1. TCP 통신의 기본 개념
✨ TCP란?
TCP(Transmission Control Protocol)는 신뢰성 있는 데이터 전송을 보장하는 연결 지향 프로토콜이다.
- 핵심 특징
- Unreliable Network에서 Reliable Network를 구현
- 순서 보장, 오류 검출 및 재전송 지원
- 연결 설정 및 종료 과정 존재 (3-way/4-way handshake)
✨ TCP가 해결해야 하는 4가지 문제
- 패킷 손실 (Packet Loss)
- 개념: 네트워크 중간에서 패킷이 유실되는 문제
- 해결: ACK 타임아웃 후 재전송
- 순서 뒤바뀜 (Out of Order)
- 개념: 패킷이 순서대로 도착하지 않는 문제
- 해결: Sequence Number로 재정렬
- 네트워크 혼잡 (Congestion)
- 개념: 네트워크 경로 상의 라우터나 스위치에 트래픽이 집중되는 문제
- 해결: 혼잡 제어로 해결
- 수신자 과부하 (Receiver Overload)
- 개념: 수신자의 처리 속도가 송신 속도를 따라가지 못하는 문제
- 해결: 흐름 제어로 해결
✨ 송수신 과정의 이해
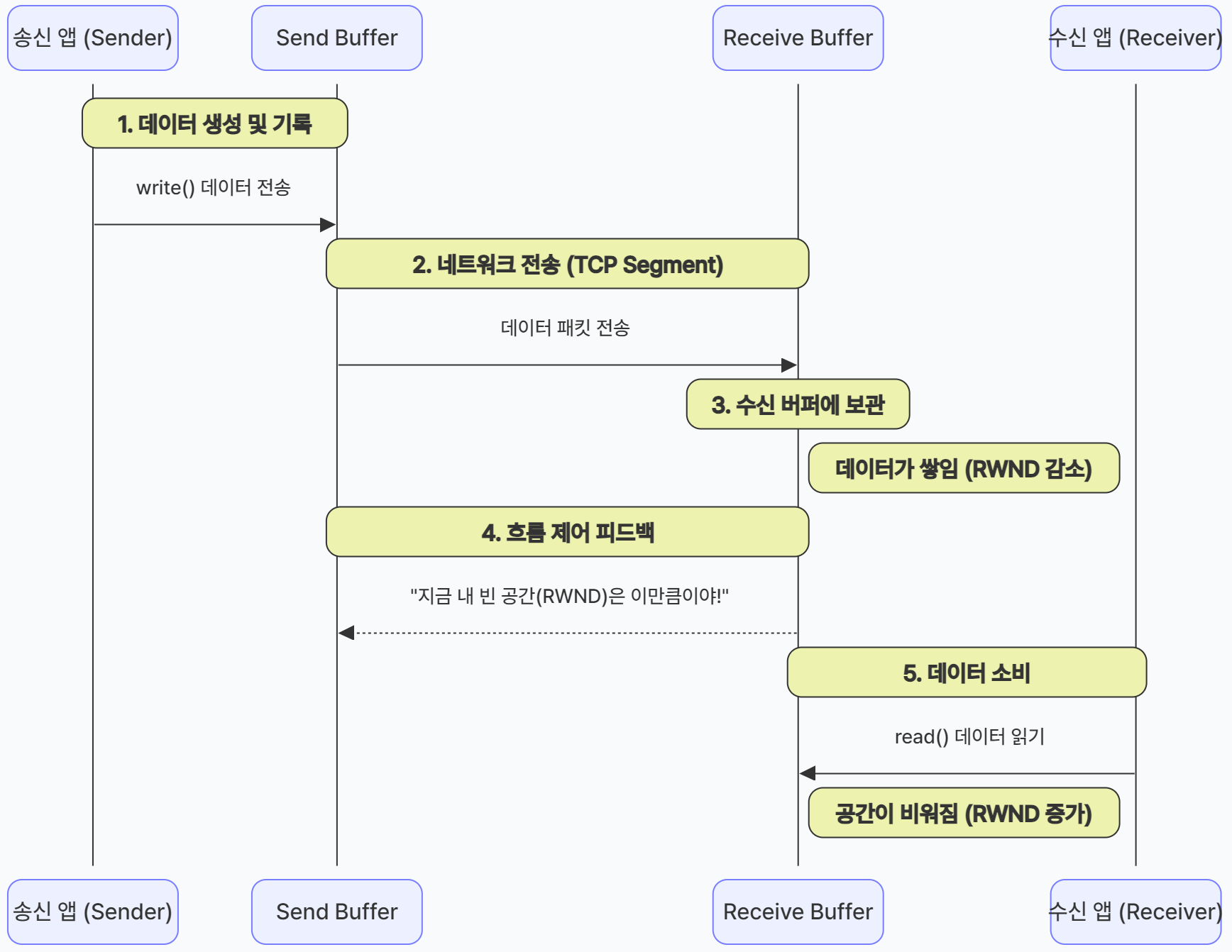
- Send Buffer (송신 버퍼): 애플리케이션이
write()를 통해 보낸 데이터를 네트워크로 나가기 전까지 잠시 쌓아두는 곳이다. - Receive Buffer(수신 버퍼): 상대방이 보낸 데이터가 도착했을 때, 수신측 애플리케이션이
read()로 가져가기 전까지 보관하는 장소이다. - RWND (Receive Window): 수신 버퍼에 현재 데이터를 얼마나 더 받을 수 있는지 알려주는 '잔여 용량'이다. 수신측은 이 크기를 송신측에 계속 알려주어, 송신측이 창고가 넘치지 않게 보낼 양을 조절하게 한다.
2. 흐름 제어 (Flow Control)
✨ 흐름 제어란?
- 정의: 송신자와 수신자 간의 데이터 처리 속도 차이를 조절하는 기법
- 목적: 수신자의 버퍼 오버플로우 방지
- 핵심 원리: 수신자가 자신의 현재 상태(남은 버퍼 공간)를 송신자에게 알려주는 피드백 방식
✨ 흐름 제어가 필요한 이유
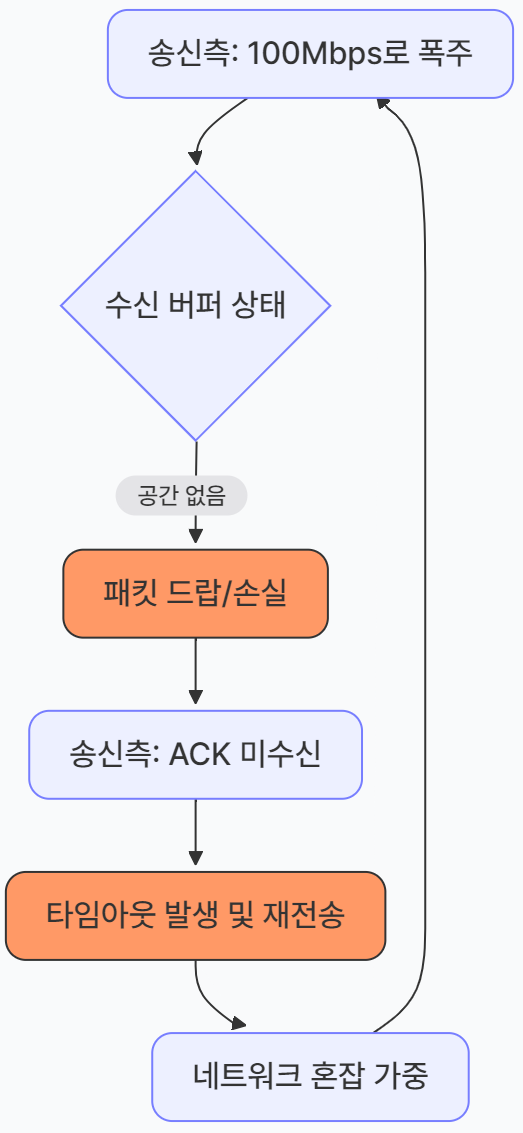
- 수신 버퍼 오버플로우 (Overflow)
수신측의 애플리케이션이 데이터를 가져가는 속도(read())보다 네트워크에서 데이터가 들어오는 속도가 10배나 빠르면, 수신 버퍼는 순식간에 꽉 차게 된다.
버퍼가 가득 찬 상태에서 새로 도착하는 데이터는 저장될 곳이 없어 그대로 버려지는데, 이를 '오버플로우'라고 한다.
- 패킷 손실과 재전송의 늪
데이터가 버려지면 송신측은 상대방으로부터 "잘 받았다"는 응답(ACK)을 받지 못하게 된다. 그러면 송신측은 다음과 같은 행동을 한다.- 재전송: "어? 응답이 없네? 다시 보내야지!" 하고 똑같은 데이터를 또 보낸다.
