1. 캐시 메모리의 정의 및 역할
(1) 정의 및 목적
캐시 메모리는 속도가 빠른 장치(CPU)와 느린 장치(주기억장치) 사이의 속도 차이로 발생하는 병목 현상을 줄이기 위한 메모리이다.
(2) 작동 원리
- CPU가 주기억장치(RAM)에서 데이터를 읽어올 때, 자주 사용하는 데이터를 캐시 메모리에 임시 저장한다.
- 다음에 해당 데이터를 이용할 때 주기억장치가 아닌 캐시 메모리에서 먼저 가져와 속도를 향상시킨다.
(3) 장단점
- 장점: 속도 향상
- 단점: 용량이 적고 비용이 비싸다.
🌟 캐시 메모리가 비싼 이유: SRAM을 사용하기 때문
SRAM은 'Static Random Access Memory(정적 랜덤 액세스 메모리)'의 약자로, 전원이 공급되는 동안에는 저장된 데이터가 사라지지 않고 유지되는 메모리이다.
우리가 흔히 '램(RAM)'이라고 부르는 주기억장치(DRAM)와는 몇 가지 결정적인 차이가 있다.-
SRAM vs. DRAM
보통 컴퓨터의 메인 메모리(RAM)는 DRAM을 쓰고, CPU 안의 캐시 메모리는 SRAM을 쓴다.구분 SRAM (캐시 메모리) DRAM (주기억장치) 속도 매우 빠름 상대적으로 느림 가격 매우 비쌈 상대적으로 저렴함 구조 복잡함 (트랜지스터 6개 필요) 단순함 (트랜지스터 1개 + 커패시티 1개) 특징 데이터 유지를 위한 재충전 필요 없음 데이터 유지를 위해 주기적으로 재충전 필요 용도 CPU 캐시 (L1, L2, L3) 메인 메모리 (우리가 구매하는 8GB, 16GB RAM) -
왜 SRAM은 비쌀까?
- 복잡한 설계: SRAM은 데이터 1비트를 저장하는 데 보통 6개의 트랜지스터가 필요하다. 반면 DRAM은 트랜지스터 1개와 전기를 담는 통(커패시터) 1개면 충분하다.
- 공간 효율성: 같은 면적에 DRAM은 데이터를 꽉꽉 채워 넣을 수 있지만, SRAM은 구조가 복잡해서 많이 넣지 못한다. 그래서 용량 대비 가격이 훨씬 비싸다.
-
왜 캐시 메모리에 SRAM을 쓸까?
비싼데도 쓰는 이유는 오직 '속도' 때문이다.
CPU는 1초에 수십억 번 연산을 하는데, 일반 DRAM(메인 메모리)은 그 속도를 따라오지 못해 병목 현상이 생긴다.
SRAM은 재충전 과정이 필요 없고 구조적으로 CPU 속도에 맞춰 데이터를 즉각 주고받을 수 있어서 캐시 메모리로 선택된 것이다.
-
(4) CPU 캐시 메모리의 종류 및 위치
-
CPU 캐시 구성: CPU에는 일반적으로 2~3개 정도의 캐시 메모리가 사용되며, 이를 L1, L2, L3 캐시 메모리라고 부른다.
-
속도 및 접근 순서
- 캐시는 속도와 크기에 따라 분류되며, 일반적으로 L1 캐시부터 먼저 사용된다.
- CPU는 L1 캐시에 가장 빠르게 접근하며, 여기서 데이터를 찾지 못하면 L2 캐시로 접근한다.
-
캐시별 위치
- L1 캐시: CPU 내부
- L2 캐시: CPU와 RAM 사이
- L3 캐시: 메인보드
🌟 메인보드란?
- 메인보드(Motherboard)
컴퓨터 본체를 열었을 때 가장 크게 보이는 판이 바로 메인보드이다.
여기에는 다음과 같은 핵심 부품들이 모두 꽂히게 된다.- CPU: 컴퓨터의 두뇌
- RAM: 주기억장치
- 그래픽카드: 화면 출력 담당
- 저장장치(SSD/HDD): 데이터 저장
- L3 캐시의 위치: 메인보드 vs. CPU 내부
- 과거의 방식: 예전에는 기술적 한계로 L1, L2 캐시만 CPU 안에 넣고, 용량이 큰 L3 캐시는 CPU 밖인 메인보드에 따로 장착하기도 했다.
