
이 챕터의 흐름
AI Agent가 무엇인지 개념부터 출발하여, Agent가 "생각"하는 방식(LLM Reasoning), 실제로 "행동"하는 방식(Tool Calling + ReAct Framework), 그리고 Agent들이 서로 소통하는 표준(MCP, A2A)까지 차례로 이해한다. 이 세 가지를 합치면 "지능(LLM) + 행동(Tool) + 연결(Protocol)"이라는 AI Agent의 전체 구조가 완성된다.
1-1. AI Agent란?
Agent의 사전적 의미
Agent는 원래 "타인을 대신해 일을 처리하는 존재" 를 의미한다. 계약/협상을 대신 처리하는 법정 대리인이나, 특정 분야에서 전문적으로 일을 처리하는 에이전트가 그 예다.
AI Agent의 정의
물리적 또는 가상 환경에서 자율적으로 목표를 달성하기 위해 행동하는 소프트웨어 시스템
- 사용자의 요구를 이해하고, 그에 맞는 기능 또는 결과를 제공하는 과정에서 언어모델(LLM)과의 상호작용을 통해 이루어진다.
- 특정 목표를 수행하기 위해 매우 구체적인 프롬프트와 특정 도구(WEB, API, Plug-in 등)가 필요하다.
- 제한된 환경(브라우저, 코드 실행 등)에서 작동한다.
Agentic AI의 개념
심리학에서 Agentic Behavior란 "외부 자극에 반응하는 것이 아니라, 스스로 목표를 설정하고 행동하는 자기 주도적 행동"을 뜻한다. AI에서 이를 적용하면:
- 단순한 Task 수행을 넘어서 → 목표 설정, 계획 수립, 도구 선택, 협업까지 수행
- 여러 에이전트와 협력하거나, 복합적인 Multi-Step Task를 조정 가능
AI Agent = LLM + Tools
AI Agent는 "두뇌(LLM)"와 "행동(Tools)"의 결합이다.
| 역할 | 담당 | 기능 |
|---|---|---|
| 두뇌 | LLM | 판단, 계획, 기억, 자연어 처리 |
| 행동 | Tools | 실제 작업 수행, 외부 시스템 상호작용 |
LLM의 역할 (두뇌)
- 자연어 처리 및 기억 (Memory): 사용자의 질문과 의도를 정확히 이해하고 적합한 응답 생성. 이전 대화 맥락 유지(단기 기억)하고, 사용자 선호도나 과거 데이터를 저장/조회(장기 기억)
- 작업 계획 및 추론 (Planning): 사전에 학습된 데이터로부터 지식을 생성하고 판단 수행. 복잡한 요청을 달성 가능한 여러 하위 단계로 쪼개고(Task Decomposition), 스스로 결과를 평가하여 다음 행동 결정(Self-Reflection)
Tools의 역할 (행동)
- 필요 도구 연결 (Tool Use): 외부 시스템(DB, Cloud, 인터넷 등)과 통합되어 실질적인 행동 실행 (예: 스케줄 시스템에 접근해 회의 일정 저장, RAG 검색 등)
- 자율적 작업 자동화 (Autonomous Action): 정의된 프로세스에 따라 반복 업무를 자동화하여 편의성 증대. LLM이 수립한 계획(Planning)에 따라 적절한 도구를 순차적으로 호출하여 사람의 개입 없이 목표 완수
💡 핵심 통찰: Prompt Engineering은 죽었는가?
"Manual prompt crafting doesn't scale. If you're still hand-tuning prompts, you're doing it wrong."
더 이상 잘 쓰는 프롬프트가 경쟁력이 아니다. 잘 작동하는 AI 에이전트/시스템을 설계하는 것이 핵심이다. 이 패러다임 전환을 Context Engineering이라고 부른다.
Context Engineering의 구성 요소:
- Prompt: Instruction/System Prompt + User Prompt
- Context: State/Short-term Memory + Long-term Memory + RAG (외부 최신 정보)
- Agent: Available Tools + Structured Output
에이전트가 어떤 작업을 합리적으로 수행하기 위해서는 그 작업에 적합한 맥락 정보가 필요하다.
1-2. LLM Reasoning
AI Agent의 두뇌가 어떻게 "생각"하는지를 이해하는 것이 중요하다. 여기서 두 가지 용어를 명확히 구분해야 한다.