- 자원 낭비: 이미 보냈던 데이터를 다시 보내는 데 네트워크 대역폭과 CPU 자원이 이중으로 소모된다.
- 비효율의 극치
수신측은 여전히 초당 10Mb밖에 처리하지 못하는데, 송신측은 손실된 데이터를 다시 보내느라 바쁘다.
결국 전체적인 통신 효율은 급격히 떨어지고, 네트워크는 불필요한 재전송 패킷들로 가득 차게 된다.
✨ 흐름 제어에서 자주 놓치는 디테일
-
Zero Window & Persist Timer: 교착 상태 탈출하기
-
필요성
수신자의 버퍼가 꽉 차면RWND=0이라고 알리면, 송신자는 전송을 멈추고 기다린다. 이후 수신자가 버퍼를 비우고 "이제 보내도 돼! (RWND=100)"라는 ACK를 보냈는데, 이 패킷이 중간에 사라지면(유실) 어떻게 될까?- 송신자: "아직 0이구나... 계속 기다려야지."
- 수신자: "보내라고 했는데 왜 안 보내지? 계속 기다려야지."
이것이 바로 아무도 움직이지 못하는 교착 상태(Deadlock)이다.
-
해결책: Persist Timer & Zero-Window Probe
이때 송신자의 Persist Timer가 작동한다.- 일정 시간이 지나면 송신자는 "진짜 아직도 0이야?"라고 묻는 아주 작은 패킷(Zero-Window-Probe)을 하나 보낸다.
- 수신자는 이 질문에 답을 하면서 현재의 진짜 RWND 값을 다시 알려주게 된다.
- 덕분에 유실되었던 "창문 열림" 소식을 다시 듣고 통신을 재개할 수 있다.
-
-
Silly Window Syndrome(SWS) & Nagle: 배보다 배꼽이 더 큰 상황 방지
-
필요성
데이터는 1바이트인데, 이걸 보내기 위한 TCP/IP 헤더는 보통 40바이트이다.- 수신 앱이 데이터를 1바이트씩 아주 느리게 읽으면, 수신자는 창문을 1바이트씩만 찔끔찔끔 연다.
- 송신자는 신나서 1바이트를 40바이트 헤더에 담아 보낸다. 결과적으로 데이터보다 헤더가 훨씬 큰 비효율이 발생하는데, 이것이 '바보 같은 윈도우 증후군(SWS)'이다.
-
해결책: Nagle 알고리즘 (송신측 해결사)
나글 알고리즘은 "보낼 게 아주 작다면, 모아서 한꺼번에 보내거나 응답이 올 때까지 기다려라"라는 규칙이다.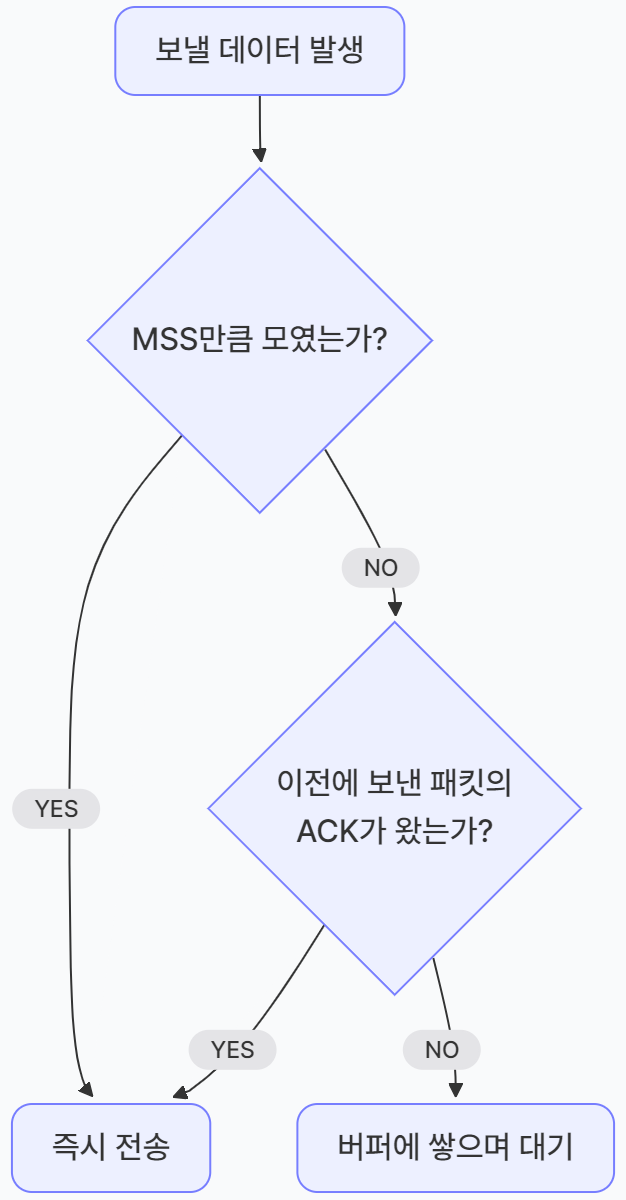
- 장점: 네트워크에 자잘한 패킷이 넘쳐나는 것을 막아 효율성을 극대화한다.
- 단점: 데이터를 모으거나 ACK를 기다려야 하므로 반응 속도(Latency)가 떨어진다. 그래서 실시간 게임이나 마우스 움직임 전송 같은 곳에서는 이 기능을 끄기도 한다.
-
3. 흐름 제어 기법
(1) Stop and Wait
이 방식의 핵심은 "상대방의 대답이 올 때까지 아무것도 하지 않고 기다린다"는 점이다.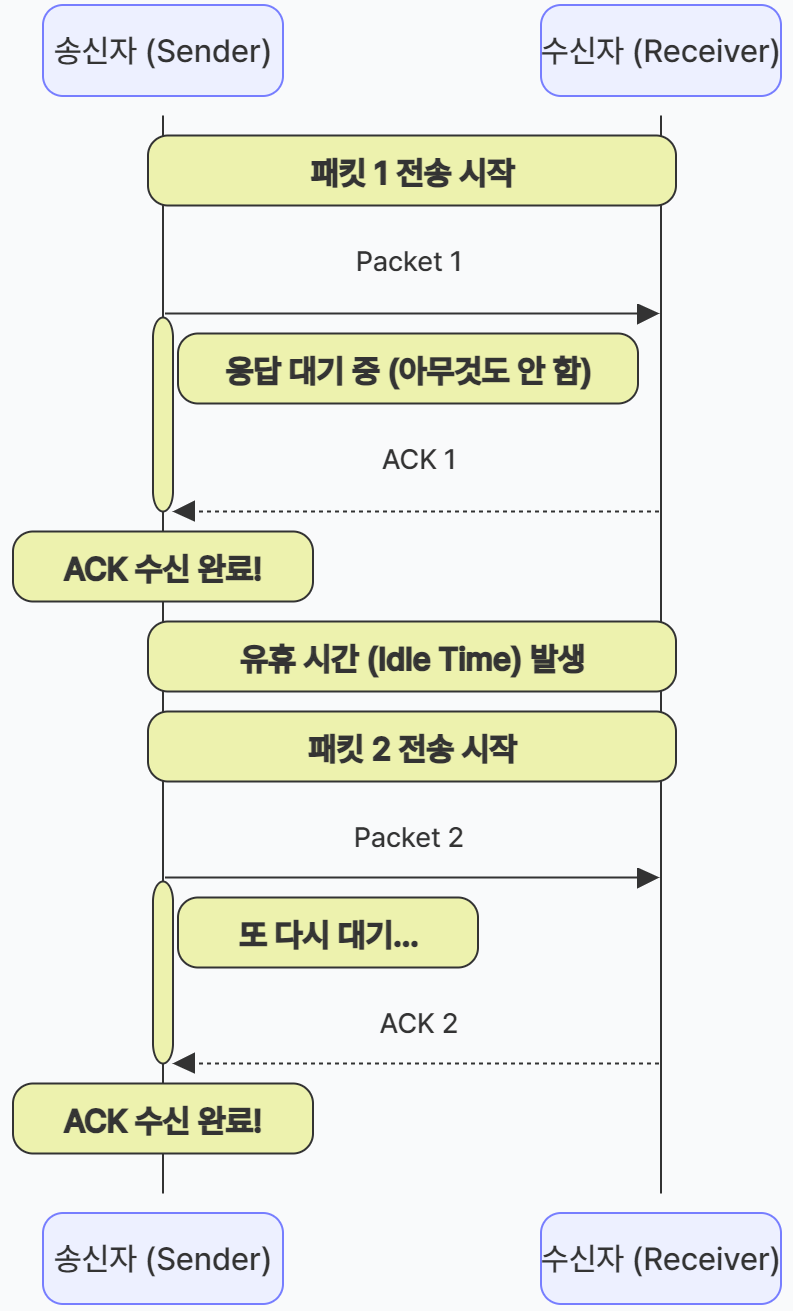
- 상세 동작 원리
- 데이터 전송: 송신자가 패킷 1개를 보낸다. 이때 송신자는 만약을 대비해 '타이머'를 작동시킨다.
