로세스는 다음과 같은 특징이 있다.
- 안정성이 좋다. 여러개의 자식 프로세스 중 하나에 문제가 발생해도, 다른 자식 프로세스에 영향이 확산되지 않는다.
- 구현이 비교적 간단하고 각 프로세스들이 독립적으로 동작하며 자원이 서로 다르게 할당된다.
- 프로세스 간 통신을 하기 위해서는 IPC를 통해야 한다.
- 메모리 사용량이 많다.
- 스케줄링에 따른 Context Switch가 많아지고, 성능 저하의 우려가 있다.
멀티 프로세스와 멀티 스레드의 비교

결론
프로세스와 스레드는 개념의 범위부터 다르다. 스레드는 프로세스 안에 포함되어 있기 때문이다.
운영체제가 프로세스에게 Code/Data/Stack/Heap 메모리 영역을 할당해 주고 최소 작업 단위로 삼는 반면, 스레드는 프로세스 내에서 Stack 메모리 영역을 제외한 다른 메모리 영역을 같은 프로세스 내 다른 스레드와 공유한다.
프로세스는 다른 프로세스와 정보를 공유하려면 IPC를 사용하는 등의 번거로운 과정을 거쳐야 하지만, 스레드는 기본 구조 자체가 메모리를 공유하는 구조이기 때문에 다른 스레드와 정보 공유가 쉽다. 때문에 멀티태스킹보다 멀티스레드가 자원을 아낄 수 있게 된다. 다만 스레드의 스케줄링은 운영체제가 처리하지 않기 때문에 프로그래머가 직접 동기화 문제에 대응할 수 있어야 한다.
프로세스 주소 공간
앞서 프로세스는 CPU에 의해서 실행이 되고 memory에 저장이 된다고 했다. 그럼 이 부분에 대해서 자세히 알아보도록 하겠다.
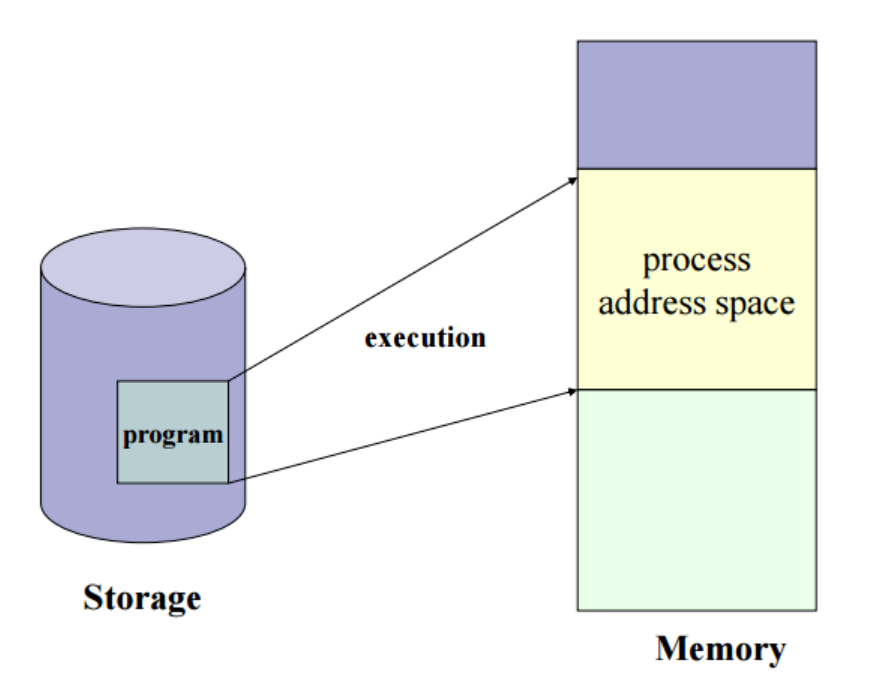
프로그램이 실행되면 프로세스 주소 공간이 그림과 같이 Memory에 할당된다. 프로세스 주소 공간에는 다음과 같은 영역들로 구분되어 있다.
 위의 그림을 좀 더 세분화 해서 나타내면 다음과 같다.
위의 그림을 좀 더 세분화 해서 나타내면 다음과 같다.
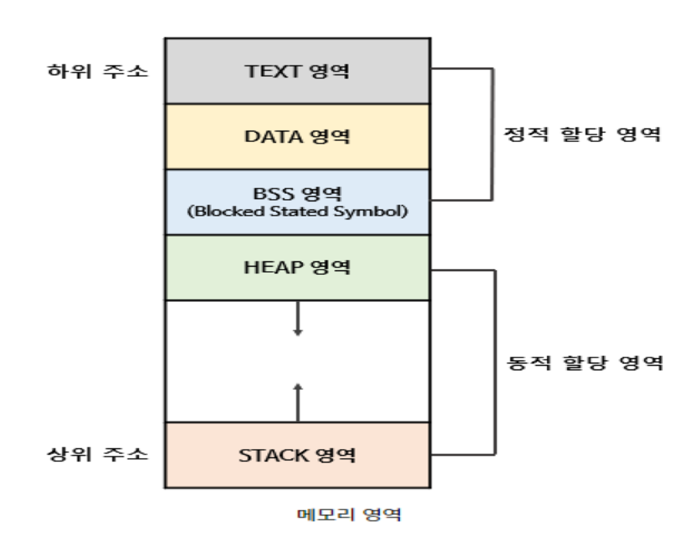
1) Code(Text) Segment
프로그래머가 작성한 프로그램 함수들의 코드가 CPU가 해석 가능한 기계어 형태로 저장되어 있는 부분이다. 프로그램의 코드는 변경되어서는 안되므로 읽기만 가능한 부분이다.
2) Data Segment
Data 영역은 .data .rodata .bss 영역으로 세분화 할 수 있는데, .data 부분은
전역 변수 또는 static 변수 등 프로그램이 사용하는 데이터를 저장하는 부분이다. 함수의 바깥에 있는 데이터(전역 변수)를 저장해 놓는다고 보면된다. Data 영역은 프로그램의 시작과 함께 할당되며, 프로그램이 종료되면 소멸한다. 변수는 변할 수 있으므로 읽고 쓰기가 가능하다.
