[Paper Review] Test-time Alignment of Diffusion Models without Reward Over-optimization
Test-time Alignment of Diffusion Models without Reward Over-optimization
Intro
이번에 리뷰하는 논문은 test-time에서 사용자가 원하는 reward 방향으로 생성 결과를 조절할 수 있는 방법을 제시한 연구입니다. 이 논문이 하고자 하는 방향은 모델을 다시 학습시키는 것이 아니라, 이미 학습된 생성 모델이 만들어낼 수 있는 수많은 가능성 중에서 더 좋은 것들이 자연스럽게 더 자주 선택되도록 만드는 것입니다.
이를 위해 논문은 샘플링 방식을 변화시키고자 이 아이디어를 Diffusion Alignment as Sampling(DAS)이라는 개념으로 정리하고, 이를 구현하기 위해 Sequential Monte Carlo(SMC)라는 확률적 샘플링 기법을 확산 모델의 생성 과정에 결합합니다.
Related Work
기존의 reward alignment 방식들은 대부분 fine-tuning을 기반으로 합니다. 예를 들어 '이 그림이 예쁘다'거나 '사람들이 더 선호한다'는 신호를 주고, 모델이 그런 샘플을 더 많이 생성하도록 파라미터를 업데이트하는 방식입니다. 하지만 이 접근은 구조적인 한계를 가집니다. 보상 함수를 직접 최적화하면 모델은 그 보상을 가장 잘 만족시키는 몇 개의 결과에 집착하게 되고, 그 결과 생성 분포가 원래의 다양하고 풍부한 분포에서 벗어나 하나의 모드로 붕괴됩니다. 이것이 바로 reward over-optimization이며, 결과적으로 다양성과 일반성이 사라지게 됩니다.
반대로 classifier-free guidance와 같은 approximate guidance 방식은 모델을 바꾸지 않는다는 장점이 있지만, noisy latent 상태에서 깨끗한 샘플을 추정한 뒤 reward를 계산하기 때문에 posterior gradient가 부정확해지고, 결국 보상을 충분히 최적화하지 못하는 under-optimization 문제가 발생합니다.
Method
이 논문이 제시하는 DAS의 관점은 이러한 한계를 근본적으로 다르게 바라봅니다. 우리가 사실상 원하는 것은 모델의 파라미터를 바꾸는 것이 아니라, 보상에 의해 재가중된 확률분포에서 샘플을 뽑는 것입니다.
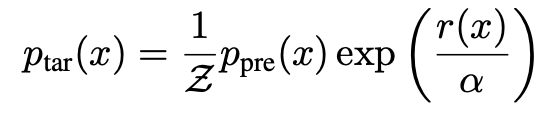
여기서 p_pre는 원래의 diffusion 모델이 만들어내는 분포이고, r(x)는 보상 함수이며, alpha는 보상과 원래 분포 사이의 균형을 조절하는 temperature 입니다. 이 식에는 KL regularization의 의미가 포함되어 있는데, 이는 보상이 아무리 높더라도 pretrained 분포에서 너무 멀어지는 샘플에는 자연스럽게 패널티가 주어지도록 하는 역할을 합니다.

DAS는 이 target 분포를 직접 샘플링하기 위해 diffusion trajectory 전체에서 SMC를 수행합니다. 확산 모델은 노이즈 x_T에서 시작해 점점 더 구조화된 샘플 x_0로 이동하는데, DAS는 이 각 timestep마다 “중간 목표 분포”를 정의하고 여러 개의 particle을 동시에 이동시키면서 보상과 pretrained 분포를 함께 고려해 입자들을 선택하고 복제합니다.
이 과정에서 가장 중요한 장치가 tempering입니다. 초기에는 lambda_t가 0에 가까워 거의 순수한 pretrained diffusion을 따르며, 시간이 지날수록 lambda_t가 1로 증가하면서 reward posterior의 영향이 점점 커집니다. 이는 noisy한 초반 단계에서 잘못된 reward gradient에 끌려 off-manifold로 벗어나는 것을 방지하고, 샘플이 깨끗해질수록 정확한 보상 신호를 반영하도록 만드는 메커니즘입니다.
각 particle은 매 step에서 기본 diffusion drift에 더해 reward gradient가 추가된 방향으로 이동합니다. 이후 각 입자는 자신의 weight를 부여받아 resampling되며, 이 과정을 반복하면서 점점 reward-aligned posterior에 집중됩니다. 중요한 점은 이 과정이 모델 파라미터를 전혀 바꾸지 않으면서도, 이론적으로 particle 수가 충분하면 정확한 target 분포로 수렴하는 asymptotically exact한 샘플링이라는 점입니다.