- 대기 상태: 송신자는 다음 데이터를 보내지 않고, 수신자의 응답(ACK)이 올 때까지 멈춰서 기다린다.
- 응답 수신: 수신자가 데이터를 잘 받았다면 "잘 받았어(ACK)"라는 신호를 보낸다.
- 다음 단계: ACK를 받은 송신자는 그제야 타이머를 끄고 다음 패킷을 준비해서 보낸다.
- 효율성 계산 과정
- 전체 주기(Total Cycle): 1ms(전송) + 100ms(대기) = 101ms
- 실제 일한 시간: 1ms
- 효율(Utilization): 실제 일한 시간 / 전체 주기 = 1ms / 101ms ≈ 0.0099 = 약 1%
- 장점
- 구현이 매우 간단하다.
- 버퍼 오버플로우가 일어나지 않는다.
- 단점
- 네트워크 활용률이 매우 낮다.
- 전송 지연이 크다. (RTT(Round Trip Time, 왕복 시간)의 영향을 크게 받음)
(2) Sliding Window (슬라이딩 윈도우)
이 방식의 핵심은 "상대방이 허락한 범위 내에서, 일단 쏟아붓는다"는 점이다.
- '슬라이딩(Sliding)'이라는 이름이 붙은 이유
- 윈도우는 송신자가 한 번에 보낼 수 있는 데이터의 범위를 말한다.
- 수신자로부터 "1번 잘 받았어!"라는 응답(ACK)이 오면, 윈도우는 그 즉시 오른쪽으로 '스르륵' 미끄러지듯 이동하며 다음 데이터를 보낼 준비를 한다.
- 파이프라이닝(Pipelining)의 마법
- Stop and Wait이 패킷 하나를 보내고 응답이 올 때까지 네트워크를 비워뒀다면, 슬라이딩 윈도우는 네트워크라는 파이프를 데이터로 가득 채운다.
- 응답을 기다리는 동안에도 계속 다음 패킷을 보내기 때문에 처리량(Throughput)이 비약적으로 상승한다.
- 기본 공식
- LastByteSent - LastByteAcked ≤ ReceiveWindowAdvertised
➡️ 즉, (전송했지만 ACK 미수신 데이터) ≤ (수신자의 남은 버퍼 크기)
- LastByteSent - LastByteAcked ≤ ReceiveWindowAdvertised
-
단계별 이동 과정 (Window Size = 4)
- 1단계: 초기 전송 (1, 2, 3, 4번 전송)
윈도우가 1~4번을 감싸고 있으며, 이 패킷들을 한꺼번에 네트워크로 보낸다.송신 버퍼: [ 1 2 3 4 ] 5 6 7 8 ... └─윈도우(4)─┘ (전송 중...) - 2단계: 일부 ACK 수신 (1, 2번 완료)
수신자로부터 1번과 2번에 대한 확인 응답(ACK)이 도착한다.송신 버퍼: [ 1 2 ] 3 4 5 6 7 8 ... └─ACK─┘└─대기─┘ - 3단계: 윈도우 슬라이딩 (오른쪽으로 2칸 이동)
확인된 1, 2번만큼 윈도우가 오른쪽으로 '스르륵' 밀려난다. 이제 윈도우는 3, 4, 5, 6번을 감싸게 된다.송신 버퍼: 1 2 [ 3 4 5 6 ] 7 8 ... └─윈도우(4)─┘ - 4단계: 새로운 패킷 전송 (5, 6번 출발)
윈도우 안에 새로 들어온 5번과 6번 패킷을 즉시 전송한다.송신 버퍼: 1 2 [ 3 4 | 5 6 ] 7 8 ... └─기존─┘└─신규─┘
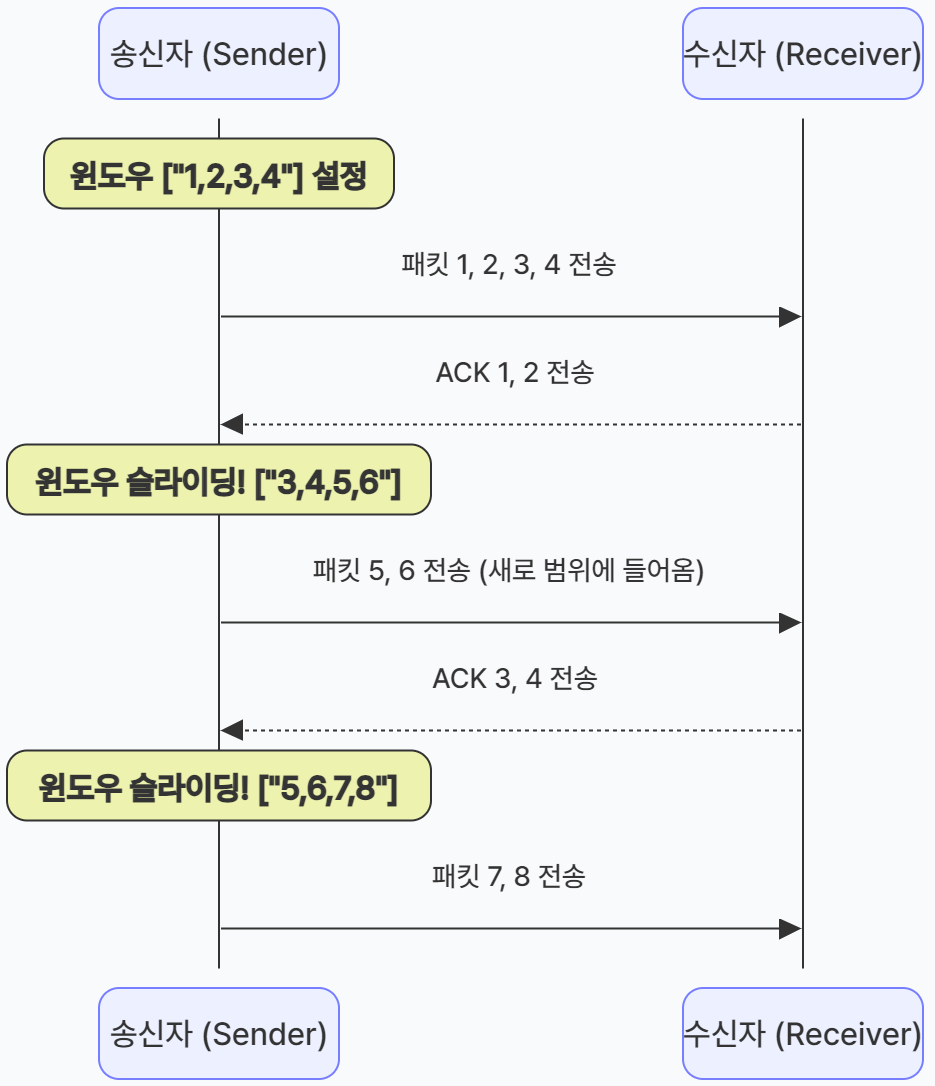
- 1단계: 초기 전송 (1, 2, 3, 4번 전송)
- 송신 버퍼의 4가지 상태
- ACKed (확인 완료): 상대방이 잘 받았다고 응답한 데이터로, 곧 버퍼에서 사라지는 데이터이다.
- In Flight (전송 중): 보냈지만, 아직 "잘 받았다"는 대답은 듣지 못한 데이터로, 윈도우 안에 있다.
- Usable (전송 가능): 윈도우 안에 있지만 아직 보내지 않은 데이터로, 즉시 전송할 수 있다.
- Not Usable (전송 불가): 윈도우 밖에 있는 데이터로, 앞선 데이터들의 ACK가 와서 윈도우가 밀려와야만 보낼 수 있다.
- 수신측의 역할: RWND (Receive Window)
- 슬라이딩 윈도우의 크기는 고정된 것이 아니다.
수신측은 자신의 수신 버퍼 남은 공간(RWND)을 수시로 송신측에 알려준다. - 수신 앱이 데이터를 빨리 읽으면 ➡️ RWND 증가 ➡️ 송신측 윈도우 커짐 ➡️ 전송 속도 빨라짐
- 수신 앱이 바빠서 데이터를 못 읽으면 ➡️ RWND 감소 ➡️ 송신측 윈도우 작아짐 ➡️ 전송 속도 느려짐
- 슬라이딩 윈도우의 크기는 고정된 것이 아니다.
- 장점
- 네트워크 대역폭을 효율적으로 사용할 수 있다.
- 파이프라이닝으로 처리량(Throughput)이 향상된다.
