
최장 공통 문자열 vs 최장 공통 부분수열
- 최장 공통 문자열: 한번에 이어져 있는 문자열만 가능
- 최장 공통 부분수열: 문자 사이를 건너뛰어 공통되면서 가장 긴 부분 문자열 찾기
- ex) ABCDEF / GBCDFE
최장 공통 문자열: BCD
최장 공통 부분수열: BCDE, BCDF
최장 공통 문자열
: Longest Common Substring (LCS)
점화식
# 마진 설정
if i == 0 or j == 0:
LCS[i][j] = 0
elif string_A[i] == string_B[j]:
LCS[i][j] = LCS[i - 1][j - 1] + 1
else:
LCS[i][j] = 0LCS는 2차원 배열을 이용하여 두 문자열을 행과 열로 매칭
i or j 가 0일 때는 모두 0을 넣어줘 마진 값을 설정
i or j 가 1이상일 때부터 검사를 시작
- 문자열A, 문자열B의 한글자씩 비교
- 두 문자가 다르다면
LCS[i][j]에 0을 표시합니다. - 두 문자가 같다면
LCS[i - 1][j - 1]값을 찾아 +1 합니다. - 위 과정을 반복합니다.
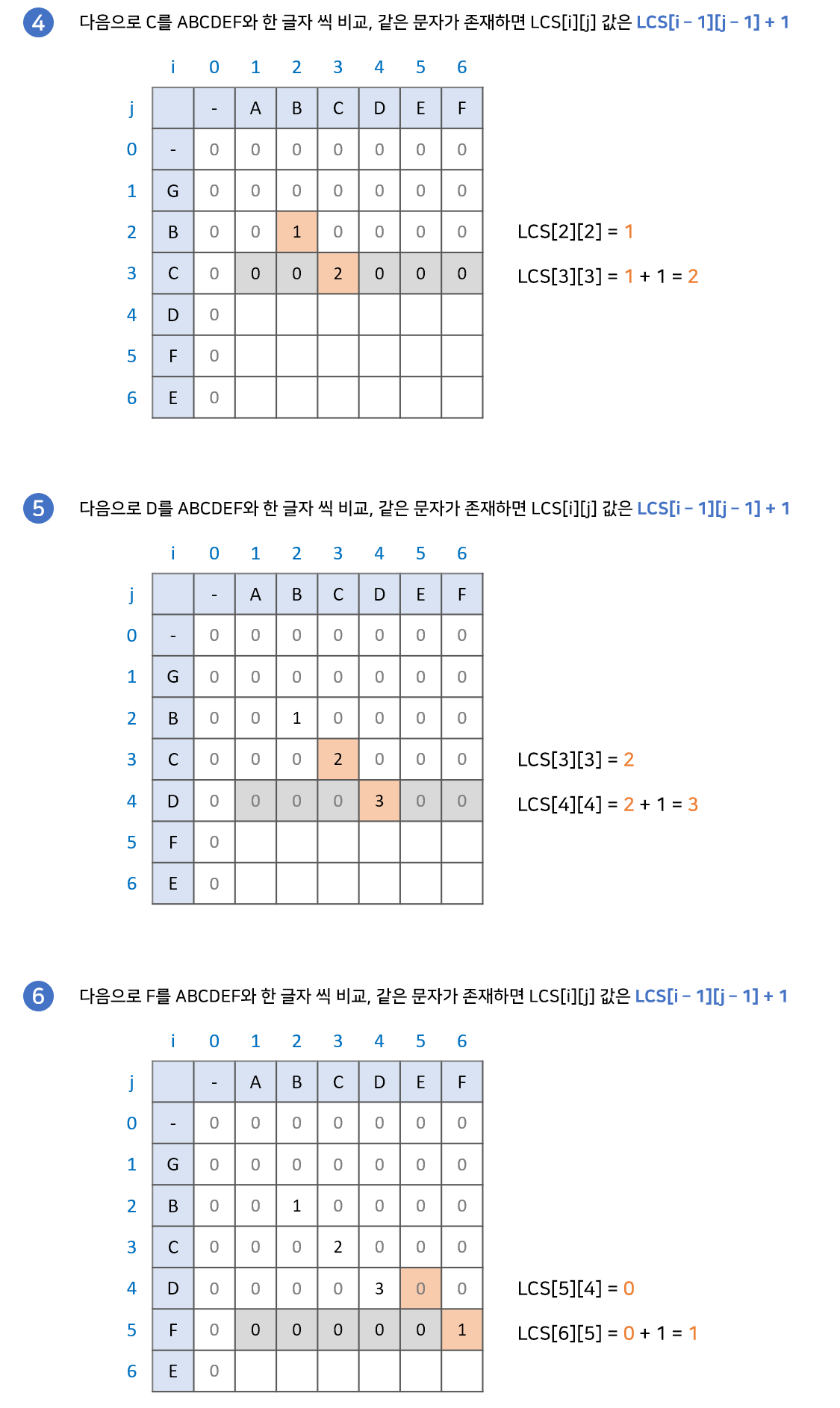
