
카프카 스트림즈
카프카 스트림즈는 토픽에 적재된 데이터를 실시간으로 변환하여 다른 토픽에 적재하는 라이브러리
- 카프카의 스트림 데이터 처리를 위해 아파치 스파크, 아파치 플링크, 아차피 스톰, 플루언트디 같은 다양한 오픈소스 애플리케이션이 존재하지만, 카프카 스트림즈를 사용해야 하는 이유는 무엇일까?
- 스트림즈는 카프카에서 공식적으로 지원하는 라이브러리이다.
- 카프카 버전이 업데이트될 때마다 스트림즈 자바 라이브러리도 같이 릴리즈된다.
- 따라서 자바 기반 스트림즈 애플리케이션은 카프카 클러스터와 완벽하게 호환되면서 스트림 처리에 필요한 편리한 기능들을 제공한다.
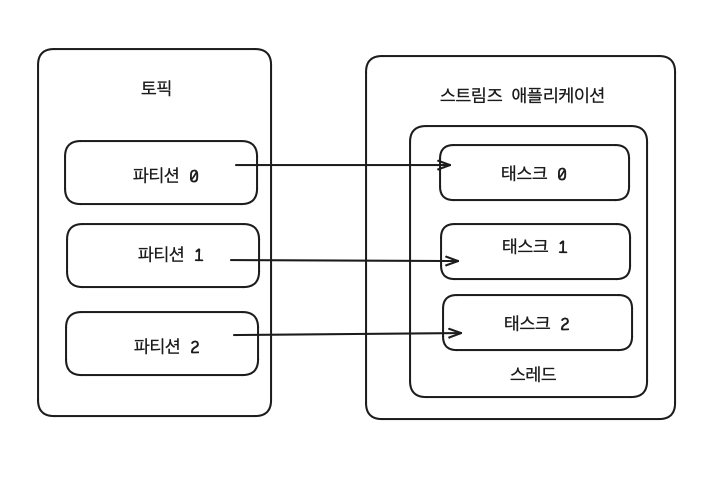
- 스트림즈 애플리케이션은 내부적으로 스레드를 1개 이상 생성할 수 있으며, 스레드는 1개 이상의 태스크를 가진다.
- ‘태스크(task)’는 스트림즈 애플리케이션을 실행하면 생기는 데이터 처리 최소 단위이다.
- 만약 3개의 파티션으로 이루어진 토픽을 처리하는 스트림즈 애플리케이션을 실행하면
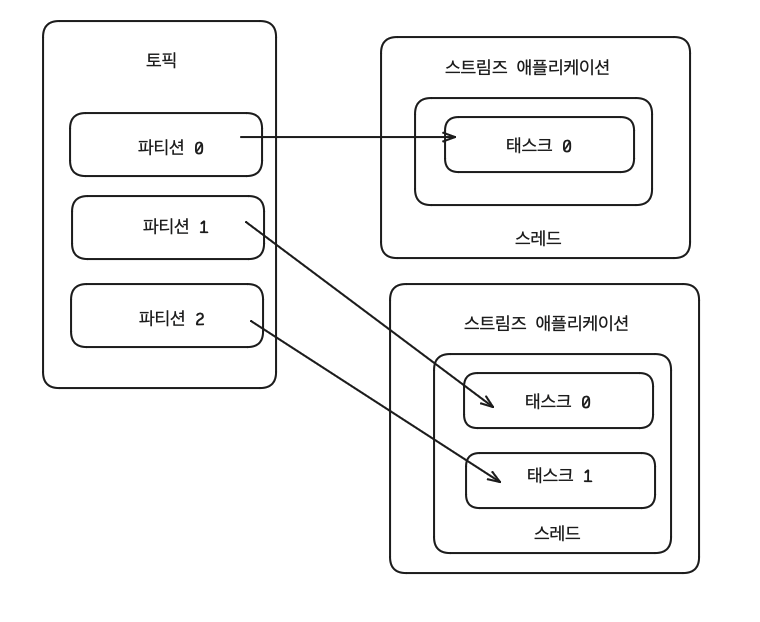
내부적으로 3개의 태스크가 생성된다. - 카프카 스트림즈는 컨슈머 스레드를 늘리는 방법과 동일하게 병렬처리를 위해 파티션과 스트림즈 스레드 개수를 늘림으로써 처리량을 늘릴 수 있다.