- 동적으로 전송 속도를 조절할 수 있다.
- 단점
- 구현이 복잡하다.
- 메모리 관리가 필요하다.
(3) Go-Back-N vs. Selective Repeat
- Go-Back-N (GBN): "뒤로 돌아가서 다 가져와!"
- GBN은 '누적 확인 응답(Cumulative ACK)' 방식을 사용한다.
수신자는 순서대로 받은 마지막 패킷에 대해서만 "여기까지 잘 받았어"라고 말한다. - 동작: 3번 패킷이 사라지면, 수신자는 4번, 5번을 받아도 계속 "난 2번까지만 받았어(ACK 2)"라고 대답한다.
- 재전송: 송신자는 "아, 3번부터 문제가 생겼구나"라고 판단하고, 이미 성공적으로 전송됐던 4번, 5번까지 포함해서 3번부터 다시 싹 보낸다.
- 장점: 수신측 구조가 단순하다. 순서가 어긋난 패킷을 따로 보관할 필요가 없기 때문이다.
- 단점: 이미 잘 도착한 패킷까지 다시 보내야 하므로 네트워크 낭비가 발생한다.
- GBN은 '누적 확인 응답(Cumulative ACK)' 방식을 사용한다.
- Selective Repeat (SR): "빠진 것만 골라서 보내줘!"
- SR은 '개별 확인 응답(Individual ACK)' 방식을 사용한다.
수신자는 순서가 어긋나더라도 도착한 패킷은 일단 다 챙겨둔다. - 동작: 3번이 사라져도 4번, 5번을 받으면 "4번 잘 받았어", "5번 잘 받았어"라고 각각 알려준다.
- 재전송: 송신자는 응답이 오지 않은 3번 패킷만 콕 집어서 다시 보낸다.
- 장점: 필요한 것만 보내므로 네트워크 효율이 매우 높다.
- 단점: 수신측이 순서가 바뀐 패킷들을 임시로 저장(버퍼링)하고, 나중에 순서를 재조합해야 해서 구현이 복잡하다.
- SR은 '개별 확인 응답(Individual ACK)' 방식을 사용한다.
4. 혼잡 제어 (Congestion Control)
✨ 혼잡 제어란?
- 정의: 네트워크의 혼잡을 방지하기 위해 송신자의 전송 속도를 제어하는 기법
- 네트워크 혼잡이 발생하면 다음과 같은 4단계의 파멸적 과정을 거치게 된다.
- 라우터의 비명 (Buffer Overflow)
- 인터넷의 교차로 역할을 하는 라우터는 들어오는 패킷을 잠시 보관하는 '큐(Queue)'라는 버퍼를 가지고 있다.
- 여러 송신자가 동시에 데이터를 쏟아부으면 이 큐가 꽉 차게 되고, 이후에 들어오는 패킷은 가차 없이 버려진다(Drop).
- 송신자의 오해 (Timeout & Retransmit)
- 패킷이 버려지면 송신자는 응답(ACK)을 받지 못한다.
- 송신자는 "아, 네트워크가 좀 느린가 보네?" 혹은 "패킷이 사라졌나 보네?"라고 생각하며 똑같은 데이터를 다시 보낸다(재전송).
- 불난 집에 부채질 (Congestion Collapse)
- 이미 막혀 있는 라우터에 재전송된 패킷까지 추가로 들어온다.
- 네트워크는 이제 새로운 데이터는커녕 재전송 데이터조차 처리하지 못하는 '혼잡 붕괴' 상태에 빠진다.
- 자원 낭비의 극치
- 결국 네트워크 대역폭은 '실제로 전달되는 데이터'가 아니라 '버려질 운명인 재전송 데이터'들로 가득 차게 된다.
- 라우터의 비명 (Buffer Overflow)
-
혼잡의 징후
네트워크는 자신이 힘들다는 신호를 다음과 같은 방식으로 보낸다.징후 발생 원인 비유 RTT 증가 라우터의 대기 줄(Queue)이 길어지면서 패킷이 통과하는 데 시간이 오래 걸린다. 고속도로 톨게이트 대기 시간이 길어지는 것 패킷 손실률 증가 라우터 버퍼가 꽉 차서 들어오는 패킷을 버리기 시작한다. 창고가 꽉 차서 배달된 물건을 길바닥에 버리는 것 타임아웃 발생 패킷이나 ACK가 중간에 사라져서 송신자가 무한정 기다리다 포기한다. 편지를 보냈는데 한 달째 답장이 없는 상황 중복 ACK 수신 중간 패킷 하나가 사라지면, 수신자는 그 이후 패킷을 받을 때마다 "나 아직 n번 못 받았어!"라고 계속 외친다. "3번 주세요", "3번 주세요", "3번 주세요"라고 계속 재촉하는 상황
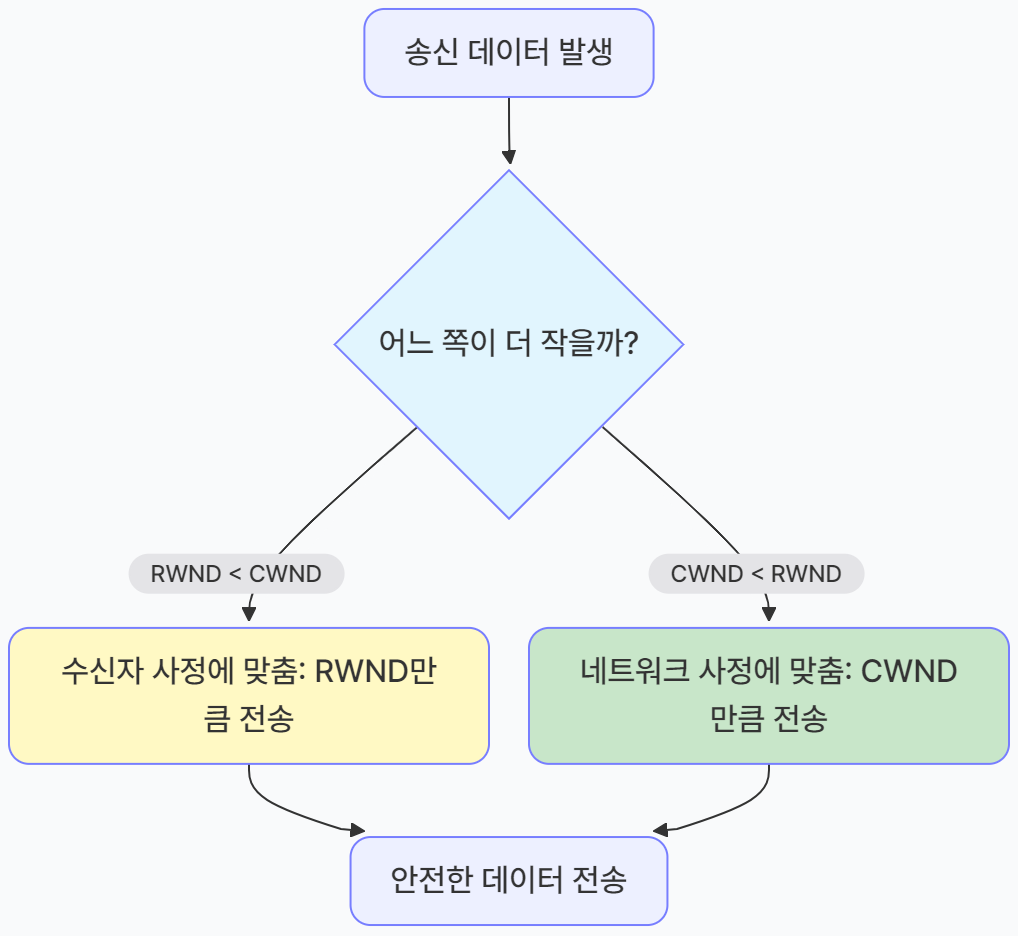
✨ 혼잡 윈도우 (CWND)
실제 전송량 =
min(CWND, RWND)
-
RWND (Receive Window): 수신자의 그릇 크기
- 관점: 수신측 (Flow Control)
- 의미: 수신자의 버퍼에 남은 빈 공간이 얼마인지를 나타낸다.
- 결정: 수신자가 TCP 헤더를 통해 송신자에게 빈 공간의 용량을 직접 알려준다.
-
CWND (Congestion Window): 네트워크 도로의 폭
- 관점: 네트워크 상황 (Congestion Control)
- 의미: 현재 네트워크가 혼잡하지 않게 보일 수 있는 데이터의 양이다.
- 결정: 송신자가 스스로 판단한다. 패킷이 잘 도착하면 조금씩 늘리고, 손실이 발생하면 확 줄이면서 최적의 값을 찾아낸다.
