
아파치 카프카를 사용하는 이유
높은 처리량
많은 양의 데이터를 송수신할 때 네트워크 비용은 무시할 수 없는 규모가 된다.
카프카는 프로듀서 → 브로커, 브로커 → 컨슈머로 데이터를 송수신할 때 모두 묶어서 전송하기 때문에,
동일한 양의 데이터를 전송할 때 네트워크 통신 횟수를 최소한으로 한다.
또한 파티션 단위를 통해 동일 목적의 데이터를 여러 파티션에 분배하고 데이터를 병렬 처리할 수 있다.
이는 파티션 개수만큼 컨슈머 개수를 늘려 동일 시간당 데이터 처리량을 늘리는 것이다.
확장성
평균 1000건가량 들어오던 데이터가 갑자기 100만 건 이상 들어오는 경우도 있다.
(ex. 무신사 블랙프라이데이)
카프카는 가변적으로 확장이 가능한데, 데이터가 적을 때는 카프카 클러스터의 브로커를 최소한의 개수로
운영하다가 데이터가 많이지면 클러스터의 브로커 개수를 늘려 스케일 아웃할 수 있다.
스케일 아웃, 스케일 인 과정은 클러스터의 무중단 운영을 지원하여 안정적인 운영이 가능하다.
영속성
프로그램을 종료하더라도 데이터가 사라지지 않는 것을 뜻한다.
카프카는 데이터를 메모리에 저장하지 않고, 파일 시스템에 저장한다.
파일 시스템에 데이터를 저장하고 사용하는 것은 느리다고 알고 있지만, 카프카는 운영체제 레벨에서
파일 시스템을 최대한 활용하는 방법을 적용하였다.
운영체제에서 파일 I/O 성능 향상을 위해 페이지 캐시 영역을 메모리에 따로 생성하고 사용하기 때문에
카프카가 파일 시스템에 저장하고 데이터를 사용하더라도 처리량이 높은 것이다.
따라서 프로세스가 중단되더라도 데이터는 날라가지 않고, 안전하게 데이터를 다시 처리할 수 있다.
고가용성
3개 이상의 서버들로 운영되는 카프카 클러스터는 데이터의 복제를 통해 고가용성의 특징을 가지게 되었다.
프로듀서로 전송받은 데이터를 여러 브로커 중 1대의 브로커만 가지는 게 아니라, 또 다른 브로커에도 저장한다. 만약 하나의 브로커가 장애가 발생하더라도, 복제된 데이터가 다른 하나의 브로커에 있기 때문에 저장된
데이터 기준으로 지속적으로 데이터 처리가 가능하다.
카프카 클러스터를 3대 이상의 브로커들로 구성해야 하는 이유
1대로 운영할 경우 브로커의 장애는 서버의 장애로 이어진다.
2대로 운영할 경우 1대의 브로커에 장애가 발생해도, 다른 하나가 있기 때문에 데이터 처리에는 안정적이나,
브로커 간에 데이터가 복제되는 시간 차이로 인해 데이터의 일부가 유실될 수 있다.
이 때 min.insync.replicas 옵션을 2로 설정하면 최소 2개 이상의 브로커에 데이터가 완전히 복제됨을 보장할 수 있는데, 이 때 브로커가 3대 이상으로 운영되어야 한다.
이유는 옵션값보다 작은 수의 브로커가 존재할 때는 토픽에 더이상 데이터를 넣을 수 없기 때문이다.
따라서 3대 이상의 브로커를 운영해야 한다.
정리
이러한 장점들로 인해 대기업이나 은행 등에서 카프카를 많이들 운영한다.
하지만 데이터양이 적은 스타트업에서도 유용하게 사용할 수 있다.
빠른 성장속도와 확정성을 생각해보면, 타 대기업들보다 빠른 속도를 가진 스타트업에서 카프카를 사용하면
빠른 성장 속에서도 데이터 관련 작업을 안정적으로 확장할 수 있기 때문이다.
또한 카프카는 오픈소스 생태계 속에서 지속적으로 발전하고 있다는 장점이 있다.
카프카 기본 개념
브로커, 클러스터, 주키퍼
카프카 클라이언트와 데이터를 주고받기 위해 사용되는 주체이다.