1-2-1. Inference vs Reasoning
Inference (추론/예측)
- "증거나 추론을 바탕으로 도달한 결론" — 결론 자체를 가리킴
- ML/DL에서: 학습이 끝난 모델을 이용해 새로운 데이터에 대한 출력을 생성하는 단계
- LLM에서: 결국 딥러닝 모델이므로, 확률적으로 가장 가능성 높은 단어를 예측하는 과정
- 중요: LLM에서 inference 단계 ≠ 논리적 reasoning 단계
Reasoning (추론/사고 과정)
- "어떤 결론이나 판단에 도달하기 위해 논리적으로 사고하는 행위" — 과정 자체를 가리킴
- 전제 → 사고 과정 → 결론 도출로 구분되는 생각의 전개 과정에 초점
- LLM에서: 단순 암기나 패턴 응답이 아닌, 논리 구조를 따라가며 정답에 도달하는 과정
- 예시: "A는 B보다 무겁고, B는 C보다 무겁다. 누가 가장 무겁나?" → reasoning 필요
⚠️ LLM의 확률적 추론의 불안정성
Apple이 발표한 연구(GSM-Symbolic Benchmark)에 따르면, 동일한 문제의 수치값만 변경해도 LLM의 모델 성능이 크게 변하는 불안정성이 확인되었다. LLM이 수치값의 변화에 민감하며, 일관된 수학적 추론을 수행하는 데 한계가 있음을 보여준다. 이는 LLM이 진정한 논리적 추론을 수행하는지, 아니면 그럴듯한 답변 생성만 하는지에 대한 논란을 불러일으킨다.
1-2-2. LLM Reasoning의 본질
단순 답변 생성이 아닌, 목표 달성을 위해 "판단하고 계획하는 사고의 과정"으로 봐야 한다.
LLM Reasoning은 AI Agent가 "왜 이 행동을 해야 하는가"를 판단하게 하는 과정이다.
AI Agent에서 Reasoning의 역할:
| Agent 역할 | 내용 |
|---|---|
| 행동 판단 | 도구를 쓸 것인지, 응답을 생성할 것인지를 결정 |
| 작업 계획 | 단계를 나누고 어떤 순서로 처리할지 구상 |
| 결과 검토 및 수정 | 행동 결과를 평가하고 다시 사고(재추론)하여 행동 수정 |
| 목표 일치 판단 | 현재 정보가 사용자의 목표를 충족하는지 확인 |
System 1 vs System 2 사고 (Karpathy, 2023)
- System 1: 빠르고 본능적인 판단. 기존 LLM의 즉각적인 패턴 매칭 응답 (Fast Thinking)
- System 2: 느리고 논리적인 연산. AI Agent가 수행하는 추론(Reasoning) 및 계획(Planning) 과정 (Slow Thinking)
- 현재의 LLM은 System 1에 불과하며, 진정한 AI는 System 2(생각하는 과정)을 가져야 한다.
1-2-3. LLM Reasoning을 위한 전략적 도구
LLM의 Reasoning 능력은 완전하지 않기 때문에, 다양한 보완 방식이 연구되고 활용된다.
Prompt-level 보완
| 보완 방식 | 핵심 개념 | 역할/목적 |
|---|---|---|
| Chain-of-Thought (CoT) | 모델이 중간 사고 과정을 말하도록 유도하는 프롬프트 설계 | 단순 답이 아니라 생각하는 흐름을 생성하도록 함 |
| Self-Consistency Decoding | 하나의 프롬프트에 대해 여러 개의 추론 경로를 생성한 뒤, 가장 일관된 정답을 다수결로 선택 (CoT와 함께 자주 사용) | 여러 사고 흐름 중 가장 논리적인 것을 선택하여 신뢰도 확보 |
| Inference-time Scaling | 추론 단계에서 중간 추론 단계를 생성하는 메커니즘 도입 | Reasoning 과정 조절 |
Model-level 보완
| 보완 방식 | 핵심 개념 | 역할/목적 |
|---|---|---|
| SFT + RL | 사람이 직접 만든 정답 데이터를 학습하고, 보상 기반 학습 추가 | 논리적 사고력을 정밀하게 학습하도록 유도 |
| Distillation | 추론이 가능한 모델의 사고 과정을 다른 모델이 학습하도록 전이 (Teacher → Student Model) | 잘 훈련된 모델의 추론 방식을 복제 |
Tool-level 보완
| 보완 방식 | 핵심 개념 | 역할/목적 |
|---|---|---|
| Tool Augmentation | 계산기, 검색엔진, 웹서치, 코드 실행기 등의 도구와 상호작용 | 외부 도구의 능력과 함께 사용하여 사고력 보완 |
| RAG-based | DB/문서에서 관련 정보를 찾아, 검색된 정보를 연결 및 종합하여 결론을 이끌어냄 | 지식의 고정성을 극복하며 정보 기반 추론 능력 강화 |
| Scratchpad | 모델이 사고의 중간 메모나 연산 과정을 텍스트 상에 남기도록 유도 | 추론의 투명성과 디버깅 가능성 추가 |
| Task Decomposition | 복잡한 개발 요청을 실행 가능한 단위 작업으로 분해하고 의존성 기반으로 순서 배치 | 대규모 프로젝트, 개발 워크플로우를 체계적으로 관리 |
💡 Chain-of-Thought (CoT) 상세 이해
개념: LLM에게 '정답만 말해'가 아니라 "생각 과정을 말해가면서 답해"라고 요청하는 기법
프롬프트 예시:
A car travels at 60 km/h for 2 hours, then at 80 km/h for 1.5 hours. What is the total distance the car travels? Let's think step by step.출력 예시:
Step 1: First part of the trip → 60 km/h × 2 h = 120 km Step 2: Second part of the trip → 80 km/h × 1.5 h = 120 km Total distance = 120 km + 120 km = 240 kmSelf-Consistency와의 차이: CoT는 단일 사고 흐름을 유도하고, Self-Consistency는 여러 번 CoT를 실행해 가장 자주 나오는 정답을 채택한다. 즉, Self-Consistency = CoT × N + 다수결 투표.
