DNS/URGENT 챌린지
DNS 챌린지와 URGENT 챌린지 소개
오늘은 음성 향상 분야의 대표적인 두 대회, DNS 챌린지와 URGENT 챌린지에 대해 소개해 드리겠습니다.
두 대회 모두 잡음이나 왜곡이 섞인 환경에서도 사람이 듣기 좋은, 혹은 후속 작업에 유리한 깨끗한 음성을 만들어내는 기술을 겨루는 대회입니다.
다만 초점이 조금 다릅니다. DNS 챌린지는 노이즈 제거(enhancement*)에 좀 더 초점을 맞추고 있으며, 여기에 더해 fullband 처리, 개인화, 간섭 화자 억제, 실시간 처리 제약 등이 핵심 과제입니다. 반면 URGENT 챌린지는 '범용(universal) 음성 향상'을 내세우며, 다양한 유형의 노이즈, 여러 가지 입력 샘플링레이트, 대규모·다언어 데이터를 결합해 하나의 모델이 여러 조건을 통합적으로 처리하도록 요구하는 대회입니다.
용어 설명
- Enhancement(음성 향상): 잡음, 울림 등이 섞인 음성 신호에서 불필요한 성분을 제거하거나 줄여, 원래 깨끗한 음성에 가깝게 복원하는 기술을 말합니다.
- Narrowband: 샘플링레이트 8kHz로, 약 4kHz까지의 주파수만 담을 수 있는 가장 낮은 음질 대역입니다. 일반 유선 전화 통화가 대표적인 예로, 상대방 목소리는 알아들을 수 있지만 소리가 답답하고 뭉개지는 느낌이 납니다.
- Wideband: 샘플링레이트 16kHz로, 약 8kHz까지의 주파수를 담습니다. HD Voice 통화나 화상회의 음질이 여기에 해당하며, Narrowband보다 목소리가 한결 선명하고 자연스럽습니다.
- Fullband: 샘플링레이트 48kHz로, 약 24kHz까지의 주파수를 담아 사람이 들을 수 있는 거의 모든 소리를 표현할 수 있습니다. 음악 스트리밍이나 고품질 녹음에 사용되는 수준으로, 가장 풍부하고 자연스러운 음질을 제공합니다.
- 간섭 화자(Interfering Talker): 내가 듣고 싶은 사람의 목소리 외에, 배경에서 동시에 말하는 다른 사람의 목소리를 가리킵니다. 카페에서 대화할 때 옆 테이블 사람의 말소리가 섞이는 상황을 떠올리시면 됩니다.
- 샘플링레이트(Sampling Rate): 음성 신호를 디지털로 변환할 때, 1초에 몇 번 소리를 측정(샘플링)하는지를 나타내는 수치입니다. 예를 들어 48kHz는 1초에 48,000번, 16kHz는 16,000번 측정합니다. 숫자가 높을수록 원래 소리에 가까운 품질을 얻을 수 있습니다.
DNS 챌린지
DNS 챌린지란?
DNS는 Deep Noise Suppression Challenge의 약자입니다. Microsoft에서 주최하는 이 대회는 주로 단일 채널 환경에서의 음성 향상을 다루며, 단순한 잡음 제거(denoising)를 넘어 잔향 제거(dereverberation*), 나아가 최근에는 동시 발화 및 간섭 화자 억제까지 포함하여 "사람이 듣기에 좋은 음성 품질"을 만드는 데 집중하고 있습니다.
용어 설명
- 단일 채널(Single Channel): 마이크 하나로 녹음된 음성을 의미합니다. 마이크가 여러 개인 경우(다채널)와 달리, 방향 정보 등을 활용하기 어려워 잡음 제거가 더 까다롭습니다.
- Denoising(잡음 제거): 음성에 섞여 있는 환경 소음(에어컨 소리, 키보드 소리, 도로 소음 등)을 걸러내는 과정입니다.
- Dereverberation(잔향 제거): 방 안에서 소리가 벽에 반사되어 생기는 울림(잔향)을 줄이는 기술입니다. 넓은 강당에서 말할 때 "웅웅" 울리는 느낌이 잔향의 대표적인 예입니다.
