GLASS Flows: Transition Sampling for Alignment of Flow and Diffusion Models
https://arxiv.org/abs/2509.25170
생성 모델을 쓰다 보면, 학습이 끝난 뒤에도 결과물의 품질을 더 끌어올리고 싶은 순간이 온다. 추가 학습 없이 샘플링 단계에서 reward를 반영해 더 좋은 이미지를 뽑아내는 방법, 즉 test-time reward alignment이 그 해결책이 될 수 있다.
이전에 리뷰했던 SMC(Sequential Monte Carlo) 기반 방법이 대표적이다. Diffusion 모델이 이미지를 만들어가는 과정에서 여러 후보를 동시에 추적하고, reward가 높은 쪽에 가중치를 실어주며 점차 원하는 분포로 수렴시킨다. 매 단계에서 여러 갈래의 가능한 미래를 확률적으로 탐색할 수 있다는 게 핵심이다.
문제는 flow matching 기반 ODE 모델을 쓸 때다. Flow matching은 초기 노이즈에서 데이터까지의 경로를 ODE로 정의하기 때문에, 한번 출발하면 도착지가 하나로 정해진다. SMC가 작동하려면 지금 여기서 어디로 갈 수 있는지에 대한 확률적 답이 필요한데, ODE는 그 답이 언제나 하나뿐이다. SMC를 그대로 가져다 쓸 수가 없는 것이다.
GLASS Flows는 바로 이 문제를 해결한 논문이다.
Background
배경을 좀 더 풀어보자.
생성 모델은 보통 학습 데이터의 분포 에서 샘플을 뽑도록 훈련된다. 하지만 우리가 진짜 원하는 건 단순히 그럴듯한 이미지가 아니라, 특정 기준(reward)을 잘 만족하는 이미지다. 수식으로 쓰면 목표 분포는 이렇다:
데이터 분포에서 reward가 높은 영역을 더 강조한 형태다. 이 분포에서 직접 샘플링하기는 어렵고, 그래서 SMC나 search 같은 알고리즘이 등장한다.
이런 알고리즘들에는 공통적으로 transition kernel이 필요하다. 쉽게 말해, 지금 상태 에서 다음 시점 에 어디로 갈 수 있는지를 확률적으로 알려주는 일종의 지도다. SMC는 이 지도를 가지고 여러 후보를 동시에 펼친 다음, reward가 높은 쪽을 살린다. Search도 마찬가지다. 확률적 전이가 없으면 이 알고리즘들은 아예 돌아가지 않는다.
그런데 실전에서 배포되는 모델 대부분은 속도를 위해 ODE 샘플링을 쓴다. ODE는 빠르지만 확률적 전이가 없고, SDE는 확률적 전이가 있지만 느리다. Reward alignment를 적용하려면 느린 SDE로 돌아가야 하니, 성능을 높이자고 효율을 깎는 꼴이 된다.
ODE의 확률성은 어디에 있는가
GLASS의 아이디어를 이해하려면, 먼저 기존 ODE 기반 flow matching에서 확률성이 정확히 어디서 생기는지를 짚고 넘어갈 필요가 있다.
Flow matching은 가우시안 노이즈 에서 출발해 깨끗한 데이터 까지 ODE를 따라 흘러간다. 이때 확률성이 부여되는 순간은 딱 하나, 맨 처음 를 가우시안 분포에서 랜덤하게 뽑는 그 지점뿐이다. 일단 가 정해지고 나면, 이후 경로 은 전부 결정론적으로 고정된다. 같은 에서는 언제나 같은 이 나온다.
그런데 reward alignment를 하려면 이야기가 달라진다. 우리가 원하는 건 에서 까지의 전체 경로를 한 번에 결정하는 게 아니라, 중간중간 개입해서 reward가 높은 방향으로 경로를 틀어주는 것이다. 예를 들어 까지 왔을 때, 여기서 으로 넘어가는 여러 후보를 만들고 reward를 기준으로 좋은 후보를 골라야 한다. 그러려면 구간에서도 확률적으로 여러 갈래가 존재해야 하는데, 기존 ODE에서는 가 정해지면 와 도 하나로 고정되니 후보를 만들 수가 없다.