💡 Task Decomposition (Cursor.AI 방식)
LLM이 개발 프로젝트를 체계적으로 분해하고 관리하는 전략적 도구:
- Task Decomposition: Task 목적에 맞게 Top-Down 분해, 의존성 분석. SMART 기반 작업 단위화 (Specific, Measurable, Achievable, Relevant, Time-bound)
- Priority Matrix: 중요도-긴급도-복잡도-리스크 기반 작업 우선순위 결정
- Context Integration: 기존 코드베이스 및 기술 스택을 고려한 계획 수립, 프로젝트 일관성 유지 및 기술 부채 최소화
1-3. Tool Calling과 ReAct Framework
LLM이 "생각"한다면, Tool Calling은 실제로 "행동"하게 하는 메커니즘이다.
1-3-1. Tools의 개념
Tools(도구)는 Agent, Chain 또는 LLM이 외부 세계와 상호작용하기 위한 인터페이스다.
- Built-in Tools: LangChain에서 제공하는 사전에 정의된 도구(tool)와 툴킷(toolkit)
- Tool: 하나의 기능만 제공하는 도구
- Toolkit: 여러 도구를 묶어서 하나의 도구로 사용
- Custom Tools: 사용자가 직접 도구를 사전에 정의하여 사용
@tool데코레이터를 사용하여 일반 파이썬 함수를 도구로 변환- LLM이 함수를 호출할 때 확인할 수 있도록 docstring을 추가해야 함
1-3-2. Tool Calling 개념 및 흐름
모델이 적절한 도구를 반복적으로 호출하고 결과를 받아 문제를 해결하는 방식
Tool Calling Workflow (예시: "이번주에 볼 만한 영화를 추천해줘")
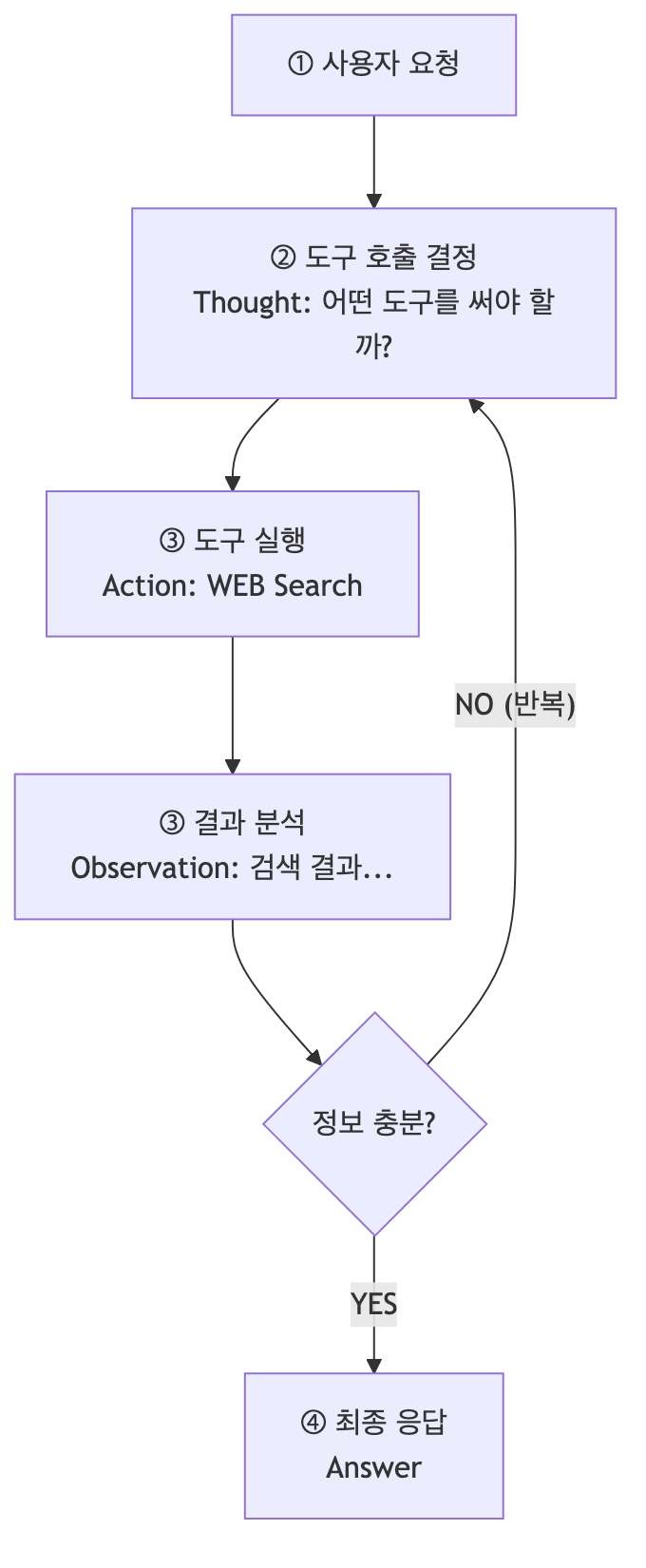
Tool Calling의 핵심은, 모델이 하나 이상의 도구가 호출되어야 하는 시기를 감지하고, 도구 호출을 일반 텍스트 완성보다 더 안정적이고 유용하게 반환하는 것이다.
