Speech & Audio
1.[Paper Review] – LoopGen: Training-Free Loopable Music Generation

반복 재생되는 음악에서 전환의 부자연스러움을 해결하기 위해, circular padding과 beat alignment를 활용한 training-free 루프 생성 방식인 LoopGen을 제안
2.[Paper Review] – FlowSep: Fast and Accurate Language-Queried Sound Separation via Rectified Flow Matching
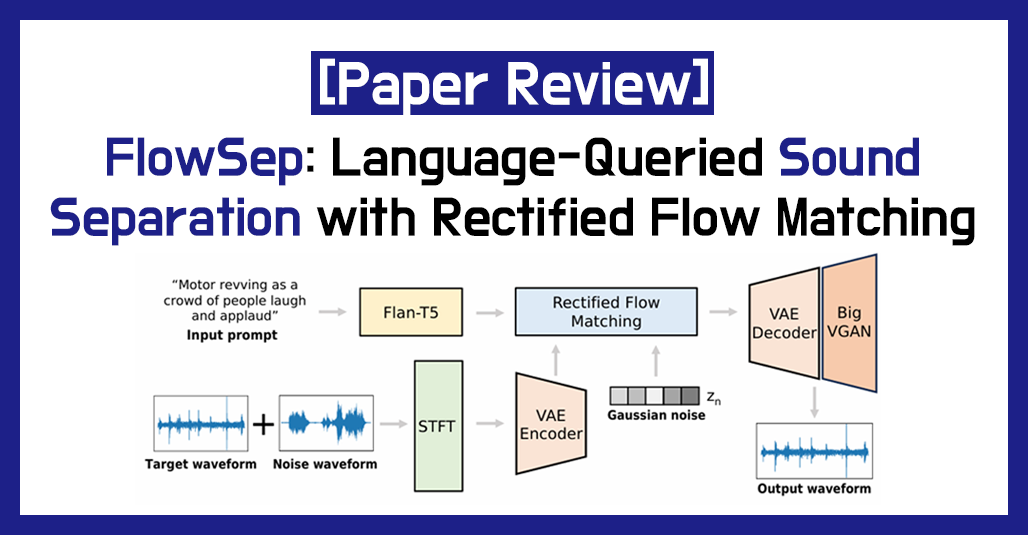
