21. 가상 메모리 개념 이해>
단골 cs지식 문항에 대해 구체적으로 이해하고
이해한 부분을 말로 설명할 수 있도록 하자
★★기술면접 단골 문제
1. 가상 메모리와 페이징 시스템에 대해 구체적 설명
2. 요구 페이징과 페이지 폴트에 대한 구체적 설명
3. MMU와 TLB에 대한 구체적 설명
가상메모리(Virtual Memory system)
실제 각 프로세스마다 충분한 메모리를 할당하기엔 메모리 크기에 한계가 있음.
메모리를 늘리면 성능이 좋아진다?
폰노이만 구조 기반이므로 코드는 메모리에 반드시 있어야함.
폰노이만 구조에서 메모리에 프로그램과 데이터 저장+
하나씩 꺼내서 cpu: Arithmetic Logic Unit으로 연산
가상 메모리 필요한 이유
- 하나의 프로세스만 실행 가능한 시스템(배치 처리 시스템 등)
프로그램을 메모리로 로드
프로세스 실행
프로세스 종료(메모리 해제) - 여러 프로세스 동시 실행 시스템
메모리 용량 부족 이슈
프로세스 메모리 영역간에 침범 이슈
가상메모리란?
메모리가 실제 메모리보다 많아 보이게 하는 기술
실제 사용하는 메모리가 작다는 점을 착안된 기술
프로세스간 공간 불리로, 프로세스 이슈가 전체 시스템에 영향을 주진 않을수있음
★메인 메모리에 실제 각 프로세스의 데이터가 조각으로 씌여 있음
지금 cpu가 필요한 데이터만 가상 메모리 해놓고 물리 메모리 안에 껴넣는데,
그 가상메모리를 MMU가 잘 찾아준다.
즉, cpu는 가상 메모리를 다루고 실제 해당 주소 접근시 mmu하드웨어 장치를 통해
물리 메모리 접근. 하드웨어 장치를 이용해야 주소 변환이 빠르기 때문에 별도 장치를 둠.
가상메모리를 모두 메모리에 올릴 필요가 없다.

가상메모리 기본 아이디어
- 프로세스는 가상 주소를 사용(cpu는 가상 주소로만 의사소통),
실제 해당 주소에서 데이터를 읽고 쓸때만 물리 주소로 바꿔주면 됨. - virtual address (가상주소): 프로세스가 참조하는 주소
- physical address (물리 주소): 실제 메모리 주소
MMU(Memory Management Unit)
- 가상주소 + 물리주소를 맵핑.별도의 하드웨어 칩.
- CPU에 코드 실행시, 가상 주소 메모리 접근이 필요할 때, 해당 주소를 물리 주소값으로 변환해주는 하드웨어 장치.
22. ★★페이징 시스템 개념 이해>
페이징(paging) 개념
- ★'크기가 동일한' 페이지로 가상 주소 공간과 이에 매칭하는 물리 주소 공간을 관리
- 하드웨어 지원이 필요
- 리눅스에서는 4kb로 paging
- 페이지 번호를 기반으로 가상 주소/물리 주소 매핑 정보를 기록/사용
cpu는 가상주소를 요청.가상주소+물리주소 변위값 더해서? 물리메모리에 값이 나옴
그 값의 주소를 알수 있다는 내용.
페이징 시스템 구조
- page 또는 page frame:고정된 크기의 block(4kb)
- 페이징 시스템.
가상주소 v=(p, d) p는 가상메모리 페이지. d는 p안에서 참조하는 위치

- 페이지 크기가 4kb 예
가상 주소의 O비트에서 11비트가 변위(d)를 나타내고
12비트 이상이 페이지 번호가 될 수 있다.
모든 것은 결국 bit와 연결되 있음.
(본래 프로세스가 4GB를 사용했던 이유 - 32bit 시스템에서 2의 32승이 4GB)
페이지 테이블
- 물리 주소에 있는 페이지 번호와 해당 페이지의 첫 물리 주소 정보를 매핑한 표
- 가상주소 v=(p, d) 라면 p는 페이지번호. d는 페이지 처음부터 얼마 떨어진 위치인지.
- 페이징 시스템 동작
해당 프로세스에서 특정 가상 주소 엑세스를 하려면
해당 프로세스의 페이지 테이블에 해당 가상 주소가 포함된 페이지 번호가 있는지 확인
페이지 번호가 있으면 이 페이지가 매핑된 첫 물리 주소를 알아내고(p) p+ d가 실제 물리 주소가 된다.
