[Paper Review] Easy Turn: Integrating Acoustic and Linguistic Modalities for Robust Turn-Taking in Full-Duplex Spoken Dialogue Systems
Speech & Audio
#Full-duplex spoken dialogue systems
#turn taking detection
#음향과 언어를 함께 써서, 더 자연스러운 대화를 만들 수 있을까?
✔️ 배경
최근 spoken dialogue system은 단순히 “질문하면 대답하는” 반응형 구조를 넘어서, 사람이 말하는 도중에도 듣고 판단하고 적절한 순간에 응답하는 full-duplex interaction으로 빠르게 넘어가고 있습니다. 그런데 이때 중요한 요소 중에 하나는 지금 시스템이 말해야 하는지 혹은 계속 들어야 하는지를 정확히 판단하는 것입니다. (turn-taking detection)
저자들은 기존 오픈소스 접근이 너무 크거나, 음성 또는 텍스트 한쪽만 보는 단일 모달 구조라는 한계를 지닌다고 보고, acoustic + linguistic bimodal information을 함께 쓰는 Easy Turn 모델과 1,145시간규모의 turn-taking 데이터셋을 동시에 제안합니다.
Turn-taking detection이란?
사용자가 말을 “끝낸 것인지”, “잠깐 멈춘 것인지”, “맞장구만 친 것인지”, 혹은 “시스템에게 멈추라고 한 것인지”를 판별해서, 시스템의 다음 행동을 결정하는 모듈입니다. 이 논문은 이를 complete / incomplete / backchannel / wait의 4가지 상태로 정의합니다.
✔️ Paper Info
- Title: Easy Turn: Integrating Acoustic and Linguistic Modalities for Robust Turn-Taking in Full-Duplex Spoken Dialogue Systems (https://arxiv.org/pdf/2509.23938)
- Authors :
- Affiliation: Northwestern Polytechnical University ASLP 그룹과 Huawei Technologies 소속 연구진의 공동 연구입니다.
- Conference:
- Keywords: turn-taking detection, full-duplex, open-source, corpus, bimodal.
✔️ Main Problem and Key Approach
기존 접근의 한계
이 논문이 짚는 기존 방법의 한계는 다음과 같습니다.
첫째, TEN Turn Detection은 텍스트 기반 의미 해석은 가능하지만 Qwen2.5-7B를 써서 무겁고, 음성 입력을 직접 받지 못해 앞단 ASR이 필요합니다. (ASR 과정에서 acoustic information 잃어버림)
둘째, Smart Turn V2는 빠르고 가볍지만 음성만 입력으로 받고 complete / incomplete 두 상태만 분류하기 때문에 의미적 맥락을 충분히 반영하기 어렵습니다.
셋째, LLM backbone 자체를 full-duplex하게 만드는 end-to-end 접근은 매력적이지만, 이를 위해 필요한 대규모 고품질 full-duplex 데이터가 공개 형태로 거의 없다는 문제가 있습니다.
- 오픈소스 아닌 turn taking model 에 의존한다.
- 공개돼 있는 건 parameter size 가 크거나, 언어/음성 중 하나의 모달리티만 제공한다.
- LLM backbone 으로 훈련시키는건 full-duplex 데이터셋이 필요하다.
- complete, incomplete, backchannel, and wait 예측하는 모델 + 데이터셋 공개하겠다.
Easy Turn의 핵심 아이디어
이 논문의 해법은 다음과 같습니다.
“음향 정보만으로도 부족하고, 텍스트 정보만으로도 부족하다. 둘을 함께 보자.”
그래서 Easy Turn은 사용자의 speech를 입력받아, 먼저 ASR transcription을 생성하고, 그 과정에서 얻은 linguistic 정보와 acoustic representation을 결합해 turn state를 예측합니다. 즉, 이 논문은 turn-taking을 단순 classifier 문제로 보지 않고, ASR + state prediction이 연결된 멀티모달 이해 문제로 재정의합니다.