자연어로 원하는 소리만 분리해주는 FlowSep 모델 제안. Rectified Flow Matching 기반 생성 방식으로 빠르고 깔끔한 오디오 분리가 가능하다.
3.[Paper Review] Game-Oriented ASR Error Correction via RAG-Enhanced LLM
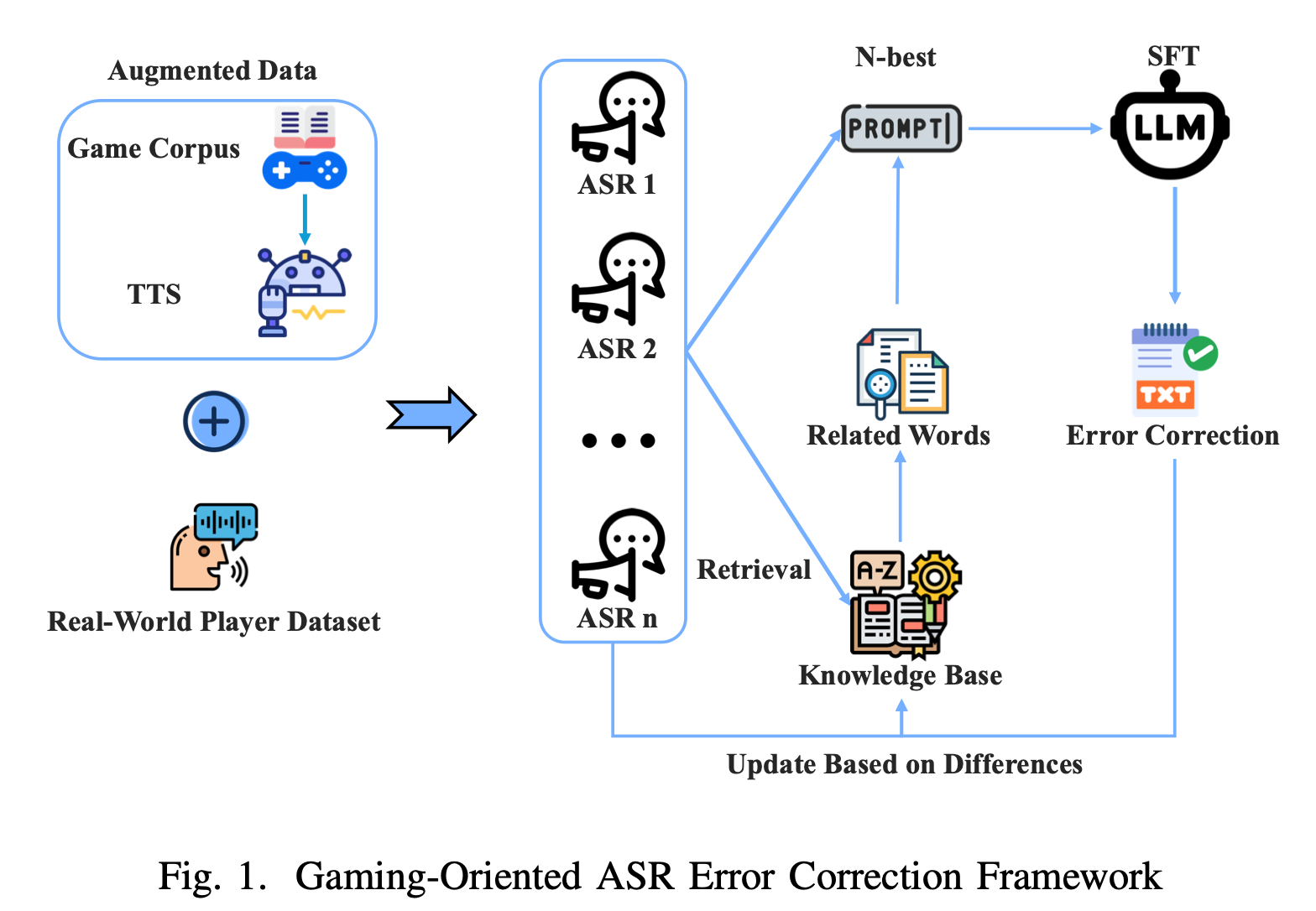
ASR for game domain
4.[Paper Review] VoXtream: Full-Stream Text-to-Speech with Extremely Low Latency