데이터셋 종류
DNS 챌린지(5th, ICASSP 2023 기준)는 Wideband(16kHz)와 Fullband(48kHz) 두 가지 시나리오에 대해 데이터를 제공하며, 전체 데이터는 압축 해제 시 약 1TB 규모입니다. DNS5부터는 Fullband(48kHz)가 주력이며, 두 트랙(Track 1: 헤드셋, Track 2: 스피커폰) 모두 Fullband 데이터셋을 사용합니다.
깨끗한 음성(Clean Speech) 데이터
Fullband(48kHz) — 총 약 827GB
| 데이터셋 | 내용 | 용량 |
|---|---|---|
| Read Speech | 영어 낭독 음성 (LibriVox 오디오북 기반) | 299GB |
| German Speech | 독일어 음성 | 319GB |
| French Speech | 프랑스어 음성 | 62GB |
| Spanish Speech | 스페인어 음성 | 65GB |
| Italian Speech | 이탈리아어 음성 | 42GB |
| Russian Speech | 러시아어 음성 | 12GB |
| Emotional Speech | 울음, 소리 지르기, 웃음, 노래 등 감정 표현 음성 | 2.4GB |
| VCTK | 다화자(110명) 뉴스 낭독 음성 | 27GB |
| VocalSet | 전문 성악가들의 노래 음성 | 974MB |
Wideband(16kHz) — 총 약 229GB (DNS3 기준)
| 데이터셋 | 내용 | 용량 |
|---|---|---|
| Read Speech | 영어 낭독 음성 (약 562시간) | - |
| Singing Voice | 노래 음성 (약 8.8시간) | - |
| Emotional Speech | 6가지 감정(분노, 혐오, 공포, 행복, 중립, 슬픔) × 4단계 강도 (약 3.6시간) | - |
| Mandarin Speech | 중국어 만다린 음성 (약 185시간) | - |
| 다국어 음성 | 프랑스어, 독일어, 이탈리아어, 러시아어, 스페인어 | - |
| 전체 Clean Speech | 약 760시간 (DNS2 대비 50% 증가) | 204GB |
DNS5에서는 개인화(Personalized) DNS 모델 개발을 위해, DNSMOS P.835 OVRL 점수가 4.25 이상인 고품질 음성만 선별하여 제공합니다. 총 3,230명의 화자에 대해 화자별 ID 정보가 제공되며, 각 화자당 2.5분의 등록(enrollment) 음성이 포함됩니다.
잡음(Noise) 데이터 — 총 약 181시간, 150개 클래스, 약 62,000 클립
잡음 데이터는 세 가지 출처에서 수집됩니다.
Audioset: YouTube 동영상에서 추출한 약 200만 개의 사람 레이블 10초 음성 클립 모음(약 600개 오디오 이벤트 클래스)에서 선별합니다. 원본 Audioset은 음악·말소리 같은 클래스가 100만 개 이상인 반면, 칫솔질·삐걱거림 같은 클래스는 200개 미만으로 불균형하기 때문에, 클래스당 최소 500개 클립이 되도록 샘플링을 조정했습니다. 또한, 음성 활동 탐지기(VAD*)를 사용하여 사람 말소리가 포함된 클립을 모두 제거했습니다.
Freesound: CC0 라이선스(저작권 제한 없음)의 다양한 환경음 클립에서 약 10,000개를 추가로 수집했습니다.
DEMAND (Diverse Environments Multi-channel Acoustic Noise Database): 공원, 카페, 지하철역, 세탁실, 사무실 등 다양한 실제 환경에서 다채널로 녹음된 잡음 데이터베이스입니다.
세 출처를 합산하면 약 150개 잡음 클래스, 62,000개 클립, 총 181시간입니다. VoIP(인터넷 통화) 환경에 자주 등장하는 잡음 유형 위주로 선별되었습니다. Fullband 잡음 데이터(noise_fullband)는 별도로 약 58GB 규모로 제공됩니다.
용어 설명
- VAD(Voice Activity Detection, 음성 활동 탐지): 오디오 신호에서 사람의 말소리가 있는 구간과 없는 구간을 자동으로 구분하는 기술입니다. 여기서는 잡음 데이터에 사람 말소리가 섞여 들어가는 것을 방지하기 위해 사용되었습니다.
방 임펄스 응답(RIR*) 데이터
Wideband: SLR26(2.1GB)과 SLR28(2.3GB)을 합쳐 약 4.3GB, 총 118,000개 이상의 실제·합성 RIR 샘플이 포함됩니다. 각 RIR에 대해 잔향 시간(RT60)과 명료도(C50) 파라미터가 함께 제공됩니다.
