Accent · Prosody · Emotion · Duration 정리
예전에 읽었던(2024년도) VC/TTS에서의 Accent / Prosody / Emotion / Duration modeling을 정리하고자 한다.
정리가 덜 돼서 뒤죽박죽...
Feature를 어떻게 정의하고 모델링할 것인가?
우선 가장 근본적으로 f0, duration, energy, prosody 등을
어떻게 정의하고, 어떻게 모델링할 것인가?
단순히 predictor를 붙이는 것이 아니라,
- feature 자체를 정제해서 GT로 사용할 것인지
- latent space에서 disentangle해서 사용할 것인지
- diffusion/flow 기반 generator에서 implicit하게 학습할 것인지
이 선택에 따라 모델 구조가 완전히 달라진다.
duration 관련해서...
1) DurFlex-EVC + Stylebook 결합 가능성
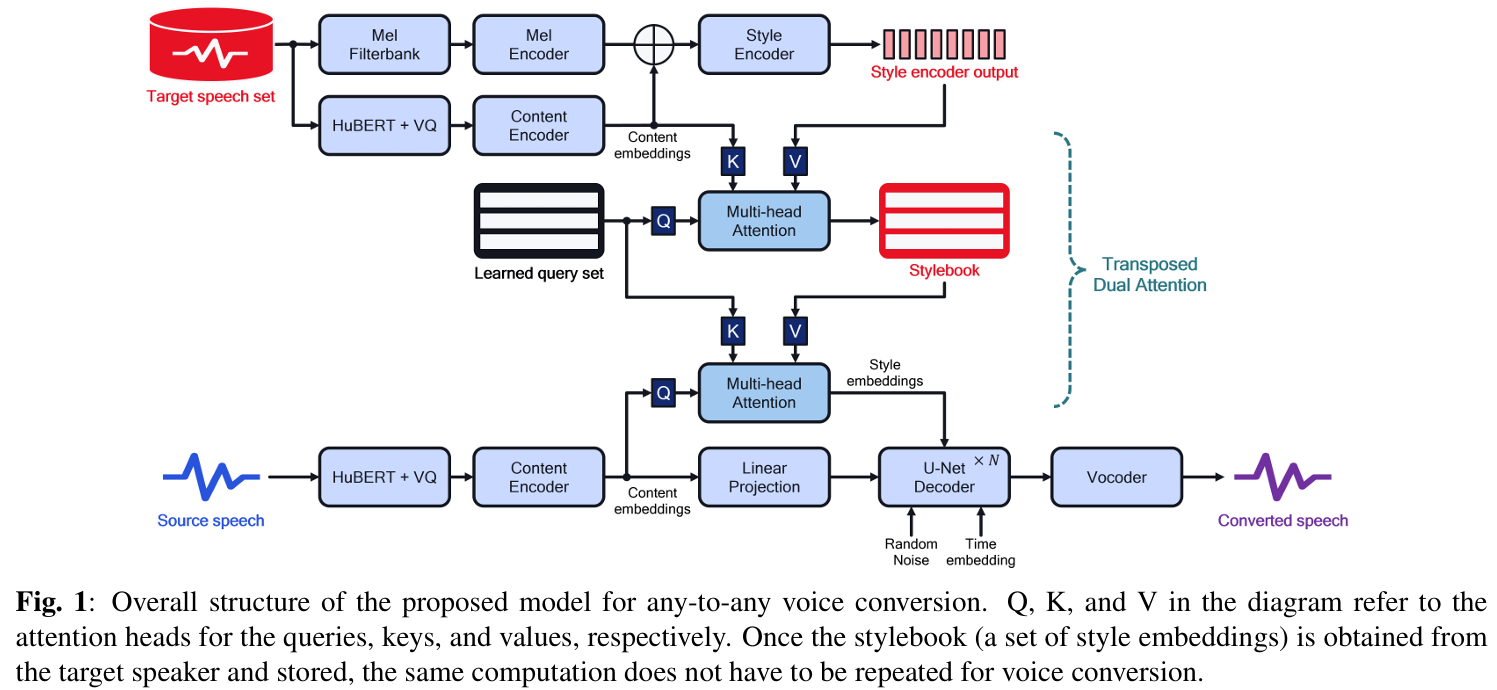
- stylebook(https://arxiv.org/abs/2309.02730) + DurFlex-EVC
DurFlex-EVC에서는 duration modeling을 위해 cross-attention을 사용한다.
하지만 key, query, value를 target speaker에서 직접 받아오지는 않는다.
Stylebook의 Dual Attention 구조에서 나온 key, value를
duration attention에 활용할 수 없을까?
- Stylebook: content-dependent speaking style modeling
- DurFlex-EVC: duration-flexible emotional VC
만약 Stylebook에서 style-aware key/value를 만든 뒤
이를 duration modeling에 활용한다면,
→ 단순 alignment가 아니라
→ style-dependent duration modeling이 가능하지 않을까?
2) Multi-scale duration modeling
duration은 단일 스케일로 보기 어렵다.
- utterance-level rhythm
- word-level timing
- phoneme-level duration
- frame-level alignment
Multi-scale 구조를 두고, - coarse rhythm은 global embedding으로
- fine duration은 diffusion 기반 predictor로
나누어 modeling하는 구조도 가능해 보인다
3) Voice Conversion에서 Semantic 정보 활용 가능할까?
TTS는 text가 있으니 semantic 정보를 쉽게 활용할 수 있다.
하지만 VC는 text가 없다.
그렇다면:
- ASR 기반 PPG
- wav2vec2 one-hot text prediction
- Sentence-BERT embedding
같은 semantic proxy를 활용할 수 있을까?
특히 emphasis modeling에서는
semantic importance가 중요하기 때문에,
VC에서도 semantic-aware prosody modeling이 가능하지 않을까?
4) 문장 내 Emphasis는 어떻게 결정되는가?
우리가 문장을 읽을 때:
- 중요한 단어는 강세를 두고
- 덜 중요한 단어는 빠르게 약하게 발음한다
이를 모델링하려면? - attention 기반 weighting
- Sentence-BERT + multi-head attention
- HyperSum 같은 importance estimation 모델
semantic importance → prosody modulation
이라는 경로를 만들 수 있을 것 같다.
5) Accent Discriminator 확장 가능성
Voice-Preserving Zero-Shot Multiple Accent Conversion에서는
accent discriminator가 native vs foreign을 구분한다.
그렇다면,
source vs target style discriminator가 있다면
학습 안정성이나 disentanglement에 도움이 될까?
Domain adversarial training 구조로 확장 가능해 보인다.