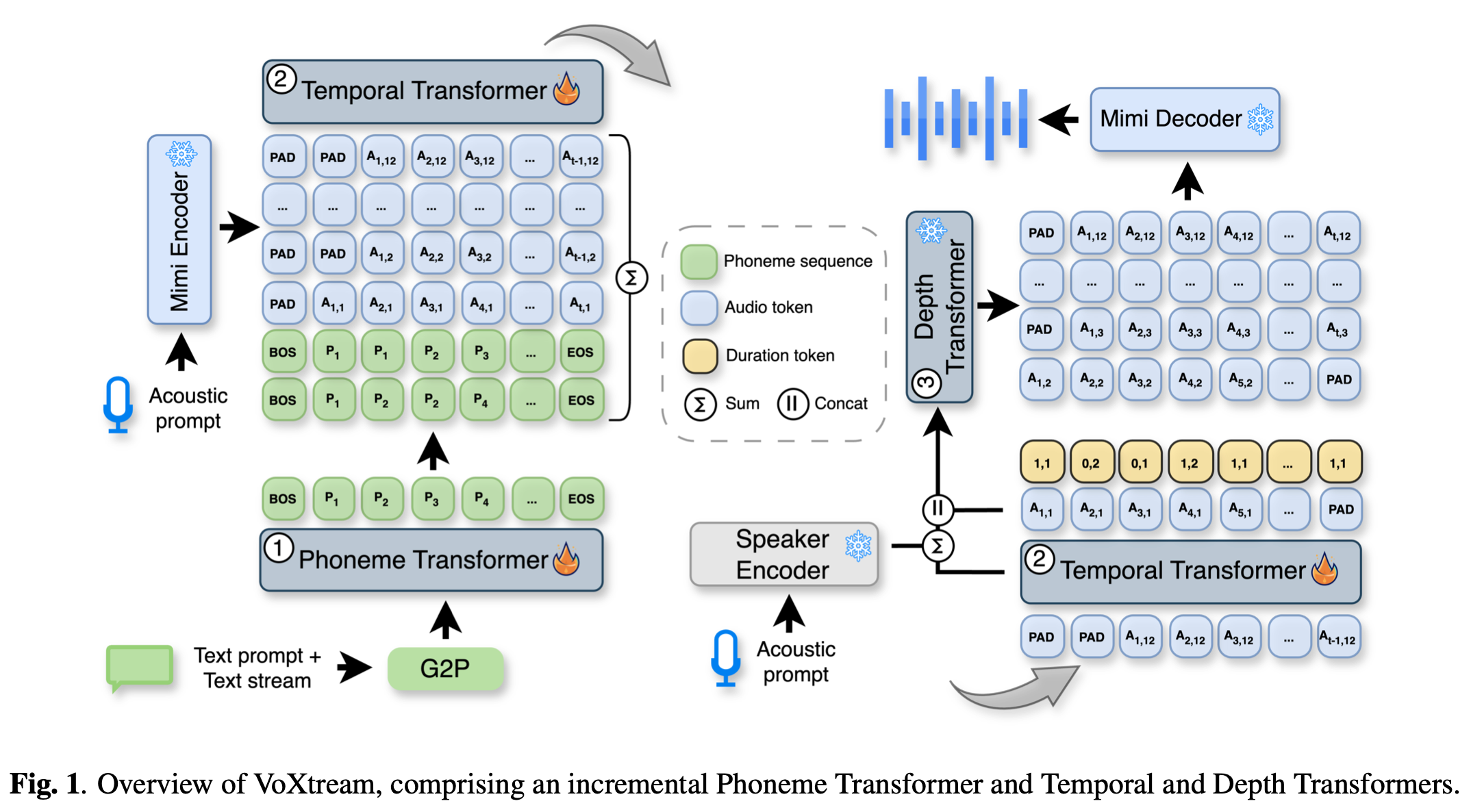
VoXtream / Streaming TTS / 102ms FPL
5.[Paper Review] moshi - temporal/depth transformer
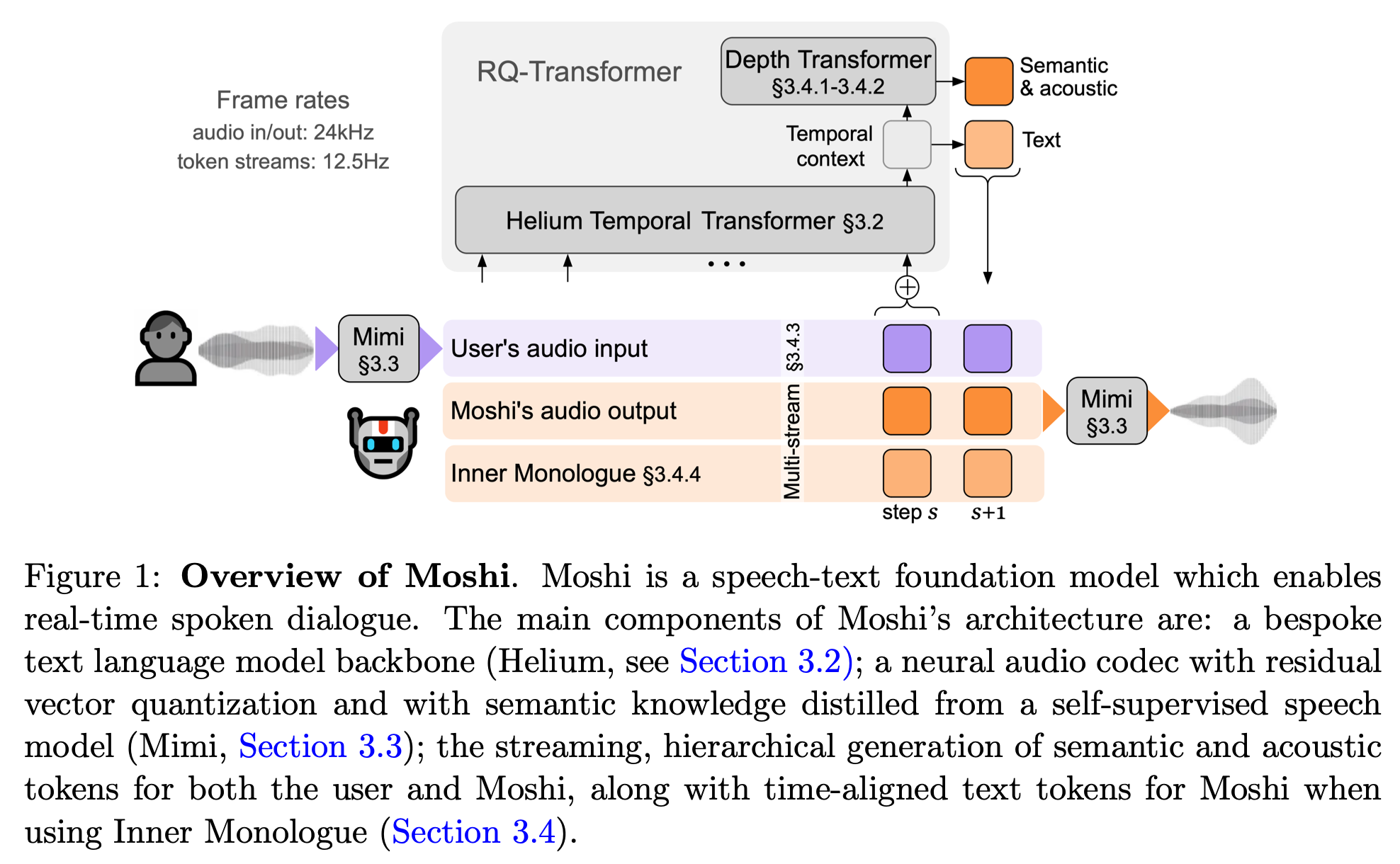
moshi - temporal and depth transformer
6.[Paper Review] GLASS Flows

GLASS Flows: Transition Sampling for Alignment of Flow and Diffusion