2-1) .BSS
초기값 없는 전역 변수, static 변수가 저장되는 영역이다. bss 영역은 초기화 없이 해당 데이터의 사이즈만 기억하며, 해당 부분을 실행할 때 할당 받으면서 0으로 초기화 합니다.
2-2) .rodata
rodata 부분은 const같은 상수 키워드 선언 된 변수나 문자열 상수가 저장된다.
3) Stack Segment
함수나 함수 안에 있는 지역 변수와 매개변수를 저장해 놓는다고 보면된다. Stack은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸한다. 컴파일 타임에 크기가 결정되기 때문에 무한히 할당 할 수 없다. 재귀함수가 너무 깊게 호출되거나 함수가 지역 변수를 많이 가지고 있어 stack 영역을 초과하면 stack overflow 에러가 발생한다. 변수는 변할 수 있으므로 읽고 쓰기가 가능하다. 스택은 메모리의 높은 주소에서 낮은 주소의 방향으로 할당된다. 프로그램이 실행될 때 메모리를 어느만큼 사용할지 계산할 수 없기 때문에 stack 함수의 뒷부분에서부터 변수의 주소가 매겨진다. 그래서 FFFFFFFF근처의 메모리 값을 가지고 변수 선언 순서에 따라 높은 주소에서 낮은 주소로 내려간다.
4) Heap Segment
런타임에 크기가 결정되는 메모리 영역이다. 사용자에 의해 메모리 공간이 동적으로 할당되고 해제된다. heap 부분에는 주로 클래스와 같은 참조형의 데이터가 할당된다.
Process Address Space 내부는 아래 그림과 같이 이루어져 있다.
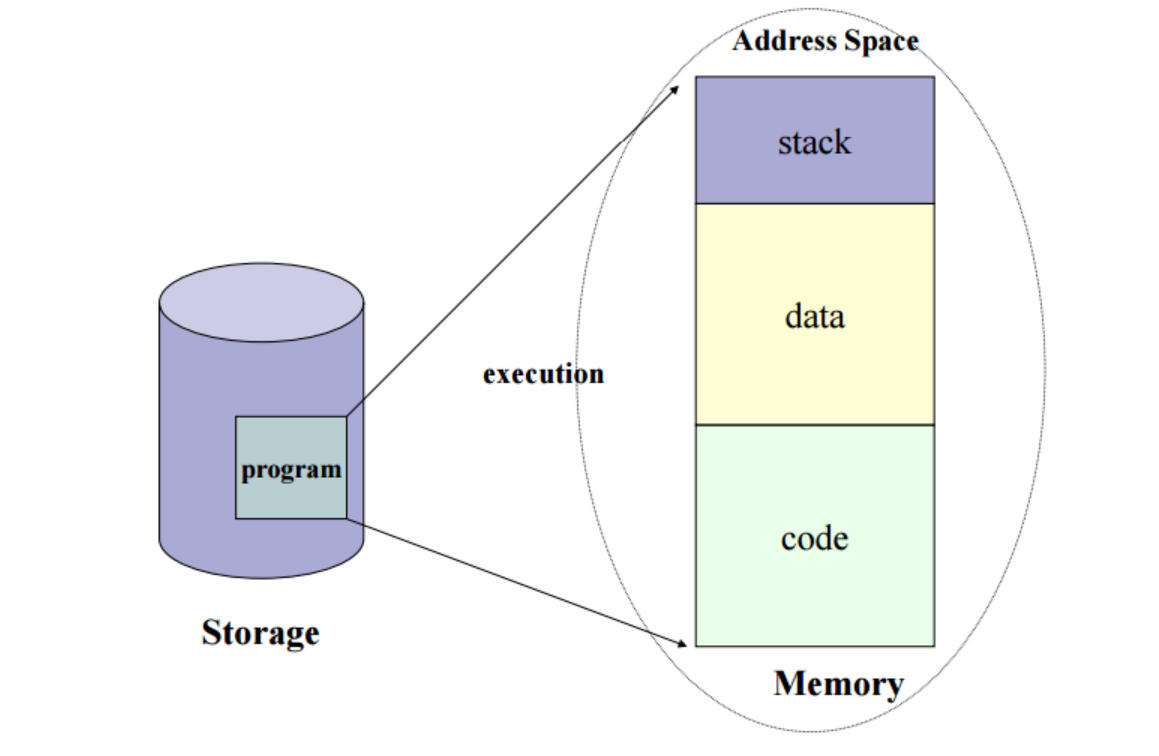
그림을 보면서 다시 간략히 정리하면 Program이 실행되면 Process가 생성이되고 Memory에 그 Process의 Address Space가 할당되게 된다. 그리고 그 Address Space안은 위 그림과 같이 Code, Data, Stack 부분으로 이루어져 있다.
Stack이 높은 주소에서 낮은 주소로 할당되는 또 다른 이유
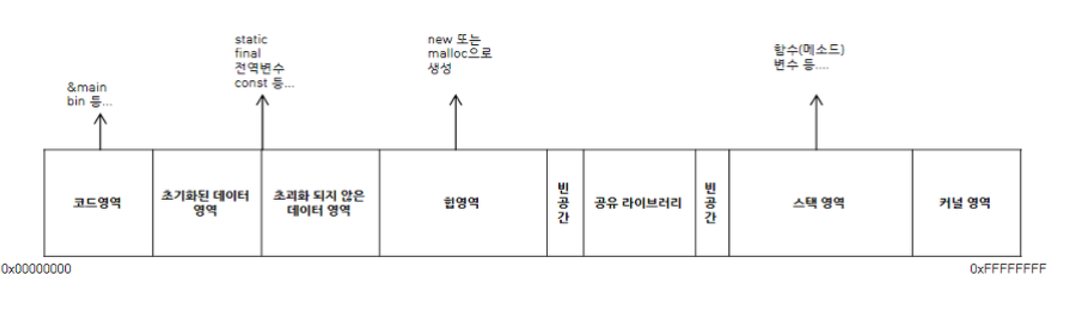 앞서 말한 이유 말고도 stack이 높은 주소에서 낮은 주소로 할당되는 이유가 있는데 위의 그림과 같아 stack 영역의 오른쪽을 보면 커널 영역이 있다. 이 커널 영역은 하나의 프로세스에 할당되는 총 메모리 공간 중 유저 영역을 제외한 나머지 공간이고, 운영체제 소프트웨어를 실행시키기 위해서 필요한 메모리 공간이다.