6) Diffusion-based Duration Predictor에 Reference Condition 주기
diffusion duration predictor를 만들 경우,
- target reference의 rhythm
- speaking rate
- emotional tempo
를 condition으로 넣으려면 어떻게 설계해야 할까?
가능한 방법: - conditional noise schedule
- cross-attention conditioning
- global rhythm embedding injection
Accent
Accent-TTS
pronounciation input으로 G2P 사용
논문제목 : Accent-VITS: accent transfer for end-to-end TTS(National Conference on Man-Machine Speech Communication, NCMMSC 2023)
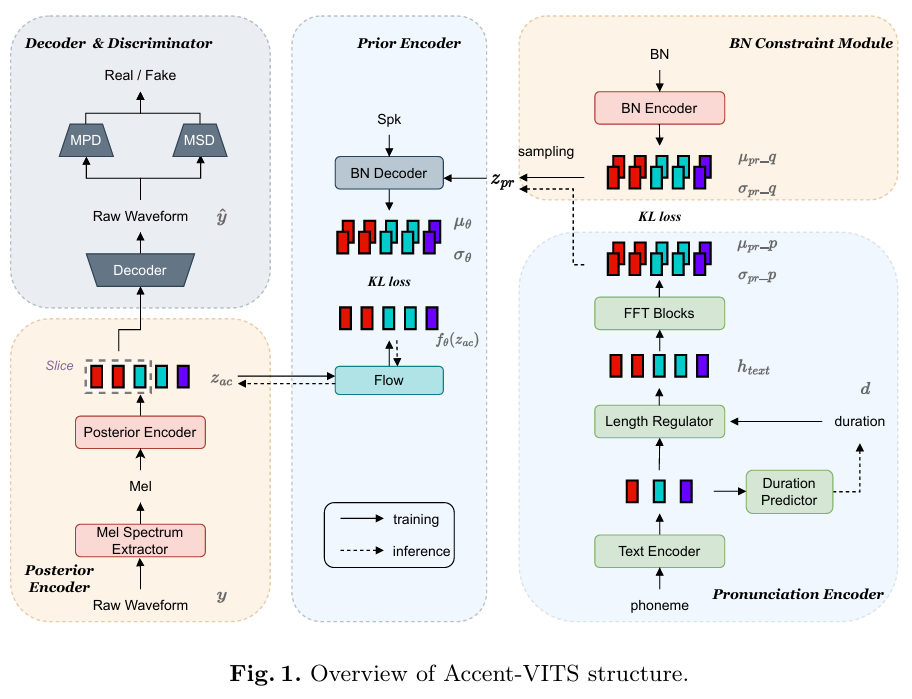
- 해결해고자한 부분 : accent(phoneme pronunciation pattern and prosody variations) 을 반영하고자 함
- method : hierarchical CVAE structure to model accent pronunciation information and acoustic features, respectively, using bottleneck features and mel spectrums as constraints.
Moreover, the text-to-wave mapping in VITS is decomposed into textto-accent and accent-to-wave mappings in Accent-VITS.
LR은 일반적 Fastspeech, 하지만 phoneme 단위로 duration predict
발음 인코더 모듈은 첫 번째 CVAE 구조의 사전 정규화 항에 사용되는 사전 분포를 예측
phoneme은 G2P 사용
Accent-VC
ppg를 input으로 사용
논문제목 : Voice-Preserving Zero-Shot Multiple Accent Conversion (ICASSP 2023)
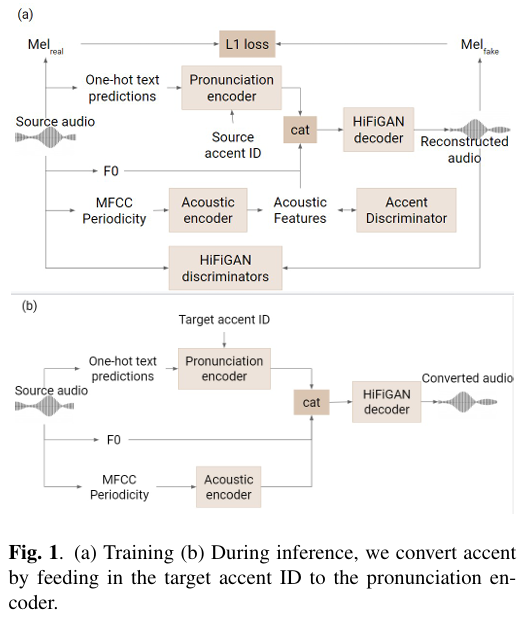
- method
one-hot text prediction(wav2vec2)
pronunciation 에 acoustic feature를 더하고 나면 native or foreign 으로 label 되어 있는 accent discriminator 사용
Prosody
Prosody - TTS
논문제목 : IST-TTS: Interpretable Style Transfer for Text-to-Speech with ControlVAE and Diffusion Bridge(interspeech 2023)
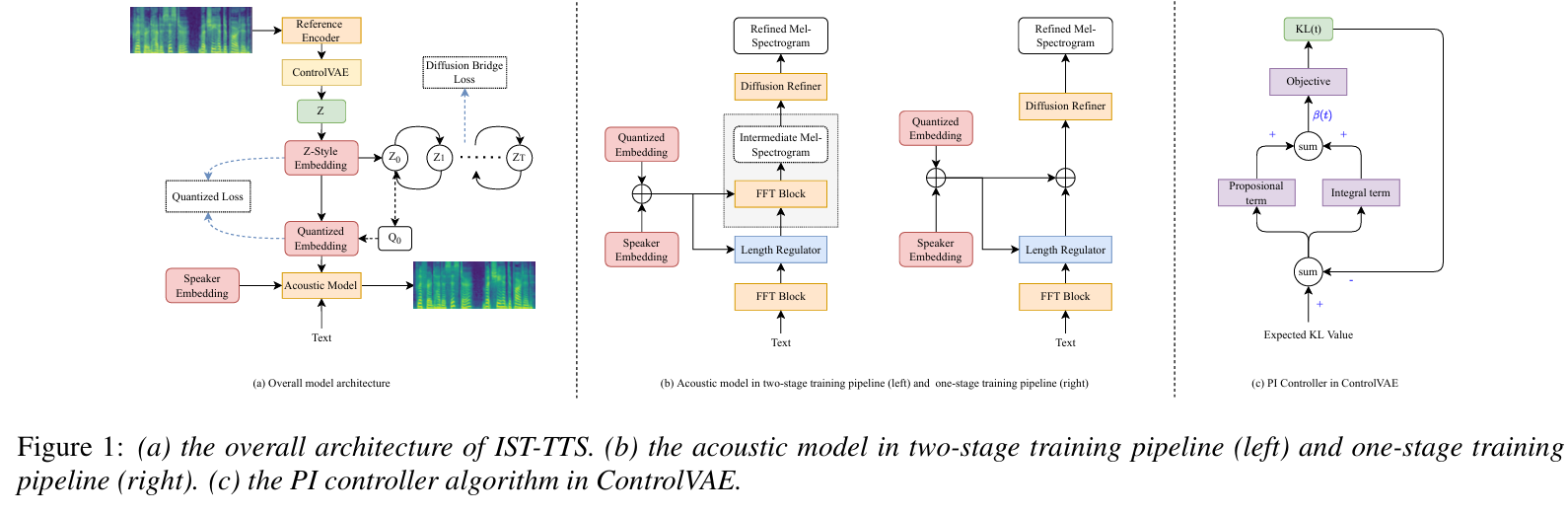
- 해결해고자한 부분
- method
(1) diffusion refiner, (2) diffusion bridge, and (3) ControlVAE.