1-3-3. ReAct Framework
ReAct = Reasoning + Acting
사고(Reasoning)와 행동(Acting)을 하나의 시스템으로 결합한 프레임워크 (2022, Princeton Univ & Google Research)
ReAct의 순환 구조:
- Thought (사고): 사용자 질문을 받은 후, 다음으로 어떤 행동을 취해야 할지 사고 (Reasoning)
- Action (행동): 행동을 결정하고 실행 (예: 도구 호출, 데이터 검색, 외부 API 호출 등)
- Observation (관찰): 행동의 결과로 얻은 피드백(검색결과)을 관찰함
- 정보가 충분하면 → Answer 반환 / 부족하면 → Thought로 돌아가 반복
ReAct 예시 (SK하이닉스 종가 조회):
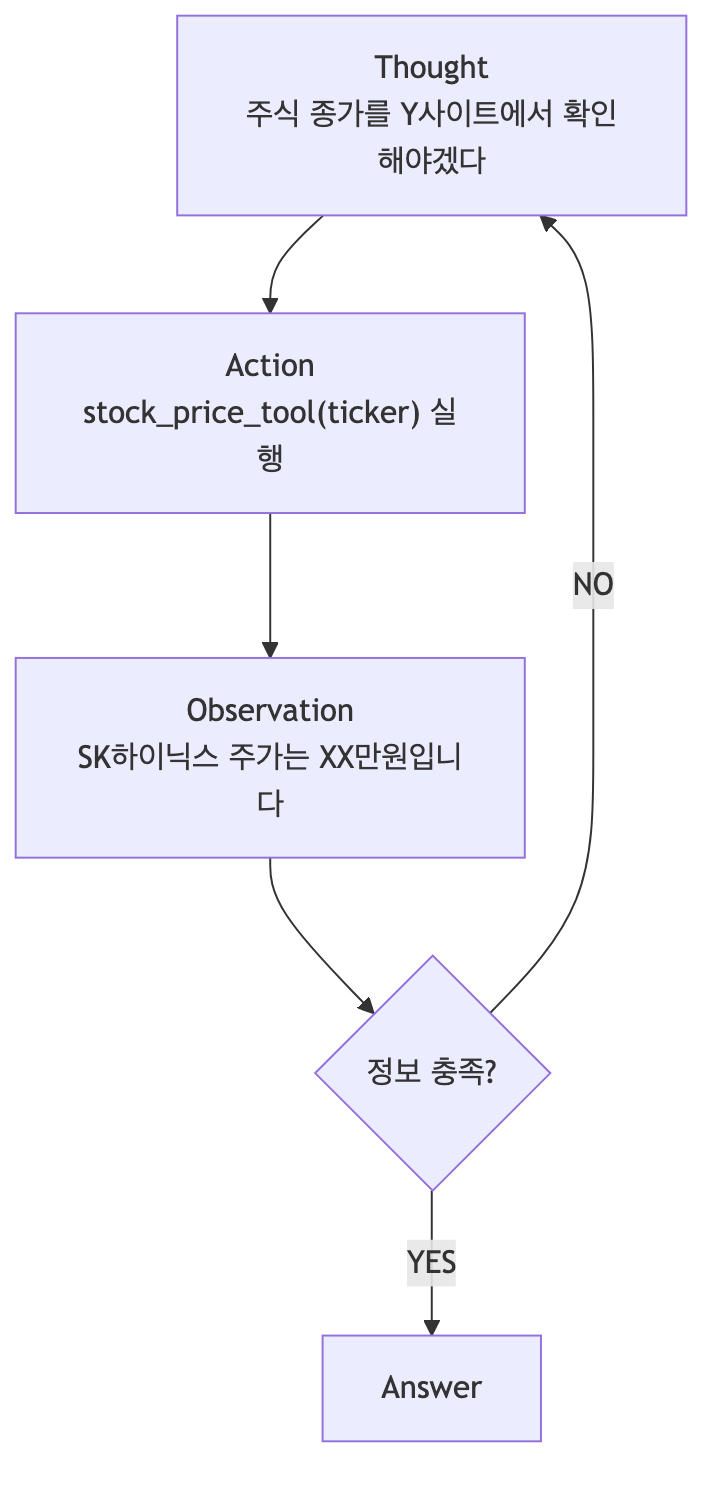
ReAct의 역사적 기여:
- Reasoning과 Acting을 최초로 하나의 시스템으로 결합한 연구
- 이후 Tool-use, Memory, Multi-Agent 설계 프레임워크들의 기반이 됨
- LangGraph 등 개발 프레임워크 성숙의 출발점
1-3-4. ReAct Framework의 확대/발전
Multi-Agent로의 확대 (2024~현재):
단일 에이전트의 ReAct 구조가 여러 에이전트가 협력하는 구조로 발전했다.
