
이 챕터의 흐름
앞서 설계한 AI Agent의 개념과 워크플로우를 실제 코드로 어떻게 구현하는가를 다룬다. LangChain의 역사적 진화를 통해 왜 LangGraph가 등장했는지 이해하고, LangGraph의 핵심 구성 요소(State, Node, Edge)를 이해한 뒤, 실제 시스템을 설계하는 패턴(Loop, Memory, Human-in-the-Loop)과 병렬 처리 기법을 학습한다. 구현의 핵심은 "사고 구조(Reasoning)"와 "운영 정책(Governance)"을 분리하는 것이다.
3-1. Agent Framework: LangChain의 진화
3-1-1. LangChain (Pre) 구조와 한계점
초기 LangChain은 LCEL(LangChain Expression Language) 기반으로 다양한 응용 프로그램을 만드는 프레임워크였다.
기본 구조:

LCEL 주요 기능:
- 스트리밍 지원, 비동기 지원, 병렬 실행, 재시도 및 풀백, 중간 결과 액세스, 입/출력 스키마, LangSmith 추적, LangServe 배포
AS-IS (문제점):
- Prompt: 체인 내부에 로직이 섞여 있음
- Chain: Callback은 가능하지만 관찰 중심
- Chain: 실행 흐름과 실행 통제가 명확히 분리되지 않음
한계점 — 운영 서비스에서 필요한 것들이 Chain 내부에 포함되면 설계가 복잡해진다:
- 운영 통제: 비용/토큰 제한, Latency 제어
- 정책 통제: 정책에 맞지 않는 Tool 호출 방지, Command 제어 등
- 모니터링: Tracing, Audit, Logging
핵심 문제: "사고 구조"와 "운영 정책"이 뒤섞여 있음
3-1-2. LangChain 1.0: Agent와 Runtime Governance의 분리
LangChain 1.0은 이 문제를 해결하기 위해 Agent(사고 구조)와 Runtime Governance(운영 정책)를 분리한 아키텍처로 재정렬되었다.
아키텍처 계층:
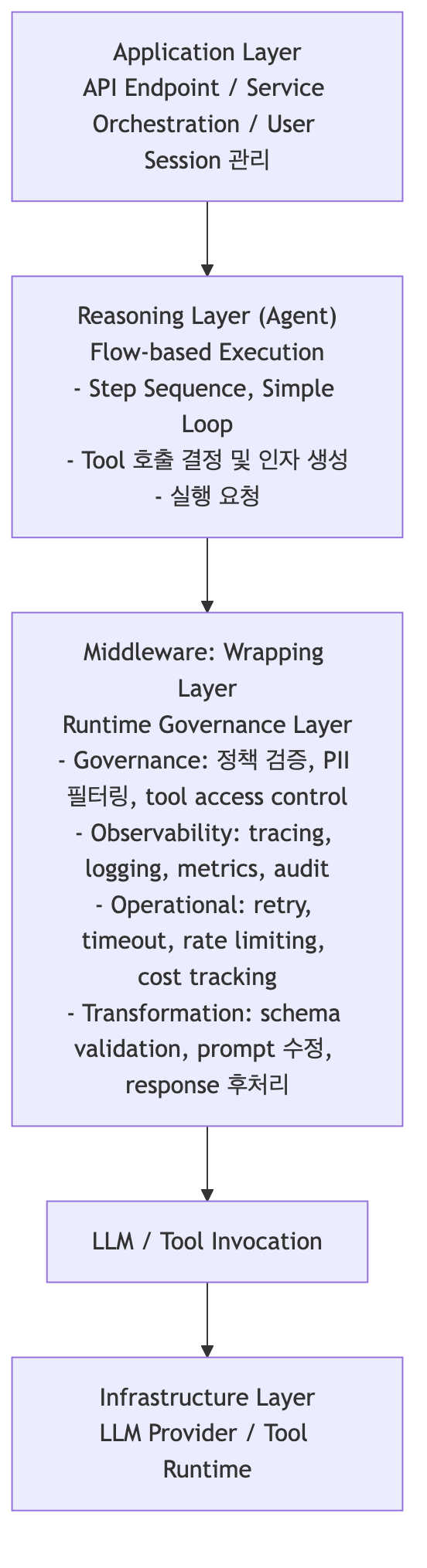
Pseudo Code 비교:
# LangChain Pre: 사고 구조와 운영 로직이 섞여 있음
def handle_request(user_input):
prompt = build_prompt(user_input)
response = llm.invoke(prompt)
if violates_policy(response): # 운영 로직
response = regenerate(response)
log_trace(response) # 운영 로직
track_cost(response) # 운영 로직
return output_parser(response)
# LangChain 1.0: 사고 구조와 운영 정책이 분리됨
agent = create_agent(graph=design) # 사고 구조
runtime = wrap_with_middleware( # 운영 정책
agent,
governance=[policy_check],
observability=[tracing],
operational=[retry, timeout],
transformation=[schema_validation],
)
def handle_request(user_input):
return runtime.invoke(user_input) # 호출 흐름은 동일3-1-3. LangGraph: Reasoning을 State Machine으로 새롭게 정의
LangGraph는 LLM을 활용한 Stateful Multi-Agent Application 구축을 위한 Orchestration Engine이다.
복잡한 문제는 한 번의 시도(Zero-shot)가 아닌, 반복적 사고와 수정(Loop)을 통해서만 해결 가능하다.