하나의 서버에는 한 개의 카프카 브로커 프로세스가 실행된다.
카프카 브로커 서버 1대로도 실행이 가능하지만, 데이터를 안전하게 처리하기 위해
3대 이상의 브로커 서버를 1개의 클러스터로 묶어서 운영한다.
묶인 브로커들은 프로듀서가 보낸 데이터를 안전하게 분산 저장하고, 복제하는 역할을 수행한다.
- 데이터 저장, 전송
프로듀서 → 브로커 : 데이터를 전달
브로커 : 프로듀서가 요청한 토픽의 파티션에 데이터를 저장, 데이터는 파일 시스템에 저장
컨슈머 → 브로커 : 데이터를 요청
파일 시스템을 사용하니까 처리속도가 느린 거 아닌가?
아니다. 페이지 캐시를 사용하여 문제를 해결했다.
페이지 캐시란 OS(운영체제 레벨)에서 파일 입출력 성능 향상을 위해 만들어 놓은 메모리 영익이다.
한 번 읽은 파일 내용은 메모리의 페이지 캐시 영역에 저장되기 때문에 빠른 속도를 가질 수 있다.
- 데이터 복제, 싱크
데이터 복제(replication)는 카프카를 장애 허용 시스템(fault tolerant system)으로 동작하도록 한다.
클러스터로 묶인 브로커 중 일부에 장애가 발생하더라도 파티션 단위로 일어나는 데이터 복제 덕분에
다른 브로커도 같은 데이터를 가지고 있기 때문이다.
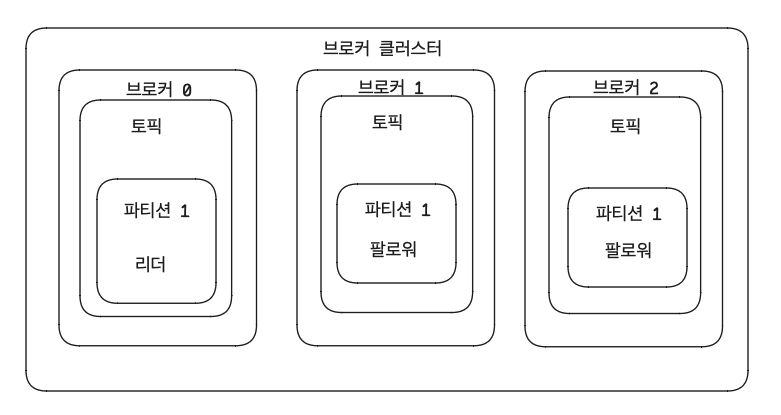
위 사진은 브로커가 3대로 구성된 경우이다. 복제된 파티션은 리더(leader)와 팔로워(follower)로 구성된다. 이 때 리더는 프로듀서 또는 컨슈머와 직접 통신하는 파티션을 부르고, 나머지 복제 데이터를 가지는 파티션을 팔로워라고 부른다.
팔로워 파티션 : 리더 파티션의 오프셋을 확인하여 현재 자신의 오프셋과 다른 경우 리더 파티션으로부터
데이터를 가져온다.
위 과정을 복제 replication 이라고 한다.
물론 파티션 복제에서 데이터가 복제되는 만큼 저장 용량이 증가한다는 단점이 있지만
데이터를 안전하게 사용할 수 있다는 장점을 위해서는 2 이상의 복제 개수를 정해야 한다.
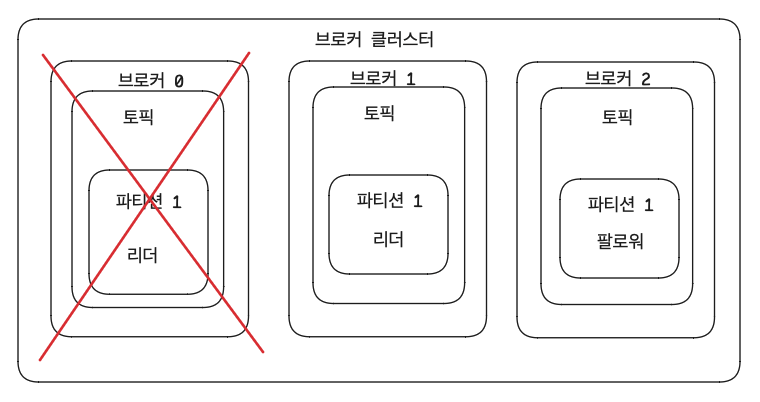
만약 위와 같이 브로커 0번에 장애가 발생하면, 리더 파티션을 사용할 수 없기 때문에
팔로워 파티션 중 하나가 리더 파티션이 된다.