- Orchestration: Supervisor에 의한 동적 작업 분배 및 관리
- Graph-based Collaboration: 단순 순차 실행이 아닌, 순환(Loop)과 분기 처리(Conditional Edge)가 가능한 워크플로우 설계
- Context, Memory 관리:
- 단기 메모리: Scratchpad를 통한 임시 저장
- 장기 메모리: History 정보를 별도 DB에 구성하여 저장
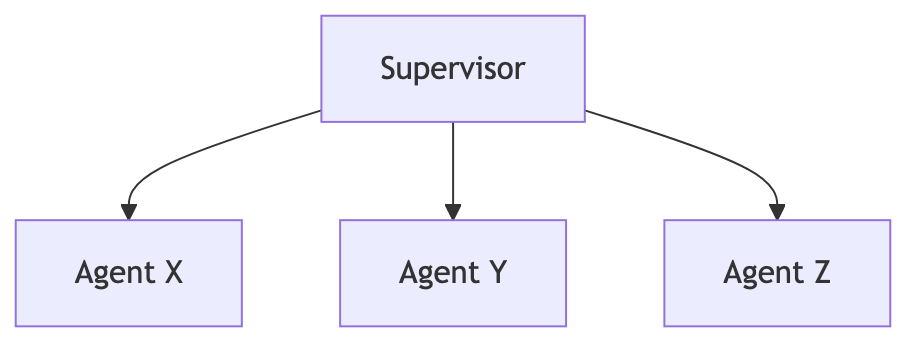
💡 Supervisor 패턴 (HuggingGPT 2023 & AutoGen 2023)
Supervisor는 입력된 요청을 분석해 가장 적합한 에이전트에게 실행을 맡기고(Routing), 그 결과를 종합하여 답변을 완성하는 Orchestration 패턴이다.
- 개념적 기원 (HuggingGPT, 2023.03): LLM이 직접 문제를 풀지 않고, 관리자(Controller)로서 하위 모델(Expert Models)에게 일을 시킨다는 개념
- 구조적 기원 (AutoGen, 2023.08): Multi-Agent 간의 협업 및 순서 제어를 프레임워크 단위로 구현한 최초의 사례
1-3-5. Tool Calling 구현 프로세스 (LangChain)
Tool Calling을 코드로 구현하는 4단계 프로세스:
- 도구 생성:
@tool데코레이터로 파이썬 함수를 도구로 정의. 여러 개의 도구는 리스트로 묶음 - Agent Prompt 생성:
ChatPromptTemplate을 활용하여 정의system: 에이전트에게 모델이 수행할 작업 설명chat_history: 이전 대화 내용 저장agent_scratchpad: 에이전트가 임시로 저장하는 변수
- Agent 생성: 실행에 필요한 도구와 프롬프트를 묶어서
create_tool_calling_agent(llm, tools, prompt) - Agent 실행:
AgentExecutor를 통해 처리,invoke또는stream으로 실행
LangChain 1.0 업데이트:
- "Message" 중심 설계로 전환 (system_prompt + message 구조)
scratchpad가 자동 관리됨create_agent내부로 통합
1-4. Agent Protocol (MCP, A2A)
여러 AI Agent가 협력하거나 외부 도구/데이터와 연결되려면 표준화된 통신 규약(Protocol)이 필요하다. 자연어로 소통하는 모델이 맥락을 파악하고 작업을 수행하려면, 먼저 그 맥락을 모델이 이해할 수 있는 형식으로 변환하는 과정이 필요하기 때문이다.
1-4-1. MCP (Model Context Protocol)
목적:
- 에이전트와 다양한 데이터베이스를 쉽게 연결할 수 있는 오픈소스 프로토콜 (Anthropic 발표, 2024.11)
- AI 시스템이 외부 정보에 직접 접근하여 성능과 활용도를 높임
핵심 비유: "Just as USB-C simplifies how you connect different devices to your computer, MCP simplifies how AI models interact with your data, tools, and services."