Linear Chain을 넘어, 순환하는 아키텍처가 필요하다.
LangGraph의 핵심 특징:
- Cycles and Branching: Loop를 직접 지원. 에이전트가 스스로 판단하고 작업을 반복/수정하는 Agentic Workflow 구현의 핵심
- Persistence (지속성): 단순히 대화를 기억하는 것을 넘어, 에이전트의 모든 상태(State)를 자동으로 저장. Time Travel: 과거 시점으로 돌아가서 에러를 수정하고 다시 실행 가능
- Human-in-the-Loop: 그래프의 흐름을 일시 정지하고 사람이 승인하거나 데이터를 수정한 후 다시 진행할 수 있는 기능 기본 내장
LangChain 진화 비교:
| 항목 | LangChain (Pre~1.0) | LangChain 1.0 | LangGraph |
|---|---|---|---|
| 설계 철학 | Chain (선형 연결), 단순 조립형 파이프라인 | Standard Agents (표준화), 표준화된 에이전트 규격 | Flow Engineering (흐름 설계), State 기반의 정밀 제어 |
| 흐름 제어 | Linear (단방향), 순차적 처리만 가능 | Managed Loop (관리형 루프), 내장된 루프가 자동 동작 | Cyclic (순환/분기), 개발자가 루프와 조건을 직접 통제 |
| STATE | Stateless, 단발성 실행 후 종료 | Implicit State, 에이전트 내부에서 자동 관리 | Explicit State, Schema로 정의하여 보존 |
| 조건 분기 | Custom 코드 필요, 구현 난이도 높음 | Built-in Logic, 표준 패턴 사용 | Conditional Edge, 흐름 정의로 처리 |
| 디버깅 | Callbacks, 제한적 | LangSmith 연동, 추적 및 모니터링 | Time-Travel, 과거 시점으로 되돌리기 및 수정 |
Agent Architecture = LangChain + LangGraph:
| 역할 | 프레임워크 | 핵심 |
|---|---|---|
| Agent를 정의하는 프레임워크 (설계) | LangChain | Agent = Prompt + Model + Tool |
| Agent를 실행하는 Runtime Engine (실행) | LangGraph | Agent = State + Runtime + Middleware |
3-2. LangGraph 구성 요소: State, Node, Edge
LangGraph의 핵심은 3가지 구성 요소다.
| 구성 요소 | 목적 | 역할 |
|---|---|---|
| Node | 어떤 작업(task)을 수행할지 정의 | 특정 로직 수행 또는 상태 업데이트 (입력으로 현재 상태를 받고, 업데이트된 상태 반환) |
| Edge | 다음으로 실행할 동작 정의 | 워크플로우의 흐름 제어 |
| Conditional Edge | 조건에 따른 분기 처리 | 조건에 따른 흐름 분기, 다음에 실행할 노드 결정 |
| State | 현재의 상태값을 저장 및 전달 | 전체 워크플로우의 흐름 정보 유지, 노드 간 정보 공유 |
3-2-1. State: LangGraph의 기억 저장소
State는 LangGraph 전체 흐름의 기억 저장소이며, 노드 간 연결성과 판단을 위한 핵심 데이터 구조다.
State의 두 가지 핵심 역할:
- 노드와 노드 간에 정보를 전달할 때 State 객체에 담아 전달 → 데이터 공유
- 에이전트가 현재까지 수행한 작업의 결과를 담고, 이후 판단에 기억처럼 사용 → Context 유지, 흐름 유지
State 코드 예시:
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
class GraphState(TypedDict):
question: Annotated[list, add_messages] # 질문 (누적)
context: Annotated[str, "Context"] # 문서 검색 결과
answer: Annotated[str, "Answer"] # 답변
messages: Annotated[list, add_messages] # 메시지 (누적)
relevance: Annotated[str, "Relevance"] # 관련성핵심 개념:
- TypedDict: Python dict에 Type Hinting을 추가한 방식으로 State 구조를 정의
- Reducer (
add_messages): 자동으로 리스트에 메시지를 추가해주는 기능. 여러 데이터를 하나로 합치거나 누적 처리할 때 사용 - State 업데이트 방식:
- 일반 필드: Overwrite (덮어쓰기)
- 메시지 등 리스트 필드: 누적 (Reduce: add_messages)
State Update 동작 방식 (RAG 기반 예시):
NODE 1 (질문 입력) → NODE 2 (문서 검색) → NODE 3 (답변 확인) → NODE 4 (답변 관련성 평가)
context: (없음) context: 문서1 context: 문서1 context: 문서1
question: 질문1 question: 질문1 question: 질문1 question: 질문1
answer: (없음) answer: (없음) answer: 답변1 answer: 답변1
score: (없음) score: (없음) score: (없음) score: BADNODE 4에서 score가 BAD일 경우 선택 가능한 다음 행동:
- NODE 3으로 되돌아가기: 답변 재작성 요청 (프롬프트 조정 또는 다른 LLM 사용)
- NODE 2로 되돌아가기: 문서 재검색 요청 (검색을 통한 정보 보완 또는 검색기 변경)
- NODE 1으로 되돌아가기: 질문 재작성 요청
이것이 바로 Agentic Workflow의 순환 구조가 State를 통해 구현되는 방식이다. State의 값을 보고 다음에 어떤 단계로 이동할지 결정할 수 있다.