앞서 말한 이유 말고도 stack이 높은 주소에서 낮은 주소로 할당되는 이유가 있는데 위의 그림과 같아 stack 영역의 오른쪽을 보면 커널 영역이 있다. 이 커널 영역은 하나의 프로세스에 할당되는 총 메모리 공간 중 유저 영역을 제외한 나머지 공간이고, 운영체제 소프트웨어를 실행시키기 위해서 필요한 메모리 공간이다.
다시 말해서, 운영체제가 실행되기 위해서는 운영체제 또한 메모리에 올라가야되고 또, 일반 프로그램처럼 실행되는 과정에서 변수 선언도 하고 메모리를 동적으로 할당하기도 한다. 예전에는 변수에 stack 영역이 초과되는 크기의 데이터를 저장해서 커널 영역을 침범해 데이터를 조작하는 방식으로 해킹을 했다고 하는데, 이를 막기위해 높은 주소에서 낮은 주소로 할당받는다고 한다.
data 영역과 bss 영역을 구분하는 이유?
data 영역과 bss 영역을 구분하는 이유는 초기화 되지 않은 변수는 프로그램이 실행될 때 영역만 잡아주면 되고 그 값을 프로그램에 저장하고 있을 필요는 없는 반면, 초기화가 되는 변수는 그 값도 프로그램에 저장하고 있어야 하기 때문이다.
왜 Code 부분을 따로 두었나?
Program의 Code는 Program이 만들어지고(컴파일되고) 나서는 변경될 일이 전혀 없다. 따라서 읽기만 가능한 Read Only 부분이다. 그렇기 떄문에 같은 프로그램을 실행시켜 몇 개의 Process가 실행되더라도 같은 프로그램이라면 Code 부분은 동일한 내용을 가지고 있게 된다. 따라서 같은 Program의 Process일 경우 Code 부분을 공유하여 메모리 사용량을 줄이는 목적이다.
Stack vs Heap
stack과 heap의 차이점에 대해서 더 찾아봤다. 구글링 해보니 다음과 같은 답을 얻을 수 있었다.
- 정적 할당은 변수 선언을 통해 필요한 메모리를 확보하는 것이고, 동적 할당은 프로그램 실행 중 필요한 메모리를 확보하는 방법이다.
- 프로그램이 동작하면서 원하는 크기의 메모리를 사용해야 될 경우가 있다. 이러한 경우를 위해 일정한 크기를 선언해놓고 프로그램이 동작할 때 메모리를 할당해주는 영역을 힙이라고 한다.
- Heap은 프로그램에서 자유롭게 할당하고 해제할 수 있는 영역이다.
이와 같이 공통적으로 heap은 프로그램 실행 동안 사용하는 영역이라는 점이었다.
Java언어에서의 String 처럼 크기가 정해진 원시형 데이터는 필요한 공간만큼만 메모리를 사용하면 되고 그래서 컴파일 단계에서 얼마만큼의 메모리가 필요한지 예측이 된다. 즉, 원시형의 데이터는 stack 영역에 저장되니까 stack 영역은 컴파일 단계에서 정해진다.
반면, 크기가 정해져 있지 않은 참조형의 데이터는 필요한 메모리를 예측할 수 없다. 프로그램이 실행되는 동안 어떻게 사용하는지에 따라 필요한 메모리가 달라진다. 따라서 참조형의 데이터는 heap에 저장해놓고, 프로그램을 사용하는 동안 필요한 메모리 만큼 heap의 영역을 사용하게 된다. 그래서 heap이 동적으로 할당되고 해제되는 영역이라고 설명하는 이유였다.
왜 Stack 부분과 Data 부분을 나누었나?
Stack 구조는 아래의 사진과 같이 이루어져 있다. 하단 부가 막혀있고 상단 부가 뚫려있는 구조라고 생각하면 된다. 따라서 한 쪽으로만 데이터를 집어 넣을 수 있고 꺼낼 때는 최근에 집어 넣었던 것 부터 꺼낼 수밖에 없는 구조이다. C언어를 예로 들면 함수의 호출이 Stack 구조로 되어있다고 보면 된다.
잘 와닿지 않을 수도 있어 추가로 설명을 하자면 다음과 같은 C언어 코드가 있다고 가정하자.
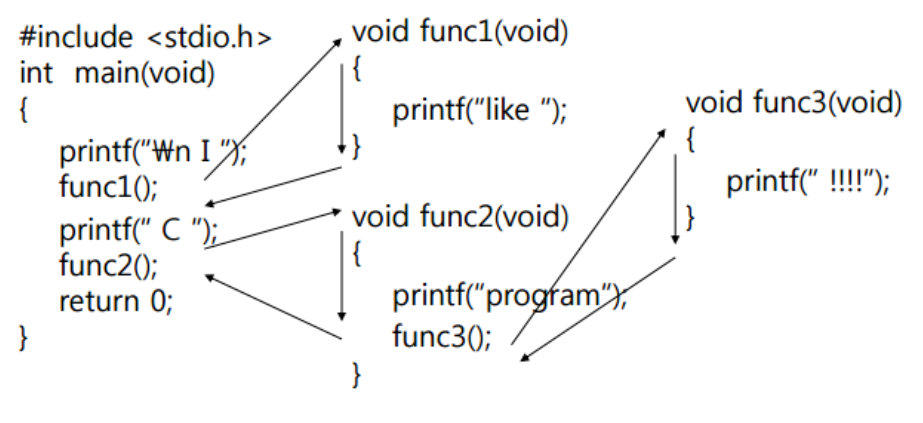
main 함수부터 실행이 되며 처음 printf를 수행한 뒤 함수 func1을 실행하게 된다. 함수 func1이 실행되고 나서 main에서 다시 printf를 실행하고 함수 func2를 실행한다. 그리고 func2에서는 printf를 수행하고 func3를 실행하게 된다. Stack 구조로 함수가 실행되고 있는게 글로 적어서 느낌이 안올 수도 있지만 그림으로 보면 다음과 같다.