기능 및 특징:
- 표준화된 인터페이스: 다양한 AI 시스템과 데이터 소스가 서로 잘 연동될 수 있도록 공통의 규칙과 형식 정의
- 통합의 용이성: 각 데이터 소스에 맞춰 별도의 인터페이스 코드를 작성할 필요 없이, 통합된 프로토콜로 여러 데이터 소스와 연결
Key Milestones:
1. Phase 1 (2024.11): 초기 런칭 — Spec 공개, Python/TypeScript SDK 배포
2. Phase 2 (2025 상반기): 생태계 확산 — Java, Kotlin, Go 등 SDK 지원 확대 및 Community Server 활성화
3. Phase 3 (2025 하반기): 표준 정착 — Cursor, VS Code, LangChain, LlamaIndex 등 네이티브 통합 완료
1-4-2. MCP 아키텍처 (Host-Client-Server)
MCP는 명확한 역할 분담을 통해 유연하고 확장 가능한 시스템을 구현한다.
MCP Host (회사의 팀장 역할)
- 사용자와 직접 상호작용하는 어플리케이션
- 여러 MCP Server와의 연결을 조정하는 중앙 통제실 역할
- 주요 역할: LLM과의 통합 및 전체 데이터 흐름 조정, 다양한 서버의 응답을 취합 및 정리하여 AI 모델에 전달
MCP Client (팀장과 각 부서 사이의 전담 인력)
- 호스트 내부에서 동작
- 각 MCP Server와 1:1로 연결되는 중개자 역할
- 주요 역할: 서버와의 독립적인 연결 및 세션 관리, 프로토콜 협상, 기능 교환, 요청/응답 메시지 전달
MCP Server (회사의 각 부서 역할)
- 특정 업무(데이터 제공, 도구 실행 등)를 담당
- AI 모델이 사용할 수 있는 3대 핵심 요소 제공:
- Resources: File, API, DB 등 모델이 읽을 수 있는 데이터 정보
- Tools: 모델이 외부 시스템에 개입하여 실행할 수 있는 액션 (함수 호출)
- Prompts: 사용자가 쉽게 작업을 시작할 수 있도록 정의된 프롬프트 템플릿
- 주요 역할: 로컬 데이터(파일, DB)나 원격 서비스(API, 클라우드 등)와 연결
Sequence Diagram 예시 ("2026년_매출.pdf 파일을 읽고 최신 뉴스 동향을 웹에서 검색하여 종합 요약"):
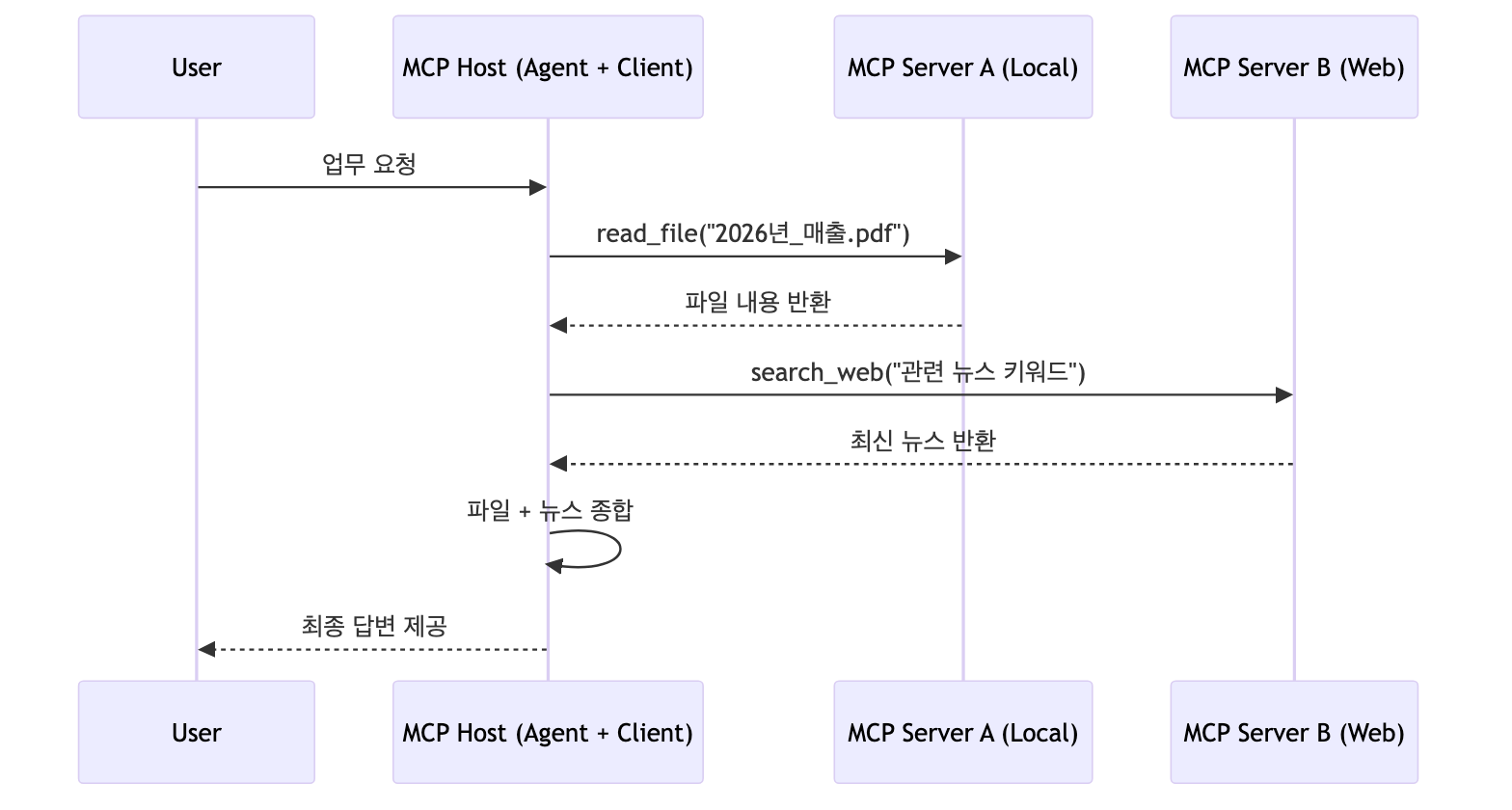
1-4-3. Tool Calling vs MCP
요구사항과 목적에 맞춰 강한 결합(Native)과 느슨한 결합(MCP) 중 적절한 아키텍처를 선택해야 한다.
| 항목 | Native Tool Calling | MCP |
|---|---|---|
| 아키텍처 성격 | 강한 결합 (Tightly Coupled) | 느슨한 결합 (Loosely Coupled) |
| 도구 정의 및 관리 | 개발자가 직접 스키마를 정의, LLM 프롬프트에 반영 | MCP Server가 동적으로 도구 목록을 제공, 에이전트는 도구 목록을 탐색 |