State 설계 고려사항 (4가지 원칙):
-
State는 데이터 컨테이너가 아니라 Read/Write Contract
- 노드는 State 전체를 알 필요 없음
- 노드는 자신이 읽고/쓸 KEY만 알아야 함 → State Ownership
- State는 Graph의 공용 API
-
State는 서비스 관점에서도 고려되어야 함
- 이전 값 보존이 필요한가?
- 같은 조건에서 같은 결과를 낼 수 있는가? Trace 가능한가?
- → Overwrite vs append 전략 고려
-
State는 실패를 고려해야 함 (Error-aware)
- Status field: RUNNING, FAILED, SUCCESS
- retry_count, error_message 등
-
State는 확장 가능해야 함
- Optional Field 사용
- Nested 구조 사용
- Evaluation은 dict로 감싸기 등
Production State 설계 예시 (Pseudo Code):
# Nested Structures
class RetrievalResult(TypedDict):
query: str
documents: List[str]
source_ids: List[str]
retrieval_time_ms: float
class GenerationResult(TypedDict, total=False):
draft: str
revised: str
final: str
class EvaluationResult(TypedDict):
relevance: float
groundedness: float
overall: Literal["GOOD", "BAD"]
# Production-level GraphState
class GraphState(TypedDict, total=False):
# --- User Input ---
user_input: str
# --- Conversation (append-only trace) ---
messages: Annotated[List[BaseMessage], add_messages]
# --- Retrieval Layer ---
retrieval: RetrievalResult
# --- Generation Layer ---
generation: GenerationResult
# --- Evaluation Layer ---
evaluation: EvaluationResult
# --- Execution Control ---
status: Literal["RUNNING", "FAILED", "SUCCESS"]
current_node: str
step_count: int # 무한루프 방지
# --- Error Handling ---
error: ErrorInfo3-2-2. Node: LangGraph의 작업 유닛
Node는 LangGraph 내에서 실제로 어떤 행동(작업)을 수행하는 단위로, 각 노드는 하나의 함수로 정의된다.
- State를 입력 받아 결과를 다시 State로 변환
- 내부에서 LLM, API, DB 호출 등 다양한 작업 수행 가능
Node 코드 예시:
def retriever_document(state: GraphState) -> GraphState:
# Question에 대한 문서 검색을 retriever로 수행
retrieved_docs = pdf_retriever.invoke(state["question"])
# 검색된 문서를 context 키에 저장
return GraphState(context=format_docs(retrieved_docs))Pitfalls:
- 반환 값은 반드시 State 객체여야 함
- State 값을 수정할 때 기존 키 이름을 정확히 사용해야 다른 노드에서 활용 가능
- 복잡한 로직을 넣을 경우 디버깅이 어려워지므로 기능은 단순화하는 것이 좋음
- 조건 분기나 외부 연결 로직을 노드 안에 과도하게 포함하지 않도록 주의
3-2-3. Edge: 흐름을 정의하는 연결선
Edge: A 다음에 B와 같이 순서를 연결하는 연결선
Conditional Edge: 상황을 보고 다음 행동을 판단/실행하는 분기 로직
Edge 코드 예시:
# 시작점 정의
workflow.set_entry_point("retrieve")
# Node 연결 (Edge)
workflow.add_edges("retrieve", "llm_answer")
workflow.add_edges("llm_answer", "relevance_check")
# Conditional Edge
workflow.add_conditional_edges(
"relevance_check",
is_relevant,
{
"grounded": END, # 관련성이 있으면 종료
"notGrounded": "llm_answer", # 관련성 없으면 다시 답변 생성
"notSure": "llm_answer", # 모호하면 다시 답변 생성
},
)Pitfalls:
- 조건 분기 함수에서 반환하는 값이 명확히 일치해야 연결이 이어질 수 있음
- 조건 분기/반복 설정 시, exit 조건을 명확히 정의해야 함 → 그렇지 않으면 무한루프 발생 → 토큰 낭비
3-2-4. Node vs Agent: 무엇이 다른가?
| 구분 | Node (어떻게 수행할지) | Agent (무엇을, 언제 수행할지) |
|---|---|---|
| 정의 | 에이전트 시스템 내에서 특정 기능을 수행하는 가장 작은 독립적인 작업 단위 (레고 블록의 개별 조각) | 특정 목표를 달성하기 위해 상황을 이해하고 계획을 수립하고 행동을 실행 (레고 블럭으로 조립된 로봇) |
| 역할 | 단일 기능 수행: 문서 검색, 텍스트 요약, DB 조회, 답변 생성 등. 함수 형태로 정의 | 목표 설정 및 달성, Node Orchestration, 의사결정 |
| 특징 | 주어진 입력에 따라 정의된 작업을 기계적으로 수행 | 동적이고 유연한 동작: 상황과 입력에 따라 실행할 노드의 종류와 순서 변경 |
Node와 Agent의 관계 — 반드시 1:1 맵핑이 아니다:
- [Case 1] Node = Agent: 하나의 Node 안에서 LLM이 프롬프트를 읽고, 도구를 선택하고, 답변까지 생성. (비유: 만능 작업자가 하나의 방에서 모든 업무를 처리)
- [Case 2] 여러 개의 Node = 1개의 Agent: 에이전트의 인지 과정을 여러 노드로 쪼갠 형태 (e.g., Planning Node → Execution Node → Review Node). 쪼개진 여러 노드가 합쳐져서 하나의 에이전트 자아를 구성.