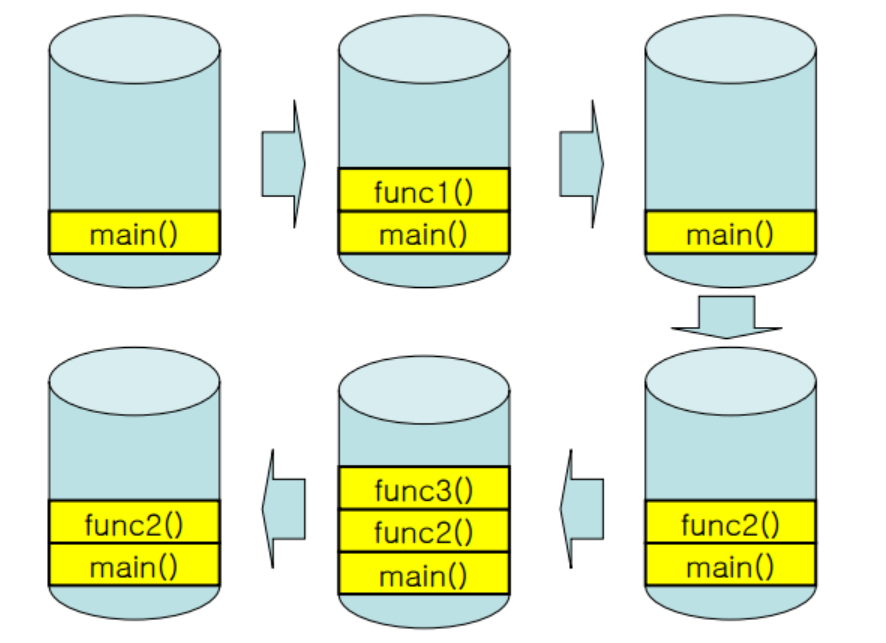
이러한 함수의 Stack 구조로 인해 Data 부분과 Stack 부분을 따로 나누어두게 된 것이다. 전역 변수는 어떤 함수에서도 접근 할 수 있기 때문에 Data로 따로 관리를 해주는 것이다. 따라서 함수 외부와 함수에 따라서 Stack구조 활용을 위해 나누어 두었다고 생각하면 된다.
Compile time vs Runtime
프로그램을 작성하면 Code 영역이 늘어난다. Code, Data, BSS는 Compile time에 크기가 결정되고 이후로 변동되지 않는다. (고정) Stack, Heap은 Runtime시에 메모리 사용이 결정된다. Heap은 아래로, Stack은 위로 주소값을 매긴다.
PCB
프로세스 제어 블록(Process Control Block)은 운영체제가 프로세스에 대한 중요한 정보를 저장해 놓는 곳으로, 운영체제 커널의 자료구조이다. 즉, 운영체제가 프로세스 스케줄링을 위해 프로세스에 관한 모든 정보(메타 데이터)를 가지고 있는 데이터베이스를 PCB라 한다.
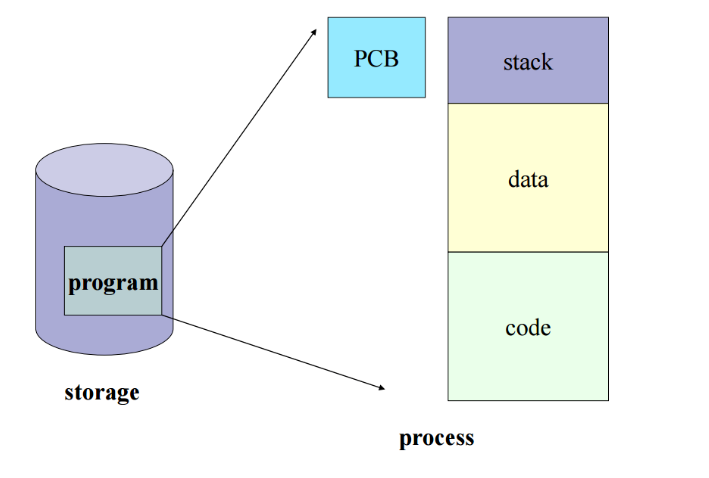
운영체제에서 프로세스는 PCB로 나타내어지며, PCB는 프로세스에 대한 중요한 정보를 가지고 있는 자료이다. 각 프로세스가 생성될 때마다 고유의 PCB가 생성되고, 프로세스가 완료되면 PCB는 제거된다.
프로그램 실행 → 프로세스 생성 → 프로세스 주소 공간에 (코드, 데이터, 스택) 생성 → 이 프로세스의 메타데이터가 PCB에 저장
PCB가 왜 필요한가?
CPU에서는 프로세스의 상태에 따라 교체작업이 이루어진다. 즉, 프로세스는 CPU를 점유하여 작업을 처리하다가도 상태가 전이되면, 진행하던 작업 내용들을 모두 정리하고 CPU를 반환해야 하는데, 이때 진행하던 작업들을 모두 저장하지 않으면 다음에 자신의 순서가 왔을 때 어떠한 작업을 해야하는지 알 수 없는 사태가 발생한다. 따라서,프로세스는 CPU가 처리하던 작업의 내용들을 자신의 PCB에 저장하고, 다음에 다시 CPU를 점유하여 작업을 수행해야 할 때 PCB로부터 해당 정보들을 CPU에 넘겨와서 계속해서 하던 작업을 진행할 수 있다.
