지도학습
라벨링된 기존 데이터를 학습시켜서 새로운 데이터가 왔을 때 결과 추론
회귀분석(Regression)

(네이버 지식백과 참고)
회귀분석에 대해 공부하기 전에 함수의 기본 개념부터 다시 보고 넘어갔다.
함수
입력과 출력이 있으며 하나의 입력에는 하나의 결과가 매칭되어야한다.
y=x에 관한식. x승 중에서 가장 높은게 n이면 n차함수
x하나에 y하나가 대응되어야한다.
Linear Regression 회귀분석
지도학습을 통해서 기존 데이터들을 바탕으로 그래프(직선 그래프)를 하나 도출하여 이 그래프를 바탕으로 새 데이터에 대한 결과값을 예측한다.
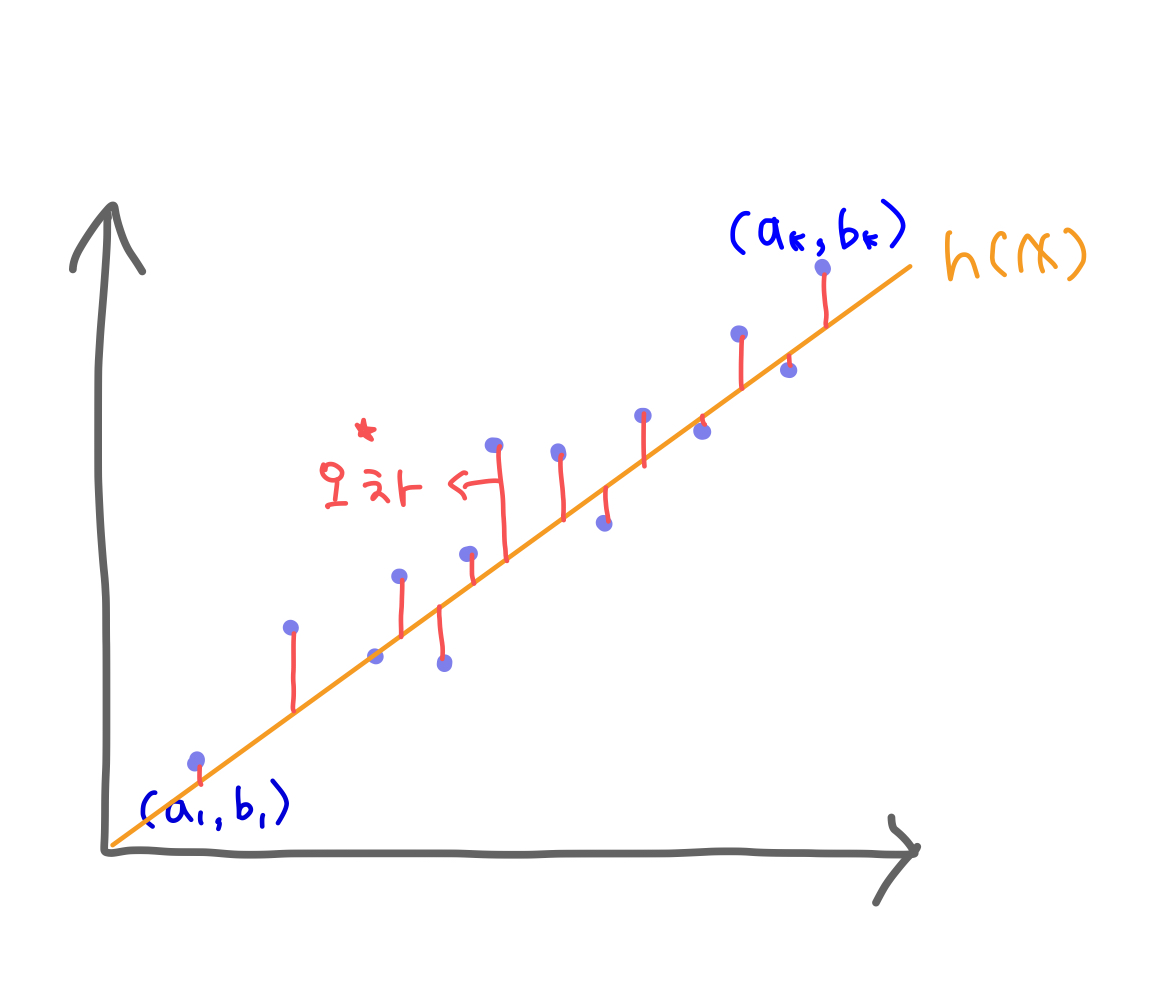
파란색 점들 (()부터 ()까지)은 실제 데이터,
주황색 선은 가설 h(x) = wx + b
파란색점부터 가설까지의 거리는 오차이다.