- [Case 3] Node = Tool: 지능(LLM) 없이 코드만 실행되는 노드. Tool을 실행하는 전용 노드나, 단순 텍스트 처리 노드 등. (비유: 사람(Agent) 없이 세척기만 놓여 있는 방)
3-2-5. Tool, Node 그리고 Agent의 비교
| 구분 | Tool | Node | Agent |
|---|---|---|---|
| 목적 | 특정 작업을 수행하는 독립적인 기능 단위 | 워크플로우 내 특정 단계나 처리 과정 담당 | 목표 달성을 위해 동적으로 계획을 수립하고 실행 |
| 구성 | Agent → Tool 호출 (순수 함수, State 모름) | Workflow 내에서 Node 실행 (State를 입력받고 반환) | Agent = LLM + Tools + Memory (Node 내부에 위치하며 실질적 지능 역할) |
| 자율성 | 없음 — 호출 시에만 실행 | 낮음 — 정해진 규칙에 따라 실행 | 높음 — LLM 기반 계획 수립 및 실행 |
| 장점 | 명확하고 예측 가능, 디버깅 용이, 성능 빠름, 비용 효율적 | 워크플로우 재사용성, 체계적 흐름 관리, 병렬 처리 가능 | 유연한 문제 해결, 동적 의사결정 및 실행 |
| 단점 | 단순 작업만 처리, 의사결정 불가 | 모든 경로를 사전에 정의, 예외 상황 처리 제한적 | 예측 불가능성(LLM), 디버깅 어려움, Latency/Cost 높음 |
공장 라인 비유:
- Tool (도구): 전동 드릴, 망치 (스스로 움직일 수 없음)
- Agent (작업자): 도면을 보고 언제 드릴을 사용할지 결정하는 숙련된 인부
- Node (작업장): 공장 컨베이어 벨트 위의 '제 1 조립 구역'
- → 작업자(Agent)는 전동 드릴(Tool)을 들고, 제 1 조립 구역(Node) 안에서 일을 수행합니다.