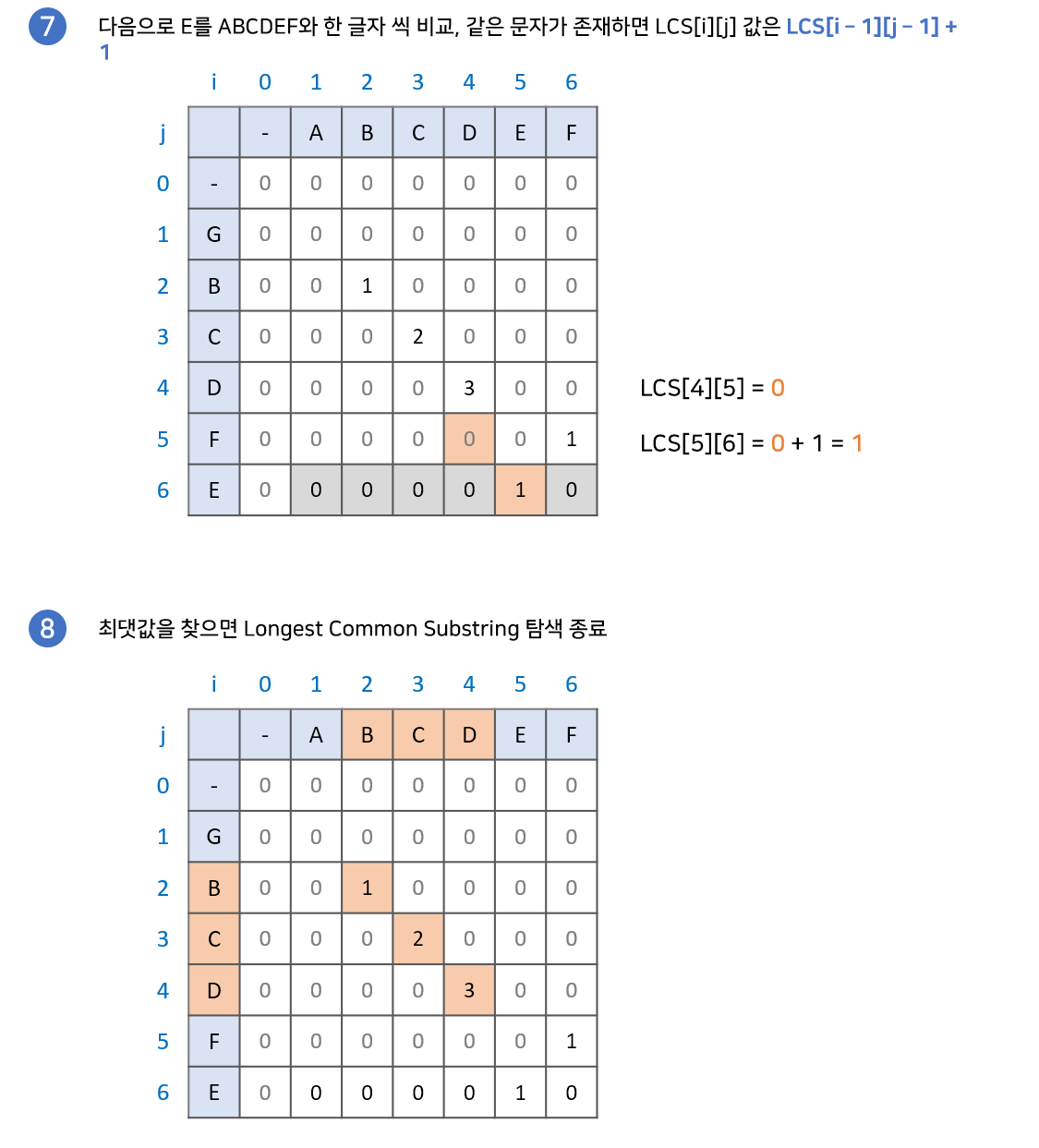
현재 두 문자가 같을 때 두 문자의 앞글자까지가 공통 문자열이라면 계속 공통 문자열이 이어질 것이고, 아니라면 다시 공통 문자열을 만들어 가게 될 것
구현 과정 (출처: emplam27.log)

최장 공통 부분수열
: Longest Common Subsequence (LCS)
최장 공통 부분수열의 길이 구하기
점화식
if i == 0 or j == 0: # 마진 설정
LCS[i][j] = 0
elif string_A[i] == string_B[j]:
LCS[i][j] = LCS[i - 1][j - 1] + 1
else:
LCS[i][j] = max(LCS[i - 1][j], LCS[i][j - 1])LCS는 2차원 배열을 이용하여 두 문자열을 행과 열로 매칭
i or j 가 0일 때는 모두 0을 넣어줘 마진 값을 설정
i or j 가 1이상일 때부터 검사를 시작
- 문자열A, 문자열B의 한글자씩 비교
- 두 문자가 다르다면 LCS[i - 1][j]와 LCS[i][j - 1] 중에 큰값을 표시합니다.
- 두 문자가 같다면 LCS[i - 1][j - 1] 값을 찾아 +1 합니다.
- 위 과정을 반복합니다.