이를 통해 데이터가 유실되지 않고 컨슈머, 프로듀서와 데이터를 주고받도록 동작할 수 있다.
- 컨트롤러 Controller
클러스터의 다수 브로커 중 한 대가 컨트롤러의 역할을 한다.
컨트롤러는 다른 브코러들의 상태를 체크하고, 브로커가 클러스터에서 빠지는 경우 해당 브로커에 존재하는
리더 파티션을 재분배한다. 또한 브로커가 비정상이라면, 클러스터에서 빼내는 역할을 한다.
만약 컨트롤러 역할을 하는 브로커에 장애가 발생하면, 다른 브로커가 컨트롤러 역할을 한다.
- 데이터 삭제
카프카는 컨슈머가 데이터를 가져가더라도 토픽의 데이터는 삭제되지 않는다.
또한 컨슈머나 프로듀서가 데이터 삭제 요청할 수도 없다.
오직 브로커만이 데이터를 삭제할 수 있다.
데이터 삭제는 파일 단위로 이루어지는데 이 단위를 로그 세그먼트(log segment)라고 한다.
이 세그먼트에는 여러 데이터가 들어있기 때문에, 데이터를 특정해서 삭제할 수 없다.
- 컨슈머 오프셋 저장
컨슈머 그룹은 토픽이 특정 파티션으로부터 데이터를 가져가서 처리하고, 이 파티션의 어느 레코드까지 가져갔는지 확인하기 위해 오프셋을 커밋한다. 커밋한 오프셋은 consumer offsets 토픽에 저장되고,
여기에 저장된 오프셋을 토대로 컨슈머는 다음 레코드를 가져가서 처리한다.
- 코디네이터 coordinator
클러스터의 여러 브로커 중 하나는 코디네이터의 역할을 수행한다.
코디네이터는 컨슈머 그룹의 상태를 체크하고, 파티션을 컨슈머와 매칭되도록 분배하는 역할을 한다.
컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않은 파티션을 정상 동작하는 컨슈머로 할당한다.
이렇게 파티션을 컨슈머로 재할당하는 과정을 리밸런스 라고 한다.
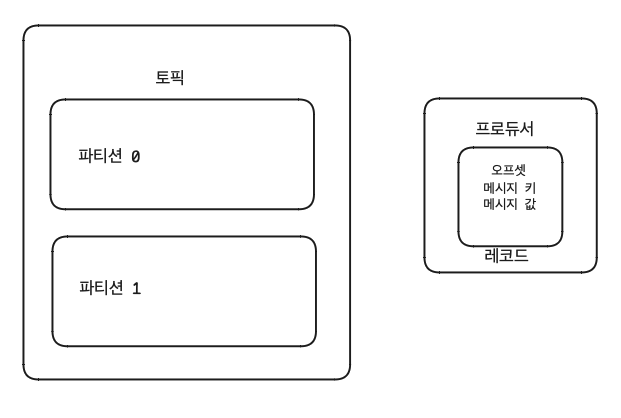
토픽과 파티션
카프카에서 데이터를 구분하기 위해 사용하는 단위
토픽은 1개 이상의 파티션을 소유하고 있다.
파티션에는 프로듀서가 보낸 데이터들이 저장되는데, 이 데이터를 레코드 Record 라고 부른다.
파티션은 그룹으로 묶인 컨슈머들이 레코드를 병렬로 처리할 수 있도록 매칭된다.
컨슈머 처리량이 한정된 경우 많은 레코드를 병렬로 처리하는 방법은 컨슈머의 개수를 늘리는 것이다.
컨슈머의 개수와 파티션 개수를 같이 늘리면 처리량이 증가할 수 있다.
이 때 파티션은 큐 Queue와 비슷한 구조이다.
FIFO (First In First Out) 구조로 먼저 들어간 레코드는 컨슈머가 먼저 가져간다.