- 안정적인 운영을 위해 2개 이상의 서버로 구성하여 스트림즈 애플리케이션을 운영한다.
- 토폴로지(topology)
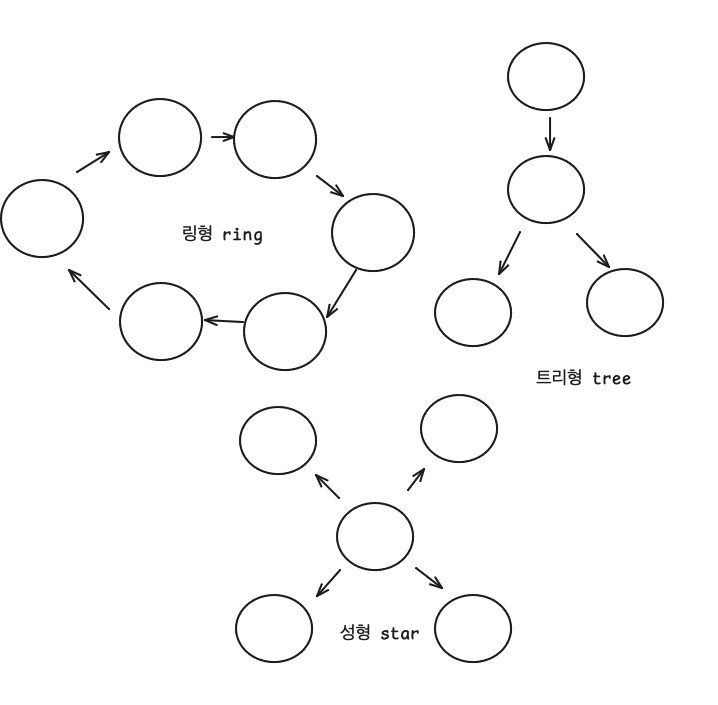
- 토폴로지란 2개 이상의 노드들과 선으로 이루어진 집합이다.
- 종류로는 링형(ring), 트리형(tree), 성형(star) 등이 있다.
- 스트림즈에서 사용하는 토폴로지는 트리(tree) 형태와 유사하다.
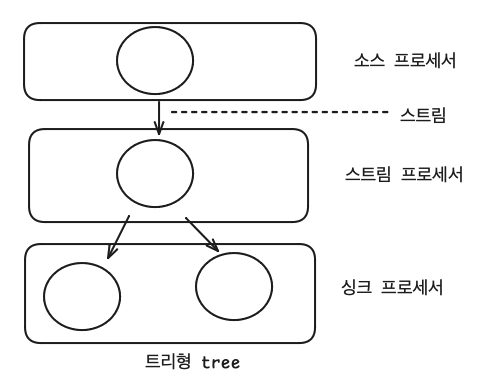
- 토폴로지를 이루는 노드를 프로세서(processor), 노드와 노드를 이은 선을 스트림(stream) 이라고 부른다.
- 스트림은 토픽의 데이터를 뜻하는데, 프로듀서와 컨슈머의 레코드와 동일하다.
- 프로세서 종류 (소스 프로세서, 스트림 프로세서, 싱크 프로세서)
- 소스 프로세서 : 데이터 처리하기 위해 최초로 선언해야 하는 노드, 하나 이상의 토픽에서 데이터를 가져오는 역할을 한다.
- 스트림 프로세서 : 다른 프로세서가 반환한 데이터를 처리하는 역할을 한다.
- 싱크 프로세서 : 데이터를 특정 카프카 토픽으로 저장하는 역할을 하며 스트림즈로 처리된 데이터의 최종 종착지이다.
- 스트림즈 DSL과 프로세서 API 2가지 방법으로 개발 가능하나, 여기서는 자세하게 다루지 않는다.
스트림즈 DSL
- 레코드의 흐름을 추상화한 3가지 개념 (KStream, KTable, GlobalKTable)
- 위 개념은 컨슈머, 프로듀서, 프로세서 API에서는 사용되지 않고 스트림즈DSL에서만 사용되는 개념이다.