이 논문이 정의한 4가지 상태

- Complete: 사용자가 의도를 끝까지 말했고, 시스템이 이제 응답해야 하는 상태
- Incomplete: 사용자가 잠깐 멈췄지만 아직 말을 덜 끝낸 상태
- Backchannel: “응”, “맞아”, “uh-huh” 같은 짧은 맞장구라서 시스템 발화를 끊으면 안 되는 상태
- Wait: “잠깐”, “그만”, “shut up”처럼 시스템에게 멈추거나 pause하라고 하는 상태
✔️ Architecture & Method
-
Input : 사용자의 음성 (speech)
별도의 ASR을 앞단에 두지 않고 음성을 직접 받습니다. 이게 논문에서 주장하기로 TEN Turn Detection 대비 장점으로 강조되는 부분입니다. TEN Turn Detection은 텍스트만 받기 때문에 ASR을 거쳐야 하고, 그 과정에서 acoustic 정보(억양, 멈춤, 말끝 흐려짐 등)가 손실되는 문제가 있을 수 있기 때문입니다. -
Output
두 가지를 동시에 출력합니다:
(1) ASR transcription - 입력 음성에 대한 텍스트 전사
(2) Dialogue turn state - 네 가지 중 하나로 분류
Easy Turn Corpus
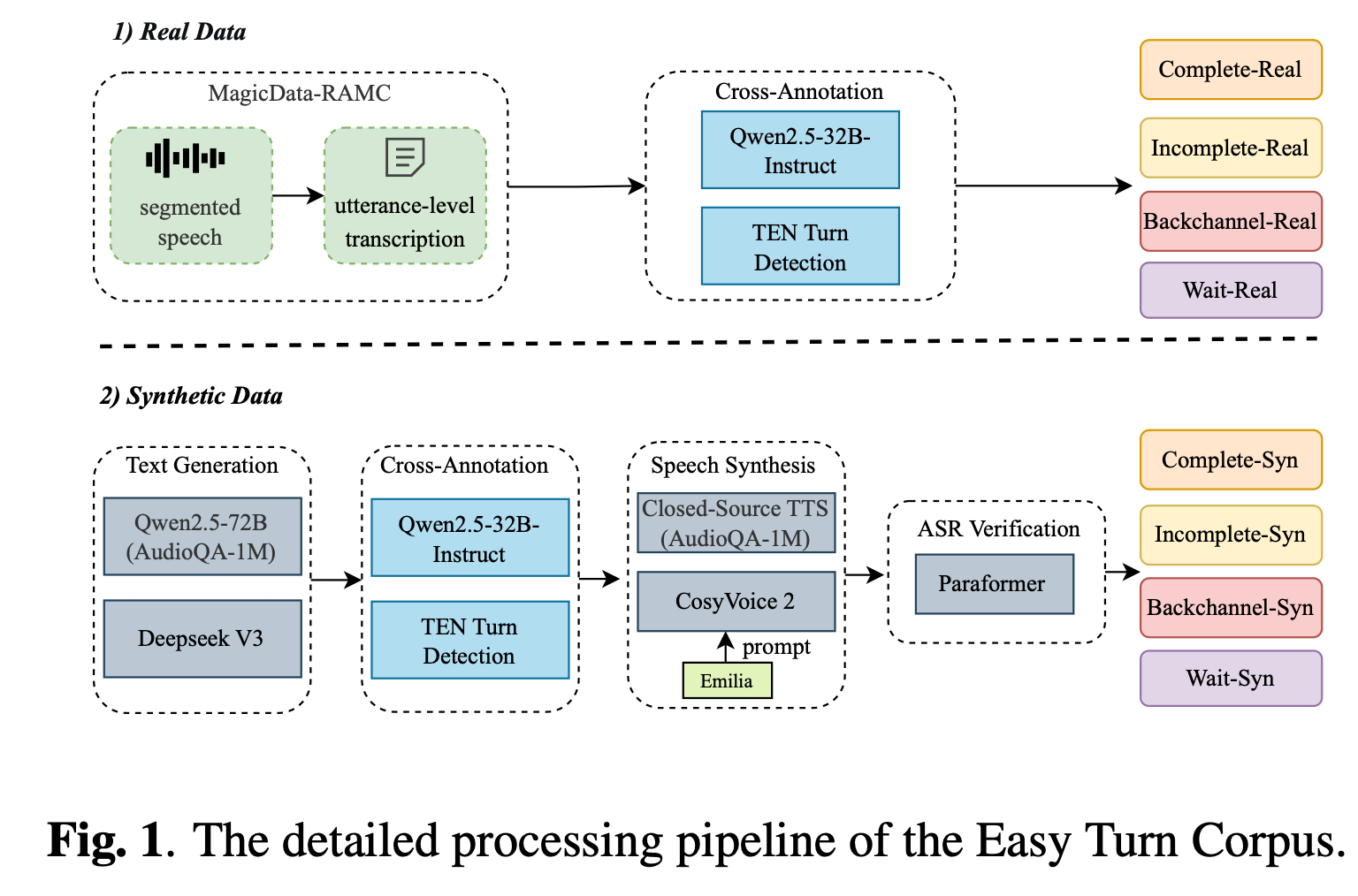
이 논문의 큰 기여 중 하나는 모델만이 아니라 Easy Turn Corpus를 함께 공개한다는 점입니다. 2페이지 Figure 1을 보면, 데이터 구축 파이프라인이 real data와 synthetic data 두 축으로 나뉘어 설계되어 있습니다.