- 현대의 방식: 하지만 지금은 기술이 발전해서 L3 캐시도 CPU 칩(패키지) 안에 함께 들어있는 경우가 대부분이다. CPU와 물리적으로 더 가까워야 속도가 더 빨라지기 때문이다.
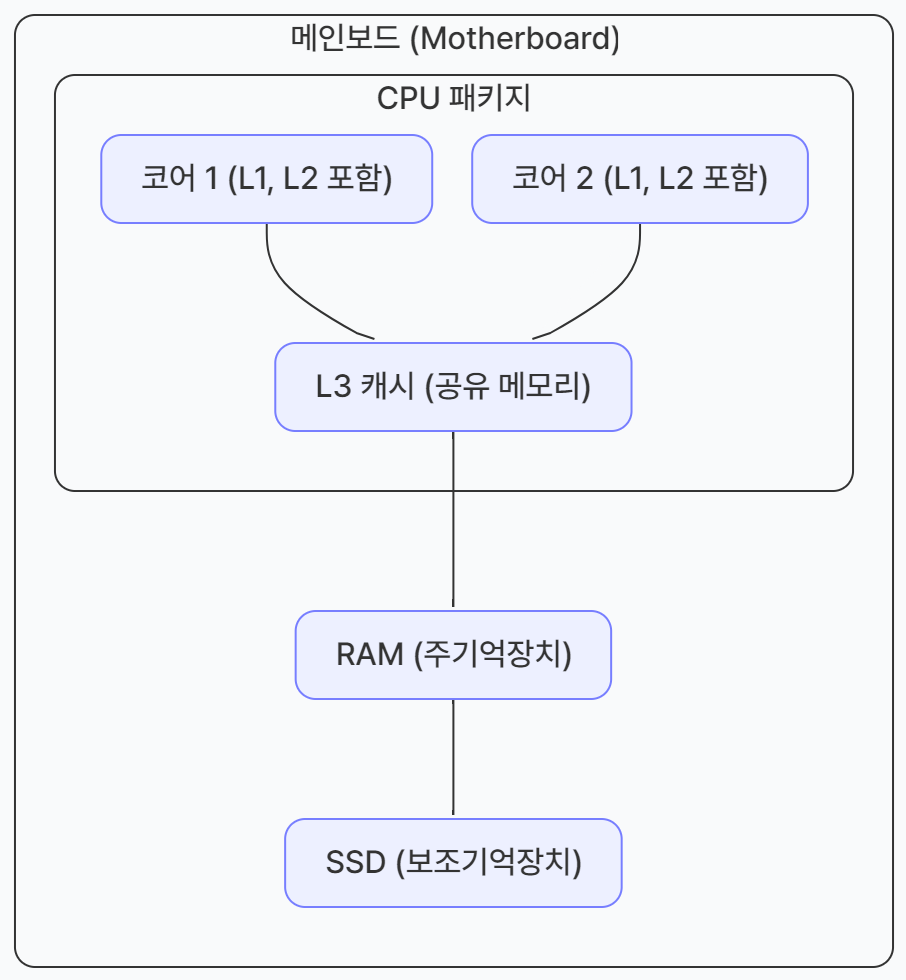
- 메인보드(Motherboard)
-
듀얼 코어 프로세서의 캐시 구조
-
각 코어마다 독립된 L1 캐시 메모리를 가진다.
-
두 코어가 공유하는 L2 캐시 메모리가 내장된다.
-
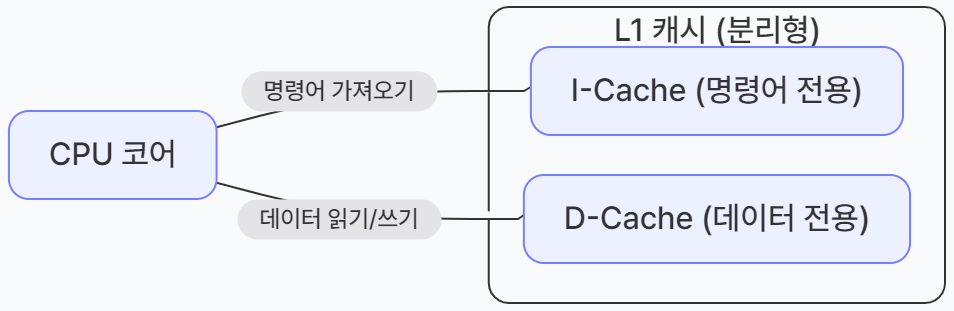
L1 캐시가 128KB인 경우, 64KB는 명령어를 처리하기 직전의 명령어를 임시 저장하는 I-Cache로, 나머지 64KB는 실행 후 명령어를 임시 저장하는 D-Cache로 나누어 사용된다.