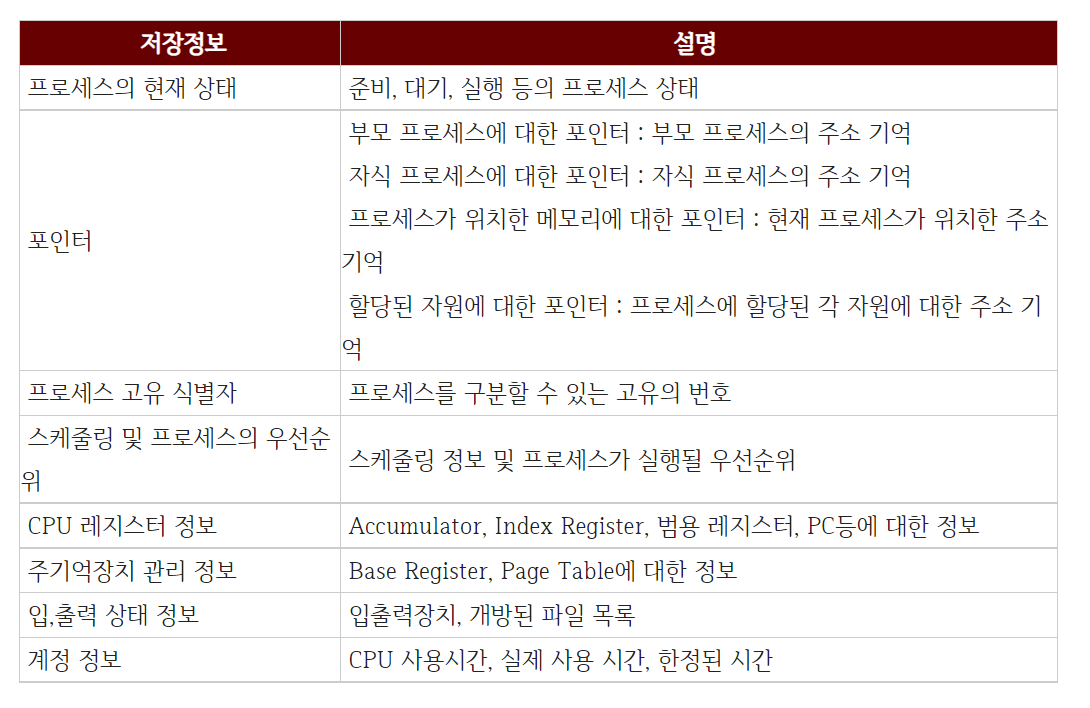
PCB에 저장되어 있는 정보
PCB는 어떻게 관리되나?
Linked List 방식으로 관리한다. PCB List Head에 PCB들이 생성될 때마다 붙게 된다.  주소값으로 연결이 이루어져 있는 연결리스트이기 때문에 삽입 삭제가 용이하다. 즉, 프로세스가 생성되면 해당 PCB가 생성되고 프로세스 완료시 제거된다.
주소값으로 연결이 이루어져 있는 연결리스트이기 때문에 삽입 삭제가 용이하다. 즉, 프로세스가 생성되면 해당 PCB가 생성되고 프로세스 완료시 제거된다.
Context Switching / 스케줄러의 종류
먼저 스케줄링이 무엇이고, 왜 이런 것이 필요한지 알아보도록 하자. 여러 가지 스케줄링 알고리즘을 달달달 외우는 것보다 스케줄링이 왜 필요한지 이유를 아는 것이 더 중요할 수도 있다.
스케줄(Schedule)이라는 단어에서 알 수 있듯이 운영체제에서 말하는 스케줄링은 운영체제가 CPU의 자원을 어떤 프로세스에게 할당해 줄 지 그 일정을 짜는 것이라고 이해하면 쉽다. 앞서 언급했던대로 프로세스 간의 Context Switching 과정은 많은 자원 손실을 발생시킨다. 따라서 이 일정을 어떻게 짰는지에 따라 CPU의 자원을 얼마나 효율적으로 사용하게 되는지가 결정된다. 한 마디로 스케줄링은 운영체제 입장에서 매우 중요한 과정이라고 할 수 있다.
Context Switching
본격적으로 스케줄링에 대해 설명하기 전에 Context Switching에 대해 알고 가야 할 필요가 있다. Switch라는 단어의 뜻을 안다면 Context라는 단어를 모른다고 하더라도 "일단 Context라는 것을 Switching (교체, 전환) 하는 것이겠구나" 하고 생각할 수 있을 것이다. 그럼 Context는 뭘까? 흔히들 '문맥'이라는 단어로 번역하는데 여기서는 이렇게 번역하는 것이 좋은 방법이 아니다. 운영체제에서 말하는 Context라는 건 문맥 같은 게 아니고 CPU가 프로세스를 실행하기 위한 (프로세스에 대한) 정보를 말한다. 더 자세히 말하면 Context는 현재 프로세스의 상태, 프로세스가 다음에 실행할 명령어, 레지스터 값, 프로세스 번호 등의 정보를 담고 있으며 이는 운영체제의 PCB (Process Control Block)에 저장된다.
멀티프로세스 환경에서는 여러 프로세스가 동시에 실행되는 것 처럼 보인다. 이 환경에서는 필연적으로 프로세스 간 CPU 자원 할당 이동이 일어날 수밖에 없다. 이 이동 과정을 Context Switching이라고 하며, CPU는 기존 할당된 프로세스의 Context를 저장하고, 새로 자원을 할당할 프로세스의 Context로 교체하는 과정을 거치면서 자원을 새로운 프로세스에게 할당하게 된다. 여기서 주의해야 할 점이 있다. Context Switching 중에는 CPU의 자원이 어떤 프로세스에게 할당된 상태가 아니기 때문에 CPU가 아무 일도 하지 못 한다. 따라서 Context Switching 과정이 너무 자주 발생하면 오히려 CPU 성능이 떨어지게 된다.
결국 운영체제라는 건 컴퓨터가 효율적으로 일을 하게 만들기 위한 시스템이다. 그런데 방금 위에서 Context Switching 과정이 너무 자주 발생하면 오히려 CPU 성능이 떨어지게 된다고 언급했었다. 이 말은 바로 Context Switching 과정을 쓸데없이 자주 반복하지 않도록 하고, 필요한 순간에 적절하게 하도록 하는 알고리즘이 필요하다는 뜻이다. 그리고 이 알고리즘을 사용하는 주체가 바로 운영체제 스케줄러다.
이해하기 쉽도록 설명하기 위해 어쩌면 잘못 설명했을 수도 있는 부분에 대해 보강하도록 하겠다. Context Switching 중에는 CPU의 자원이 어떤 프로세스에게 할당된 상태가 아니라고 했는데, 사실 할당이라는 단어를 사용했지만 정확히는 프로세스가 점유 중이지만 사용 중은 아닌 상태다. 특정 프로세스에 의해 CPU 자원이 점유되고는 있는데, Context Switching 중이기 때문에 실제로 사용되는 프로세스가 없는 상태인 것이다. CPU가 아무 일도 하지 못한다는 것은 결국 CPU 자원을 아무 프로세스도 사용하지 못한다는 말이고 이는 오버헤드가 발생되었다는 뜻이다.