reference encoder에서 style vector 뽑아냄
acoustic feature는 fastspeech base
mel만 reference encoder에 들어감
ParallelStyleTransfer / Non-ParallelStyleTransfer 나눠서 MOS 평가
논문제목 : M2-CTTS: End-to-End Multi-scale Multi-modal Conversational Text-to-Speech Synthesis(ICASSP 2023)
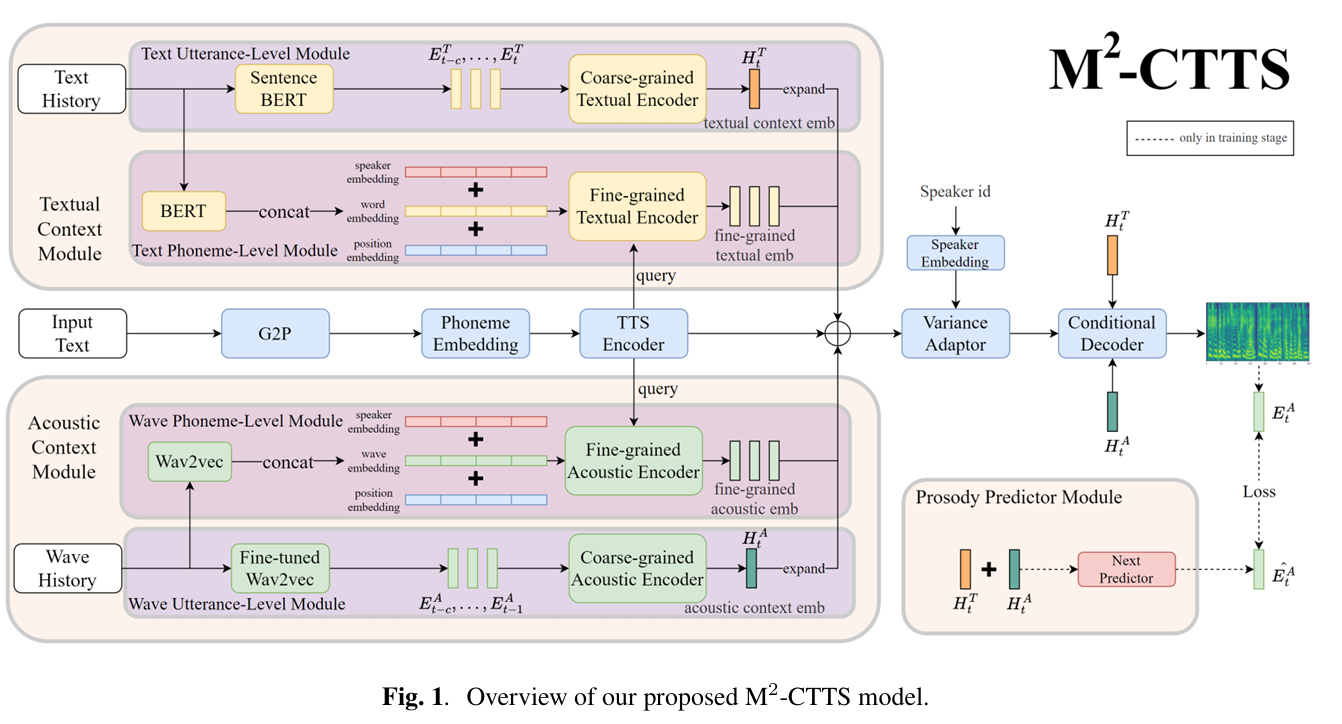
- method : diffusion based prosody predictor
1) local prosody를 잘 만들어내고자 함 : 보통 utterance(coarse-grained), phoneme(fine-grained) level로 embedding을 뽑고 여기에 speaker embedding을 뽑아서 사용함.
2) Sentence BERT에서 feature + attention : semantic information을 담고 있기 때문에 multi-head attention 을 통해 keyword, emphasis한 부분을 알아내고 이를 prosody modeling에 활용 (보통 우리가 문장을 읽을 때 중요한 부분에 강세를 두고, 필요하지 않은 부분은 빠르고 약하게 발음하는 것 등을 반영하고자 하는 것 같음)
--> 사실 semantic 정보가 반영된 상황에서 word level 이 얼마나 도움될까 싶지만 시도해보는 것은 나쁘지 않을 것 같다.
3) acoustic / textual 정보를 사용함 : text에서도 utterance/phoneme feature 뽑아 사용하고, acoustic에서도 utterance/phoneme feature 뽑아 사용함.
4) flow, ddpm 등 최근 모델들을 써서 prosody predictor를 설계함 : 성능 향상, 다양한 prosody 생성에 도움이 된다고 함.