다만 사용된 레코드는 삭제되지 않는다.
때문에 여러 컨슈머 그룹이 토픽의 데이터를 여러 번 가져갈 수 있다.
레코드
타임스탬프, 메시지 키, 메시지 값, 오프셋으로 구성되어 있다.
프로듀서가 생성한 레코드가 브로커로 전송되면 오프셋과 타임스탬프가 지정되어 저장된다.
브로커에 한 번 적재된 레코드는 수정할 수 없다.
타임스탬프는 카프카 0.10.0.0 버전 이상에서만 사용할 수 있고, 브로커 기준 유닉스 시간이 설정된다.
메시지 키
메시지 값을 순서대로 처리하거나 메시지 값의 종류를 나타내기 위해 사용한다.
메시지 키를 사용하면 프로듀서가 토픽에 레코드를 전송할 때 메시지 키의 해시값으로 파티션을 지정한다.
즉, 동일한 메시지 키를 사용한다면 같은 파티션에 들어간다.
메세지 값
메세지 값에는 실질적으로 처리할 데이터가 들어 있다. 메세지 키와 메시지 값은 직렬화되어 브로커로 전송되기 때문에 컨슈머가 이용할 때는 역직렬화를 수행해야 한다.
이 때 직렬화, 역직렬화할 때는 반드시 동일한 형태로 처리해야 한다.
(ex. StringSerializer → IntegerDeserializer : 정상 X )
오프셋
레코드의 오프셋은 0 이상의 숫자로, 직접 지정할 수 없고, 이전 레코드의 오프셋+1 값으로 생성된다.
오프셋은 컨슈머가 데이터를 가져갈 때 사용된다.
컨슈머 그룹으로 이루어진 카프카 컨슈머들이 파티션의 데이터를 어디까지 가져갔는지 지정할 수 있다.
카프카 클라이언트
카프카 클러스터에 명령을 내리거나, 데이터 송수신을 위해 카프카 클라이언트 라이브러리는
카프카 프로듀서, 컨슈머, 어드민 클라이언트 제공하는 카프카 클라이언트를 사용한다.
카프카 클라이언트는 라이브러리이기 때문에, 프레임워크나 다른 애플리케이션 위에서 구현해야 한다.
- 프로듀서 API
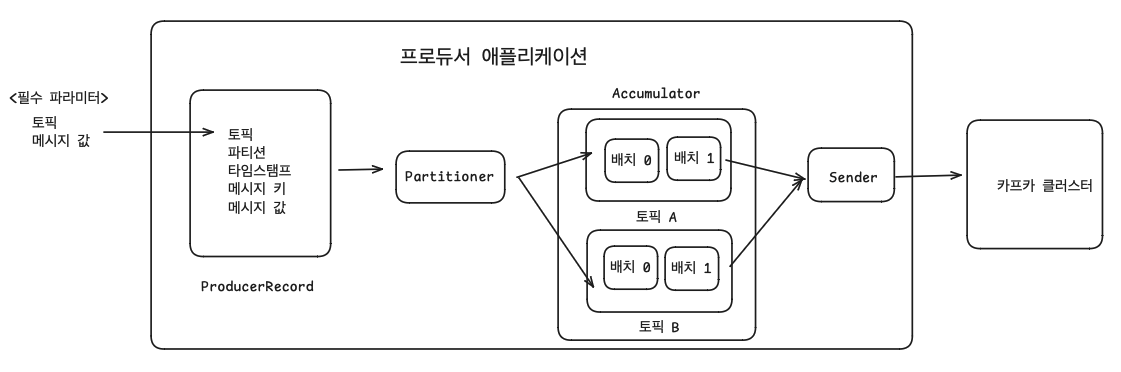
카프카에서 데이터의 시작점은 프로듀서이다.
프로듀서는 데이터를 선언하고, 직렬화하여 브로커의 특정 토픽의 파티션에 전송한다.
프로듀서는 데이터를 리더 파티션을 가지고 있는 브로커와 직접 통신한다.
프로듀서는 브로커로 데이터를 전송할 때 내부적으로 파티셔너, 배치 생성 단계를 거친다.
ProducerRecord 인스턴스 생성 시 생성 필수 파라미터인 토픽, 메시지 값을 설정해야 한다.