3-3. LangGraph 설계 패턴
3-3-1. Question-Answer 기본 설계 → Loop → Memory
LangGraph 설계는 단계적으로 복잡성을 추가하는 방식으로 진행된다.
Vanilla 구조:

[추가-1] Query Transform:

[추가-2] 추가 검색기를 통한 문맥(context) 보강:

[추가-3] 최종 답변 유효성 검증:

3-3-2. Loop Design
Loop는 단순히 "몇 번 반복할 것인가"가 아니라, 언제 재진입하고 언제 멈출지를 명확히 설계한 구조다.
Loop Design 전체 구조:
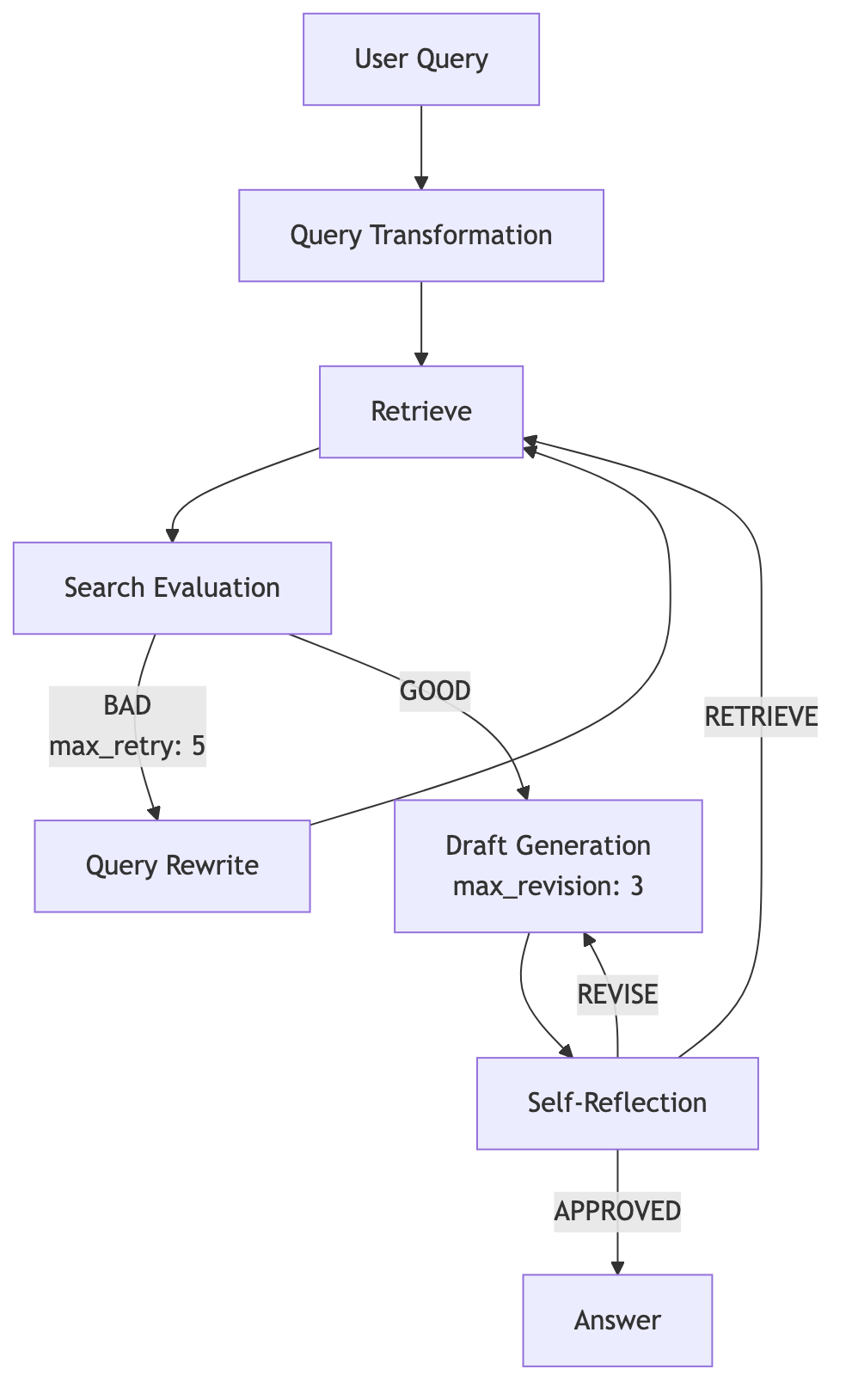
각 Loop 종료 조건:
max_retry: 5— 검색 재시도 최대 5회max_revision: 3— 답변 수정 최대 3회- Verdict: APPROVED / REVISE / RETRIEVE — Self-Reflection의 판단
⚠️ 무한루프 방지는 필수다
Loop 구조에서 종료 조건이 없으면 Agent는 영원히 돌아간다. 반드시 다음을 정의해야 한다:
- Max iteration (최대 반복 횟수)
- 실패 시 fallback 전략
- 비용 초과 시 종료 정책
LangGraph에서는
recursion_limit파라미터로 최대 재귀 횟수를 설정할 수 있다.
3-3-3. + Memory
Memory를 추가하면 이전 대화와 검증된 지식을 다음 실행에 활용할 수 있다.
Memory 추가 구조:
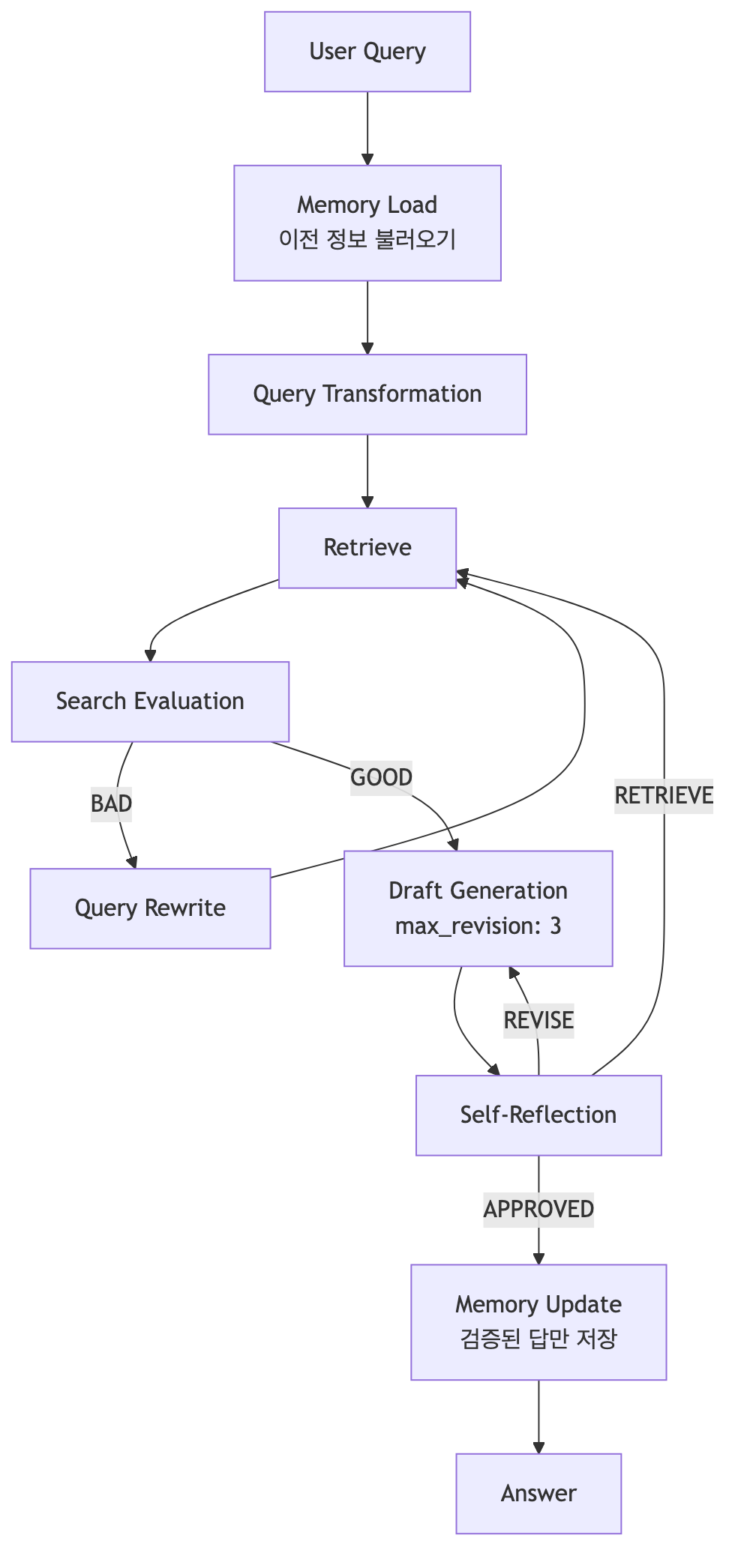
핵심 포인트: "검증된 답만 저장" — 품질이 확인된 정보만 장기 메모리에 저장하여 다음 실행에서 활용한다.