Result
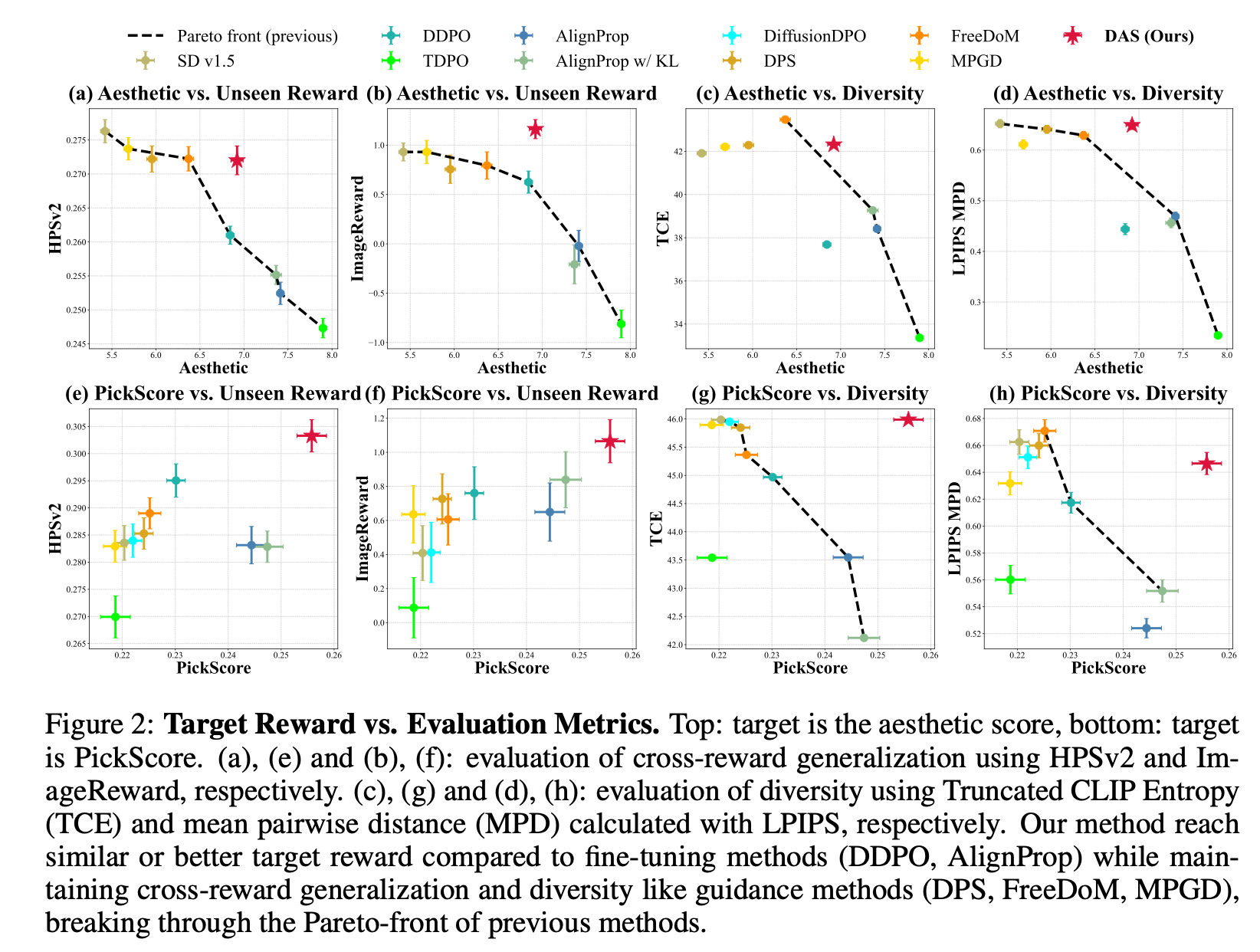
먼저 위쪽 행은 Aesthetic score를 목표로 최적화했을 때의 결과를 보여줍니다. 이때 DDPO나 AlignProp과 같은 fine-tuning 기반 방법들은 Aesthetic 점수가 올라갈수록 HPSv2나 ImageReward와 같은 다른 평가 지표가 급격히 감소하는 경향을 보입니다. 이는 모델이 미적 점수를 높이는 데 가장 유리한 특정 스타일이나 패턴에 과도하게 집착하면서, 다른 기준에서 보았을 때는 오히려 전반적인 품질이 저하되는 전형적인 reward over-optimization 현상을 나타냅니다. 동시에 이러한 방법들은 다양성 지표에서도 큰 하락을 보이는데, 이는 생성 결과가 한두 개의 모드로 붕괴되어 더 이상 다양한 스타일을 생성하지 못함을 의미합니다.
반대로 DPS, FreeDoM, MPGD와 같은 guidance 계열 방법들은 이미지의 다양성을 비교적 잘 유지하고 unseen reward 역시 어느 정도 보존하지만, Aesthetic score 자체를 크게 끌어올리지는 못합니다. 즉, 이러한 방법들은 목표 보상을 충분히 최적화하지 못하는 under-optimization 상태에 머무르게 됩니다.
이에 비해, 그림에서 빨간 별로 표시된 DAS는 Aesthetic score가 매우 높은 영역에 위치하면서도 HPSv2와 ImageReward와 같은 unseen reward 역시 높은 값을 유지하고, TCE와 LPIPS MPD로 측정한 다양성도 크게 감소하지 않습니다. 이는 DAS가 미적 점수를 높이기 위해 생성 분포를 한 방향으로 왜곡하는 것이 아니라, 원래의 생성 분포를 유지한 채 그 안에서 보상이 높은 영역을 정확하게 샘플링하고 있음을 의미합니다.
Conclusion
결론적으로, test-time에서 Sequential Monte Carlo(SMC)를 이용해 alignment를 수행하는 방식은 보상을 안정적으로 반영하면서도 분포의 다양성과 일반화를 유지할 수 있는 방법입니다. 이 접근은 모델 파라미터를 변경하지 않고 posterior 분포에서 직접 샘플링한다는 점에서 확률적 생성 모델 전반에 일반적으로 적용될 수 있는 방법론이라는 점에서 의의를 가집니다.