Fullband: 약 5.9GB 규모의 RIR 데이터가 제공됩니다.
용어 설명
- RIR(Room Impulse Response, 방 임펄스 응답): 특정 공간에서 소리가 벽, 천장, 바닥 등에 반사되어 마이크에 도달하는 패턴을 기록한 것입니다. 이 데이터를 깨끗한 음성에 적용하면, 마치 그 공간에서 녹음한 것처럼 울림이 있는 음성을 만들어낼 수 있습니다.
- RT60(잔향 시간): 소리가 발생한 뒤, 음량이 60dB(원래의 1/1000) 줄어들 때까지 걸리는 시간입니다. RT60이 길수록 울림이 오래 남는 공간(큰 강당, 성당 등)이고, 짧을수록 울림이 적은 공간(방음실 등)입니다.
- C50(명료도): 음원이 발생한 후 처음 50ms 이내에 도착하는 소리와 그 이후에 도착하는 반사음의 에너지 비율입니다. 값이 높을수록 말소리가 선명하게 들립니다.
테스트셋
개발용 테스트셋(dev testset)과 블라인드 테스트셋(blind testset)이 별도로 제공됩니다. 블라인드 테스트셋은 크라우드소싱과 Microsoft 내부에서 다양한 디바이스(모바일/데스크톱), 다양한 음향 환경에서 실제 녹음한 데이터를 포함합니다. 영어 외에도 포르투갈어, 러시아어, 스페인어(비성조), 만다린, 광동어, 펀자브어, 베트남어(성조) 등 다국어 테스트 클립이 포함됩니다. 또한 감정 음성(행복, 슬픔, 분노, 소리 지르기, 울음, 웃음)과 부수언어적 발화(헛기침, "음", 한숨, 신음 등)도 평가 대상에 포함됩니다.
평가 Metric 종류
DNS 챌린지는 주관적 평가를 핵심으로 삼으면서, 객관적 보조 지표를 함께 활용합니다.
ITU-T P.835 주관적 평가 (핵심 평가): 실제 사람이 음성을 듣고 1~5점 척도로 세 가지 측면을 평가합니다. SIG(음성 자체의 품질), BAK(배경 잡음의 억제 정도), OVRL(전체적인 음질)이며, 최종 순위는 OVRL을 기준으로 결정됩니다.
DNSMOS P.835 (비침습적* 객관적 평가): P.835 주관 평가를 딥러닝으로 자동 예측하는 메트릭입니다. 깨끗한 원본 음성 없이도 SIG, BAK, OVRL 세 점수를 추정할 수 있어, 참가자들이 개발 과정에서 빠르게 모델 성능을 확인하는 데 사용합니다.
WAcc (Word Accuracy, 단어 정확도): 음성 향상 처리가 음성 인식(ASR*) 성능에 미치는 영향을 측정합니다. 잡음을 너무 과하게 제거하면 음성까지 왜곡되어 인식 정확도가 떨어질 수 있기 때문에, 이를 확인하기 위한 보조 지표입니다.
용어 설명
- 비침습적(Non-intrusive) 메트릭: 깨끗한 원본 음성(참조 신호)이 없어도 품질을 측정할 수 있는 평가 방식입니다. 반대로 PESQ처럼 원본이 필요한 방식을 '침습적(Intrusive) 메트릭'이라고 합니다. 실제 녹음 환경에서는 깨끗한 원본을 구하기 어렵기 때문에, 비침습적 메트릭이 실용적입니다.
- ASR(Automatic Speech Recognition, 자동 음성 인식): 사람의 말소리를 컴퓨터가 자동으로 텍스트로 변환하는 기술입니다. Siri, 구글 어시스턴트 등이 대표적인 예입니다.
URGENT 챌린지
URGENT 챌린지란?
URGENT는 Universality, Robustness, and Generalizability for EnhancemeNT의 약자로, "범용 음성 향상"을 목표로 하는 대회입니다. 하나의 시스템이 다양한 왜곡 유형(잡음, 잔향, 클리핑, 대역폭 제한, 코덱 왜곡, 패킷 손실, 바람 잡음 등)과 다양한 입력 포맷(서로 다른 샘플링레이트)을 단일 프레임워크로 통합 처리할 수 있는지를 겨루는 대회입니다.