🌟 코어(Core)란?
'코어'는 쉽게 말해 CPU라는 큰 두뇌 안에 들어있는 '실제로 일을 하는 작은 두뇌'라고 생각하면 된다. 예전에는 CPU 하나에 두뇌가 하나뿐이었지만, 지금은 기술이 좋아져서 하나의 CPU 칩 안에 여러 개의 두뇌(코어)를 넣을 수 있게 되었다.
- 쉬운 비유: 요리사(코어)와 주방(CPU)
- 싱글 코어: 주방에 요리사가 1명 있는 상황이다. 재료 손질도 하고, 불 조절도 하고, 설거지도 혼자 다 해야 하니 한 번에 한 가지 요리밖에 못 한다.
- 멀티 코어(듀얼, 쿼드 등): 주방에 요리사가 여러 명 있는 상황이다. 한 명은 채소를 썰고, 다른 한 명은 고기를 굽는 등 일을 나눠서 하기 때문에 훨씬 빠르고 여러 요리를 동시에 할 수 있다.
- 코어와 캐시 메모리의 관계
- L1 캐시 (개인 도구): 각 요리사(코어)가 자기 손에 바로 쥐고 있는 칼이나 도마 같은 것이다. 다른 요리사와 공유하지 않고 나만 빠르게 쓴다.
- L2/L3 캐시 (공용 냉장고): 주방에 있는 큰 냉장고 같은 것이다. 모든 요리사(코어)가 함께 사용하며 필요한 재료를 꺼내 간다.
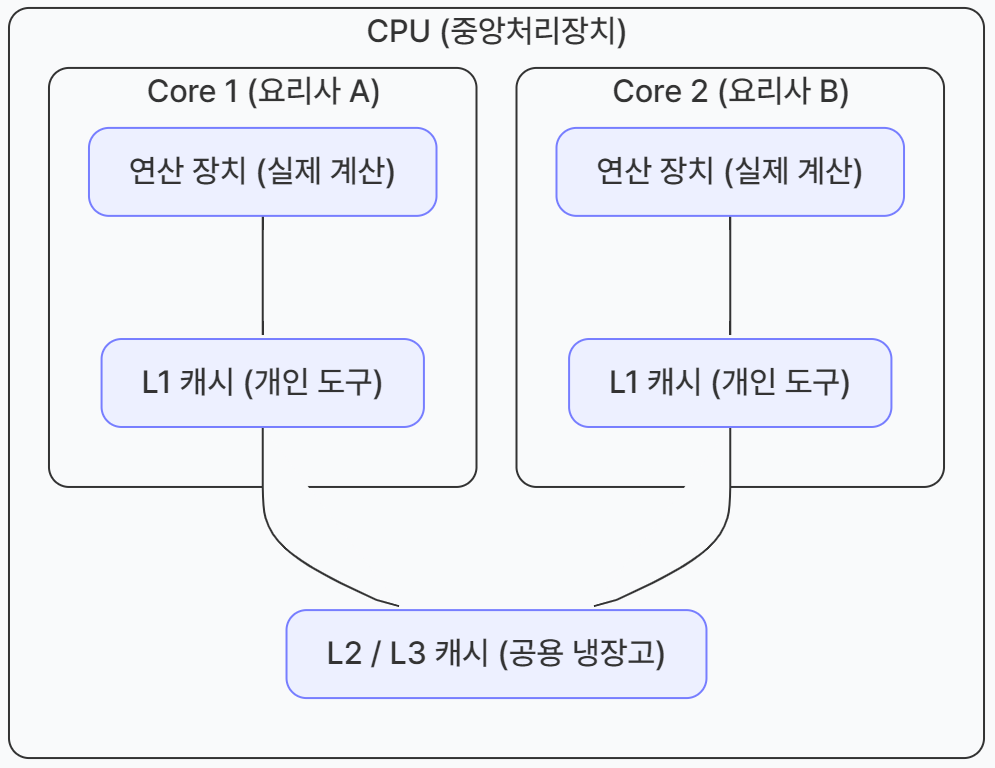
- 코어가 많으면 무조건 좋을까?