물론 다른 변수도 따로 지정할 수 있다.
파티셔너에 의해 구분된 레코드는 데이터를 전송하기 전 어큐뮬레이터(Accumulator)에 데이터를
버퍼로 쌓아놓고 발송한다. 배치로 묶어서 전송함으로써 프로듀서 처리량을 향상시킨다.
프로듀서 필수 옵션
1. bootstrap.servers : 브러커의 호스트 이름
2. key.serializer : 메시지 키 직렬화 클래스
3. value.serializer : 메시지 값 직렬화 클래스
- 컨슈머 API
프로듀서가 전송한 데이터는 카프카 브로커에 적재된다. 컨슈머는 적재된 데이터를 사용하기 위해
브로커로부터 데이터를 가져와서 처리를 한다.
1개 컨슈머는 여러 개의 파티션에 할당될 수 있다.
컨슈머 그룹의 컨슈머 개수는 가져가고자 하는 토픽의 파티션 개수보다 같거나 작아야 한다.
컨슈머 그룹은 다른 컨슈머 그룹과 격리되는 특징을 가지고 있다.
따라서 카프카 프로듀서가 보낸 데이터를 다른 역할을 하는 컨슈머 그룹끼리 영향을 받지 않게
처리할 수 있다는 장점을 가진다.
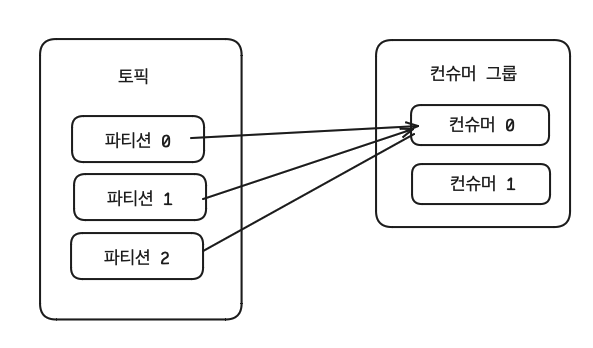
컨슈머 그룹의 컨슈머에 장애가 발생하면 어떻게 되나요?
컨슈머들 중 일부 컨슈머에 장애가 발생하면, 장애가 발생한 컨슈머에 할당된 파티션은 장애가 발생하지 않은 컨슈머에 소유권이 넘어간다. 이를 리밸런싱 이라고 한다.
리밸런싱은 크게 2가지 상황에서 발생한다.
1. 컨슈머가 추가되는 상황
2. 컨슈머가 제외되는 상황
리밸런싱은 컨슈머가 데이터를 처리하는 도중에 언제든지 발생할 수 있으므로, 리밸런싱에 대응하는 코드를 작성해야 한다.
리밸런싱이 발생할 때 파티션의 소유권을 컨슈머로 재할당하는 과정에서 해당 컨슈머 그룹의 컨슈머들이
토픽의 데이터를 읽을 수 없다. 그룹 조정자(group coordinator)는 리밸런싱을 발동시키는 역할을 한다.
카프카 브로커 중 한 대가 그룹조정자의 역할을 수행한다.
컨슈머는 커밋을 통해 브로커로부터 데이터를 어디까지 가져갔는지 기록한다.
카프카 브로커 내부에서 사용되는 내부 토픽(consumer offsets)에 기록되는데, 만약 어느 레코드까지
읽었는지 오프셋 커밋이 기록되지 못했다면, 데이터 처리의 중복이 발생할 수 있다.
컨슈머 필수 옵션
1. bootstrap.servers
2. key.deserializer
3. value.deserializer
- 어드민 API
프로듀서와 컨슈머 이외에 카프카에 설정된 내부 옵션을 설정하고 확인하는 것도 중요하다.
카프카 클라이언트에서는 내부 옵션들을 설정하거나 조회하기 위해 AdminClient 클래스를 제공한다.
어드민 주요 메서드
1. describeCluster : 브로커의 정보 조회
2. listTopics : 토픽 리스트 조회
3. listConsumerGroups : 컨슈머 그룹 조회
4. createTopics : 신규 토픽 생성
5. createPartitions : 파티션 개수 변경
6. createAcls : 접근 제어 규칙 생성