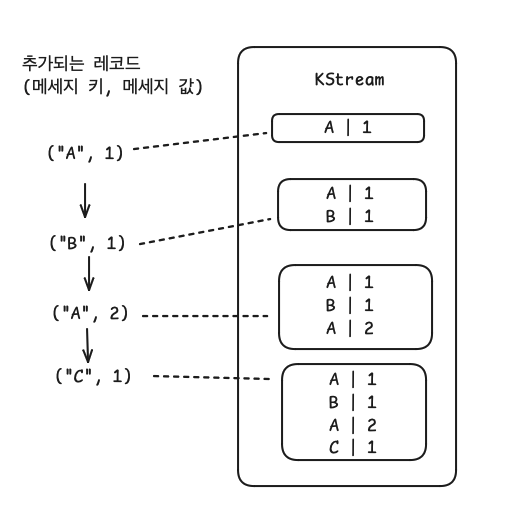
- KStream
- 레코드의 흐름을 표현한 것으로 메세지 키와 메세지 값으로 구성되어 있다.
- 데이터를 조회하면 토픽에 존재하는 모든 레코드가 출력된다.
- 컨슈머로 토픽을 구독하는 것과 동일하게 사용된다고 볼 수 있다.
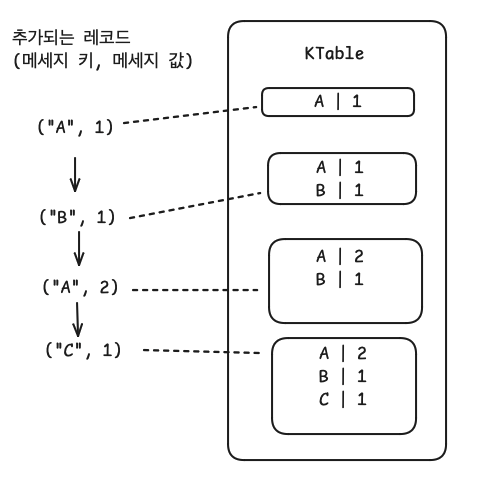
- KTable
- KStream과 다르게 메세지 키를 기준으로 묶어서 사용한다.
- KStream은 토픽의 모든 레코드를 조회할 수 있지만, KTable은 유니크한 메세지 키를 기준으로 가장 최신 레코드를 사용한다.
- 새로 데이터를 적재할 때 동일한 메세지 키가 있을 경우 데이터가 업데이트되었다고 볼 수 있다.
- GlobalKTable
- KTable과 동일하게 메세지 키를 기준으로 묶어서 사용한다.
- 그러나 KTable로 선언된 토픽은 1개 파티션이 1개 태스크에 할당되어 사용되고, GlobalKTable로 선언된 토픽은 모든 파티션 데이터가 각 태스크에 할당되어 사용된다.
- GlobalKTable을 설명하기 좋은 예시는 KStream과 KTable이 데이터 조인(join)을 수행할 때이다.
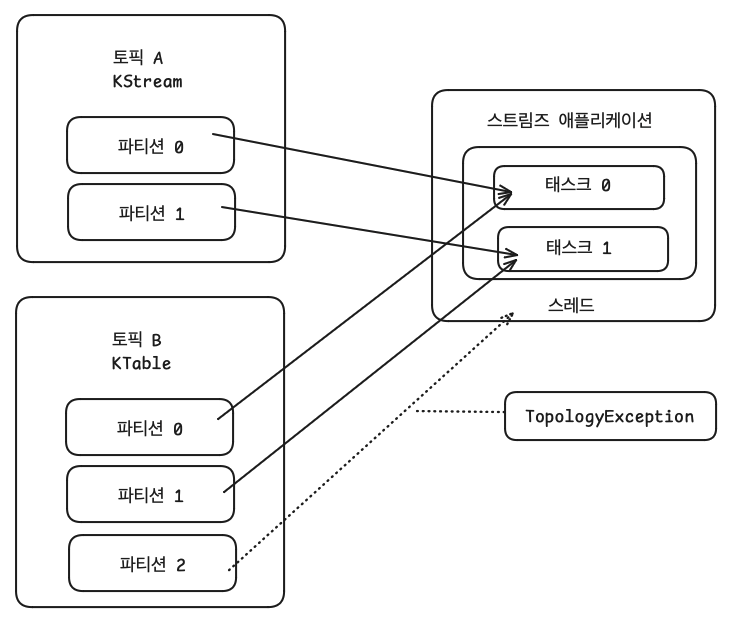
- KStream과 KTable을 조인하려면 반드시 코파티셔닝(co-partitioning)되어 있어야 한다.
- 코파티셔닝(co-partitioning)
- 조인을 하는 2개 데이터의 파티션 개수가 동일하고, 파티셔닝 전략을 동일하게 맞추는 작업이다.