이론적으로는 코어가 많을수록 성능이 좋아지지만, 여기에는 조건이 있다.- 소프트웨어의 지원: 요리사가 10명 있어도, 요리법(프로그램)이 "한 명이 처음부터 끝까지 다 해라"라고 적혀 있으면 나머지 9명은 놀게 된다. 이를 '멀티 코어 최적화'라고 한다.
- 클럭 속도: 요리사 수가 적어도 손이 엄청나게 빠른 요리사가, 손이 느린 요리사 여러 명보다 나을 때도 있다. 이 '손 속도'가 바로 CPU의 GHz 단위인 '클럭'이다.
🌟 I-Cache, D-Cache
I-Cache와 D-Cache는 L1 캐시가 효율성을 높이기 위해 '명령어'와 '데이터'를 저장하는 공간을 아예 분리해 놓은 것을 말한다.
- 각각의 역할
- I-Cache (Instruction Cache, 명령어 캐시): CPU가 어떤 동작을 해야 할지 알려주는 '명령어(코드)'들만 모아두는 곳이다. "더해라", "옮겨라" 같은 지시 사항들이 여기에 저장된다.
- D-Cache (Data Cache, 데이터 캐시): 그 명령어를 수행할 때 필요한 '실제 값(데이터)'들을 모아두는 곳이다. "10", "20" 같은 숫자나 변수 값들이 여기에 저장된다.
- 공간을 나누는 이유: 병목 현상 방지
CPU는 일을 할 때 '명령어를 읽어오는 단계'와 '데이터를 읽거나 쓰는 단계'를 동시에 처리하고 싶어 한다.- 나누지 않았을 때: 명령어를 읽으려고 하는데 마침 데이터를 쓰는 중이라면, 길이 하나라 서로 기다려야 하는 병목 현상이 생긴다.
- 나눴을 때 (I-Cache/D-Cache): 명령어를 가져오는 길과 데이터를 가져오는 길이 따로 있어서, 동시에 두 가지 일을 처리할 수 있다. 이를 통해 CPU의 처리 속도가 훨씬 빨라진다.
- 쉬운 비유: 요리사(코어)와 주방(CPU)
-
(5) 캐시 메모리의 작동 근거: 참조 지역성
- 참조 지역성의 원리: 캐시 메모리는 데이터의 참조 지역성 원리를 활용하여 작동한다.
- 시간 지역성 (Temporal Locality):
for이나while같은 반복문에 사용되는 조건 변수처럼, 한 번 참조된 데이터는 잠시 후 또 참조될 가능성이 높다. - 공간 지역성 (Spatial Locality): 배열
A[0],A[1]과 같이 연속적으로 접근할 때, 참조된 데이터 근처에 있는 데이터가 잠시 후 또 사용될 가능성이 높다.
- 시간 지역성 (Temporal Locality):
- 데이터 저장 방식: 캐시에 데이터를 저장할 때는 공간 지역성을 최대한 활용하기 위해, 요청된 데이터뿐만 아니라 옆 주소의 데이터도 같이 가져와 미래에 사용될 것에 대비한다.
(6) 캐시 히트와 캐시 미스 및 미스 유형 3가지
-
Cache Hit/Miss 정의
- Cache Hit: CPU가 요청한 데이터가 캐시에 존재하는 경우
- Cache Miss: CPU가 요청한 데이터가 캐시에 없어서 DRAM(주기억장치)에서 가져와야 하는 경우
-
캐시 미스 유형 3가지
-
Cold miss: 해당 메모리 주소를 처음 불러서 발생하는 미스
-
Conflict miss: 캐시 메모리에 A와 B 데이터를 저장해야 하는데, A와 B가 같은 캐시 메모리 주소에 할당되어 있어서 발생하는 미스
➡️ 이는 주로 Direct Mapped Cache 구조에서 많이 발생한다.🌟 Direct Mapped Cache란?
Direct Mapped Cache(직접 매핑 캐시)는 캐시 메모리 설계 방식 중 가장 단순하고 직관적인 구조이다.
- 핵심 개념: "너는 지정된 방에만 들어가!"
이 방식은 메인 메모리(RAM)의 특정 주소가 캐시의 특정 위치에만 들어갈 수 있도록 딱 정해놓은 방식이다.