| 장점 | 세밀한 제어, Low Latency (내부 함수 직접 호출) | 높은 확장성, 재사용성 (여러 에이전트가 하나의 Server 공유) |
| Best For | 목적형 에이전트, 사내 DB/API 연동 등 보안 로직 적용이 필요한 경우 | 범용 에이전트, SaaS, Local File 등 다양한 외부 생태계와의 통합이 빈번한 경우 |
핵심 구분: Tool Calling은 모델이 무엇을 하려는지(INTENT)를 표현하는 것이고, MCP는 그 행동이 확장 가능한 멀티 에이전트 생태계에서 어떻게 처리될지(INFRASTRUCTURE)를 다루는 것이다.
1-4-4. MCP가 필요한 이유
MCP 이전의 LLM 시스템이 가진 구조적 한계:
- LLM은 세션 중심 구조: 1개의 입력(prompt) → 1개의 출력(response). 모델이 세션을 넘어서 기억하지 못함.
- 내부 메모리 없는 Stateless 모델: GPT, Claude, Gemini 같은 대부분의 LLM은 상태를 기억하지 못하므로, 기억을 흉내내려면 앞선 내용을 전달해야 하며, 이는 context length 문제로 이어짐.
- 프롬프트 자체로는 Context 관리에 부적합: 자연어 기반 프롬프트는 구조적 context 표현에 불리함.
- 시스템 간 Context 교환을 위한 공통 포맷 부재: GPT에서 생성한 요약 내용을 Claude에 넘기려면 복사-붙여넣기 방식 사용.
1-4-5. 기존 LLM 구조 vs MCP 기반 구조
| 항목 | 기존 LLM 구조 | MCP 기반 구조 |
|---|---|---|
| 기억 (메모리) | Stateless (메모리 없음) | 명확한 Context 객체로 상태 저장 및 전달 가능 |
| 입력 방식 | 자연어 프롬프트 기반, 비구조적, 단방향 | 구조화된 JSON/YAML 기반, Context Object |
| 작업 전이 | 수동으로 복사-붙여넣기, 사용자 정의 로직으로 처리 | Context를 다른 에이전트나 모델에게 그대로 전달 |
| 다중 에이전트 입력 | Memory 공유가 어렵고, 상태 추적 안됨 | agent_id, task, memory 등 명시하여 처리 가능 |
| 문맥 흐름 추적 | 거의 불가능 | 각 단계의 context 기록, 흐름 추적 및 디버깅 가능 |
| 상호 운용성 | 모델/시스템 간 context 전달 어려움 | 공통 포맷으로 모델 간 연동성 확보 |
| 보안/제한 설정 | 프롬프트 내 명시 불가능 | Context에 역할/도구 제한, 사용자 권한 명시 가능 |
1-4-6. A2A Protocol
A2A (Agent-to-Agent Protocol)는 MCP가 에이전트와 외부 도구/데이터의 연결을 담당하는 것과 달리, 에이전트 간의 협업과 통신을 담당하는 프로토콜이다.