- 파티션 개수가 동일하고, 파티셔닝 전략이 같은 경우에는 동일한 메세지 키를 가진 데이터가 동일한 태스크에 들어가는 것을 보장한다.
- 각 태스크는 KStream의 레코드와 KTable의 메시지 키가 동일할 경우 조인을 수행할 수 있다.
- 코파티셔닝 되어 있음을 보장할 수 없다.
- KStream과 KTable이 사용하는 토픽의 파티션 개수가 다른 경우
- 파티션 전략이 다른 경우
- 코파티셔닝이 되어있지 않다면, TopologyException 발생
- 리파티셔닝 repartitioning
- KStream과 KTable이 코파티셔닝되어 있지 않으면 이걸 맞춰주기 위해 리파티셔닝(repartitioning) 하는 과정을 거쳐야 한다.
- 기존 데이터를 중복해서 생성하고 파티션을 재배열하기 위해 프로세싱한다.
- 리파티셔닝을 하지 않고 조인을 하고 싶다면
- KTable → GlobalKTable로 선언하고 사용하면 된다.
- GlobalKTable로 정의된 데이터는 스트림즈 애플리케이션의 모든 태스크에 동일하게 공유되어 사용되기 때문에, KStream과 코파티셔닝이 되지 않더라도 조인이 가능하다.
- 하지만 스트림즈 애플리케이션의 로컬 스토리지가 증가하고, 네트워크와 브로커에 부하가 생기므로, 많은 양의 데이터를 가진 토픽으로 조인할 경우 리파티셔닝을 통해 KTable을 사용하는 것이 좋다.
- 필수 옵션
- bootstrap.servers: 프로듀서가 데이터를 전송할 대상 카프카 클러스터에 속한 브로커 이름
- application.id: 스트림즈 애플리케이션을 구분하기 위한 고유한 아이디
프로세서 API
- 스트림즈DSL과 토폴로지를 기준으로 데이터를 처리한다는 관점에서 동일한 역할을 한다.
- 스트림즈DSL은 데이터 처리, 분기, 조인을 위한 다양한 메서드들을 제공하지만 추가적으로 상세 로직구현이 필요하다면 프로세서 API를 활용할 수 있다.
- KStream, KTable, GlobalKTable 개념이 없다.
- 자세한 구현은 나중에 살펴보겠다.
카프카 커넥트
카프카 커넥트(kafka connect)는 카프카 오픈소스에 포함된 툴 중 하나로, 데이터 파이프라인 생성 시 반복 작업을 줄이고, 효율적인 전송을 이루기 위한 애플리케이션이다.
- 파이프라인 생성 시 프로듀서, 컨슈머를 만드는 것은 좋은 방법이지만 반복적인 작업에 있어서 비효율적이다.
- 커넥트는 특정 작업 형태를 템플릿으로 만들어놓은 커넥터(connector)를 실행함으로써 반복 작업을 줄일 수 있다.
- 커넥터는 각 커넥터가 가진 고유한 설정값을 입력받아서 데이터를 처리한다.
- 커넥터는 크게 역할에 따라 2가지로 나뉜다. 소스 커넥터, 싱크 커넥터
- 오픈소스 커넥터는 직접 커넥터를 만들 필요가 없으며, 커넥터 jar파일을 다운로드하여 사용할 수 있다.
ex) AWS S3 커넥터, JDBC 커넥터…
소스 커넥터
- 프로듀서 역할을 하는 소스 커넥터(source connector)
- 데이터를 카프카 토픽으로 전송하는 프로듀서 역할을 한다.
싱크 커넥터
- 컨슈머 역할을 하는 싱크 커넥터(sink connector)
- 토픽 데이터를 저장하는 컨슈머 역할을 한다.
커넥터 실행 방법
- 단일 모드 커넥트 (standalone mode kafka connect)
- 1개 프로세스만 실행된다.
- 고가용성 x → 단일 장애점(SPOF: Single Point Of Failure)이 될 수 있다.
- 분산 모드 커넥트 (distributed mode kafka connect)
- 2대 이상의 서버에서 클러스터 형태로 운영한다.
- 장애 이슈 발생하더라도 운영이 가능하다.
- 데이터 처리량이 증가하면 무중단으로 스케일 아웃이 가능하다.
- REST API를 사용하면 현재 실행 중인 커넥터 상태, 종류 등등을 확인할 수 있다.

Backend-Developer