5. 혼잡 제어 알고리즘
(1) AIMD (Additive Increase / Multiplicative Decrease)
AIMD는 "조심스럽게 늘리고, 과감하게 줄인다"는 철학을 가진 알고리즘이다.
네트워크의 평화를 유지하는 가장 공평한 방식이지만, 동시에 아주 신중한 방식이기도 하다.
- Additive Increase (합 증가): "한 번 간을 볼까?"
- 동작: 패킷 전송에 성공하면 윈도우 크기(CWND)를 1씩 늘린다.
- 이유: 네트워크가 얼마나 비어있는지 모르기 때문에, 갑자기 확 늘렸다가 혼잡을 일으키지 않으려고 아주 조심스럽게 접근하는 것이다.
- Multiplicative Decrease (곱 감소): "앗, 위험해! 반으로 줄여!"
- 동작: 패킷 손실이나 혼잡이 감지되면 CWND를 절반(1/2)으로 뚝 떨어뜨린다.
- 이유: 혼잡이 발생했다는 건 네트워크가 비명을 지르고 있다는 뜻이다. 이때는 조금 줄여서는 해결이 안 되기 때문에, 즉각적이고 과감하게 전송량을 줄여서 네트워크가 숨을 쉴 틈을 주는 것이다.
- AIMD가 공평한 이유
-
시간에 따른 대역폭 변화 (Mbps)
호스트 A, B가 사용할 수 있는 총 네트워크 용량이 12Mbps라고 가정하자.시간 호스트 A (Mbps) 호스트 B (Mbps) 합계 상태 t1 10 2 12 정상 (용량 도달) t2 11 (+1) 3 (+1) 14 초과 t3 12 (+1) 4 (+1) 16 혼잡 발생 t4 6 (÷2) 2 (÷2) 8 절반으로 감소 t5 7 (+1) 3 (+1) 10 다시 증가 시작 t6 8 (+1) 4 (+1) 12 정상 t7 9 (+1) 5 (+1) 14 다시 혼잡 발생.. 최종 6 6 12 균등 분배 완료 -
핵심: 늘릴 때는 똑같이 +1씩 늘리지만, 줄일 때는 현재 가진 양의 절반을 줄인다는 점이 핵심이다.
-
결과: 많이 가진 쪽은 절반을 줄일 때 손실이 크고(-5), 적게 가진 쪽은 손실이 적다(-1). 이 과정이 반복되면 결국 두 호스트의 전송량은 황금 밸런스(50:50)에 수렴하게 된다.
-
- AIMD의 한계와 보완
- 문제점: 네트워크 대역폭이 아주 넓은 환경(예: 1Gbps 광랜)에서는 1씩 늘려서는 가득 채우기가 어려워, 초기 속도가 매우 답답하다는 단점이 있다.
- 해결책: 그래서 실제 TCP에서는 처음에 지수 함수적으로 속도를 확 올리는 'Slow Start' 방식을 먼저 사용하고, 어느 정도 궤도에 오르면 AIMD 방식으로 전환한다.
(2) Slow Start (느린 시작)
Slow Start는 이름은 '느린 시작'이지만, 실제로는 네트워크의 한계를 찾기 위해 가장 빠르게 가속하는 알고리즘이다.
AIMD의 답답한 초기 속도를 해결해주는 아주 똑똑한 방식이다.
- 지수적 증가
Slow Start는 패킷을 하나 보낼 때마다 ACK가 오면, ACK를 하나 받을 때마다 윈도우 크기를 1씩 늘린다.- 1개를 보내서 ACK 1개가 오면? ➡️ 다음엔 2개 전송
- 2개를 보내서 ACK 2개가 오면? ➡️ 다음엔 4개 전송
- 4개를 보내서 ACK 4개가 오면? ➡️ 다음엔 8개 전송
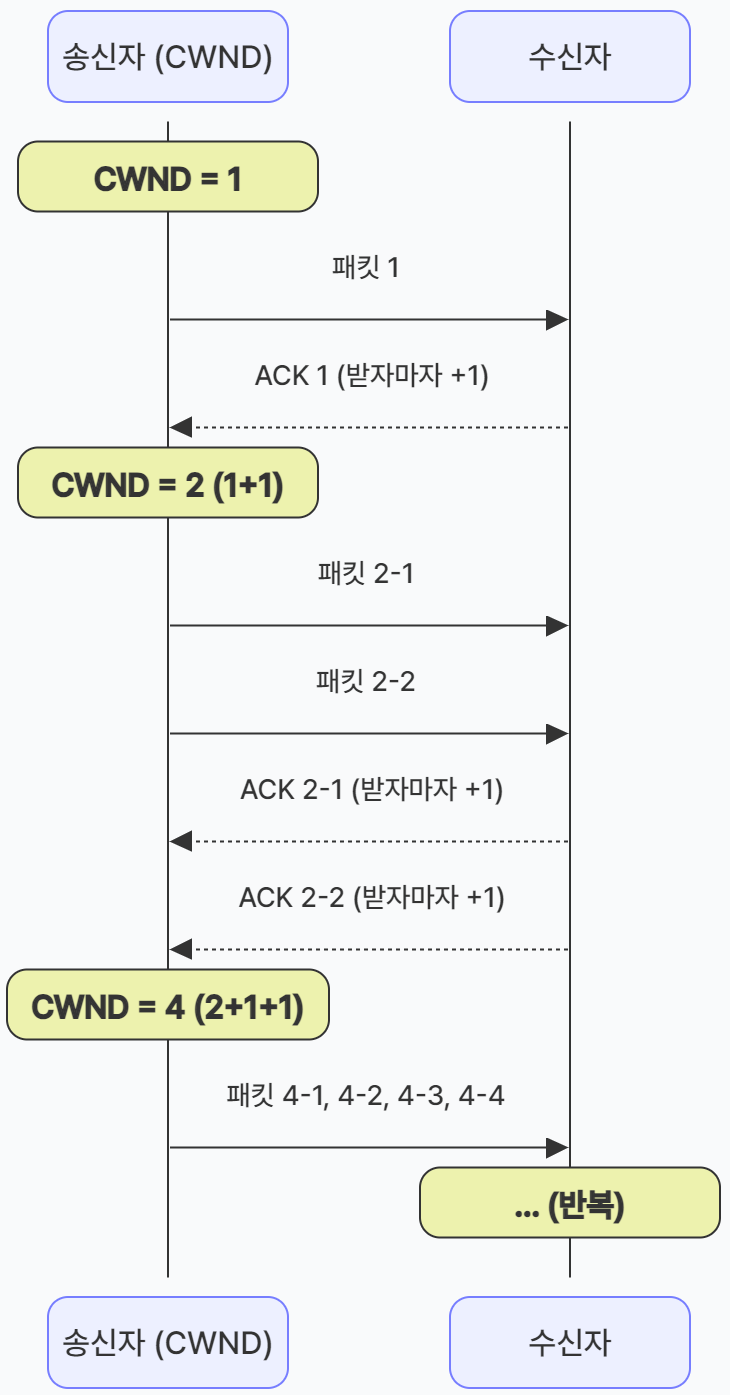
이렇게 매 주기마다 전송량이 2배씩(1, 2, 4, 8, 16...) 폭발적으로 늘어난다.
-
ssthresh (Slow Start Threshold): 안전 가이드라인
무한정 2배씩 늘리다가는 네트워크가 순식간에 터져버릴 위험이 있다.