스케줄링 알고리즘의 종류
Context Switching을 할 때 새로 자원을 할당할 프로세스는 누가 결정할까? 자원을 달라는 프로세스는 엄청 많을텐데, 어떤 프로세스에게 자원을 얼만큼 주어야 효율적으로 일할 수 있을까? 앞서 말했듯 이를 결정하는 정책을 만드는 것을 스케줄링이라고 한다. 프로세스 간 우선순위를 두고, Context Switching을 할 때 우선순위가 가장 높은 프로세스에게 CPU 자원을 할당해 주는 것이다. 이 우선순위를 결정하는 방법은 크게 두 가지로 분류할 수 있는데, 지금부터 그것들에 대해 알아보도록 하겠다.
비선점 스케줄링
비선점 스케줄링의 특징은 아래와 같다.
어떤 프로세스가 CPU를 점유하고 있다면 해당 프로세스의 작업이 완료될 때까지 다른 프로세스는 CPU를 사용할 수 없음
프로세스가 CPU를 놓아주는 시점까지 스케줄링이 일어나지 않는다. 프로세스 일괄처리에 적합하고 Context Switching을 최소화 할 수 있다는 장점이 있다. 다만 긴급히 처리되어야 할 프로세스가 처리되지 못할 수 있다는 문제점이 발생할 수 있다.
FCFS (First Come First Service)
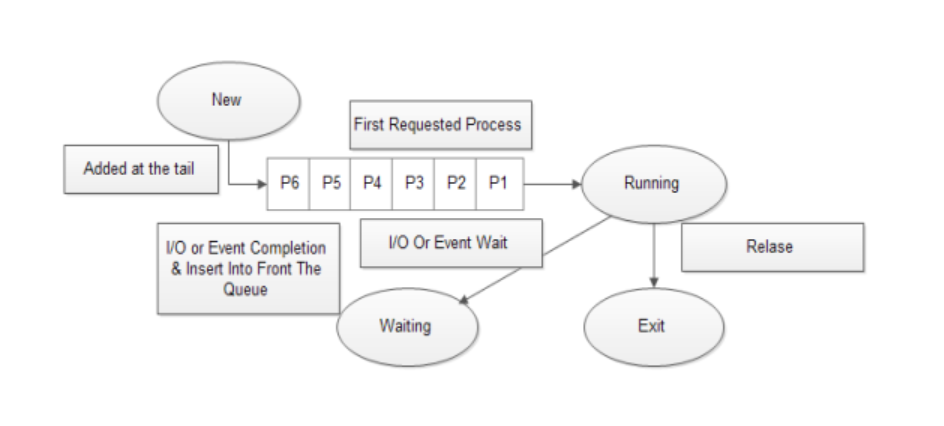
프로세스가 Ready Queue에 도착한 순서대로 CPU에 할당하는 방식이다. 작업 완료 시간을 예측하기 용이하다는 장점이 있다. 그러나 CPU 처리 시간이 길지만 덜 중요한 작업이, CPU 처리 시간이 짧고 더 중요한 작업을 기다리게 할 수도 있다. 이 상태를 호위 상태 (콘보이 이펙트; Convoy Effect)라고 한다.
SJF (Shortest Job First)
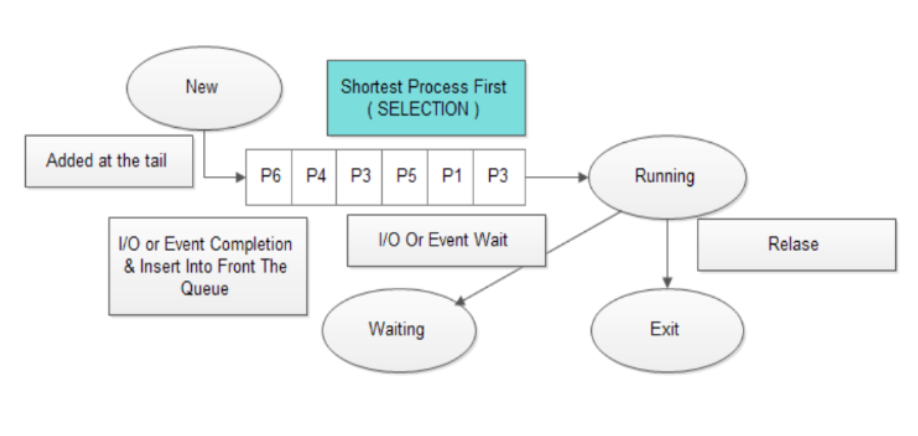
프로세스를 CPU 처리 시간이 짧은 순서대로 CPU에 할당하는 방식이다. 모든 방식을 통틀어 평균 대기 시간을 가장 짧게 만드는 방식으로 알려져 있다. 그러나 CPU 처리 시간이 긴 프로세스는 전체 시스템 성능 향상을 위해 희생하며 계속 Ready Queue의 뒤로 밀려나기 때문에 무한정 기다려야 하는 상황이 발생할 수 있다. 이 상태를 기아 상태 (스타베이션; Starvation)이라고 한다.
HRN (Highest Response Ratio Next)
SJF 스케줄링 방식에서 발생할 수 있는 기아 상태를 해결하기 위해 고안된 방식이다. 우선순위를 단순히 CPU 처리 시간으로 결정하지 않고, Ready Queue에서 대기한 시간까지 고려하여 결정한다. 대부분 우선순위를 ((대기 시간 + CPU 처리 시간) / CPU 처리 시간)으로 결정한다. 이처럼 기다린 시간에 비례하여 우선순위를 높이는 기법을 에이징(Aging) 기법이라고 한다.
HRN 스케줄링 방식이 선점일 경우엔 우선순위가 높은 다른 프로세스들이 너무 자주 생기기 때문에 Context Switching이 자주 발생한다. 이에 따라 스케줄러의 일이 너무 늘어나기 때문에 HRN 스케줄링 방식은 비선점 방식으로 이루어진다.