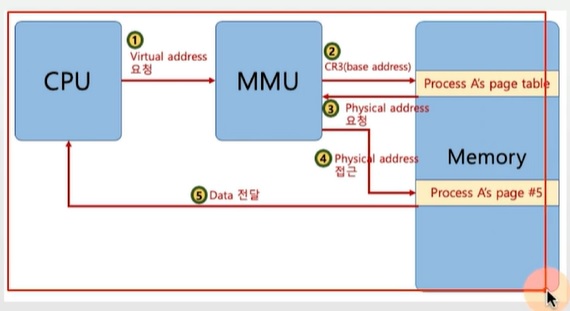
페이징 시스템과 mmu(컴퓨터 구조)
- cpu는 가상 주소 접근시, mmu 하드웨어 장치를 통해 물리 메모리 접근
- 프로세스 생성시, 페이지 테이블 정보 생성
pcb등에서 해당 페이지 테이블 접근 가능하고, 괄련 정보는 물리 메모리에 적재
프로세스 구동시, 해당 페이지 테이블 base주소가 별도 레지스터에 저장(CR3)
cpu가 가상 주소 접근시, mmu가 페이지 테이블 base 주소를 접근해서, 물리 주소를 가져옴
ㅈㄹ 어렵다 ㅋㅋㅋㅋㅋㅋㅋㅋ.20분부터 마무리 설명 보면됨...
23. 가상 메모리를 위한 TLB 이해>
참고)다중 단계 페이징 시스템: 페이지 번호를 나태내는 bit를 구분해서, 단계를 나눔
리눅스는 3단계, 최근 4단계
mmu와 TLB(컴구조) : mmu가 물리 주소를 확인 하기 위해 메모리를 갔다 와야함;
메모리 계층 구조상, 메모리 접근이 cpu 측면에서는 상당한 시간이 걸림(200사이클)
페이징 시스템과 공유 메모리(IPC)
프로세스간 동일한 물리 주소를 가리킬 수 있음(공간 절약, 메모리 할당 시간 절약)
프로세스는 독단적으로 생산되는게 아님.
기존의 부모 프로세스를 기반+여기에 새로 필요한 정보를 덮어씌우는 형태=프로세스 생산.
fork를 통해 새로운 프로세스 만듬.. 동일한 커널 가리키고 있어서 새로 업데이트할 필요x
페이징 시스템 새로 생성할 필요x (기존 프로세스를 쓸수 있어서..)
24. 요구 페이징 (Demand paging 또는 Demanded paging) 개념 이해>
프로세스 모든 데이터를 메모리로 적재하지 않고 실행 중 필요한 시점에서만 메모리로 적재함
- 선행 페이징(anticipatory paging 또는 prepaging)의 반대 개념: 미리 프로세스 관련 모든 데이터를 메모리에 올려놓고 실행하는 개념
- 더 이상 필요하지 않은 페이지 프레임은 다시 저장매체에 저장(페이지 교체 알고리즘 필요)
페이지 폴트(page fault)
- 어떤 페이지가 실제 물리 메모리에 없을때 일어나는 인터럽트(없을때 신호 보내줌)
- cpu가 mmu에 요청→TLB가서 똑같이 등록→ 메모리에 해당 주소 없음을 확인→운영체제에 신호를 보냄→운영체제가 page fault가 일어나면, 해당 페이지를 저장매체에서 찾아서 물리 메모리에 올림→페이징 테이블에 업데이트→
그 이후 다시돌아가서, cpu가 mmu에 요청→TLB가서 똑같이 등록→ 메모리에 해당 주소 있음을 확인
인터럽트
타이머 인터럽트를 가장 많이 씀. 시간 측정. 시간마다 동작.
(사용자 모드: 프로세스)
(커널 모드: 시스템 콜, 핸들러 / 프로세스 scheduler)
인터럽트와 IDT
인터럽트는 종류가 미리 정의되어 각각 번호로 구분.
번호에 따라 인터럽트를 지원하면 해당 운영체제의 코드가 실행할수 있도록,
실행 코드를 가리키는 주소(일종의 테이블)가 기록되어 있음
어디에? IDT(interrupt descriptor table)에 기록
언제? 컴퓨터 부팅시 운영체제가 기록
어떤 코드? 운영체제 내부 코드!
다시 예를 보면, 항상 인터럽트 발생시 IDT를 확인.
시스템콜 인터럽트 명령은 0X80 번호가 미리 정의
인터럽트 0x80에 해당하는 운영체제 코드는 system_call() 이라는 함수
즉, IDT에는 0x80 → system_call()와 같은 정보가 기록되어 있음
25. 페이지 교체 정책 정리>
페이지 폴트가 자주 일어나면?
실행되기 전에 해당 페이지를 물리 메모리에 올려야함(시간 오래걸림)
페이지 폴트가 안일어나게 하려면?
향후 실행/ 참조될 코드 / 데이터를 미리 물리 메모리에 올리면 됨
앞으로 있을 일을 예측 해야 함(신의 영역- -;;)
페이지 교체 정책(page replacement policy)
운영체제가 특정 페이지를 물리 메모리에 올리려는데, 물리 메모리가 다 찼으면?