3-3-4. GraphState 설계 (Question-Answer + Memory)
class GraphState(TypedDict, total=False):
# --- User Input ---
user_query: str
# --- Memory Lifecycle ---
loaded_memory: LoadedMemory
memory_update: MemoryUpdate
# --- Conversation (append-only trace) ---
messages: Annotated[List[dict], add_messages]
# --- Retrieval Flow ---
retrieval: RetrievalResult
search_evaluation: SearchEvaluation
# --- Generation Flow ---
generation: GenerationResult
reflection: ReflectionResult
# --- Execution Control ---
control: ExecutionControl # status, step_count, max_retry, max_revision3-3-5. Human-in-the-Loop (HITL)
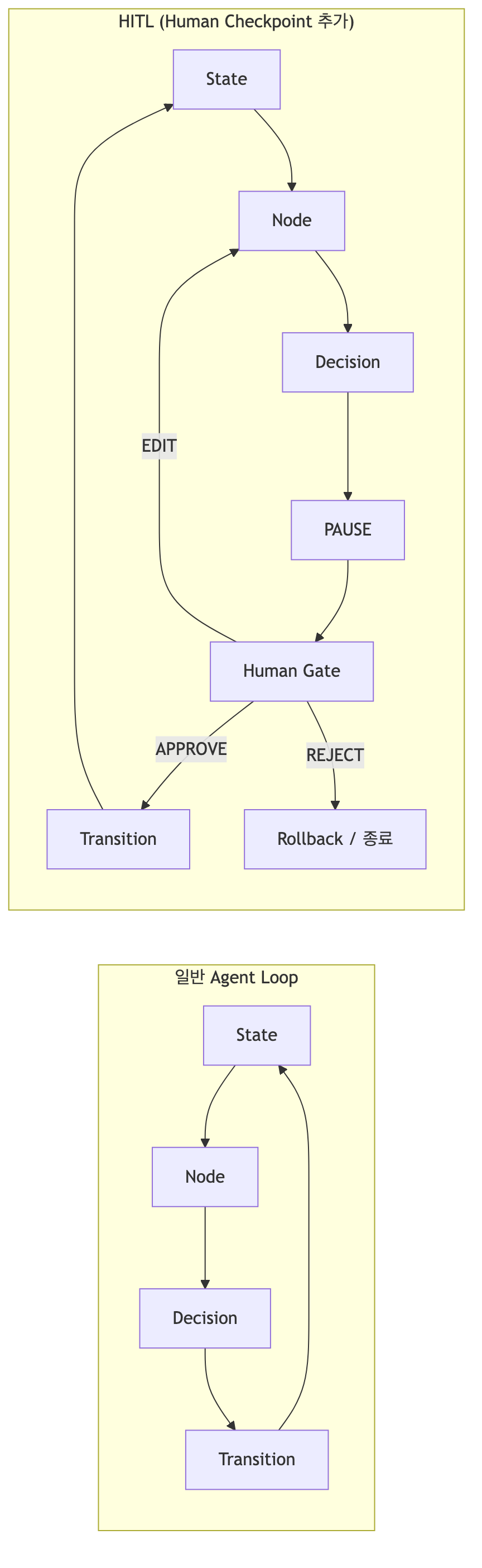
Human을 State Machine의 Transition 조건으로 녹여넣는 구조
Human-in-the-Loop는 "사람이 중간에 끼어드는 것"이 아니라, 사람이 State Machine의 일부 Transition 조건에 참여하는 행위자로 설계되는 개념이다.
일반 Agent Loop vs HITL:
HITL Pseudo Code:
agent = create_agent(
model="gpt-4.1",
tools=[write_file_tool, execute_sql_tool, read_data_tool],
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"write_file": True, # 모든 결정 허용 (approve, edit, reject)
"execute_sql": {"allowed_decisions": ["approve", "reject"]}, # edit 불가
"read_data": False, # 안전한 작업이므로 승인 불필요
},
description_prefix="Tool execution pending approval",
),
],
checkpointer=InMemorySaver(), # HITL에는 Checkpointing 필수
)중요한 설계 원칙:
- HITL은 Agent 내부가 아니라 Middleware로 선언됨 (Middleware는 LLM 호출 시점에 개입)
interrupt_on: 개입 지점 정의 — HITL은 전역 멈춤 기능이 아님. 특정 Tool/행동에 선택적으로 적용됨allowed_decisions: Human 권한 설계 → UX 제어가 아니라 아키텍처 설계- Pause/Resume = Checkpoint 기반: Checkpoint는 단순 대화 메모리가 아니라 실행 상태(State Snapshot) 저장 장치
💡 HITL 설계 시 핵심 질문들
- 어느 단계에서 사람이 개입해야 하는가? — 고위험 작업(파일 쓰기, SQL 실행 등)에만 선택적 적용
- 어떤 결정 권한을 줄 것인가? — APPROVE만? EDIT도? REJECT도? → 각각의 결과가 다르므로 UX가 아닌 아키텍처 관점에서 설계
- Checkpoint는 어디에 저장할 것인가? — 개발 시에는 InMemorySaver, 프로덕션에서는 AsyncPostgresSaver 등 영속적 저장소 사용
3-4. Parallel Execution: 병렬 처리
3-4-1. 개념
단일 에이전트가 여러 작업을 순차적으로 처리하면 응답이 느리고 비효율적이다. 특히 LLM 기반 시스템에서는 Latency가 누적되어 전체 응답 시간이 길어진다.