용어 설명
- 클리핑(Clipping): 녹음 시 소리가 장비가 처리할 수 있는 최대 범위를 넘어서면, 신호의 꼭대기 부분이 잘려나가는 현상입니다. 마이크에 너무 가까이서 크게 말하면 소리가 "찢어지는" 느낌이 나는 것이 클리핑의 대표적인 예입니다.
- 대역폭 제한(Bandwidth Limitation): 전송할 수 있는 주파수 범위가 제한되는 것을 말합니다. 예를 들어 일반 전화는 약 300Hz ~ 3,400Hz만 전달하기 때문에, 사람 목소리의 높은 주파수나 낮은 주파수가 잘리면서 음질이 떨어집니다.
- 코덱(Codec): 음성 데이터를 압축·해제하는 알고리즘입니다. MP3, AAC, Opus 등이 대표적이며, 압축 과정에서 원래 음질이 일부 손실될 수 있습니다.
- 패킷 손실(Packet Loss): 인터넷 통화(VoIP 등)에서 데이터가 작은 묶음(패킷)으로 전송되는데, 네트워크 문제로 일부 패킷이 도착하지 못하는 현상입니다. 화상 회의 중 상대방 목소리가 끊기는 현상이 패킷 손실의 대표적인 예입니다.
데이터셋 종류
URGENT 2024 챌린지의 학습 및 검증 데이터는 모두 공개 코퍼스*를 기반으로 시뮬레이션하여 생성됩니다. 참가자 간 공정한 비교를 위해, 지정된 데이터만 사용하도록 엄격히 제한한 점이 DNS 챌린지와의 큰 차이점입니다.
음성(Speech) 데이터 — 큐레이션 후 총 약 1,300시간
| 코퍼스 | 내용 | 샘플링레이트 | 규모 |
|---|---|---|---|
| DNS5 LibriVox | LibriVox 오디오북 기반 영어 음성 | 8~48kHz (대역폭 재추정 후) | 약 350시간 |
| LibriTTS | LibriSpeech에서 파생된 낭독 음성 (TTS 연구용) | 8~24kHz (대역폭 재추정 후) | 약 200시간 |
| CommonVoice 11.0 (영어) | 크라우드소싱으로 수집된 다양한 화자의 영어 음성 | 8~48kHz (대역폭 재추정 후) | 약 550시간 |
| VCTK | 110명 화자의 뉴스 문장 낭독 음성 | 48kHz | 약 80시간 |
| WSJ | Wall Street Journal 뉴스 원고 낭독 음성 | 16kHz | 약 85시간 |
URGENT 챌린지는 다양한 샘플링레이트(8k, 16k, 22.05k, 24k, 32k, 44.1k, 48kHz)의 입력을 하나의 모델로 처리해야 하므로, 각 코퍼스의 실제 유효 대역폭을 에너지 기반 알고리즘으로 재추정합니다. 예를 들어 DNS5 LibriVox의 약 50%는 공칭(파일에 표시된 스펙) 48kHz이지만 실제 유효 대역폭은 32kHz였고, LibriTTS의 약 25%도 공칭 24kHz보다 낮은 대역폭을 가지고 있었습니다. 이 재추정 과정을 통해 각 샘플이 실제 담고 있는 주파수 대역에 맞는 샘플링레이트로 재조정됩니다.
잡음(Noise) 데이터 — 총 약 250시간
| 코퍼스 | 내용 | 샘플링레이트 | 규모 |
|---|---|---|---|
| Audioset + Freesound (DNS5) | YouTube에서 추출한 환경음 + CC0 라이선스 환경음. 약 150개 잡음 클래스, 62,000개 클립. 음악, 교통소음, 기계음, 자연음 등 | 8~48kHz | 약 180시간 |
| WHAM! | 도시 환경(거리, 카페, 레스토랑 등)에서 실제 녹음한 잡음 | 48kHz | 약 70시간 |
방 임펄스 응답(RIR) 데이터
DNS5 챌린지에서 시뮬레이션된 RIR 데이터를 기본으로 활용합니다. 참가자들이 RIR-Generator, pyroomacoustics, gpuRIR 같은 도구를 이용해 직접 추가 RIR을 생성하는 것도 허용됩니다.