Prosody - VC
논문제목 : MSM-VC: High-Fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-Scale Style Modeling(ACM 2023)
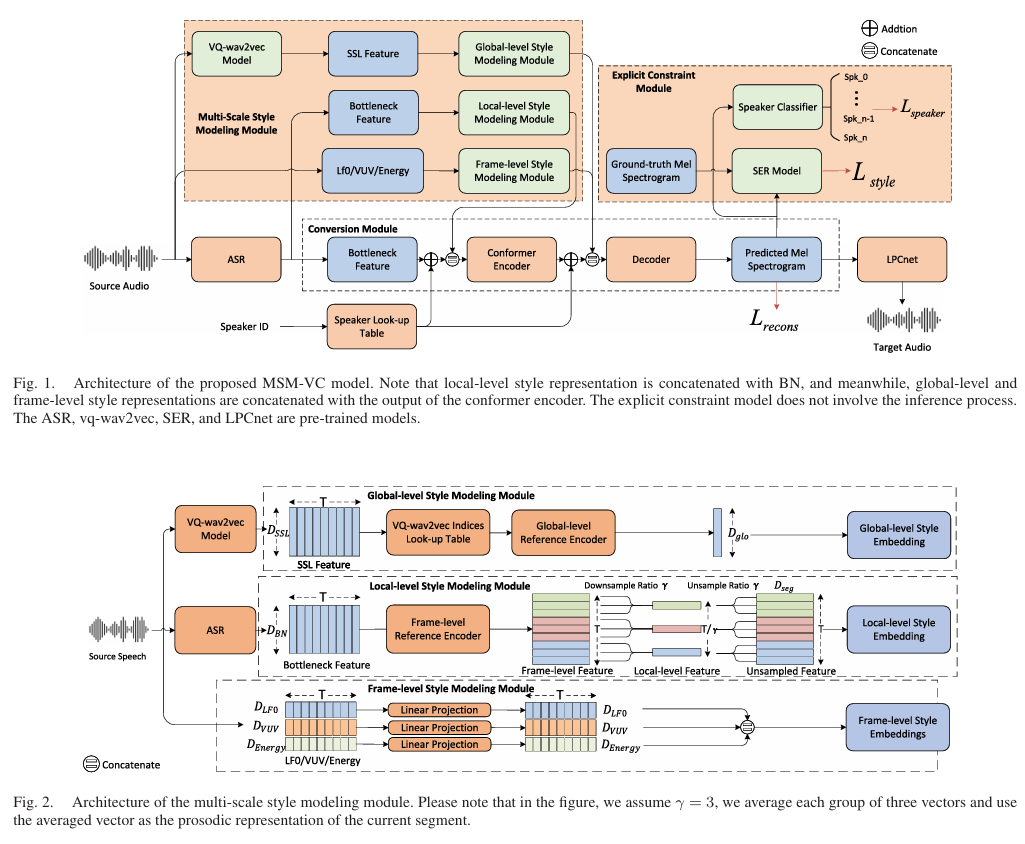
논문제목 : Stylebook: Content-Dependent Speaking Style Modeling for Any-to-Any Voice Conversion using Only Speech Data(아카이브?)
Emotion
1) 얘도 local prosody를 잘 만들고자 함 : 보통 utterance/phoneme level로 나누어짐
Emotion - TTS
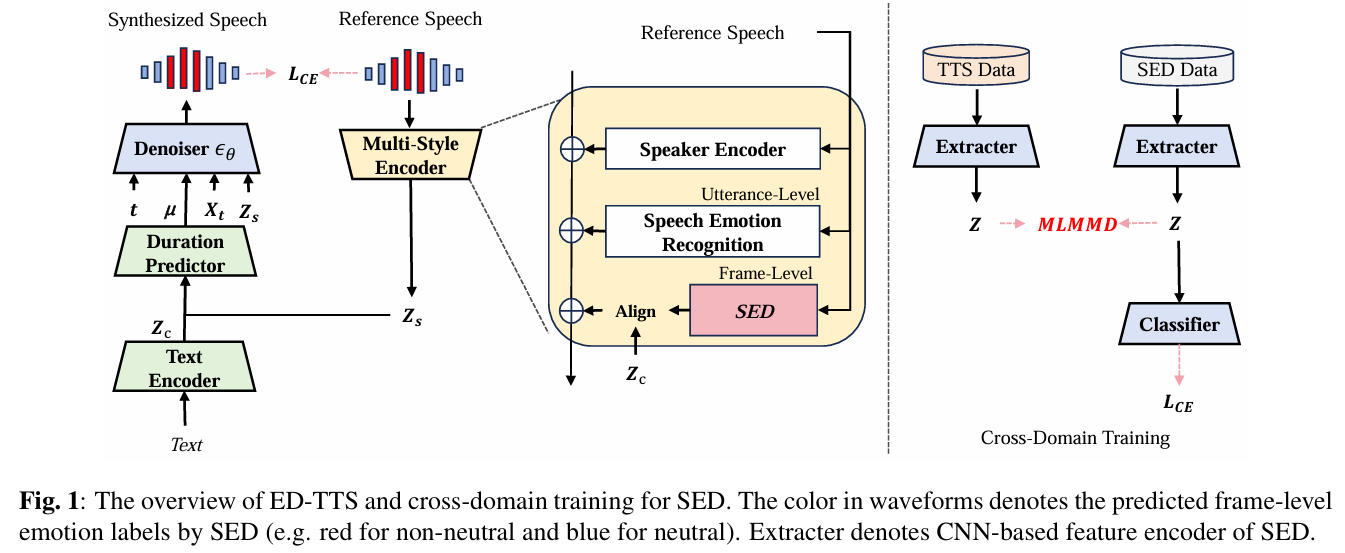
논문제목 : ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis(ICASSP 2024)
논문제목 : ZET-Speech: Zero-shot adaptive Emotion-controllable Text-to-Speech Synthesis with Diffusion and Style-based Models(Interspeech 2023)
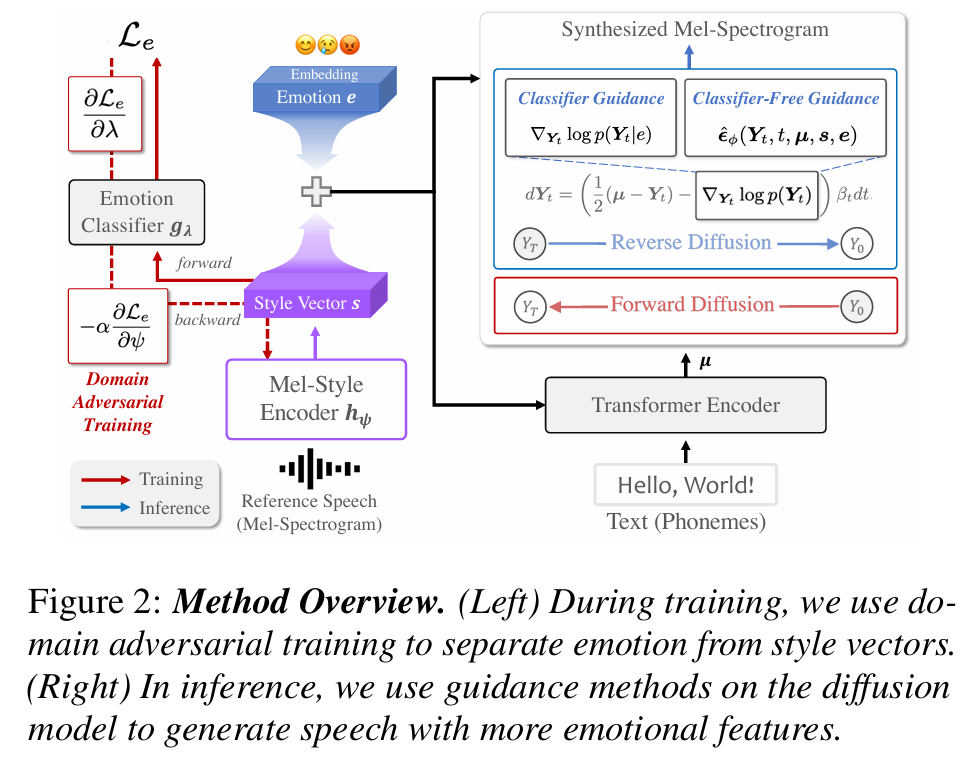
- 해결해고자한 부분 : zero shot Emotional TTS를 만들자
- method : Domain adversarial training, guidance method
보통 스타일벡터에 감정 벡터를 더해서 디코더로 보냄 그러나 이러면 화자저보와 감정 정보가 모두 포함되어 있어서 DAT를 통해 reference의 감정 정보를 스타일 벡터에서 분리하고자 함(스타일 벡터가 특정 화자의 음성 스타일을 나타내면서도, 감정 정보는 포함하지 않도록 하는 것) - Emotion classifier의 Gradient Reversal Layer 방법 이용
Emotion - VC
논문제목 : Nonparallel Emotional Voice Conversion For Unseen Speaker-Emotion Pairs Using Dual Domain Adversarial Network & Virtual Domain Pairing(ICASSP 2023)