- real 쪽은 MagicData-RAMC에서 utterance-level로 세그먼트한 뒤 텍스트 기반 LLM annotation을 적용하고,
- synthetic 쪽은 DeepSeek V3나 Qwen2.5-72B로 텍스트를 생성한 후 TTS와 ASR 검증까지 거쳐 품질을 맞추는 구조입니다.
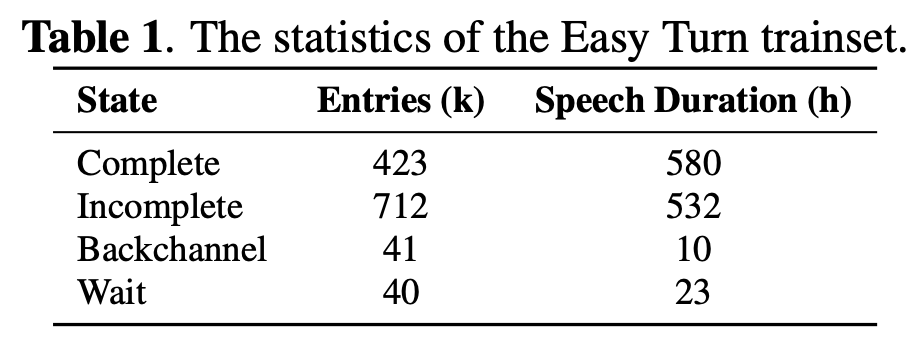
Trainset은 총 1,145시간이며, Table 1기준으로
- complete: 423k entries / 580h
- incomplete: 712k entries / 532h
- backchannel: 41k / 10h
- wait: 40k / 23h
로 구성됩니다.
즉, entry 수 기준으로는 incomplete가 가장 많고, backchannel과 wait는 상대적으로 작습니다.
그 외
- 텍스트 생성: DeepSeek V3/ Qwen2.5-72B로 4가지 turn state(complete/incomplete/backchannel/wait)에 맞는 문장을 대량 생성
- Cross-Annotation: Qwen2.5-32B-Instruct와 TEN Turn Detection 두 모델로 라벨링해서, 둘 다 같은 라벨을 준 텍스트만
- Speech Synthesis: 필터링된 텍스트를 CosyVoice 2로 TTS 변환 (Emilia 코퍼스를 화자 음색 reference로 사용)
- ASR Verification: 합성된 음성을 Paraformer로 다시 인식해서, 원본 텍스트와 WER=0으로 일치하는 샘플만 최종 채택
2. 모델 구조: Whisper + Adaptor + Qwen2.5]
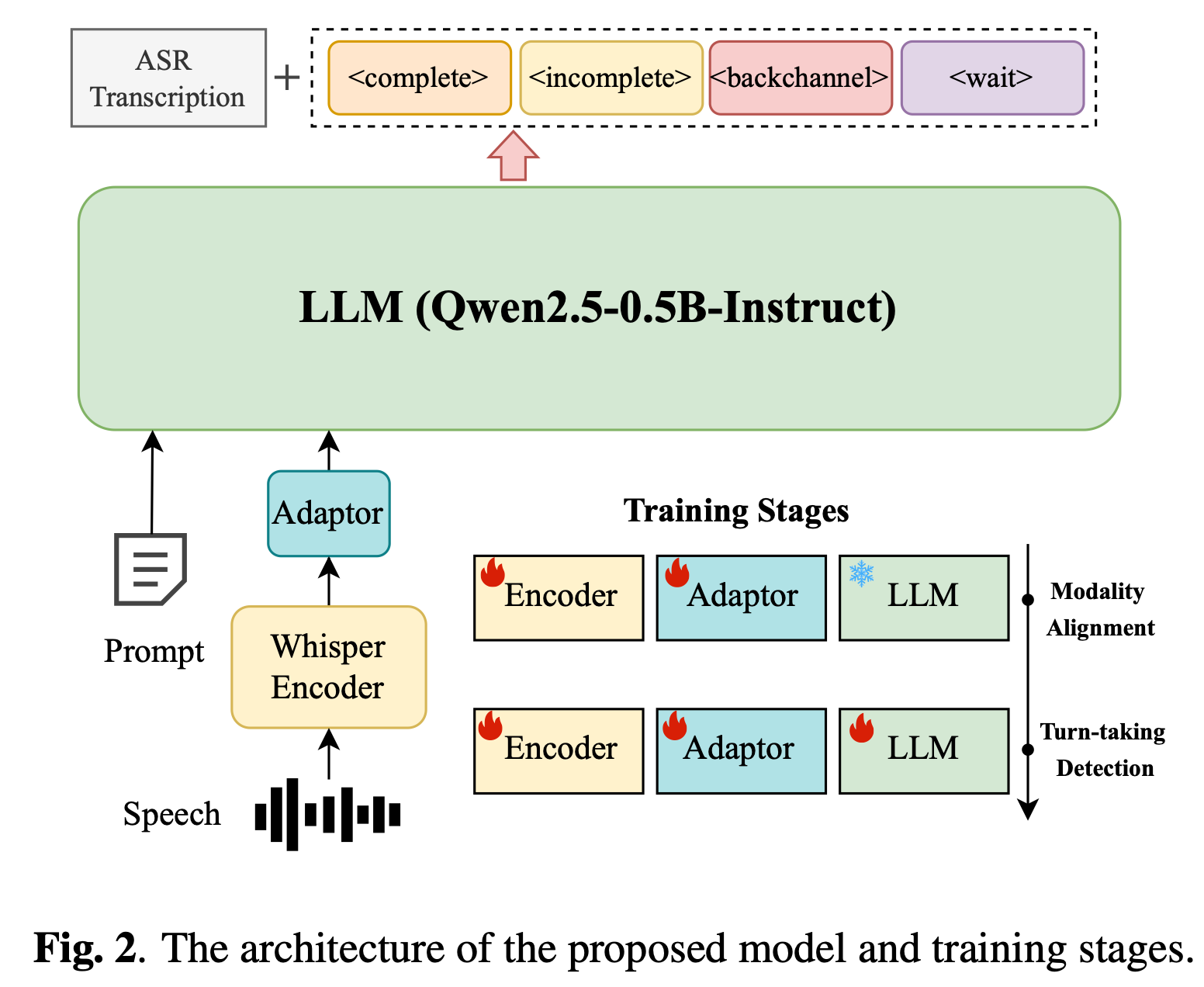
- Audio Encoder: Whisper-Medium
- Audio Adaptor: 3개의 1D convolution + 4개의 Transformer layer
- LLM: Qwen2.5-0.5B-Instruct
(1) Qwen2.5-7B 같은 대형 모델이 아니라 0.5B를 선택해, turn-taking이라는 비교적 간단한 목적에 맞게 경량화와 실용성을 챙깁니다.
(2) Whisper는 음성 자체의 pause, prosody, hesitation 같은 acoustic cue를 포착하고, 생략된 transcript는 semantic completeness를 반영하므로, 두 모달리티가 서로 보완되도록 설계되었습니다.
3. ASR + Turn-Detection