7.[Paper Review] FSPEN: An Ultra-Lightweight Network for Real Time Speech Enhancement
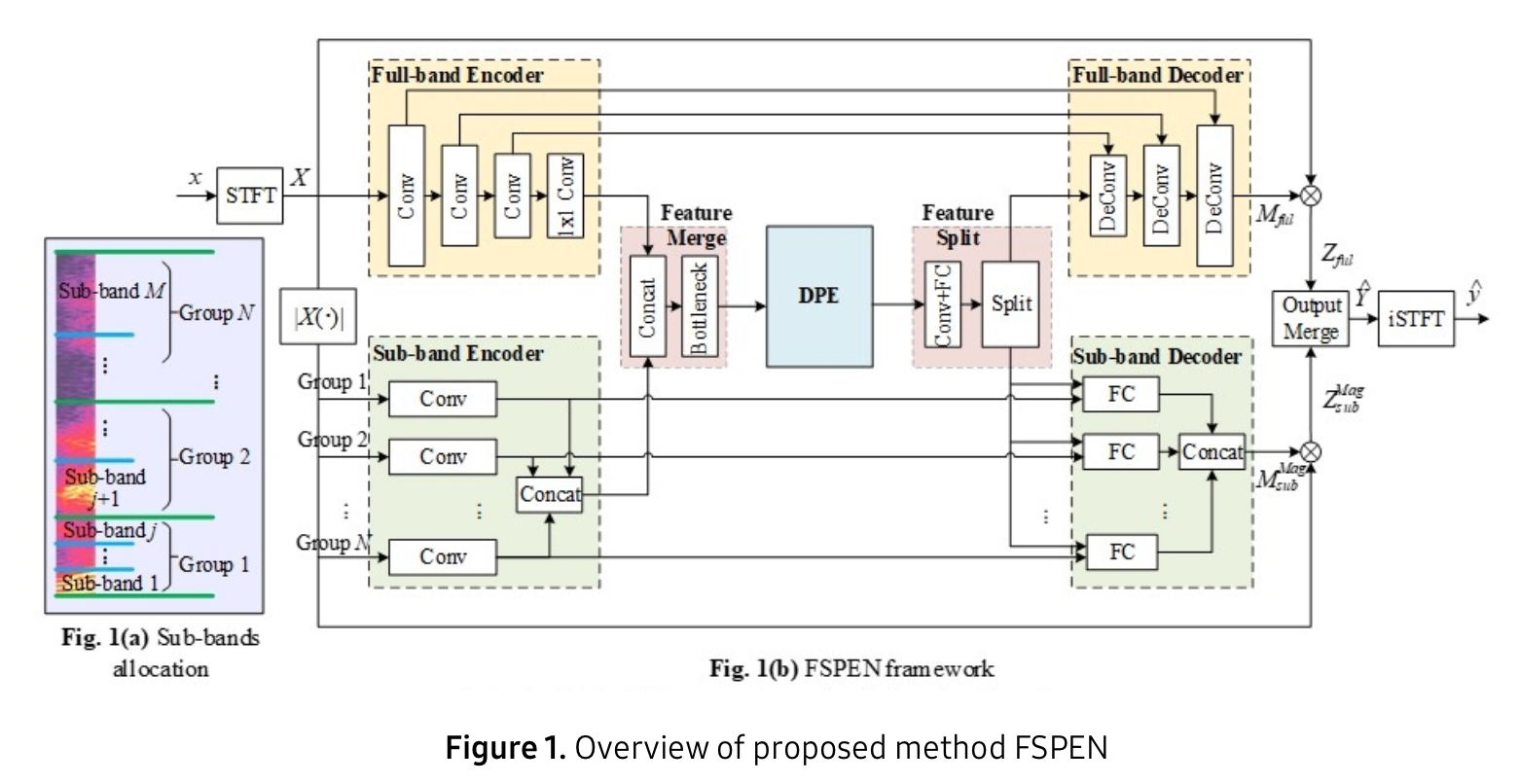
출처: https://research.samsung.com/blog/FSPEN-AN-ULTRA-LIGHTWEIGHT-NETWORK-FOR-REAL-TIME-SPEECH-ENAHNCMENT 최근에 speech enhancement 분야를 보고 있는 중인데, 경량화된 모
8.DNS/URGENT 챌린지
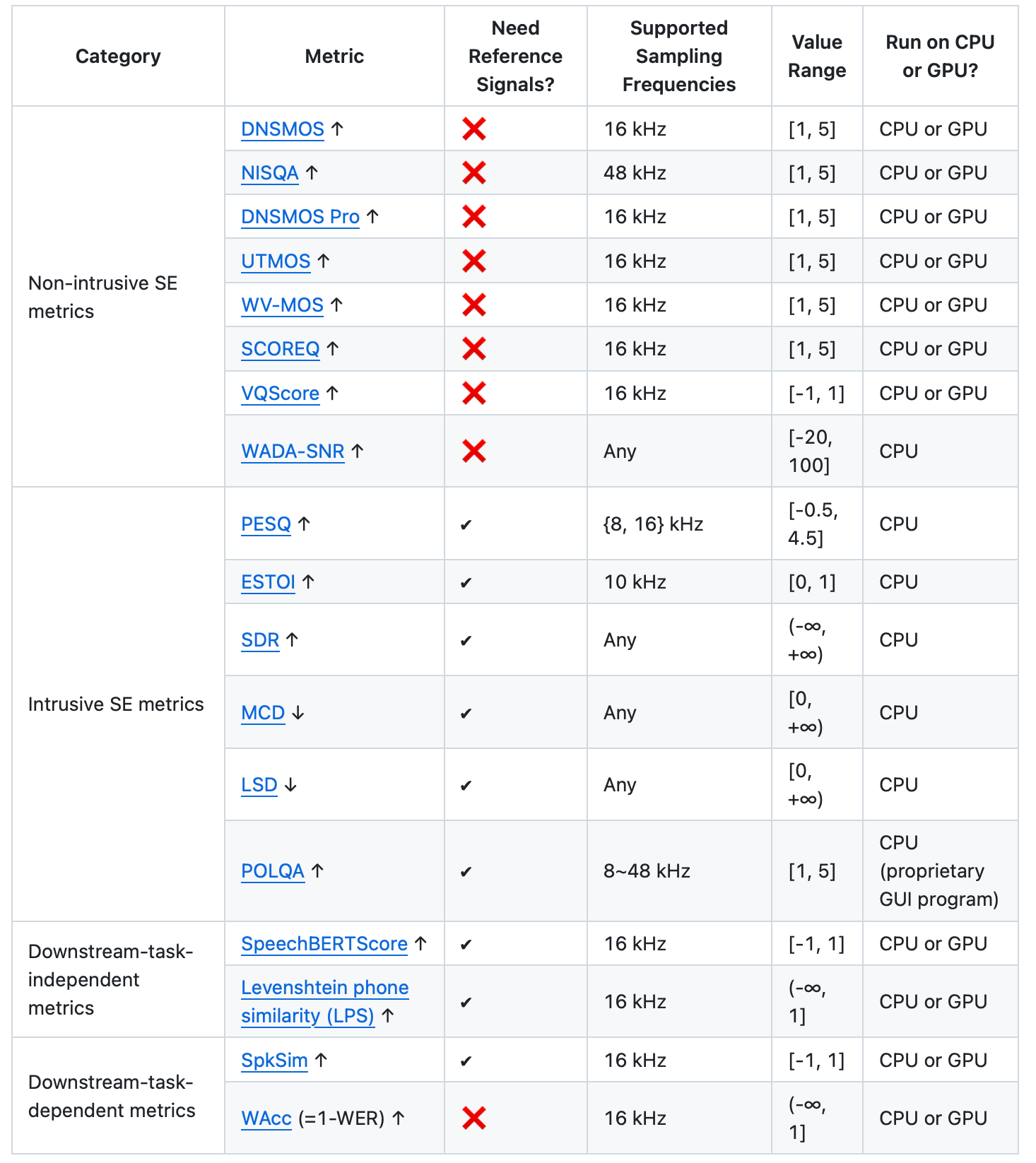
DNS 챌린지와 URGENT 챌린지 소개