예를 들어, RAM 주소가 32개 있고 캐시 방이 8개 있다면, 0, 8, 16, 24번 RAM 주소는 무조건 캐시의 0번 방만 써야 한다. (나머지 연산주소 % 8결과가 0이기 때문이다.) - 주소의 구성 (태그와 인덱스)
CPU가 메모리 주소를 들고 캐시를 찾아올 때, 그 주소를 세 부분으로 나눠서 해석한다.- 인덱스(Index): "캐시의 몇 번째 방으로 가야 하는가?"를 결정한다. (예: 8개의 방이 있다면 뒤의 3비트가 인덱스)
- 태그(Tag): "그 방에 들어있는 데이터가 내가 찾는 진짜 데이터가 맞는가?"를 확인하는 일종의 신분증이다. 여러 RAM 주수고 같은 방을 공유하므로, 현재 들어있는 데이터가 누구 것인지 표시해둬야 한다.
- 데이터(Data): 실제 저장된 내용물이다.
- 작동 과정
- 위치 찾기: CPU가 요청한 주소의 인덱스를 보고 캐시의 해당 슬롯으로 바로 달려간다.
- 본인 확인: 그 슬롯에 저장된 태그와 내가 들고 온 주소의 태그를 비교한다.
- 결과
- 태그가 일치하면(Cache Hit), 데이터를 즉시 가져온다.
- 태그가 다르거나 비어있으면(Cache Miss), RAM에서 데이터를 새로 가져와서 기존 데이터를 쫓아내고 저장한다.
- 장점과 단점
- 장점
- 매우 빠름: 인덱스만 보면 바로 위치를 알 수 있어 탐색 시간이 거의 걸리지 않는다.
- 단순함: 설계가 간단해서 비용이 저렴하다.
- 단점
- Conflict Miss(충돌 미스)에 취약: 같은 인덱스를 공유하는 데이터들을 번갈아 사용할 경우, 캐시 공간이 텅텅 비어 있어도 계속 서로를 밀어내는 비효율이 발생한다.
- 장점
- 핵심 개념: "너는 지정된 방에만 들어가!"
-
Capacity miss: 캐시 메모리의 공간 자체가 부족해서 발생하는 미스
➡️ Conflict miss는 주소 할당 문제인 반면, Capacity miss는 물리적인 공간 문제이다.
-
-
캐시 크기 증가의 단점: 캐시 크기를 키워서 Capacity miss 문제를 해결하려고 하면, 캐시 접근 속도가 느려지고 전력 소모(파워)가 많아지는 단점이 발생한다.
2. 캐시 메모리의 구조 및 작동 방식 (매핑 기법)
(1) Direct Mapped Cache (직접 매핑)
- 구조 및 방식: 가장 기본적인 구조로, DRAM의 여러 주소가 캐시 메모리의 하나의 주소에 대응되는 다대일 방식이다.
- 주소 구성: 캐시 메모리는 인덱스 필드, 태그 필드, 데이터 필드로 구성된다.
- 예시 상황: 메모리 공간 32개(00000~11111)와 캐시 메모리 공간 8개(000~111)가 있는 경우
- 메모리 주소 00000, 01000, 10000, 11000는 캐시 메모리 주소 000에 매핑된다.
- 이때 000이 인덱스 필드이며, 인덱스를 제외한 앞의 나머지(00, 01, 10, 11)가 태그 필드이다.
- 예시 상황: 메모리 공간 32개(00000~11111)와 캐시 메모리 공간 8개(000~111)가 있는 경우
- 장점과 단점
- 장점: 구조가 간단하고 접근 속도가 빠르다.
- 단점: Conflict Miss가 발생하는 것이 가장 큰 단점이다. 이는 같은 인덱스의 데이터를 동시에 사용해야 할 때 발생한다.
(2) Fully Associative Cache (완전 연관 매핑)
- 구조 및 방식: 비어 있는 캐시 메모리가 있으면 마음대로 주소를 저장하는 방식
- 저장 및 검색
- 저장: 저장 시 조건이나 규칙이 없기 때문에, 저장할 때는 매우 간단하다.
- 검색: 데이터를 찾을 때 특정 캐시 Set 안에 있는 모든 블럭을 한 번에 검색하여 원하는 데이터가 있는지 확인해야 한다.
- 특징: 검색을 위해 CAM(Content Addressable Memory)이라는 특수한 메모리 구조를 사용해야 하며, 이로 인해 가격이 매우 비싸다.
🌟 CAM (Content Addressable Memory)
CAM은 우리가 흔히 아는 메모리(RAM)와는 정반대로 작동하는 아주 독특하고 똑똑한 메모리이다.