병렬 처리: 여러 작업(또는 여러 에이전트)을 동시에 실행하여 전체 처리 시간을 단축하고 시스템의 처리 효율을 높이는 방식 → 품질보다 효율 개선이 목적
주요 유형:
- Task-level Parallel: 하나의 에이전트가 여러 Task를 동시에 실행. 예: 같은 문서를 요약+키워드추출+번역 업무를 동시 실행
- Agent-level Parallel: 여러 에이전트가 독립적으로 병렬 실행 후 결과 통합. 예: [재무분석 – 마케팅분석 – 기술평가] → 리포트 작성 에이전트
3-4-2. 설계 패턴
Fan-out, Fan-in 패턴
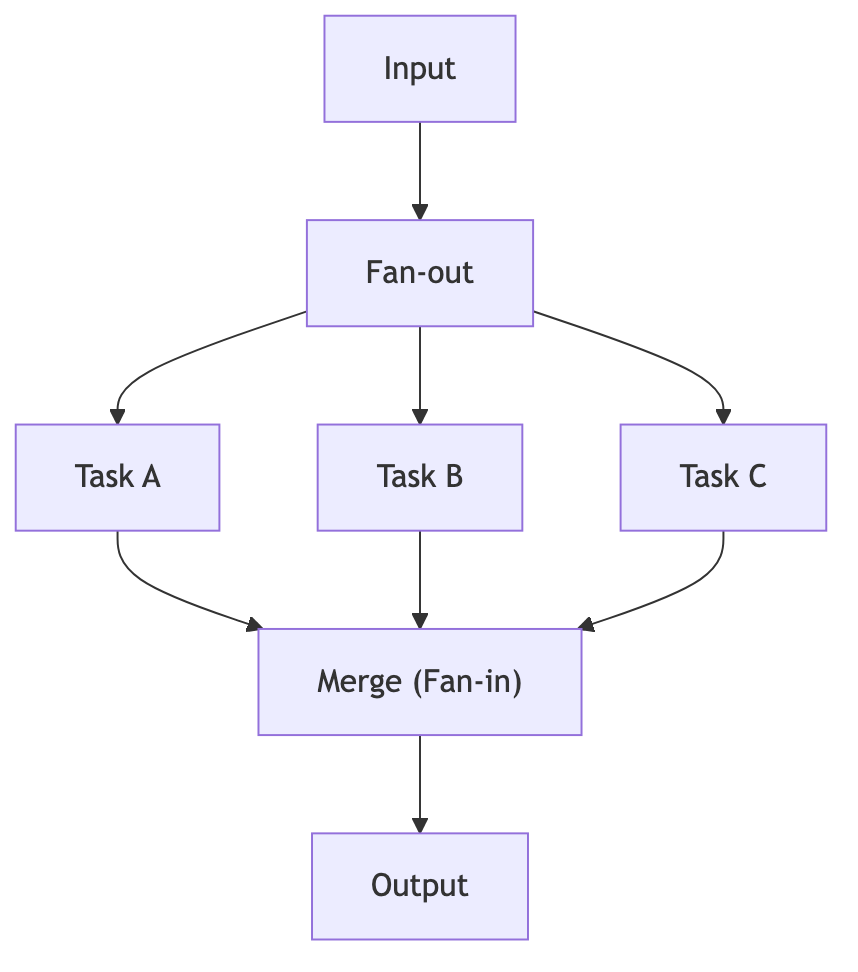
- Fan-out: 상위 노드/에이전트가 여러 하위 작업을 동시에 분기시켜 실행
- Fan-in: 분기된 작업들의 결과를 하나로 모아 통합하는 단계
Map-Reduce 패턴

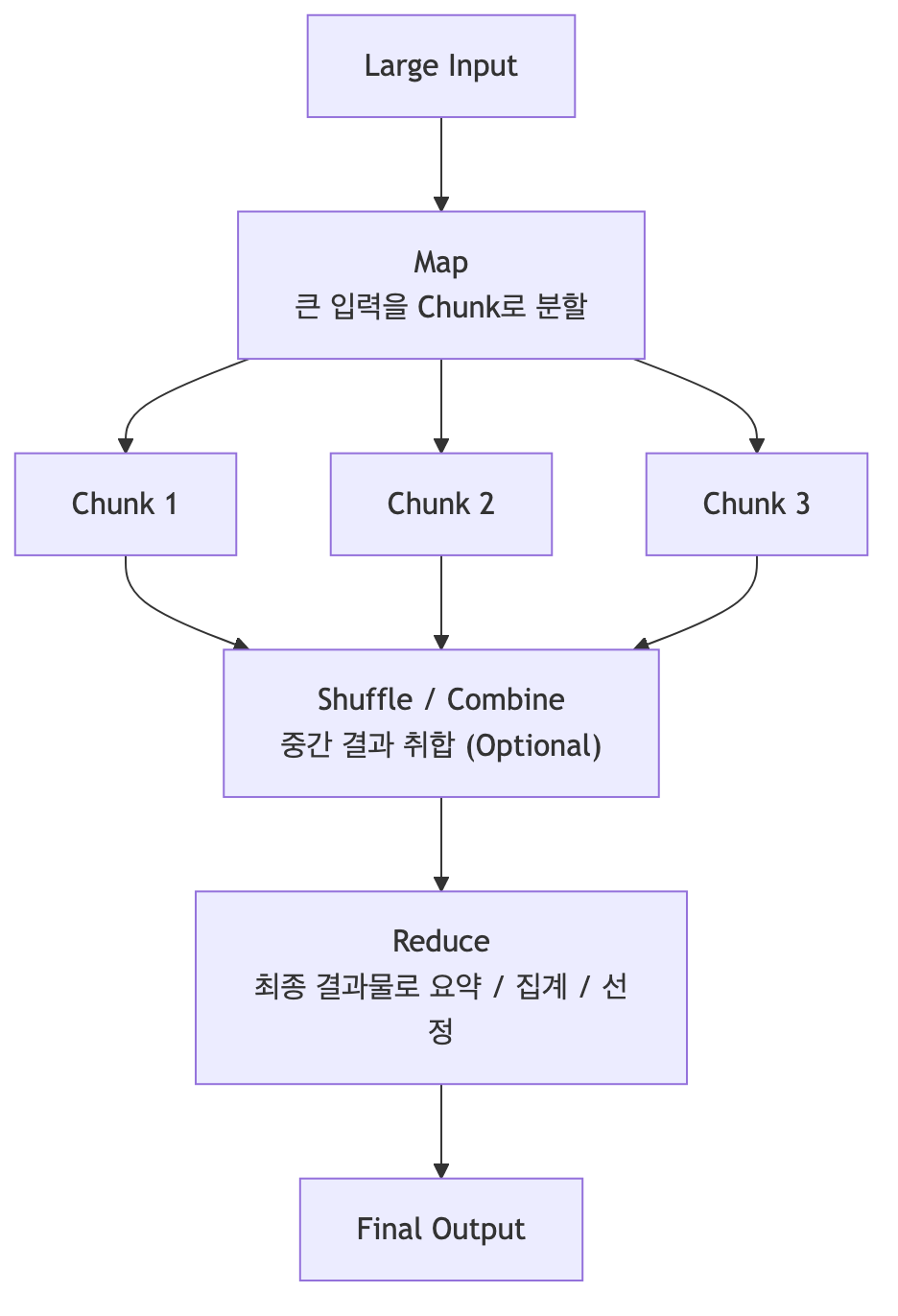
- Map: 큰 입력을 작은 조각(Chunk)으로 나누어 병렬 처리
- Shuffle/Combine: (Optional) 중간 결과 취합 (재배열, 부분 결합 등)
- Reduce: 중간 결과를 최종 결과물로 요약/집계/선정
3-4-3. 설계 고려사항
Fan-out/Fan-in 고려사항:
- 입력 스키마 통일: 하위 작업이 공통 입력을 받을 수 있도록
- 출력 스키마 표준화: Fan-in에서 쉽게 합쳐지도록 각 작업의 출력 형식을 Pydantic 형태로 표준화 (Key/Type)
- 오류 처리: 하위 작업 중 하나라도 실패해도 전체 수행에 무리가 없도록 기본값/폴백 적용
- 중복 처리: 서로 동일 또는 유사 계산이 병렬로 처리될 수 있음. 중복 기능 여부를 검토하거나, 캐시 기반으로 설계 고려
- 동시성 제어: 외부 API 호출 한도를 고려하여 동시 실행 건수 제한