지금까지의 설명만 읽어봤다면 FCFS 스케줄링 방식을 사용할 하등의 이유가 존재하지 않는 것처럼 보인다. HRN 스케줄링 방식이 다른 비선점 스케줄링 방식에 비해 이상적으로는 훨씬 우월해 보이기 때문이다. 그러나 SJF, HRN 등의 방식을 사용하기 어려운 이유가 있는데, 현실적인 상황에서는 프로세스마다 CPU 처리 시간이 얼마나 걸릴지 알 수 있는 방법이 없기 때문이다. 이는 아래에서 설명할 SRT 스케줄링 방식에서도 동일하게 적용되는 부분이다.
우선순위 (Priority)
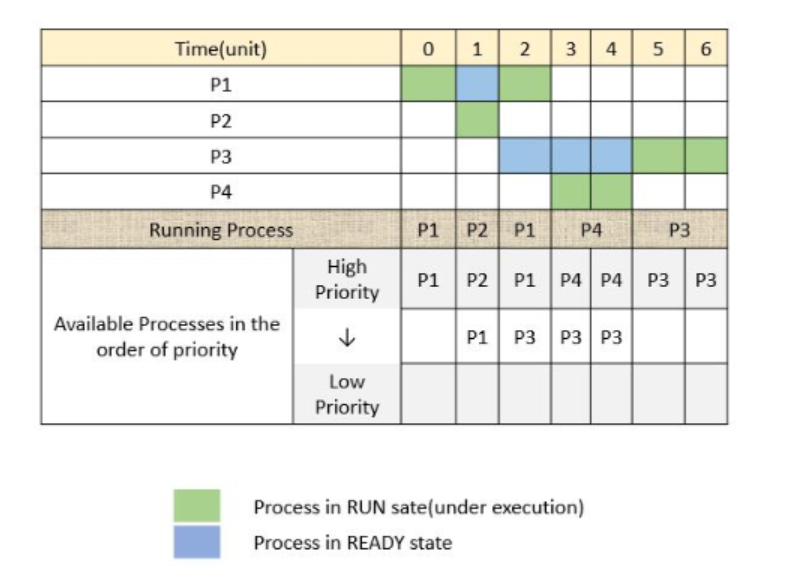
대기 중인 프로세스들에게 우선순위를 부여하여 우선순위가 높은 순서대로 처리한다. 선점형으로도 구현할 수 있으며 여기서도 에이징 기법이 사용된다. 왜나하면 우선순위가 낮은 프로세스에게 기아 상태가 생길 수 있기 때문이다. 우선순위는 정적 혹은 동적으로 부여될 수 있다. 동적으로 부여할 경우 구현이 복잡하고 오버헤드가 많다는 단점이 있으나, 시스템의 응답속도를 증가시킨다. 정적의 경우는 이 반대다.
선점 스케줄링
선점 스케줄링의 특징은 아래와 같다.
어떤 프로세스가 CPU를 점유하고 있을 때 우선순위가 높은 다른 프로세스가 점유를 빼앗아 CPU를 점유할 수 있음.
프로세스의 I/O 요청, I/O 응답, Interrupt 발생, 작업 완료 등의 특별한 상황에서 스케줄링이 발생한다. 긴급히 처리되어야 할 프로세스를 처리할 수 있다는 장점이 있지만 비선점 스케줄링 방식에 비해 Context Switching이 자주 일어날 수 있다는 단점이 있다.
SRT (Shortest Remaining Time)
SJF 스케줄링 방식을 선점 스케줄링 방식으로 변경한 기법이다. SJF 스케줄링 방식과 마찬가지로 프로세스를 CPU 처리 시간이 짧은 순서대로 CPU에 할당하는 방식이다. 위에서 설명했던 SJF 방식과 동일해 보이지만, 선점 스케줄링 방식이기 때문에 CPU를 점유 중인 프로세스보다 남은 CPU 처리 시간이 짧은 프로세스가 Ready Queue에 들어올 경우 새로 들어온 프로세스가 기존 프로세스의 CPU 점유를 빼앗아 점유할 수 있다.
우선순위 (Priority)
SJF와 SRT의 관계와 마찬가지로 비선점 우선순위 스케줄링 방식의 선점 방식인 선점 우선순위 스케줄링 방식이 있다.
라운드로빈 (Round-Robin)
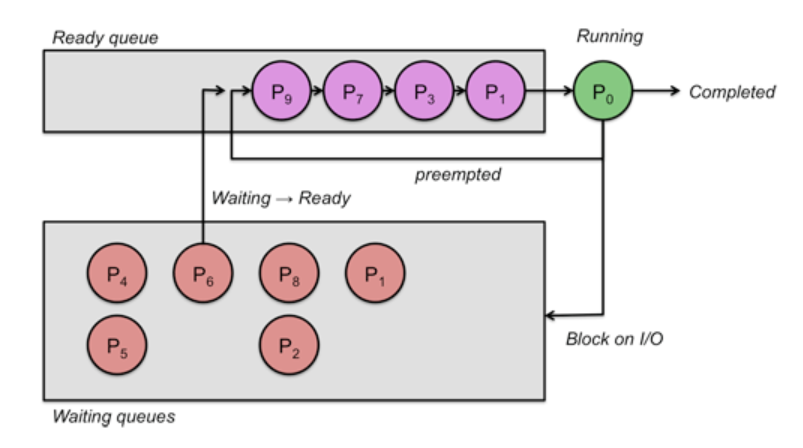
FCFS 스케줄링 방식에 선점 스케줄링 방식과 Time Quantum 개념을 추가한 방식이다. 각 프로세스마다 CPU를 연속적으로 사용할 수 있는 시간에 제한을 두고, 이 시간을 Time Quantum이라고 한다. 어떤 프로세스가 CPU를 사용한 시간이 Time Quantum만큼 지나면 이 프로세스로부터 CPU 자원을 회수하고, 이 프로세스를 Ready Queue의 가장 뒤로 보내는 것이다.
라운드로빈 스케줄링 방식에선 Time Quantum을 얼마로 둘 지 잘 결정해야 한다. 만약 Time Quantum이 너무 크다면, CPU 처리 시간이 긴 프로세스가 CPU를 오래 점유하며 정작 다른 프로세스들은 이 프로세스의 작업이 끝날 때까지 기다려야 하기 때문에 결국 FCFS 스케줄링 방식에서 발생하던 호위 상태가 또 발생하기 때문이다. 그렇다고 Time Quantum을 너무 작게 두면, Context Switching이 너무 자주 발생하기 때문에 오버헤드가 커진다.