그래서 '여기까지만 빠르게 가고, 그 다음부턴 조심하자'라고 정해둔 선이 바로 Threshold(임계점)이다.- Threshold 미만: 2배씩 지수 증가 (Slow Start)
- Threshold 이상: 1씩 선형 증가 (Congestion Avoidance / AIMD)
- 혼잡 발생 시의 변화 시각화
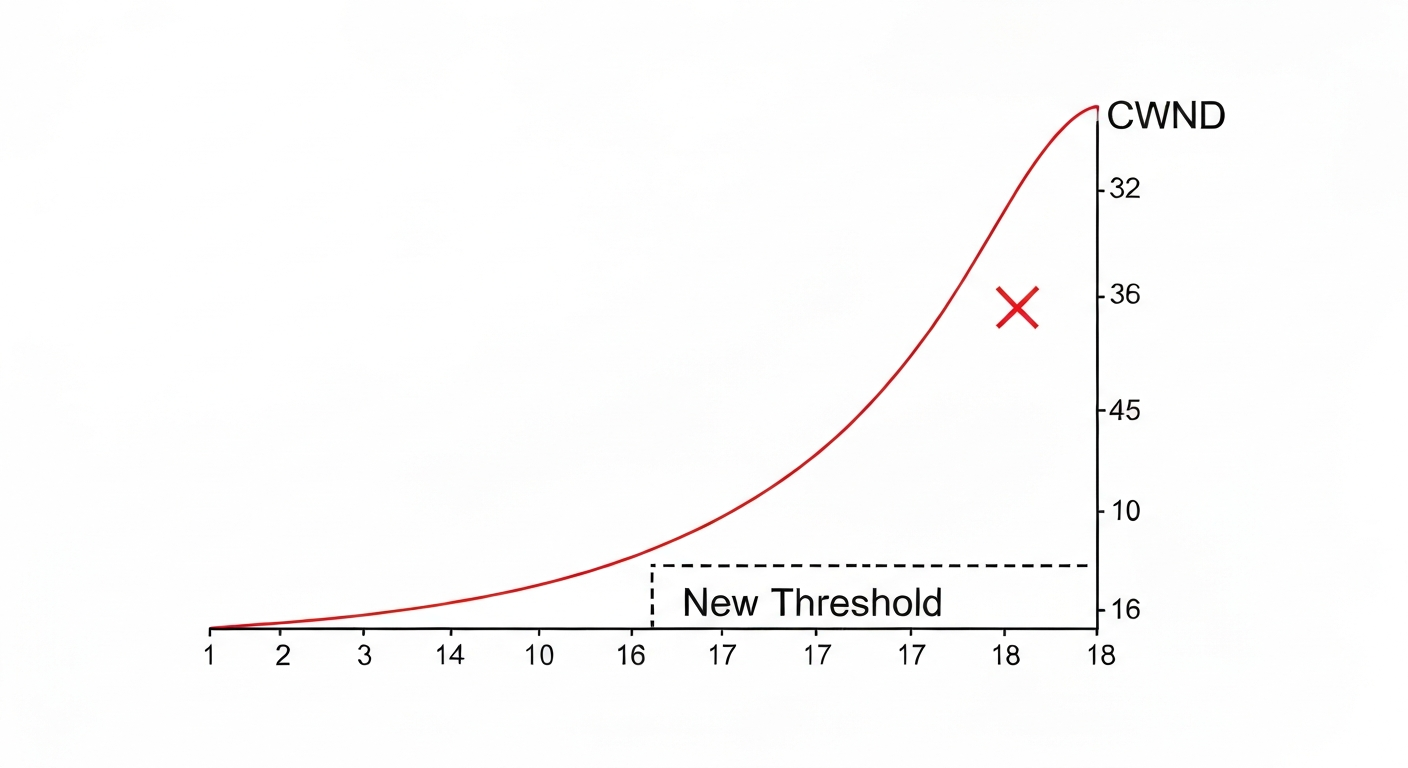
- 1단계: 초기 폭풍 가속 (t1 ~ t6)
- 동작: 1부터 시작해 매 RTT마다 2배씩 늘어난다. (1 → 2 → 4 → 8 → 16 → 32)
- 상태: 네트워크의 한계를 모르기 때문에 아주 공격적으로 대역폭을 채운다.
- 2단계: 혼잡 발생 및 응급 처치 (t6 ~ t7)
- 사건: 32KB에서 패킷 손실(혼잡)이 감지되었다.
- 조치 1 (Threshold): "아, 32는 너무 많구나. 절반인 16을 안전선으로 정하자." (ssthresh = 16KB)
- 조치 2 (CWND 리셋): 네트워크를 진정시키기 위해 전송량을 1로 뚝 떨어뜨린다.
- 3단계: 신중한 재시작 (t7 ~ t13)
- 가속 (t7 ~ t11): 안전선인 16KB까지는 다시 2배씩 빠르게 올라간다. (1 → 2 → 4 → 8 → 16)
- 신중 모드 (t11 ~): 안전선(Threshold)에 도달한 이후부터는 사고를 방지하기 위해 1씩 아주 조심스럽게 늘린다. (16 → 17 → 18...)
- 1단계: 초기 폭풍 가속 (t1 ~ t6)
- 알고리즘을 복잡하게 구성하는 이유
- 효율성: AIMD만 쓰면 1부터 100까지 가는 데 100번의 주기가 필요하지만, Slow Start를 섞으면 단 7번 만에 100 근처까지 갈 수 있다.
- 안정성: 혼잡이 발생했던 지점을 기억(Threshold)하기 때문에, 다음번에는 그 지점 근처에서 미리 속도를 줄여 사고를 예방할 수 있다.
(3) Fast Retransmit (빠른 재전송)
빠른 재전송(Fast Retransmit)은 TCP가 "가만히 앉아서 기다리는 대신, 적극적으로 문제를 해결하는" 아주 영리한 방식이다.
- 3번의 중복 ACK
네트워크에서는 패킷의 순서가 단순히 뒤바뀌는 경우(Reordering)가 종종 발생한다.- ACK 1번 중복: "어? 순서가 좀 바뀌었나?" 하고 기다려본다.
- ACK 2번 중복: "음... 진짜 문제가 있나?" 의심하기 시작한다.
- ACK 3번 중복: "이건 확실히 유실이다!"라고 확신하고 즉시 재전송한다. 이 '3번'이라는 숫자는 단순한 순서 바뀜과 실제 손실을 구분하는 심리적 마지노선인 셈이다.
- 타임아웃 vs. 빠른 재전송: 혼잡의 '급'이 다르다
TCP는 패킷이 왜 안 오는지에 따라 네트워크의 혼잡 상태를 다르게 판단한다.- 타임아웃 (Severe Congestion)
- 아무런 응답도 오지 않는 '침묵'의 상태이다.
- "길이 완전히 막혔구나!"라고 판단하여 CWND를 1로 리셋하고 처음부터 다시 시작한다. (Slow Start로 재시작)
- 빠른 재전송 (Mild Congestion)
- 중복 ACK가 온다는 건, 손실된 패킷 '이후'의 패킷들은 무사히 도착하고 있다는 뜻이다.
💡 핵심 원리: ACK는 패킷을 받을 때만 보낸다.
수신자는 아무 이유 없이 ACK를 보내지 않는다. 무언가 패킷이 도착했을 때만 "나 이거 받았어(혹은 이거 줘)"라고 대답을 한다.
- 수신자의 대답 규칙 (Cumulative ACK)
수신자는 항상 "다음에 받아야 할 패킷 번호"를 ACK에 적어서 보낸다.- 1번 받으면? ➡️ "다음엔 2번 줘 (ACK 2)"
- 2번 받으면? ➡️ "다음엔 3번 줘 (ACK 3)"
- 3번이 안 오고 4번이 오면? ➡️ "어? 4번이 왔네? 근데 난 3번이 필요한데.. 일단 3번 줘! (ACK 3)"
- 이후 패킷이 도착했다고 확신할 수 있는 이유
송신자 입장에서 생각해 보자. 3번을 달라는 똑같은 대답(ACK 3)이 3번이나 더 왔다.- 첫 번째 ACK 3: 4번 패킷이 수신자에게 도착했기 때문에 발생
- 두 번째 ACK 3: 5번 패킷이 수신자에게 도착했기 때문에 발생
- 세 번째 ACK 3: 6번 패킷이 수신자에게 도착했기 때문에 발생
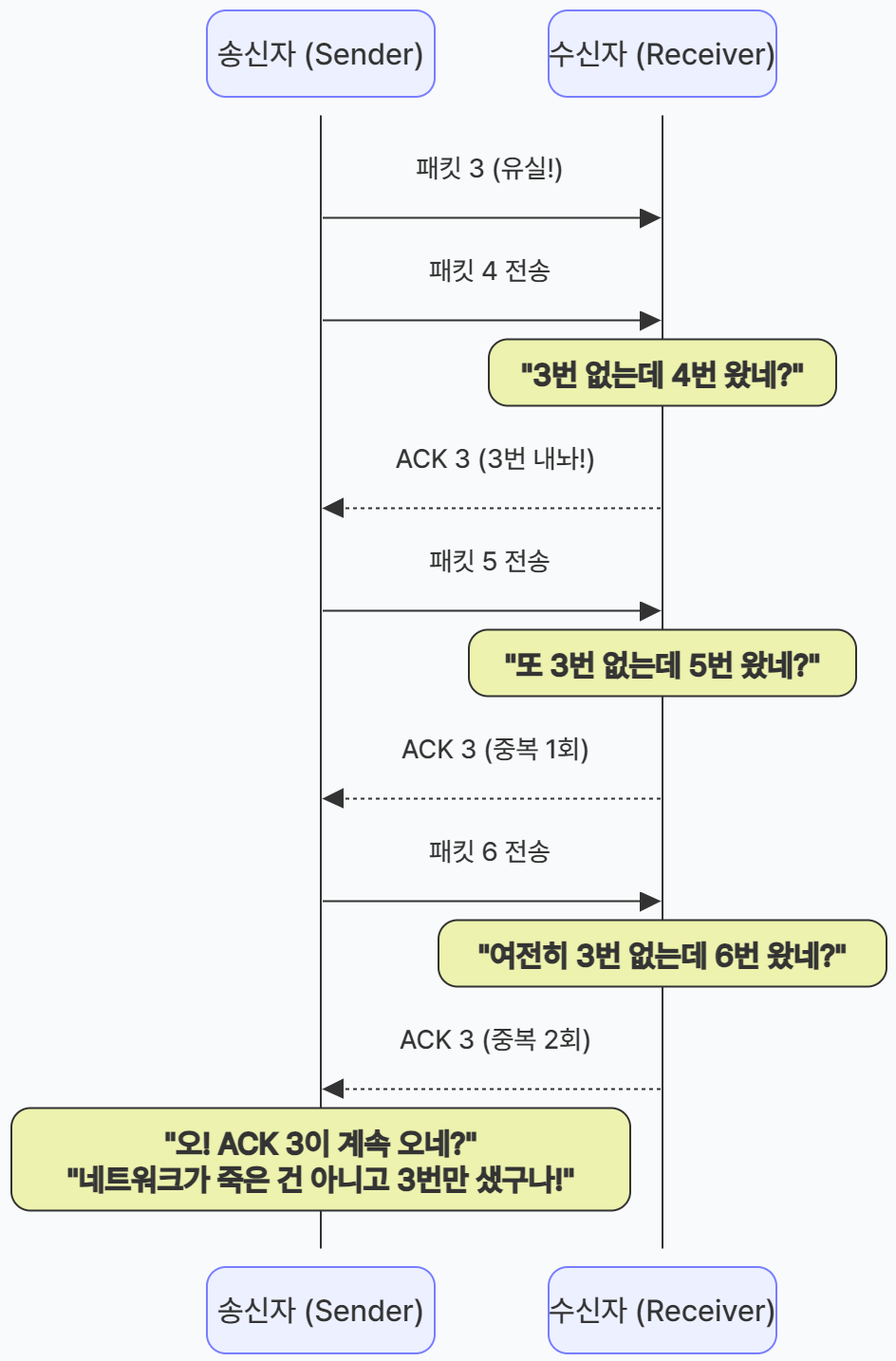 만약 네트워크가 완전히 꽉 막혀서(심각한 혼잡) 아무것도 안 지나간다면, 4, 5, 6번 패킷도 수신자에게 못 갔을 것이고, 수신자는 아무런 ACK도 보내지 못했을 것이다.