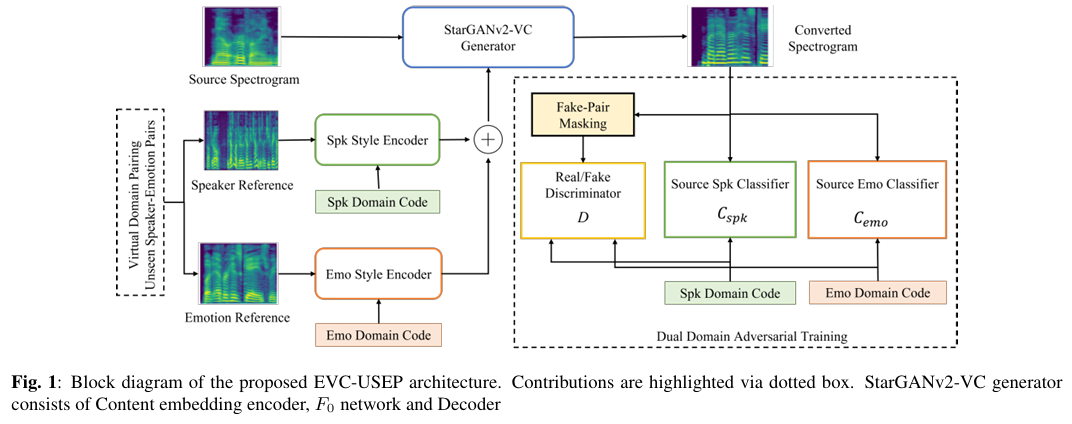
- method : (baseline: gradTTS)
EmoDiff는 classifier guidance <-- rhythm을 guidance 할 때 응용할 수 있나?
< Overall of ED-TTS >
DDPM 기반의 multi-scale emotional TTS model로써 utterance-level SER(speech emotion recognition)과 frame-level SED(Speech emotion diarization)를 활용하여, emotion의 category와 variation/boundary를 각각 identify
SED model을 통해 frame-level fine-grained emotion label을 예측하여 TTS model training을 supervise
논문제목 : DurFlex-EVC: Duration-Flexible Emotional Voice Conversion with Parallel Generation(아카이브)
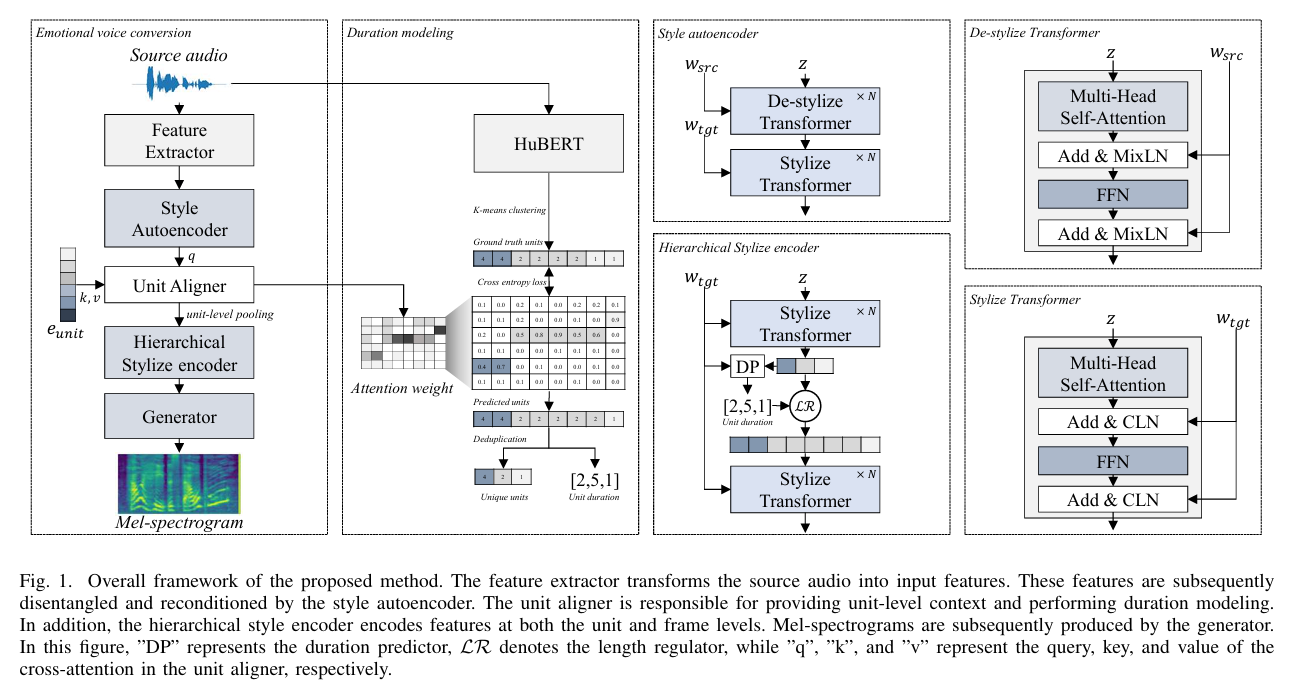
- method : attention 사용
Development of a style autoencoder to enhance style control through decomposition and reassembly of styles. --> MixLM으로 style 제거, CLM으로 style 추가 (emotion 없애고 emotion 추가한다는 의미)
Creation of a unit aligner to model unit durations and generate unit-level context vectors. --> kqv 로 duration attention weight로 활용
1) A feature extractor that adeptly transforms raw audio waveforms into finely processed features.