우리는 기존의 데이터를 가지고 새로운 데이터가 왔을 때의 결과를 예측할 것인데
가설 그래프중에서 오차의 합이 최소가 되는 그래프를 구하는 것이 목표이다.
Cost함수
내가 세운 가설의 cost값이 몇인지를 알려주는 함수
⭐️여기서 중요한 것은 가설에 대한 함수라는 것이다!!!!
따라서 식은
C(h(x)) =
이 된다.
cost함수가 가설에 대한 함수이므로 w(가설의 기울기, 가중치)와 b(가설의 y절편,오차보정)에 대한 함수로 표현할 수 있다.
C(w,b) =
C(w,b) =
여기서 계산하기 쉽게 h(x) = wx + b에서 b=0이라고 가정하자.
h(x) = wx
C(w) =
C(w) =
=
-> cost함수는 w에 대한 2차식
의 계수는 0이상이므로 아래로 볼록한 그래프를 그릴 수 있다.
(2차항의 계수 > 0 : 아래로 볼록, 2차항의 계수 <0 : 위로 볼록)
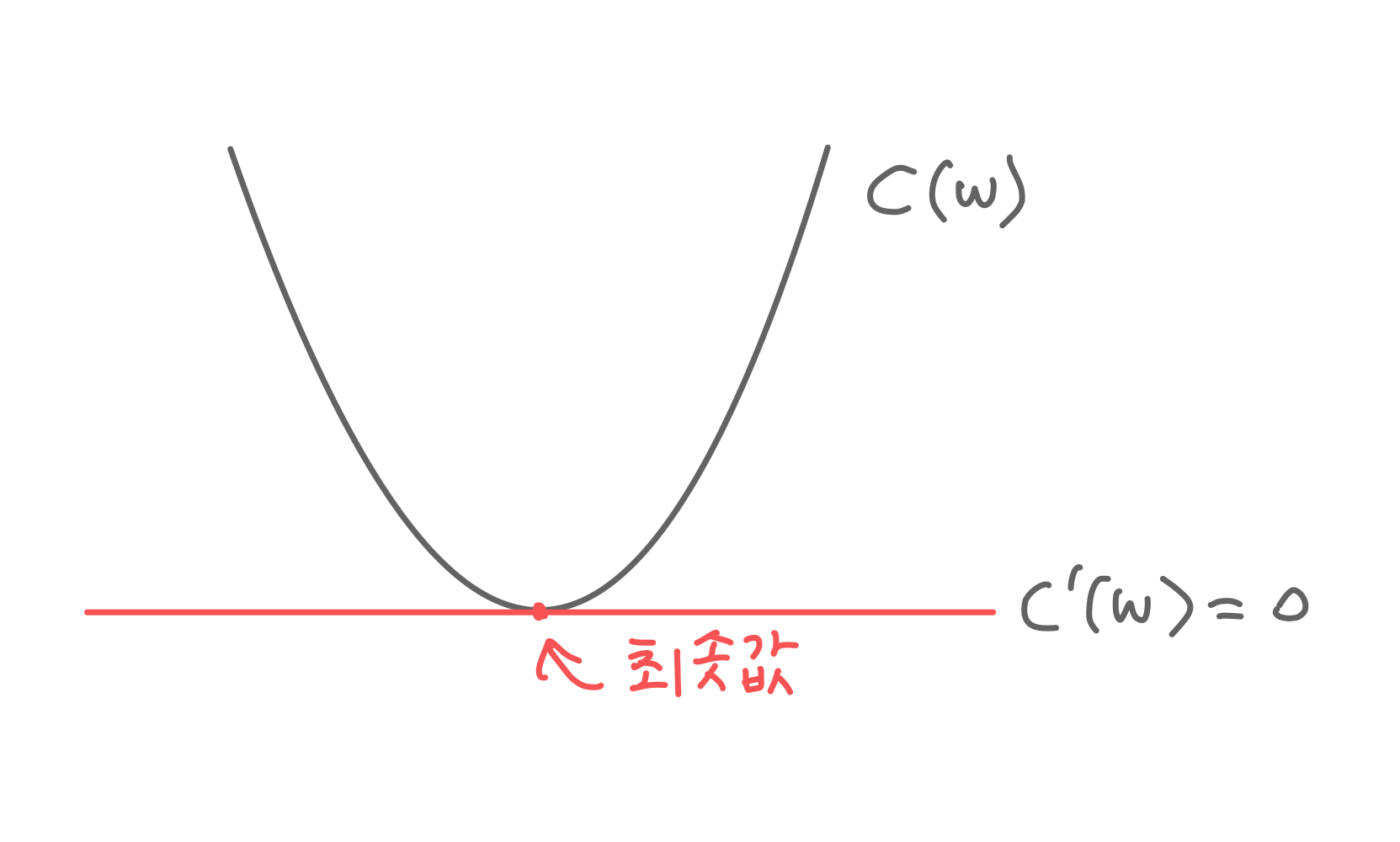
따라서 c`(w) = 0인 w의 값을 구하면 된다!