- RAM vs. CAM: 찾는 방식의 차이
- RAM (주소로 찾기): "10번 방에 뭐가 들어있니?"라고 물어보는 방식이다. 주소를 주면 데이터를 준다.
- CAM (내용으로 찾기): "이 데이터(내용)가 어느 방에 들어있니?"라고 물어보는 방식이다. 데이터를 주면 그 데이터가 있는 주소를 알려준다.
- 왜 Fully Associative Cache에서 CAM이 필요할까?
Fully Associative Cache는 "비어 있는 캐시 메모리가 있으면 마음대로 저장"하는 방식이다.- 문제: 데이터가 아무 데나 저장되어 있으니까, 나중에 찾을 때 어느 방에 있는지 알 수가 없다.
- 해결: 모든 방을 하나하나 순서대로 뒤지면 너무 느리다. 이때 CAM을 사용하면 모든 방을 동시에(병렬로) 훑어서 "내가 찾는 데이터 여기 있어!"라고 0.000...1초 만에 대답해 줄 수 있다.
- CAM의 장단점
- 장점: 모든 메모리 셀을 한 번에 검색하기 때문에 검색 속도가 압도적으로 빠르다.
- 단점
- 비쌈: 각 메모리 셀마다 "내가 찾는 게 맞나?"를 비교하는 복잡한 회로가 추가로 붙어야 해서 일반 SRAM보다 훨씬 비싸다.
- 전력 소모: 모든 방을 동시에 뒤지다 보니 전기를 엄청나게 많이 먹고 열도 많이 난다.
- RAM vs. CAM: 찾는 방식의 차이
(3) Set Associative Cache (집합 연관 매핑)
- 구조 및 방식: Direct Mapped 방식과 Fully Associative 방식의 장점을 결합한 중간형이다.
- 작동 원리: 특정 행(Set)을 지정하고, 그 행 안의 어떤 열이든 비어있을 때 데이터를 저장하는 방식이다.
- 성능 비교
- Direct Mapped Cache에 비해 검색 속도는 느리지만, 저장이 빠르다.
- Fully Associative Cache에 비해 저장이 느린 대신, 검색이 빠르다.
- 특징: 이 방식은 위 두 가지 방식보다 나중에 나온 방식이며, 실제로 많이 사용된다.
🌟 실무에서는 어떤 방식이 가장 많이 쓰일까?
- 실무의 주인공: Set Associative Cache
현대의 Intel, AMD, ARM 프로세서의 L1, L2, L3 캐시는 거의 100% 이 방식을 사용한다.
- 이유: "적절한 타협" 때문이다.
- Direct Mapped만큼 빠르지는 않지만, 충돌 미스(Conflict Miss)를 획기적으로 줄여준다.
- Fully Associative만큼 유연하지는 않지만, 훨씬 싸고 전기를 적게 먹는다.
- 실제 사례
- L1 캐시: 보통 4-way 또는 8-way 방식을 쓴다. (속도가 중요해서 길을 너무 많이 나누지는 않는다.)
- L2 캐시: 12-way, 16-way 등 더 많은 길을 나눈다. (용량이 커서 충돌이 더 자주 날 수 있으니 더 유연하게 관리한다.)
- 다른 방식들은 아예 안 쓸까?
아니다. 각자의 장점이 뚜렷해서 특정 용도로는 여전히 쓰이고 있다.
- Direct Mapped Cache: 아주 저전력, 저성능의 간단한 임베디드 칩이나, 속도가 극단적으로 중요하고 데이터 패턴이 뻔한 특수 구조에서 간혹 쓰인다.
- Fully Associative Cache: 캐시 메모리 전체로 쓰기엔 너무 비싸지만, TLB(주소 변환 버퍼) 같은 아주 작고(보통 64~128개 항목) 속도가 생명인 특수 캐시에는 이 방식을 쓴다. 비싸더라도 "무조건 한 번에 찾아야 하는" 곳에 투입되는 정예 요원 같은 느낌이다.
- 한눈에 비교하는 실무 선호도
방식 실무 활용도 주요 용도 비유 Direct Mapped 낮음 아주 단순한 저가형 칩 지정석 (빠르지만 융통성 제로) Fully Associative 부분적 (특수 목적) TLB, 아주 작은 버퍼 자유석 (찾기 힘들지만 빈자리 다 씀) Set Associative 매우 높음 (표준) 대부분의 CPU 캐시 구역 지정 자유석 (가장 효율적)