다단계 큐 (Multi-Level Queue)
프로세스를 어떤 프로세스냐에 따라서 여러 종류의 그룹으로 나누고, 그룹마다 Queue를 두는 방식이다. 한 마디로 Ready Queue를 여러 개로 나누어 사용하는 방식이다. 각각의 Queue마다 서로 다른 스케줄링 방식을 적용할 수도 있다. 이 방식에 대해서 이해하려면 먼저 Foregroud Queue와 Backgroud Queue에 대해서 알고 가야 한다.
운영체제는 프로세스를 분류할 때 사용자와 직접 상호작용하는 프로세스와 백그라운드에서 돌아가는 프로세스의 중요도를 다르게 분류한다. 사용자와 직접 상호작용하는 프로세스는 빠르게 처리되어야 하고, 백그라운드에서 일괄 처리되는 프로세스의 경우 덜 빠르게 처리되어도 괜찮다고 분류하는 것이다. 사람들은 대부분 지금 내가 보고 있는 프로세스와의 상호작용이 빠르게 처리되기를 바라지 일단 켜두고 오래 방치한 프로세스와 상호작용 하느라고 내가 보고 있는 프로세스에 렉이 걸리는 상황을 바라지는 않는다.
따라서 사용자와 직접 상호작용하는 프로세스가 모인 Foreground Queue에는 응답 시간을 줄이기 위해 라운드로빈 스케줄링 방식을 적용하고, 백그라운드에서 돌아가는 프로세스가 모인 Background Queue에는 응답 시간이 큰 의미가 없기 때문에 FCFS 스케줄링 방식을 적용하는 등 각 Queue마다 운영체제가 가장 적절하다고 판단하는 방식을 사용하게 된다.
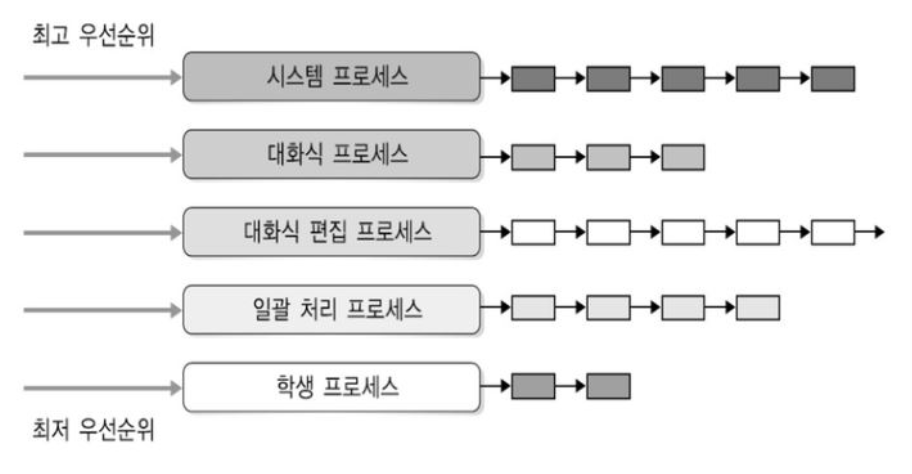
위 사진을 예로 들어 이해해보자. 위 사진에서 대화형 프로세스를 담기 위한 Foreground Queue에는 라운드로빈 스케줄링 방식을 적용하고, 프로세스 일괄처리가 필요한 Background Queue에는 일괄처리에 적합하다고 했던 비선점 방식 중 하나를 적용하면 될 것이다.
다만 다단계 큐 스케줄링 방식은 여러 개의 Queue를 사용하기 때문에 고려해야 할 점이 하나 더 생긴다. 바로 어떤 Queue에 얼마나 CPU를 오래 할당할 지 결정하는 스케줄링이 필요하게 된다. 이 스케줄링은 크게 두 가지 정도를 떠올릴 수 있다.
고정 우선순위 (Fixed Priority)
Queue마다 우선순위를 두는 방식이다. 우선순위가 높은 Queue에 처리해야 할 프로세스가 남아 있다면, 무조건 그 Queue에 남아 있는 프로세스를 처리한 뒤에 다음 우선순위의 Queue를 서비스한다. 이 방식은 사용자가 직접 원하는 프로세스에 CPU 자원을 우선 할당하기 때문에 좋아 보이지만 SJF 스케줄링 방식처럼 결국 우선순위가 낮은 Queue에 있는 프로세스는 무한정 기다려야 하는 상황이 발생할 수 있다. 모두들 기억하겠지만 이런 상태를 기아 상태라고 한다.
타임 슬라이스 (Time Slice)
고정 우선순위 스케줄링 방식에서 기아 상태가 발생할 수 있기 때문에 이를 해결하고자 생긴 스케줄링 방식이다. 운영체제가 Time Slice를 두고, 이 시간 비율에 따라서 각각의 Queue를 서비스하게 된다. 예를 들어 CPU 자원의 75%는 Foregroud Queue, 25%는 Background Queue를 서비스하는 데 할당할 수 있다.
다단계 피드백 큐 (Multi-Level Feedback Queue)
다단계 피드백 큐 스케줄링 방식은 다단계 큐 스케줄링 방식에 에이징 기법을 적용한 방식이다. 다단계 피드백 큐 스케줄링 방식에서는 다단계 큐 스케줄링 방식과 다르게 프로세스가 다른 큐로 이동할 수 있다. 우선순위가 낮은 큐에서 너무 오래 기다린 프로세스의 우선순위를 점점 올려서 우선순위가 높은 큐로 옮겨주는 방식이다. 이를 통해 다단계 큐 고정 우선순위 스케줄링 방식에서 발생할 수 있었던 기아 상태를 어느 정도 해결할 수 있게 된다.
References
https://blog.naver.com/whdgml1996/221589462999
https://velog.io/@raejoonee/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98-%EC%B0%A8%EC%9D%B4
https://whereisusb.tistory.com/10
https://inpa.tistory.com/entry/%F0%9F%91%A9%E2%80%8D%F0%9F%92%BB-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4-%E2%9A%94%EF%B8%8F-%EC%93%B0%EB%A0%88%EB%93%9C-%EC%B0%A8%EC%9D%B4?category=890836#top