9.[Paper Review] – StreamFlow: Streaming Audio Generation from Discrete Tokens via Streaming Flow Matching
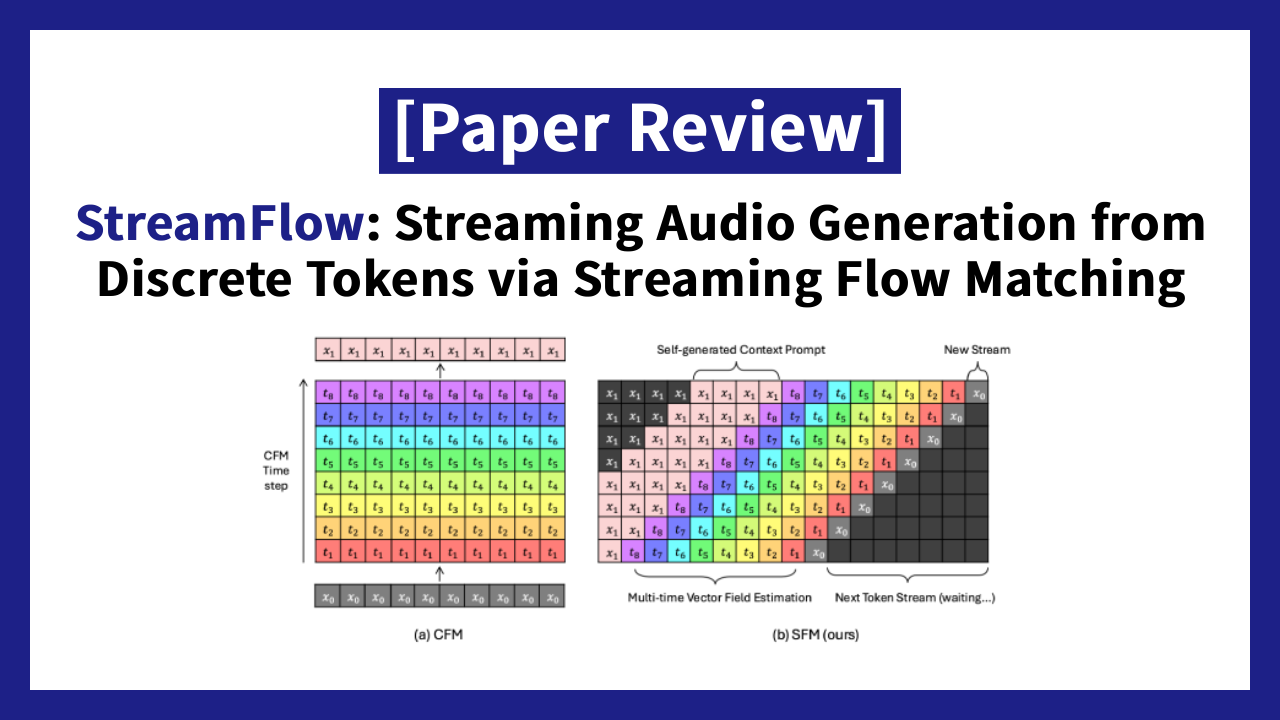
#streaming_decoder(≈vocoder)
10.[Paper Review] – Qwen3-TTS

qwen3-tts
11.kaldi 세팅하기
kaldi 세팅하기..
12.[Paper Review] Emotion Concepts and their Function in a Large Language Model