왜곡(Distortion) 유형
학습 데이터를 생성할 때, 다음 4가지 왜곡을 다양한 조합과 강도로 적용합니다. SNR 범위는 -5dB ~ 20dB로 설정됩니다.
| 왜곡 유형 | 설명 |
|---|---|
| 잡음 추가(Additive Noise) | 위의 잡음 데이터를 다양한 SNR로 깨끗한 음성에 혼합 |
| 잔향(Reverberation) | RIR을 깨끗한 음성에 적용하여 공간 울림 효과 부여 |
| 클리핑(Clipping) | 음성 신호의 피크를 인위적으로 잘라내어 왜곡 생성 |
| 대역폭 제한(Bandwidth Limitation) | 고주파·저주파를 잘라내어 전화 통화와 유사한 제한된 음질로 변환 |
테스트셋
| 테스트셋 | 샘플 수 | 특징 |
|---|---|---|
| 검증(Validation) | 1,000개 (약 1.5시간) | 시뮬레이션 데이터. 깨끗한 음성과 잡음 음성 쌍 + SNR, 왜곡 설정, 전사(transcript) 등 메타 정보 포함 |
| 비블라인드(Non-blind) 테스트 | - | 시뮬레이션 데이터. 모든 객관적 메트릭으로 평가 |
| 블라인드(Blind) 테스트 | 1,000개 | 시뮬레이션 데이터 + 실제 녹음 데이터 혼합. 실제 녹음 부분은 CommonVoice, LibriTTS, VCTK의 테스트 파티션 및 YouTube 크리에이티브 커먼즈 팟캐스트 등에서 수집. 실제 녹음에는 DEMAND, TUT Urban Acoustic Scenes 등 학습에 포함되지 않은 잡음 코퍼스와 SLR28, MYRiAD v2 등의 실제 녹음 RIR을 사용 |
용어 설명
- 코퍼스(Corpus): 연구나 학습에 사용하기 위해 체계적으로 수집·정리된 대규모 데이터 모음을 말합니다. 음성 분야에서는 녹음된 음성 파일들의 집합을 가리킵니다.
- SNR(Signal-to-Noise Ratio, 신호 대 잡음비): 원하는 신호(음성)와 잡음의 크기 비율을 데시벨(dB)로 나타낸 값입니다. SNR이 높을수록 잡음에 비해 음성이 크고 깨끗하게 들리며, 낮을수록 잡음이 심한 환경을 의미합니다.