최장 공통 문자열을 구하는 과정과 다른부분은 비교하는 두 문자가 다를 때 입니다. 비교하는 두 문자가 같을 때는 같은 과정을 보여줍니다.
이해하고 넘어갈 것
LCS[i - 1][j]와 LCS[i][j - 1]
- 부분수열은 연속된 값이 아니다.
- 현재의 문자를 비교하는 과정 이전의 최대 공통 부분수열은 계속해서 유지됨
- 현재의 문자를 비교하는 과정 이전의 과정 =
LCS[i - 1][j]와 LCS[i][j - 1]
LCS[i][j] = LCS[i - 1][j - 1] + 1
- 지금까지의 최대 공통 부분수열에 1을 더해주는 것
최장 공통 부분수열 찾기
- LCS 배열의 가장 마지막 값에서 시작합니다. 결과값을 저장할 result 배열을 준비합니다.
- LCS[i - 1][j]와 LCS[i][j - 1] 중 현재 값과 같은 값을 찾습니다.
2-1. 만약 같은 값이 있다면 해당 값으로 이동합니다.
2-2. 만약 같은 값이 없다면 result배열에 해당 문자를 넣고 LCS[i -1][j - 1]로 이동합니다. - 2번 과정을 반복하다가 0으로 이동하게 되면 종료합니다. result 배열의 역순이 LCS 입니다.

공부한 내용을 기록하는 공간입니다. 📝