2) A style autoencoder, facilitating the decomposition of content and style.
3) A unit aligner, responsible for context transformation and meticulous duration modeling.
4) A hierarchical stylization encoder, operating at both unit and frame levels for nuanced stylization.
5) A diffusion-based generator, engineered for the generation of high-quality Mel-spectrograms.
The unit aligner then aggregates contextual information at the frame level through a cross-attention module.
z = input vector to be normalized (hubert features 말하는건가?)
w=original style vector
tilda w = shuffled style vectores
r, b = adaptive parameters
s = speaker vectore (embedding lookup table)
e = emotion vector (embedding lookup table)
Q : output of the style autoencoder
K : learnable embeddings
V : learnable embeddings
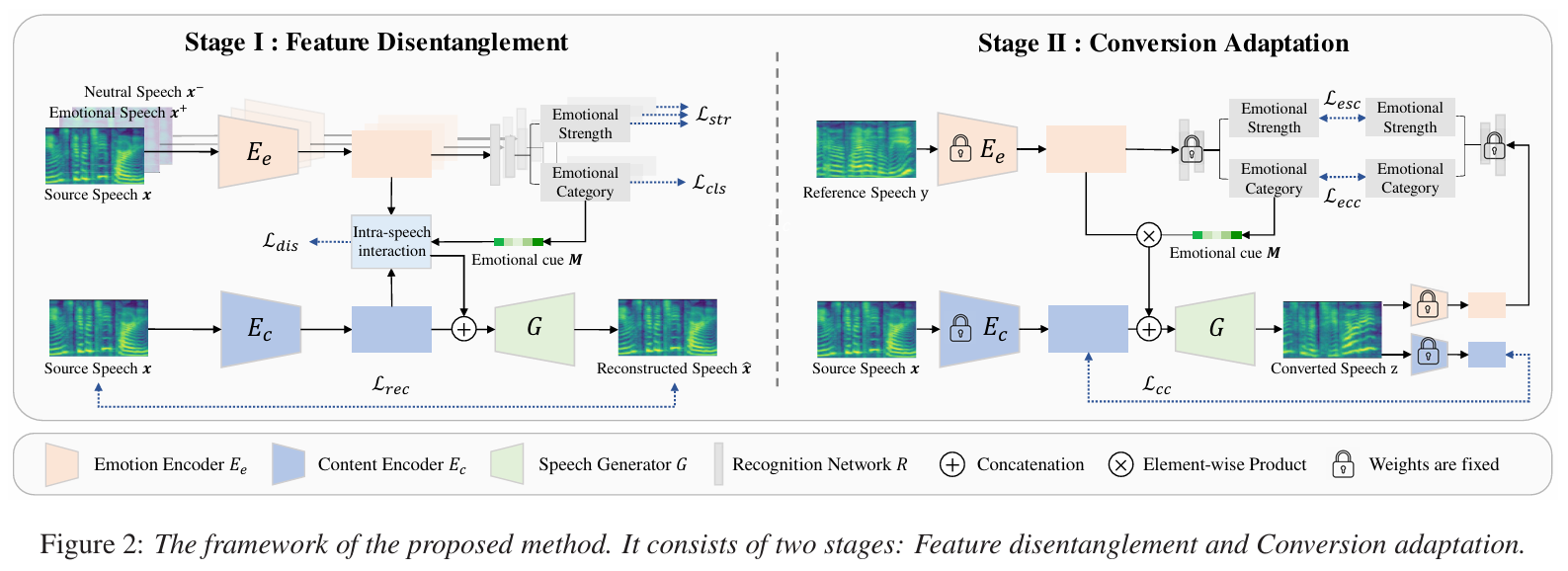
논문제목 : Attention-based Interactive Disentangling Network for Instance-level Emotional Voice Conversion(Interspeech 2023)
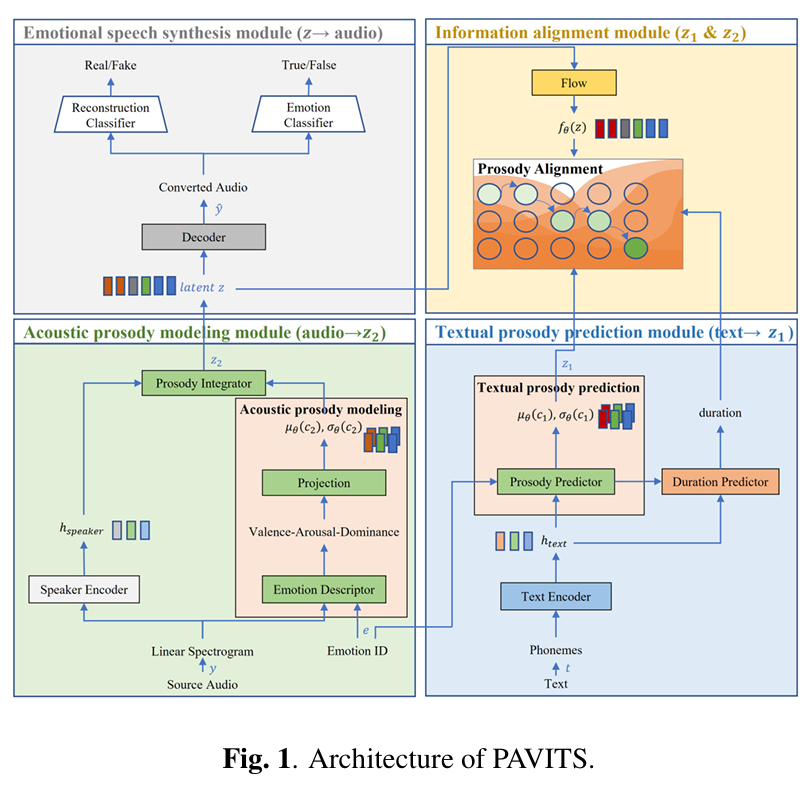
논문제목 : PAVITS: Exploring Prosody-Aware VITS for End-to-End Emotional Voice Conversion(ICASSP2024)
Duration
Duration - TTS