- 결과 통합 전략: 단순 결합, 가중치 앙상블, 신뢰도 기반 선택, 품질 검증 등
Map-Reduce Reduce 전략:
- 계층적 요약: chunk → section → document
- 랭킹/가중치 기반: 유사도 기반 상위 K개 Chunk만 채택
- 근거 추적(citation) 기반: 신뢰성 확보
3-4-4. Fan-out 구현 (LangGraph)
# LangGraph에서의 Fan-out 구현 핵심
class ParallelState(TypedDict, total=False):
input: str
result_a: str # 부분 업데이트를 허용하는 타입 정의
result_b: str
result_c: str
final_result: str
# 동일한 upstream 노드를 가진 downstream 노드를 자동 병렬 실행
builder.add_edge("fan_out_start", "task_a")
builder.add_edge("fan_out_start", "task_b")
builder.add_edge("fan_out_start", "task_c")
# 모든 upstream 노드가 완료되어야 fan_in 실행
builder.add_edge(["task_a", "task_b", "task_c"], "fan_in")핵심 요약
LangChain에서 LangGraph로의 진화는 "사고 구조"와 "운영 정책"을 분리하고, 추론 흐름을 State Machine으로 표현하면서 순환과 분기를 가능하게 만든 과정이다. State는 노드 간 데이터 공유 계약이고, Node는 작업 단위, Edge는 흐름 결정이다. 실제 시스템은 단순 Q&A에서 Loop → Memory → HITL 순으로 복잡성을 쌓으며, HITL은 사람이 State Machine의 전환 조건 자체로 녹아드는 구조라 Checkpoint 설계가 필수다.