평가 Metric 종류
URGENT 챌린지는 DNS 챌린지와 달리, 5가지 카테고리의 13개 메트릭을 종합적으로 활용하여 순위를 매기는 것이 가장 큰 특징입니다.
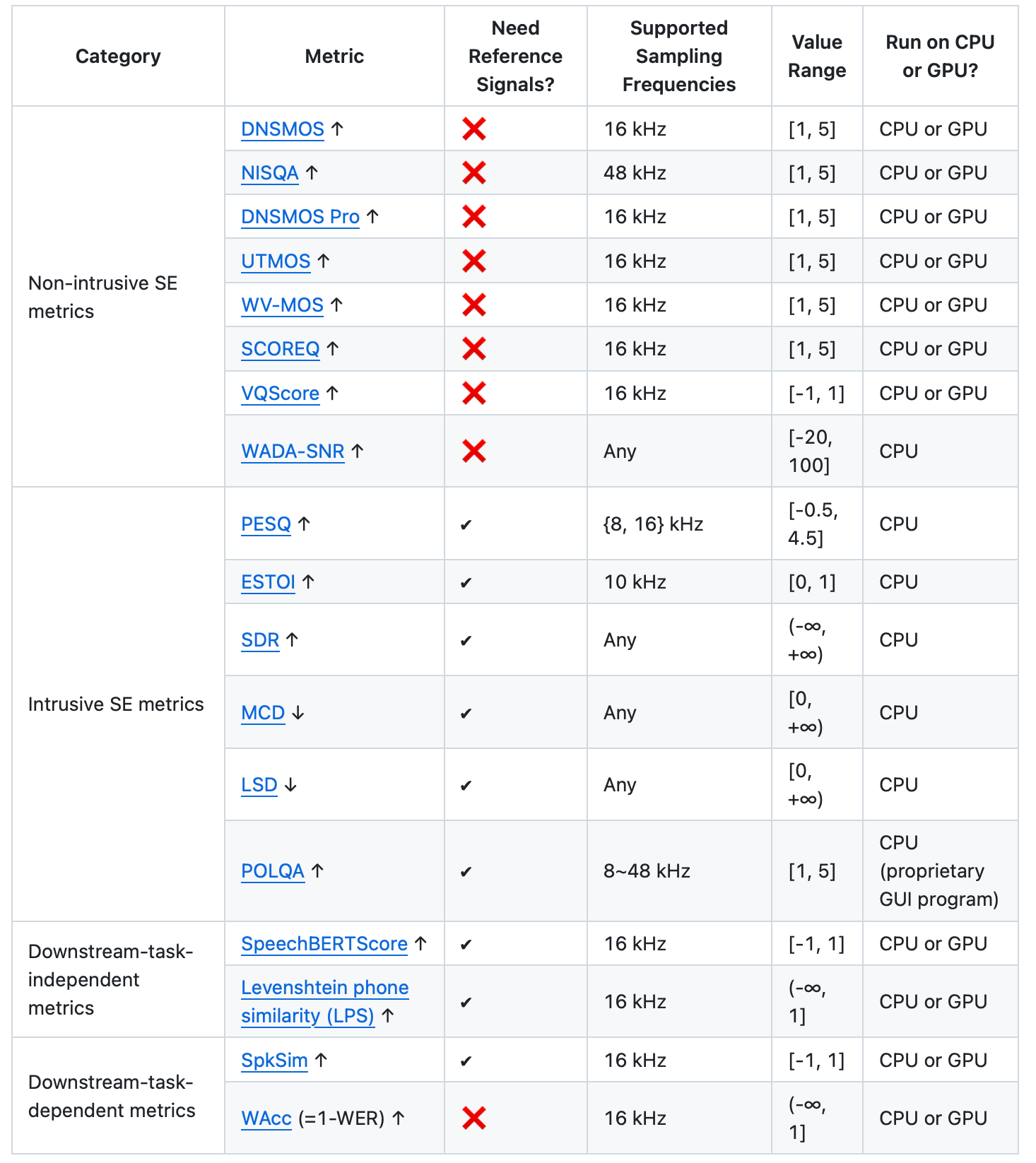
비침습적 음성 향상(SE) 메트릭: DNSMOS(SIG/BAK/OVRL 점수 예측)와 NISQA*(전반적 음질, 잡음감, 색채감, 불연속성, 음량 등을 예측)를 사용합니다. 원본 음성 없이 품질을 추정할 수 있어 실제 녹음 데이터에도 적용 가능합니다.
침습적 음성 향상(SE) 메트릭: POLQA, PESQ(음성 품질), ESTOI(음성 명료도), SDR(신호 왜곡비), MCD*(멜 켑스트럼 왜곡), LSD(로그 스펙트럼 거리) 등을 사용합니다. 원본 깨끗한 음성과 비교하여 정밀하게 측정합니다.
다운스트림 작업 독립 메트릭: LPS(Levenshtein Phone Similarity)와 SpeechBERTScore를 사용합니다. 특정 언어나 화자에 의존하지 않고, 음성의 음소* 수준 충실도를 평가합니다.
다운스트림 작업 의존 메트릭: SpkSim(화자 유사도)과 WAcc(단어 정확도)로, 향상된 음성이 화자 인식이나 음성 인식 같은 후속 작업에 얼마나 유용한지를 측정합니다.
주관적 메트릭: 최종 블라인드 테스트 단계에서 ITU-T P.808 기준에 따라 크라우드소싱으로 MOS(평균 의견 점수)를 수집합니다. 300개 샘플 서브셋에 대해 8명의 평가자가 점수를 매깁니다.
용어 설명
- NISQA(Non-Intrusive Speech Quality Assessment): 원본 음성 없이 음질을 다차원(잡음감, 색채감, 불연속성, 음량)으로 평가하는 딥러닝 기반 메트릭입니다.
- PESQ(Perceptual Evaluation of Speech Quality): 전화 통화 품질 평가를 위해 개발된 국제 표준(ITU-T P.862) 메트릭으로, 원본 음성과 처리된 음성을 비교해 사람이 느끼는 음질 차이를 수치화합니다.