1) 크게 두 방식으로 나눠짐 : glowTTS의 MAS(GT=dynamic programming alignment) & FastSpeech의 duration predictor + LR(GT=MFA)
논문제목 : DurIAN: Duration informed attention net work for speech synthesis(Interspeech 2020)
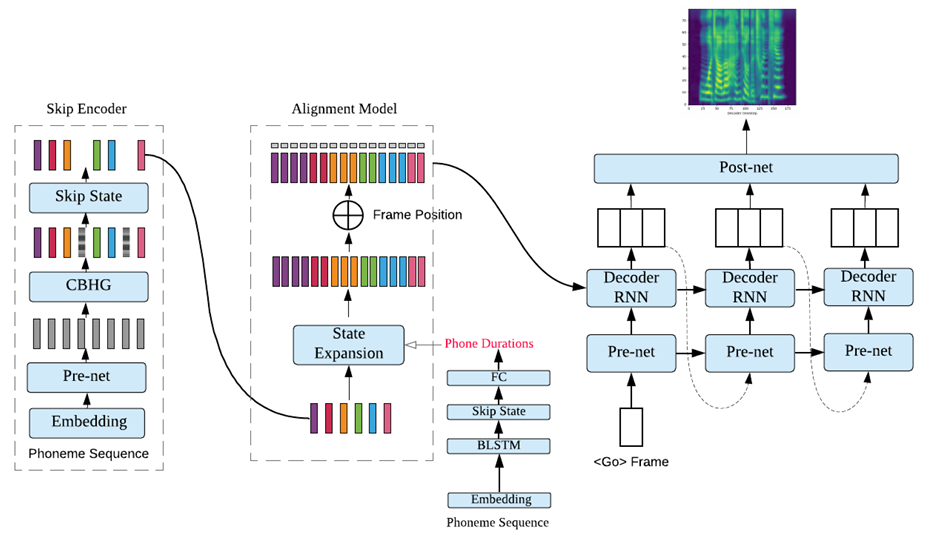
논문제목 : DurIAN-E: Duration Informed Attention Network For Expressive Text-to-Speech Synthesis(아카이브?)
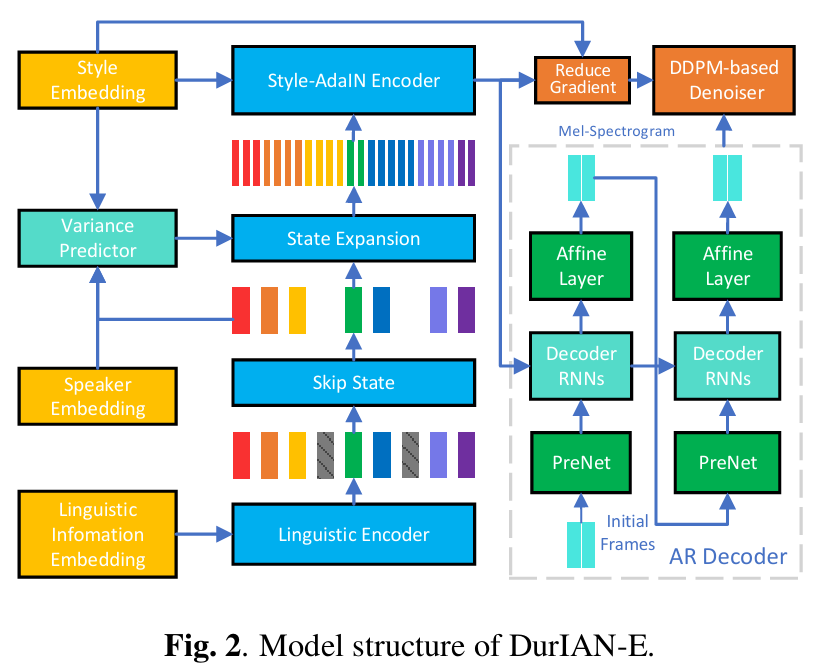
- method : AdaIN으로 Speaker에 따라 duration 조절
multi-speaker나 zero-shot으로 확장한건가?
1) the proposed DurIAN-E uti lizes multiple stacked SwishRNN-based Transformer blocks as linguistic encoders.
2) Style-Adaptive Instance Normaliza tion (SAIN) layers are exploited into frame-level encoders to improve the modeling ability of expressiveness.
3) A denoiser incorporating both denoising diffusion probabilistic model (DDPM) for mel-spectrograms and SAIN modules is con ducted to further improve the synthetic speech quality and expressiveness
At present, there are two main stream approaches to model the speaking style information: one uses pre-defined categorical style labels as the global control condition of TTS systems to denote different speak ing styles [5, 6] and the other imitates the speaking style given a reference speech [7, 8].