https://transformer-circuits.pub/2026/emotions/index.html 작성중..
13.화자 분리(Speaker Diarization) 기초 (1) - MFCC
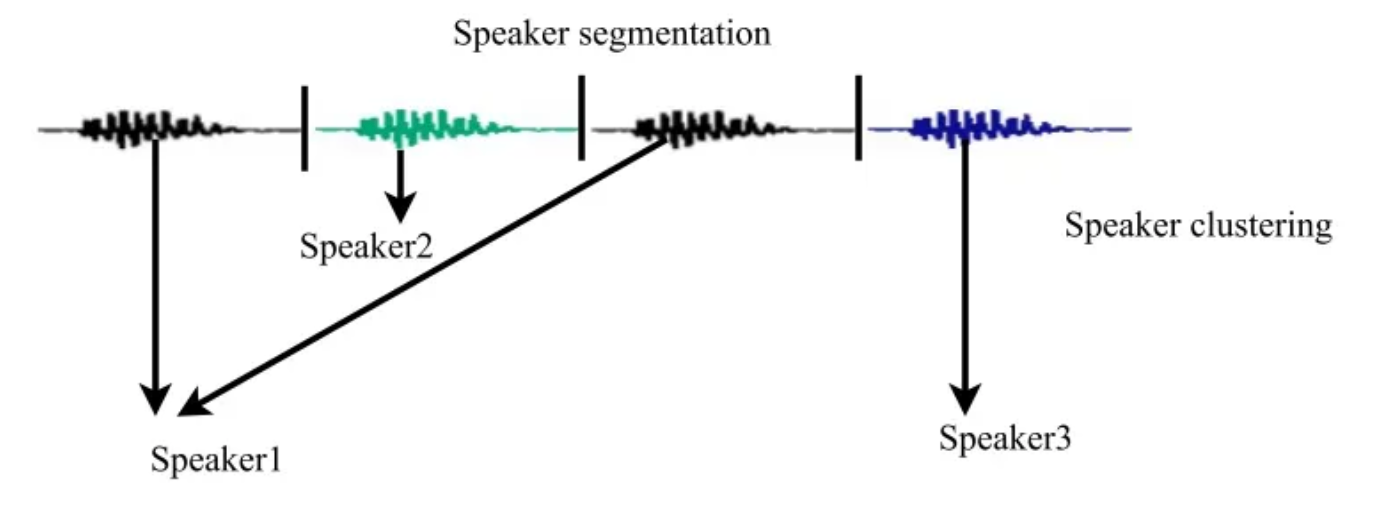
시작하기 전에... 용어를 헷갈려 하실까봐 spectrum, spectrogram, mel spectrogram, mfcc 의 차이를 간단히 정리하자면 이와 같습니다. 이미지 출처 waveform → (pre-emphasis) → STFT(framing(hamming window, overlap, hop size) → 각 프레임에 DFT(실제로는 연산 ...