- POLQA(Perceptual Objective Listening Quality Analysis): PESQ의 후속 표준(ITU-T P.863)으로, 더 넓은 네트워크 환경(HD Voice, VoIP 등)에서의 음질 평가를 지원합니다.
- ESTOI(Extended Short-Time Objective Intelligibility): 잡음 환경에서 음성이 얼마나 알아듣기 쉬운지(명료도)를 측정하는 메트릭입니다.
- SDR(Signal-to-Distortion Ratio): 원본 신호 대비 왜곡의 비율을 데시벨로 나타낸 값입니다. 높을수록 원본에 가깝게 복원되었음을 의미합니다.
- MCD(Mel Cepstral Distortion): 원본과 처리된 음성의 멜 켑스트럼* 차이를 측정합니다. 값이 낮을수록 원본에 가까운 음색을 유지했다는 뜻입니다.
- 멜 켑스트럼(Mel Cepstrum): 사람의 청각 특성을 반영한 주파수 분석 방법으로, 음색의 특징을 수치로 표현한 것입니다.
- 음소(Phoneme): 언어에서 의미를 구별하는 가장 작은 소리 단위입니다. 예를 들어 "밥"과 "밤"에서 "ㅂ"과 "ㅁ"이 서로 다른 음소입니다.
- MOS(Mean Opinion Score, 평균 의견 점수): 여러 사람이 음질을 1~5점으로 평가한 뒤 평균을 낸 점수입니다. 5점이 최고 품질, 1점이 최저 품질을 의미합니다.
- 크라우드소싱(Crowdsourcing): 불특정 다수의 사람들에게 온라인으로 작업(여기서는 음질 평가)을 분배하여 대규모 데이터를 수집하는 방식입니다. Amazon Mechanical Turk 같은 플랫폼이 대표적입니다.
앞으로의 전망
URGENT 챌린지는 빠르게 진화하고 있습니다. 2024년(1회) 대비 2025년(2회)에서는 왜곡 유형이 4가지에서 7가지(코덱 왜곡, 패킷 손실, 바람 잡음 추가)로 늘어났고, 영어 단일 언어에서 5개 언어(영어, 독일어, 프랑스어, 스페인어, 중국어)로 확장되었습니다. 데이터 규모도 Track 2 기준 약 60,000시간까지 대폭 확대되어, 데이터 스케일링이 음성 향상 성능에 미치는 영향까지 탐색할 수 있게 되었습니다.
2025년 챌린지 결과에서 주목할 만한 점은, 판별적(discriminative) 모델과 생성적(generative) 모델을 결합한 하이브리드 방식이 대세로 떠올랐다는 것입니다. 또한 순수 생성 모델이 언어에 따라 성능 편차를 보이는 현상(언어 의존성)이 새롭게 확인되어, 앞으로 다국어 환경에서의 범용 음성 향상이 중요한 연구 주제가 될 전망입니다.
가장 최신인 URGENT 2026(ICASSP 2026)에서는 한 발 더 나아가, 기존의 음성 향상(SE) 트랙(Track 1)에 더해 음성 품질 평가(SQA) 트랙(Track 2)이 새롭게 추가되었습니다. Track 2는 음성을 직접 향상시키는 것이 아니라, SE 시스템이 처리한 음성의 MOS 점수를 정확하게 예측하는 모델을 만드는 과제입니다. "좋은 음성 향상 모델을 만드는 것"뿐 아니라 "음성 품질을 정확하게 자동 측정하는 것"까지 챌린지의 범위가 넓어지고 있는 셈입니다.
Reference
두 챌린지 모두 데이터셋 다운로드 스크립트, 학습 데이터 생성 스크립트, 평가 메트릭 계산 스크립트가 각각의 GitHub 저장소에 공개되어 있습니다. 직접 데이터를 내려받고, 모델을 학습하고, 평가까지 해볼 수 있으니 관심 있으신 분들은 아래 링크를 참고해 주세요.
- DNS 챌린지: https://github.com/microsoft/DNS-Challenge
- URGENT 2024 챌린지: https://github.com/urgent-challenge/urgent2024_challenge
- URGENT 2025 챌린지: https://github.com/urgent-challenge/urgent2025_challenge
- URGENT 2026 챌린지:
https://github.com/urgent-challenge/urgent2026_challenge_track1
https://github.com/urgent-challenge/urgent2026_challenge_track2