만약 네트워크가 완전히 꽉 막혀서(심각한 혼잡) 아무것도 안 지나간다면, 4, 5, 6번 패킷도 수신자에게 못 갔을 것이고, 수신자는 아무런 ACK도 보내지 못했을 것이다.
하지만 중복된 ACK라도 계속 온다는 것은, 비록 3번은 잃어버렸을지언정 4, 5, 6번 같은 뒤따라오는 패킷들은 무사히 네트워크를 통과해서 수신자에게 전달되고 있다는 확실한 증거가 된다. - 수신자의 대답 규칙 (Cumulative ACK)
- "길이 좀 막히긴 했지만, 아예 못 다닐 정도는 아니네?"라고 판단하여 CWND를 절반으로만 줄이고 계속 달린다. (Fast Recovery로 진입)
- 중복 ACK가 온다는 건, 손실된 패킷 '이후'의 패킷들은 무사히 도착하고 있다는 뜻이다.
- 타임아웃 (Severe Congestion)
- 빠른 회복(Fast Recovery)과의 조합
빠른 재전송이 일어나면 TCP는 보통 빠른 회복(Fast Recovery) 단계로 들어간다.- CWND 절반 감소: 사고가 났으니 일단 속도를 반으로 줄인다.
- 선형 증가 시작: 1부터 다시 시작하는(Slow Start) 고통스러운 과정 없이, 줄어든 지점부터 바로 AIMD 방식(1씩 증가)으로 전환하여 빠르게 원래 속도를 회복한다.
(4) Fast Recovery (빠른 회복)
빠른 회복(Fast Recovery)은 혼잡 제어의 '완성판' 같은 기술이다. 패킷 하나가 사라졌다고 해서 겁먹고 1부터 다시 시작하는 대신, "네트워크가 아직 살아있으니 조금만 속도를 줄여서 계속 가자!"라고 판단하는 아주 효율적인 방식이다.
- 동작 과정
- [1단계] 사고 발생: "3번 패킷이 사라졌다!"
- 상황: 32KB 속도로 신나게 보내던 중 3번 패킷이 유실되었다.
- 신호: 수신자가 "3번 없어!"라고 외치는 중복 ACK를 3개 보낸다.
- 의미: "3번은 잃어버렸지만, 그 뒤에 보낸 4, 5, 6번 패킷은 무사히 나한테 도착했어!"라는 뜻이다.
- [2단계] 풍선 불기 (Window Inflaction): "나간 만큼 더 보내자"
- 계산:
Threshold = 16KB,CWND = 16 + 3 = 19KB - 이유: 중복 ACK가 3개 왔다는 건, 패킷 3개가 네트워크를 빠져나가 수신자 창고에 들어갔다는 증거이다.
"네트워크에 3개만큼 빈자리가 생겼으니, 윈도우를 3만큼 더 키워서(부풀려서) 데이터를 더 보내도 되겠네?"라고 판단하는 것이다.
- 계산:
- [3단계] 계속 부풀리기: "추가 응답마다 +1"
- 상황: 4번째, 5번째 중복 ACK가 계속 온다.
- 동작: CWND를 20, 21... 이렇게 1씩 계속 늘린다.
- 이유: 중복 ACK가 올 때마다 패킷이 하나씩 더 수신자에게 도착했다는 뜻이므로, 그 빈자리를 채우기 위해 윈도우를 계속 부풀리는 것이다.
- [4단계] 바람 빼기 (Deflation): "이제 정상으로!"
- 상황: 드디어 재전송했던 3번 패킷에 대한 '새로운 ACK'가 도착한다.
- 동작: 부풀렸던 윈도우에서 바람을 팍 빼서
CWND = 16KB(Threshold)로 맞춘다. - 이유: 이제 유실된 구멍을 메웠으니, 임시로 부풀렸던 윈도우를 정상화하고 1씩 조심스럽게 늘리는 단계(혼잡 회피)로 돌아가는 것이다.
- [1단계] 사고 발생: "3번 패킷이 사라졌다!"
- 공식:
CWND = Threshold + 3MSS- 의미: 중복 ACK가 3개 왔다는 건, 내가 보낸 패킷 중 3개가 이미 네트워크를 빠져나가 수신자에게 도착했다는 확실한 증거이다.
- 논리: "네트워크에서 패킷 3개가 빠져나갔으니, 그만큼의 공간이 생겼네? 그럼 그만큼은 더 보내도 안전하겠지?"라고 판단하여 윈도우를 임시로 부풀리는(Inflation) 것이다.
- 중복 ACK가 오면 CWND를 1씩 계속 늘리는 이유
- 동작: 4번째, 5번째 중복 ACK가 올 때마다
CWND += 1을 해준다. - 이유: 중복 ACK가 올 때마다 "아, 또 패킷 하나가 수신자에게 무사히 도착했구나!"라고 판단하기 떄문이다.
네트워크에 떠 있는 패킷 수를 일정하게 유지하기 위한 전략이다.
- 동작: 4번째, 5번째 중복 ACK가 올 때마다
- 새로운 ACK가 오면 CWND를 다시 Threshold로 줄이는 이유 (Deflation)
- 상황: 드디어 재전송했던 패킷에 대한 '새로운 ACK'가 도착했다.
- 조치: 부풀려졌던 윈도우를 다시
Threshold(16KB)로 팍 줄인다. - 이유: 이제 유실됐던 구멍이 메워졌으니, 임시로 부풀렸던 윈도우를 정상화하고 혼잡 회피(Congestion Avoidance) 단계로 넘어가서 1씩 조심스럽게 늘리기 위해서이다.
(5) CUBIC: 현대 OS의 대표 혼잡제어
CUBIC은 우리가 지금 쓰고 있는 리눅스, 윈도우, 안드로이드 등 대부분의 OS가 기본으로 채택하고 있는 아주 강력한 알고리즘이다.
기존의 AIMD(Reno)가 '조심스러운 거북이'였다면, CUBIC은 '길을 기억하는 영리한 치타'라고 비유할 수 있다.
- 왜 CUBIC(3차 함수)일까?
기존 방식(Reno)은 윈도우를 1, 2, 3, 4... 처럼 직선(선형)으로 늘렸다. 하지만 요즘처럼 대역폭이 엄청나게 넓은 광랜 환경에서는 이렇게 1씩 늘려서는 대역폭을 다 쓰는 데 한 세월이 걸린다.
CUBIC은 3차 함수(y=x³) 곡선을 그리며 윈도우를 조절한다.- 초반: 혼잡 지점에서 멀 때는 확 늘린다.