14.[Paper Review] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
https://arxiv.org/abs/2306.00978 작성중..
15.화자 분리(Speaker Diarization) 기초(2) - VAD, UBM
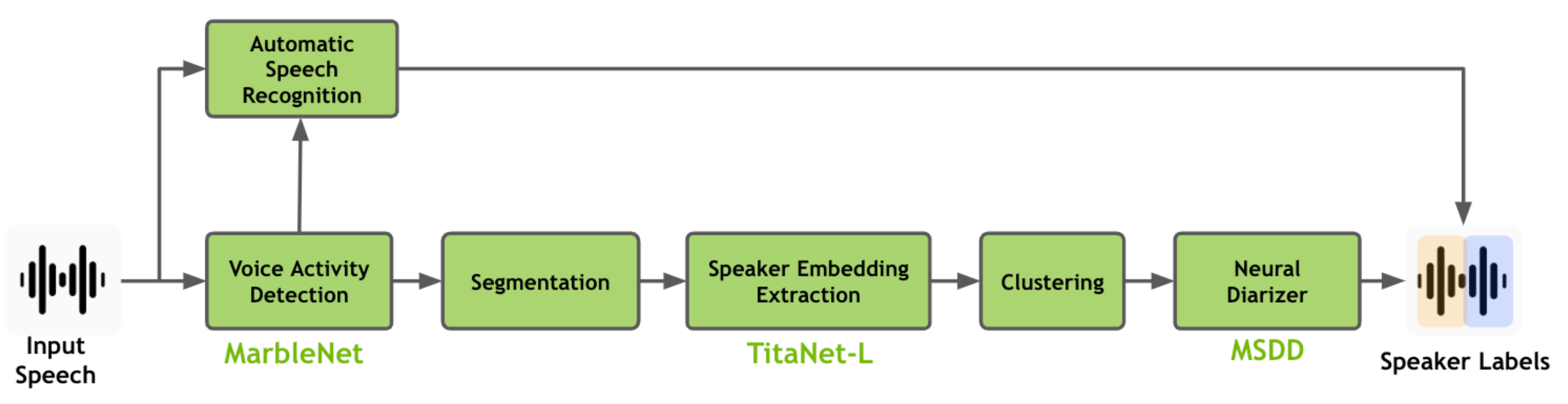
작성중
16.[Paper Review] Easy Turn: Integrating Acoustic and Linguistic Modalities for Robust Turn-Taking in Full-Duplex Spoken Dialogue Systems
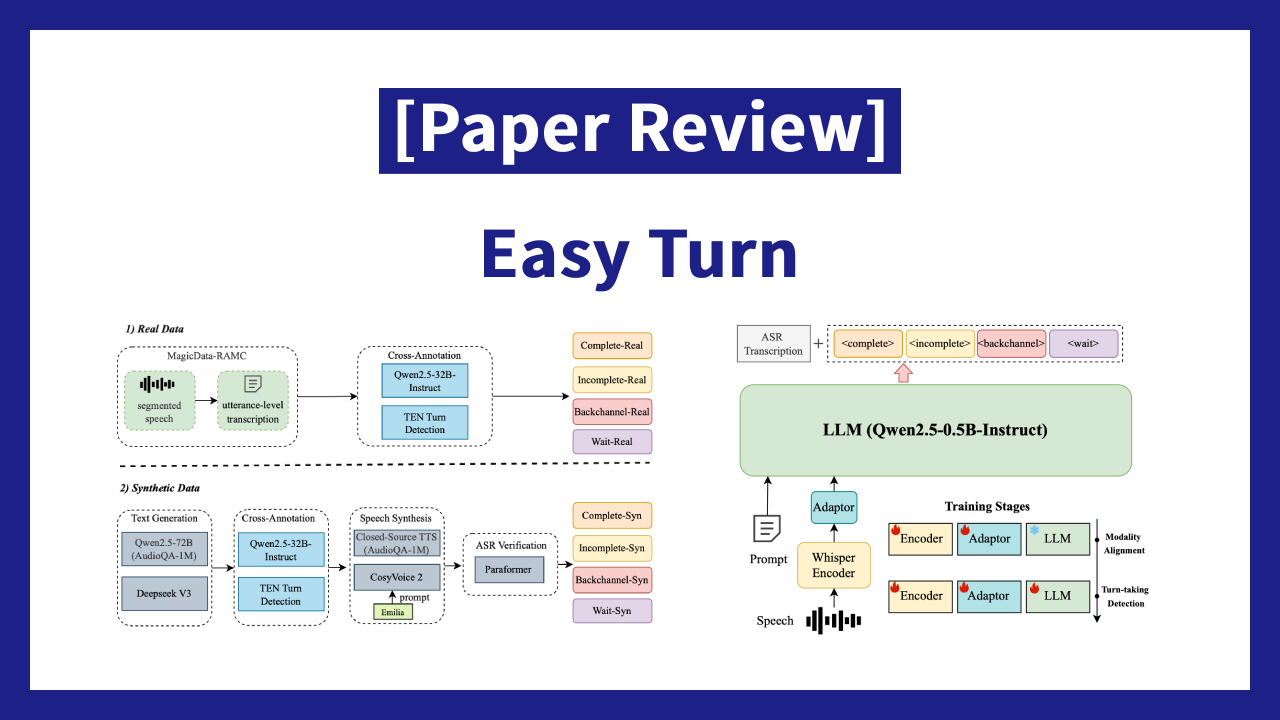