개요:
- 에이전트들이 서로 연동할 수 있도록 돕는 오픈소스 프로토콜
- 현재 Linux Foundation 산하 프로젝트로 150개 이상의 글로벌 기업이 참여
- 에이전트들이 서로의 기능을 활용하여 복잡한 비즈니스 프로세스를 자동화하고, 개입을 최소화할 수 있음
주요 기능:
- Capabilities Discovery & Intelligent Routing: 에이전트는 JSON 형식의 Agent Card를 통해 자신의 역량과 Latency를 광고. 적절한 에이전트를 식별하고, 가장 응답성이 좋은 에이전트에게 작업을 할당하는 지능형 작업 배분 지원
- Task Management & Collaboration: Client가 작업을 요청하면, Server가 해당 작업을 수행하고 결과물 반환. Host는 전체 워크플로우를 관리하며, 에이전트 간 Context, 응답, 결과물, 지시 등을 전달하기 위해 메시지 관리
- UX Negotiation & Enterprise Security: 단순한 데이터 전송을 넘어 에이전트 간에 "어떻게 화면에 보여줄까?"까지 협상할 수 있도록 설계. gRPC 지원 및 보안 카드 서명 기능을 통해 엔터프라이즈급 고성능, 고보안 통신 제공
💡 gRPC란?
기존 방식(REST API)은 길고 상세한 텍스트(JSON)로 전달하며, 한 번에 한 건만 처리할 수 있는 좁은 도로(HTTP/1.1)를 사용한다. 반면 gRPC(Google Remote Procedure Call)는:
- 마치 무전기로 미리 짠 암호로 주고받듯이, 사전에 구조화된 암호표(Protocol Buffers)를 공유
- 데이터 크기가 엄청나게 작아져서 전송 속도가 비교할 수 없이 빠름
- 여러 차선의 고속도로(HTTP/2)를 사용하기 때문에 실시간, 양방향 스트리밍 모두 지원
Multi-Agent 구조에서는 속도와 효율성이 최우선이기 때문에, 여러 에이전트들의 작업을 병목 현상 없이 실시간으로 수집하고 연결할 수 있다.
1-4-7. A2A Protocol의 필요성
- Standardized Protocol: 에이전트 간 통신을 위한 메시지 구조(HTTP, SSE, JSON-RPC, gRPC 등)를 개방형 표준으로 통일
- Scaled and Structured Collaboration: 멀티 에이전트 구조의 유연성 극대화. 특정 Server 에이전트를 교체하거나 삭제하는 것이 매우 용이
- Cross-Platform Interoperability: 서로 다른 플랫폼과 기술 환경에서도 원활한 에이전트 간 통신 보장
- Modular, Extensible AI Ecosystem: Linux Foundation의 벤더 중립적 오픈소스 운영 원칙을 통해 특정 단일 플랫폼에 종속되지 않음
1-4-8. Protocol 현황 및 한계 (2026)
MCP(Anthropic)와 A2A(Google)의 경쟁 구도에서 벗어나, 두 프로토콜 모두 Linux Foundation이라는 거대한 오픈소스 우산 아래로 통합되었다.
에이전트 생태계를 위한 과제:
| 과제 | 현황 | 한계점 |
|---|---|---|
| 의미론적 상호 운용성 부재 | MCP와 A2A를 통해 에이전트들이 서로 메시지를 주고받을 수 있도록 연결 | Client가 요청한 작업의 맥락을 다른 개발자가 만든 Server 에이전트가 잘못 이해할 여지가 여전히 남아있음 |
| 분산 트랜잭션 및 Rollback | 여러 에이전트가 연쇄적으로 작업을 수행할 때 중간 단계 오류 시 전체 Workflow 관리 복잡 | 표준화된 복원(Resilience) 패턴 부재 |
| 환각 전파 및 책임 소재 | 단일 AI 모델의 환각 현상은 멀티 에이전트 환경에서는 더욱 치명적 | 하나의 잘못된 정보가 다음 에이전트 입력으로 전달되어 오류가 눈덩이처럼 증폭될 수 있음 |
| 오버헤드와 지연 시간 | A2A에 지능형 작업 배분과 gRPC가 도입되었으나 여러 에이전트를 거치는 과정은 물리적으로 시간 소모 | 사용자와 실시간으로 상호작용하는 환경에서는 여전히 병목으로 작용 |
핵심 요약
AI Agent는 LLM(두뇌)과 Tools(행동)의 결합이다. 단순히 토큰을 생성하는 Inference와 논리적으로 사고하는 Reasoning은 다르며, CoT나 Task Decomposition 같은 전략이 그 간격을 메운다. 이를 실제 행동으로 연결하는 것이 ReAct 프레임워크(Thought → Action → Observation 루프)이고, 여러 Agent가 협력하는 데 필요한 연결 표준이 MCP(도구 연결)와 A2A(Agent 간 통신)다.