LLM이 먼저 ASR transcription을 생성하고, 이어서 acoustic feature와 결합해 complete / incomplete / backchannel / wait를 순차적으로 예측합니다. 저자들은 이를 위해 자연어 prompt를 사용하고, DeepSeek V3가 생성한 5개의 후보 prompt 중 하나를 학습 중 랜덤 샘플링해 robustness를 높였다고 설명합니다.
이 부분이 중요한 이유는, 기존 acoustic-only classifier가 잘 보기 어려운 “의미적으로 아직 문장이 안 끝났는가?” 같은 문제를 transcript가 보완해주기 때문입니다. 반대로 text-only 방식은 pause나 짧은 맞장구의 음향적 특성을 놓치기 쉬운데, Easy Turn은 이를 음향 표현으로 메웁니다.
4. 학습 전략
학습은 2단계로 진행됩니다.
(1) 먼저 modality alignment training 단계에서, Aishell1/2, WenetSpeech, 내부 ASR 데이터를 포함한 23,000시간 규모의 ASR 데이터로 acoustic-linguistic alignment를 맞춥니다. 이때는 LLM을 freeze하고 encoder와 adaptor만 학습합니다.
(2) 이후 두 번째 단계에서는 Easy Turn trainset으로 turn-taking 전용 학습을 수행하며, 이때는 encoder / adaptor / LLM 전체를 full fine-tuning합니다.
처음부터 turn-taking만 학습시키면 음성과 텍스트 정렬이 약할 수 있는데, 먼저 대규모 ASR로 representation alignment를 만든 뒤, 그 위에서 downstream turn policy를 얹는 구조입니다.
✔️ Dataset & Evaluation
Testset은 총 800개 샘플로 구성됩니다.
- complete 300
- incomplete 300
- backchannel 100
- wait 100
이며,
real : synthetic = 1 : 1로 맞췄고, trainset 외부 출처의 transcription을 사용해 독립성을 확보하려고 했습니다.
또 state annotation은 수동 라벨링으로 진행합니다.
비교 대상은 두 오픈소스 모델입니다.
하나는 Paraformer + TEN Turn Detection, 다른 하나는 Smart Turn V2입니다. 평가 지표는 각 상태별 accuracy와 함께, 모델 크기, 평균 latency, GPU memory usage를 함께 봅니다.
✔️ Results
1. 메인 결과

2. Ablation 결과

- 두 modality 함께 황용
✔️ Resources