#Full-duplex spoken dialogue systems #turn taking detection #음향과 언어를 함께 써서, 더 자연스러운 대화를 만들 수 있을까? ✔️ 배경 최근 spoken dialogue system은 단순히 “질문하면 대답하는”
17.[Paper Review] DialogueSidon: Recovering Full-Duplex Dialogue Tracks from In-the-Wild Dialogue Audio
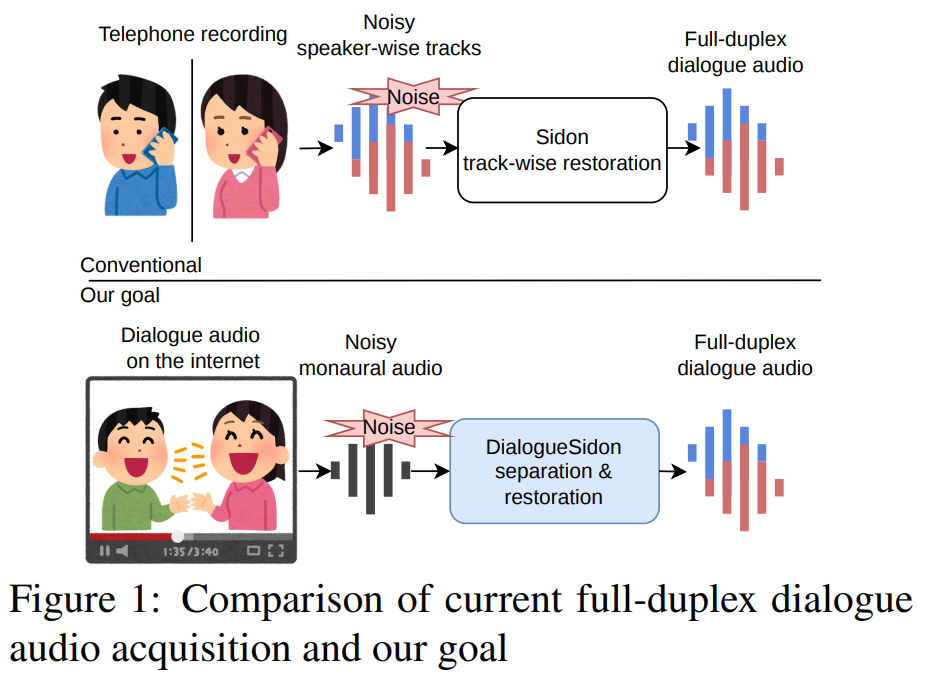
How can we make a better dataset from in-the-wild data for training full-duplex models? ✔️ Background Training a full-duplex spoken dialogue model requires dialogue recordings where each speaker is o...