variance predictors -> FastSpeech2 논문에서 가져옴 : phoneme-level duration, pitch, pitch range predictors가 있음, ground truth 값은 training 때 inputs으로 사용되고 variance predictor를 학습시키는데도 사용됨. inference 단계에서는 predictor에서 예측한 값 사용
Duration - VC
attention 사용
논문제목 : DurFlex-EVC: Duration-Flexible Emotional Voice Conversion with Parallel Generation(아카이브)
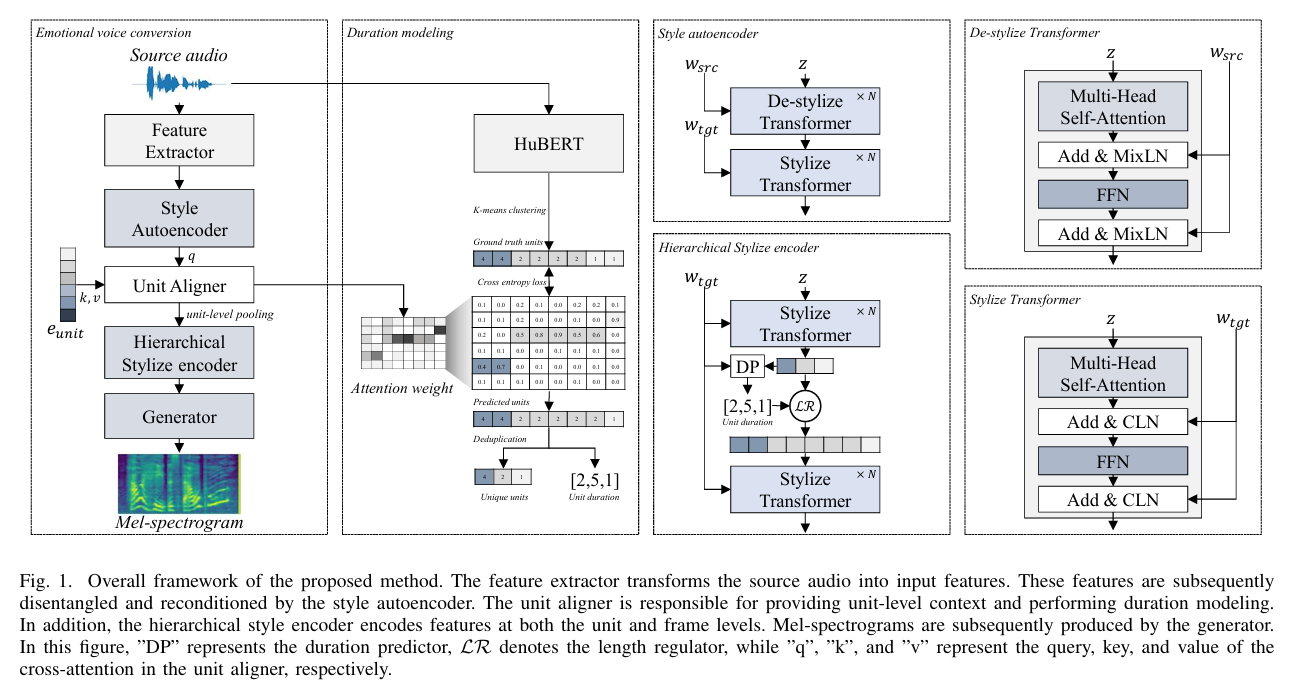
- 해결해고자한 부분 : parallel 모델에서 duration control 하는 것
- method : MixLN으로 style 제거, CLN으로 style 추가, kqv 로 duration attention weight로 활용
논문제목 : Duration Controllable Voice Conversion via Phoneme-Based Information Bottleneck(2022 ACM)
논문제목 : DuTa-VC: A Duration-aware Typical-to-atypical Voice Conversion Approach with Diffusion Probabilistic Model(Interspeech 2023)
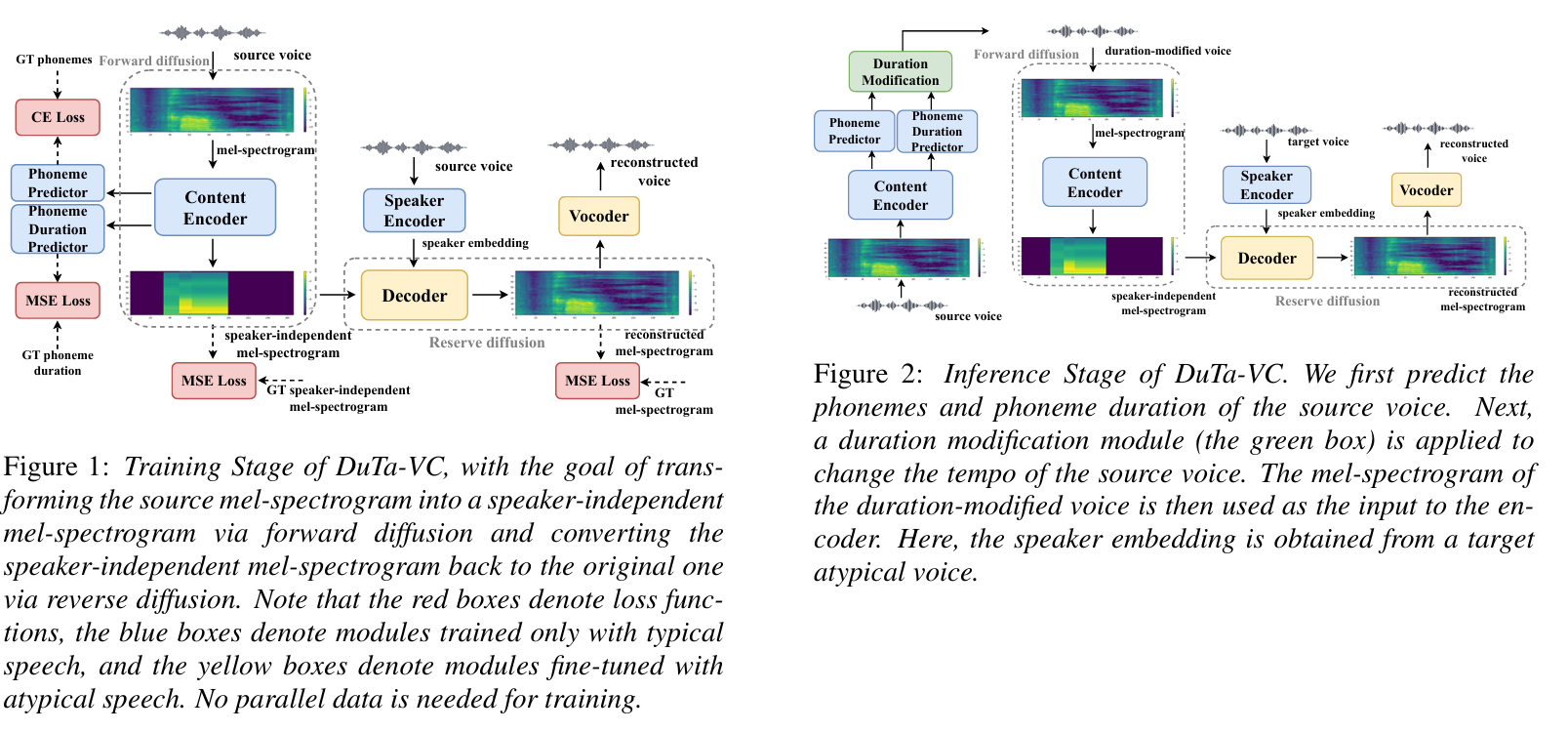
+)
Urhythmic(rhythm modeling for voice conversion) 은 hubert feature에서 duration을 예측해서 hubert feature를 interpolation 해주는 방식으로 진행
AutoPST : “Global rhythm style transfer without text transcriptions,” in ICML, 2021.
UnsupSeg : “Investigation into target speaking rate adaptation for voice conversion,” in Interspeech, 2022.
DISSC : “Speaking style conversion with discrete self supervised units,” arXiv preprint arXiv:2212.09730, 2022