경사하강법
** Single Linear Regression
h(w) = wx + b
** Multi Linear Regression
🤓 실제로 AI알고리즘을 적용할 때는 w값을 식으로 한번에 구할 수가 없기 때문에 경사하강법을 사용하여 조금씩 조금씩 길을 더듬어가며 최저점을 찾으려고 노력해야함
❗️최저점이 1개인 그래프에서만 사용할 수 있다. → 그래프를 펴주어야함
전략
c(w)의 최솟값을 찾아감에 있어서
c`(a) > 0 인 경우, a = a - kc`(a)를 한 후 for문을 반복한다.
c`(a) < 0 인 경우, a = a - kc`(a)를 한 후 for문을 반복한다.
c`(a) - 0인 경우, 최솟값을 찾은 것이므로 for문을 탈출한다.
c(a)는 c함수의 최솟값
코드로 표현하자면,
Single Linear Regression의 cost함수 C(w)의 최솟값을 구함에 있어서
(단, h(x) = wx로 b는 무시한다.)
a = 랜덤값
for문 충분히 반복(단, 유한반복 ex 40000)
if c`(a) != 0:
a -= kc`(a) # 단 k는 본인이 정한 임의의 상수
else :
for문 탈출
w = a 일때 c(w)는 최솟값 c(a)를 가짐k -> lr(learning rate)
min_w = min_w -lrc`(min_w)
인공지능이 제대로 학습하기 위해서는 '적당한' lr을 정하는 것이 필수다.
너무 큰 lr를 지정하면 최솟값을 영원히 못찾게 된다. cost가 오히려 올라가는 것을 볼 수 있다.
너무 작은 lr를 지정하면 최솟값까지 도달하는데 너무 오랜 시간이 걸린다.
적당한 lr를 지정하면 cost가 계속 낮아지는 쪽으로 min_w의 값이 조정되는 것을 볼 수 잇으며 머지않아 최솟값에 도달하게 된다.
실습 코드
#인공지능 학습시킬 때 사용
import torch
#3차원이상을 tensor라고 부름. GPU가 텐서 연산에 최적화되어 있음. 1차원은 벡터, 2차원은 행렬, 3차원은 텐서
#FloatTensor는 임의의 실수로 채워놔
x_train = torch.FloatTensor([[30],[60],[90]])
#학습데이터 변수가 2개일 때,
#x_train = torch.FloatTensor([[30, 40],[60, 20],[90,30]])
y_train = torch.FloatTensor([[700],[750],[800]])
#괄호안 숫자는 차원을 의미. 1차원짜리 텐서(공간)에 넣는다.
#왜냐? 행렬연산을 사용하면 복잡하고 여러개의 식으로 표현해야만 하는 연산을 한번에 처리할 수 있다.
W = torch.zeros(1)# 학습데이터 변수가 2개 일땐 괄호안에 2
b = torch.zeros(1)
lr = 0.0002
epochs = 400000 #반복횟수
len_x = len(x_train) #학습데이터의 변수의 개수가 아니라 학습데이터의 갯수! 3
for epoch in range(epochs):
hypothesis = x_train * W + b
cost = torch.mean((hypothesis -y_train)**2)
gradient_w = torch.sum((W*x_train - y_train +b)*x_train)/ len_x
#핑크색은 cost함수를 w에 대해 편미분(w이외의 미지수는 모두 상수로보고 미분)
gradient_b = torch.sum((W*x_train - y_train +b))/len_x
#갈색음 b에 대해 편미분
W -= lr * gradient_w
b -= lr * gradient_b
if epoch % 10000 == 0:
print('Epoch {:4d}/{} W:{:.6f} b:{:.6f} Cost: {:.6f}'.format(epoch,epochs,W.item() ,b.item() , cost.item()))