- 중반: 예전에 혼잡이 발생했던 지점에 가까워지면 조심스럽게(평평하게) 속도를 유지하며 간을 본다.
- 후반: "오? 예전 혼잡 지점을 넘었는데도 괜찮네?" 싶으면 다시 폭발적으로 늘려 새로운 한계를 찾아 나선다.
-
ACK 기반이 아닌 '시간' 기반
기존 방식은 ACK가 올 때마다 윈도우를 키웠지만, CUBIC은 마지막 혼잡 발생 이후 흐른 시간을 기준으로 계산한다.
덕분에 RTT(왕복 시간)가 긴 장거리 통신에서도 훨씬 안정적이고 빠르게 속도를 올릴 수 있다. -
CUBIC의 3단계 가속 시나리오
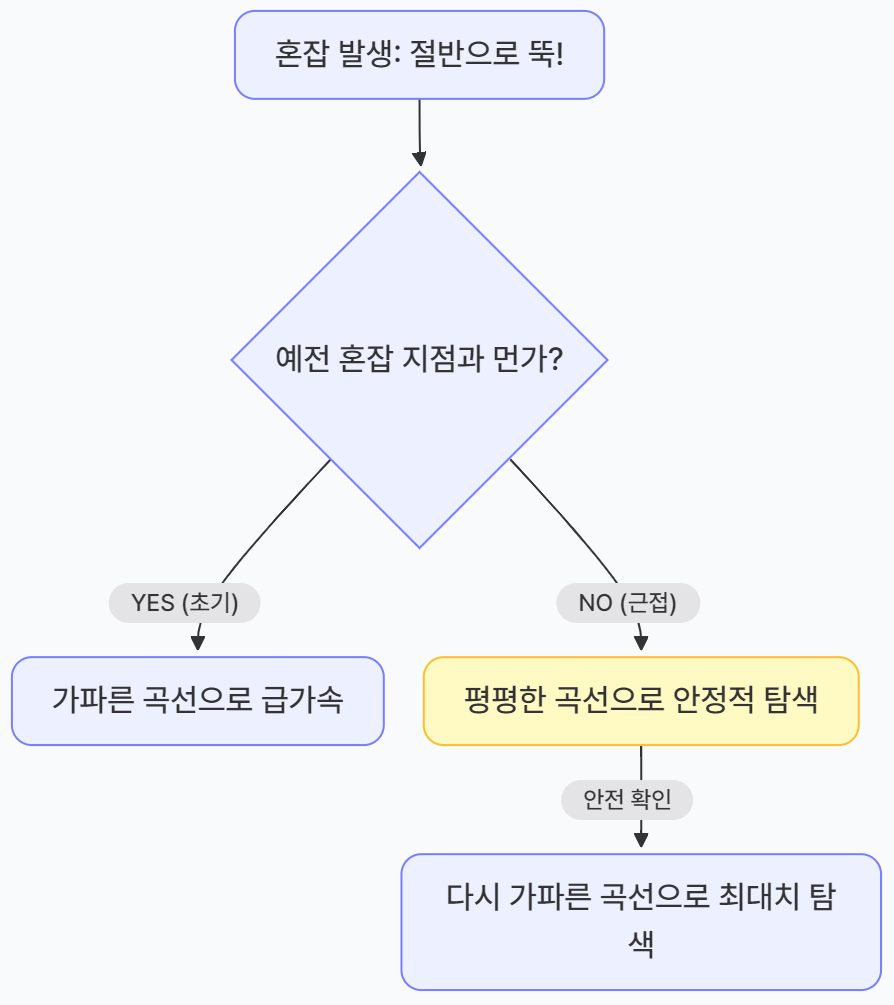
- 급가속 구간: 사고 지점의 절반까지는 아주 빠르게 회복한다.
- 안정 구간 (Plateau): 예전에 사고 났던 속도 근처에서는 아주 미세하게만 조절하며 네트워크를 안정시킨다.
- 최대치 탐색 구간: 네트워크 환경이 좋아졌을 가능성을 염두에 두고 다시 속도를 확 올려본다.
6. TCP 진화 과정
(1) TCP Tahoe (1988)
- 특징: 아주 보수적이고 겁이 많다.
- 대처: 타임아웃이 나든, 중복 ACK가 3개 오든 "사고다!" 싶으면 무조건 차를 세우고 출발선(CWND=1)으로 돌아간다.
- 단점: 다시 속도를 올리는 데 시간이 너무 오래 걸려서 답답하다.
(2) TCP Reno (1990)
- 특징: 사고의 경중을 따질 줄 알게 되었다.
- 대처
- 타임아웃(심각): 이때는 Tahoe처럼 출발선(CWND=1)으로 돌아간다.
- 중복 ACK 3개(경미): "어? 뒤차들은 잘 오네? 굳이 멈출 필요 없지!"하고 속도를 반으로만 줄이고 계속 달린다(Fast Recovery).
- 혁신: 현대 TCP의 표준이 된 아주 중요한 버전이다.
(3) TCP NewReno (개선)
- 특징: Reno의 약점을 보완했다.
- 대처: Reno는 한 번에 패킷이 여러 개 유실되면 당황해서 다시 출발선으로 돌아가곤 했는데, NewReno는 여러 개가 유실되어도 끝까지 평정심을 유지하며 하나씩 다 고칠 때까지 빠른 회복 상태를 유지한다.
✨ 한눈에 비교하는 버전별 차이
| 구분 | TCP Tahoe (1988) | TCP Reno (1990) | TCP NewReno (개선) |
|---|---|---|---|
| 3개 중복 ACK 시 | CWND=1 (Slow Start) | CWND=절반 (Fast Recovery) | Reno와 동일 (더 정교함) |
| 타임아웃 시 | CWND=1 | CWND=1 | CWND=1 |
| 핵심 철학 | "안전이 최고, 무조건 리셋" | "갈 수 있으면 계속 가자" | "복합 사고도 침착하게 해결" |
7. 흐름 제어 vs. 혼잡 제어
✨ 흐름 제어: "너 입 안 아파?"
- 대상: 송신자와 수신자 (1:1 관계)
- 목적: 수신자의 버퍼가 넘치는 것(Overflow)을 방지한다.
- 핵심 지표: RWND (Receive Window) ➡️ 수신자가 "나 지금 이만큼 빈 공간 있어"라고 알려주는 값이다.
- 상황: 송신자는 100Mbps로 쏠 수 있고 네트워크도 뻥 뚫려 있지만, 수신자의 컴퓨터가 느려서 10Mbps밖에 처리 못 한다면? 송신자는 수신자의 속도에 맞춰 10Mbps로 줄여서 보내야 한다.
✨ 혼잡 제어: "길이 너무 막혀!"
- 대상: 송신자와 네트워크 (라우터 등 중간 경로 포함)
- 목적: 네트워크의 라우터들이 감당 못 할 정도로 패킷이 몰리는 것을 방지한다.
- 핵심 지표: CWND (Congestion Window) ➡️ 송신자가 네트워크 상황을 살피며 스스로 조절하는 윈도우 크기이다.
- 상황: 송신자도 빠르고 수신자도 준비됐지만, 중간에 거치는 라우터들이 이미 다른 데이터들로 꽉 차 있다면? 패킷이 유실될 수 있으므로 송신자는 네트워크가 소화할 수 있을 때까지 전송 속도를 강제로 줄인다.
✨ 비교 분석 표
| 구분 | 흐름 제어 (Flow Control) | 혼잡 제어 (Congestion Control) |
|---|---|---|
| 제어 주체 | 수신자 | 송신자 |
| 제어 범위 | 송신자 ↔️ 수신자 | 송신자 ↔️ 네트워크 ↔️ 수신자 |
| 보호 대상 | 수신자 | 네트워크 |
| 관점 | End-to-End (양 끝단 호스트) | Network-wide (호스트 + 라우터) |
| 원인 | 수신측의 처리 속도가 느림 | 네트워크 경로에 데이터가 너무 많음 |
| 제어 목적 | 수신자 버퍼 보호 | 네트워크 혼잡 방지 |
| 해결책 | 슬라이딩 윈도우 (RWMD) | AIMD, Slow Start 등 알고리즘 |
| 피드백 | 수신자가 명시적으로 알려줌 | 패킷 유실이나 지연을 보고 송신자가 판단 |
✨ 두 제어의 결합: 최종 전송량 결정
실제로 송신자가 데이터를 얼마나 보낼지 결정할 때는 이 두 가지를 모두 고려한다.
즉, (최종 윈도우 크기) = min(RWND, CWND)가 된다.
수신자가 아무리 많이 받을 수 있어도(RWND가 커도) 네트워크가 막히면(CWND가 작으면) 조금만 보내야 하고, 반대로 네트워크가 뻥 뚫려 있어도 수신자가 바쁘면 조금만 보내야 하는 것이다.