GLASS Flows
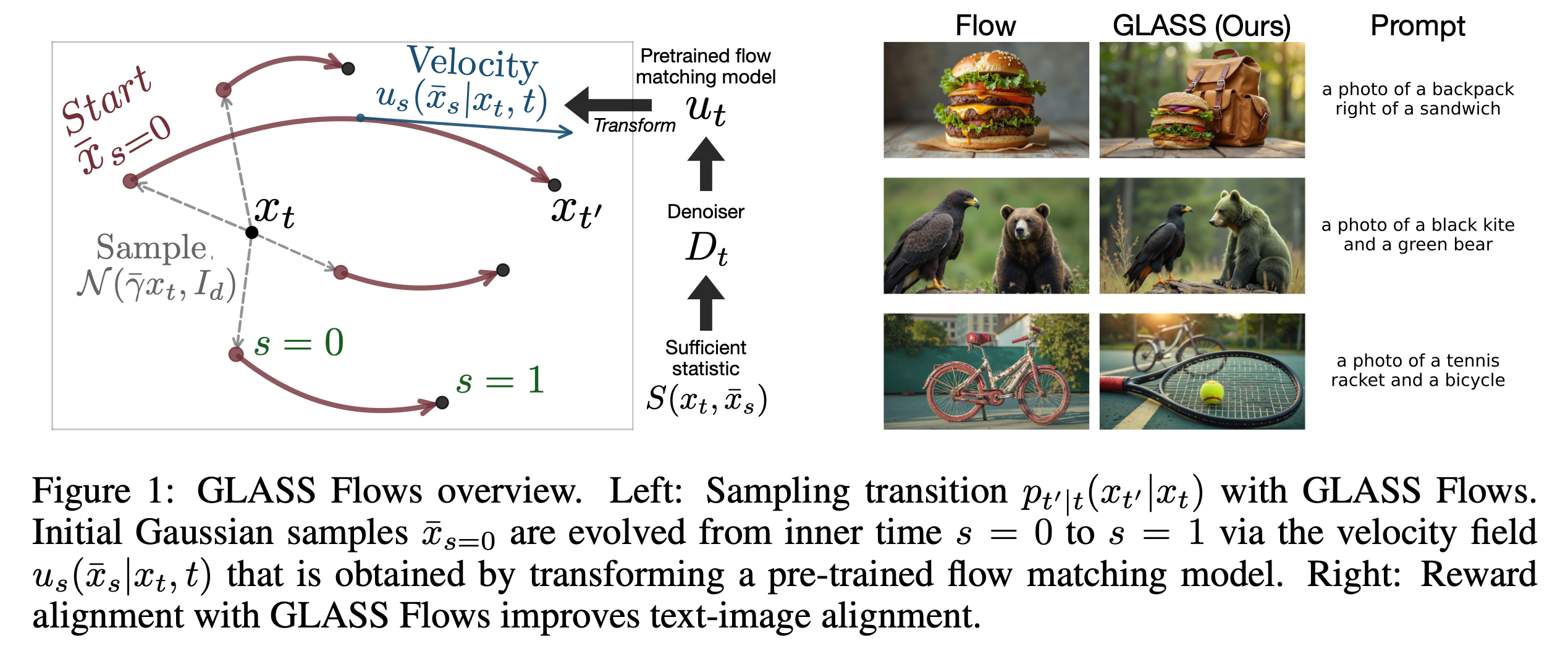
GLASS의 해법은 발상의 전환에 가깝다. 같은 중간 구간의 전이를, 그 자체로 하나의 작은 flow matching 문제로 다시 세우는 것이다.
구체적으로 보자. 에서 으로 보내고 싶다고 하자. GLASS는 이 구간을 위한 별도의 inner flow matching을 만든다. 이 inner flow에서는 에 해당하는 새로운 시작점을 로, 에 해당하는 도착점을 로 놓는다. 그러면 이 작은 flow matching 안에서도 원래 flow matching과 똑같은 구조가 성립한다. 를 가우시안에서 랜덤하게 뽑는 순간 확률성이 생기고, 이후는 ODE를 따라 결정론적으로 에 도착한다.
결국 원래 flow matching에서 확률성이 맨 처음 샘플링에서만 생기는 것과 같은 원리를, 중간 구간에도 반복 적용하는 것이다. 구간의 inner flow에서 초기 노이즈를 랜덤하게 뽑으면, 같은 에서 출발하더라도 매번 다른 에 도착할 수 있다. 이렇게 되면 중간 전이마다 여러 후보가 만들어지고, SMC가 작동할 수 있는 조건이 갖춰진다.
그리고 이 inner flow matching 모델을 처음부터 새로 학습할 필요가 없다. 통계학의 충분통계량(sufficient statistic) 개념을 활용한 변환을 거치면, 이미 훈련된 기존 flow matching 모델을 그대로 재활용할 수 있다. 이름의 GLASS가 Gaussian Latent Sufficient Statistic의 약자인 이유다.
한편, GLASS는 두 시점의 상태 를 하나의 결합 분포(joint distribution)로 먼저 정의하고, 여기서 조건부 분포 를 도출하는 방식을 취한다. 결합 분포가 각 시점의 marginal을 정확히 재현하도록 설계되어 있기 때문에, 전이를 아무리 확률적으로 만들어도 전체 분포 구조가 깨지지 않는다. 두 시점 간의 상관 정도를 조절하면, 거의 결정론적인 전이부터 강하게 확률적인 전이까지 연속적으로 조절할 수 있다.

GLASS의 구조를 정리하면:
- 기존 flow matching 모델에서 FM denoiser를 가져온다.
- 충분통계량 기반 변환을 통해 GLASS denoiser를 구성한다.
- 여기서 GLASS velocity field를 정의해 inner ODE를 만든다.
- Inner ODE의 초기 조건을 랜덤 샘플링해서 확률적 전이를 수행한다.
ODE의 계산 효율성은 유지하면서, 중간 전이마다 확률성을 부여하는 구조가 완성된다.
Flow matching 모델에 test-time alignment을 적용하고 싶었지만 ODE의 결정론적 구조 때문에 막혀 있던 입장에서, GLASS는 꽤 직접적인 답을 주는 논문이었다. 이를 통해 ODE를 포기하지 않고도 확률적 전이를 만들 수 있고, 기존 모델을 재학습 없이 변환만으로 쓸 수 있다.