기존 페이지 중 하나를 물리 메모리에서 저장매체로 내리고(저장)
새로운 페이지를 해당 물리 메모리 공간에 올린다.
어떤 페이지를 물리 메모리에서, 저장매체로 내릴 것인가? 페이지 교체 정책.
페이지 교체 알고리즘(FIFO)
FIFO Page Replacement Algorithm : 가장 먼저 들어온 페이지를 내리자
페이지 교체 알고리즘(OPT)
최적 페이지 교체 알고리즘(OPTimal Replacement Algorithm)
앞으로 가장 오랫동안 사용하지 않을 페이지를 내림. 일반 OS에서는 구현 불가;;
페이지 교체 알고리즘(LRU)
(Least Recently Used) Page Replacement Algorithm가장 오래전에 사용된 페이지를 교체(OPT대체)
OPT교체 알고리즘이 구현이 불가하므로, 과거 기록을 기반으로 시도
메모리 지역성을 기반으로 오래전 사용된 페이지 찾음.
페이지 스왑 알고리즘(LFU)
(Least Frequently Used) Page Replacement Algorithm
가정 적게 사용된 페이지를 내림
페이지 스왑 알고리즘(NUR)
(Not Used Recently) Page Replacement Algorithm
LRU와 마찬가지로 최근에 사용하지 않은 페이지부터 교체하는 기법
각 페이지마다 참조 비트(R), 수정 비트(M)을 둔다. (R, M)
(0, 0) , (0, 1), (1, 0), (1, 1) 순으로 페이지 교체
이러한 알고리즘을 다 알필요는 없지만 이상적인 알고리즘이 있다는 것만 알자..
스레싱(Thrashing) :
반복적으로 페이지 폴트가 발생해서 과도하게 페이지 교체 작업이 일어나,
실제로는 아무 일도 하지 못하는 상황
→메모리를 늘려줘야 함,페이지를 조금 띄워서 사용하거나..

26. 파일 시스템 개념 이해>
단골 CS지식 문제/엄청 많이 언급 되진 않지만 1번은 알아둘 필요있다.
★1. inode 파일 시스템 방식에 대해 간단히 설명
2. 가상 머신에 대해 간단히 설명
3. 외부 단편화에 대해 간단히 설명
파일 시스템 : 운영체제가 저장매체에 파일을 쓰기 위한 자료구조 또는 알고리즘
<가볍게 알아두기>파일 시스템이 만들어지는 이유(블록)
0과 1의 데이터를 어떻게 저장매체에 저장할까?
- 비트로 관리하기는 오버헤드가 너무 큼
- 블록 단위로 관리하기로 함(보통 4KB)
- 블록마다 고유 번호를 부여해서, 관리
<가볍게 알아두기>파일 시스템이 만들어지는 이유(파일)
사용자가 각 블록 고유 번호를 관리하기 어려움
- 추상적(논리적) 객체 필요: 파일
사용자는 파일 단위로 관리 - 각 파일에는 블록 단위로 관리
<가볍게 알아두기> 파일 시스템이 만들어지는 이유(저장방법)
저장매체에 효율적으로 파일을 저장하는 방법
- 가능한 연속적인 공간에 파일을 저장하는 게 좋다
- 외부 단편화 파일ㅇ 사이즈 변경 문제로 불연속 공간에 파일저장 기능 지원 필요
블록 체인: 블록을 링크드 리스트로 연결
끝에 있는 불록을 찾으려면, 맨처음 블록부터 주소를 따라가야 함
★인덱스 블록 기법 : 각 블록에 대한 위치 정보를 기록해서 한번에 끝 블록을 찾아가게 함.
ㄴ리눅스 계열이 일종의 인덱스 블록 기법인 ★inode방식 사용
외부 단편화와 링크드 리스트 자료 구조
파일 시스템과 파일 관련 함수 및 시스템 콜
- 동일한 시스템콜을 사용해서 다양한 파일 시스템 지원 가능토록 구현.
- 읽고/쓰고 시스템 콜 호출시, 각 기긱 및 파일 시스템에 따라 실질 적인 처리를 담당하는 함수를 호출하는 방식으로 내부 구현됨
- 운영체제가 제공하는 시스템 콜을 기반으로, 각 언어에서 해당 시스템 콜을 호출하도록 라이브러리 등을 제공.

제로베이스 프론트엔드 스쿨 입니다 !
과정 시작한지 1달이 다 되어가는데요.
공부하시면서 블로그 작성까지 하는 것이 쉽지
않으실텐데 정말 대단하신 것 같아요 !
취업 준비하실 때 많은 도움이 되실테니
힘드시더라도 끝까지
꾸준히 작성하시면 좋을 것 같습니다.
오늘도 화이팅 하세요:)