[Paper Review] VoXtream: Full-Stream Text-to-Speech with Extremely Low Latency
Speech & Audio
느낀 점 :
최근 들어 실시간 음성합성(Streaming Text-to-Speech) 기술에 대한 수요가 점점 더 증가하고 있습니다. 음성은 가장 기본적이고 전통적인 의사소통 방법인데, 최근 AI와의 상호작용이 일상으로 확장되면서 관련 연구가 활발히 진행되고 있습니다. 대화형 AI 로봇, 게임 내 NPC와의 실시간 대화, 웨어러블 디바이스의 음성 비서 등 다양한 응용 시나리오에서 지연 없이 즉각적으로 반응하는 음성 합성이 핵심 요구사항이 되고 있으며, 본 논문 역시 이러한 문제의식 아래 low latency TTS를 목표로 제안된 모델입니다.
그런데 최근 Streaming TTS 논문들을 보면 AR(Autoregressive) 모델을 많이 활용하고 있습니다. 과거에는 지연 시간 개선을 위해 NAR(Non-Autoregressive) 모델을 사용했던 것을 생각하면 모순되는 것 아닌가 하는 의문이 들었습니다. 하지만 다시 생각해보니 이는 문제 설정의 변화에 따른 합리적인 구조 선택이었습니다.
과거에는 음성 합성 모델의 성능을 평가할 때 전체 합성 속도, 즉 문장 전체를 입력했을 때 얼마나 빠르게 전체 음성을 생성하는지가 주요 기준이었습니다. 이 관점에서 Tacotron 계열 같은 AR 모델은 한 프레임씩 순차적으로 생성해야 해서 추론 시간이 길다는 한계가 있었고, 이를 개선하기 위해 FastSpeech 같은 NAR 모델이 등장했습니다. NAR 모델은 병렬 생성이 가능해 합성 속도가 빠르고 대규모 배치 처리에 유리했으며, 당시 기준에서는 합리적인 선택이었습니다.
하지만 Streaming TTS라는 새로운 문제 설정에서는 평가 기준 자체가 달라집니다. 중요한 것은 더 이상 "문장 전체를 얼마나 빨리 끝내느냐"가 아니라, "첫 음성이 얼마나 빨리 출력되느냐"와 "중간에 끊김 없이 자연스럽게 이어지느냐"입니다. 사용자가 말하거나 텍스트를 입력하는 즉시 반응해야 하는 실시간 환경에서는 문장의 끝을 기다린 뒤 한 번에 음성을 생성하는 방식이 구조적으로 불리할 수밖에 없습니다.
이러한 맥락에서 Voxtream이나 Microsoft의 Vibevoice 같은 최근 모델들이 다시 AR 구조를 채택하고 있다는 점은 흥미롭습니다. AR 모델은 본질적으로 causal한 구조를 가지기 때문에 미래 토큰 정보 없이도 이전 상태만으로 다음 음성을 생성할 수 있으며, 이는 streaming 환경에서 큰 장점이 됩니다. 특히 prosody, 억양, 감정 같은 연속적인 음향적 특성을 이전 프레임에 자연스럽게 연결할 수 있어, chunk 단위로 생성하더라도 발화가 끊어진 느낌이 적습니다. 반면 NAR 모델은 duration 예측이나 prosody 모델링 과정에서 문장 전체 정보를 암묵적으로 필요로 하는 경우가 많아, streaming 환경에서는 chunk 경계에서 부자연스러움이 발생하기 쉽습니다.
결론적으로, 배치 기반 오프라인 합성이나 대량 음성 생성에서는 NAR 모델이 여전히 강점을 가지지만, 대화형 AI나 게임 NPC, 음성 에이전트처럼 실시간 반응성과 자연스러운 발화 흐름이 중요한 환경에서는 AR 기반 Streaming TTS가 더 적합해 보입니다. 그래서 저라면 data augmentation이나 콘텐츠 제작용 대본 기반 음성 생성에는 F5-TTS 같은 NAR 모델을, 실시간 AI 대화 상황에서는 AR 모델을 선택할 것 같습니다.
아무튼, Voxtream이 어떻게 Streaming TTS 모델을 설계했을까 생각하다 보니 전반적인 모델 선택에 대한 고민을 해볼 수 있었던 재밌는 논문이었습니다.
Paper Info
- Title: VoXtream: Full-Stream Text-to-Speech with Extremely Low Latency
- Authors: Nikita Torgashov, Gustav Eje Henter, Gabriel Skantze
- Affiliation: Department of Speech, Music and Hearing, KTH Royal Institute of Technology, Stockholm, Sweden
- Conference: Submitted to IEEE ICASSP 2026
- Keywords: Text-to-Speech, Speech Synthesis, Stream-ing TTS, Zero-shot TTS
요약 TL;DR
VoXtream은 입력 텍스트의 첫 단어가 들어오자마자 음성을 생성할 수 있는 초저지연(full-stream), zero-shot, autoregressive TTS 모델입니다. Mimi codec 기반으로 스트리밍 음성을 생성하며, first-packet latency 102ms로 실시간 인터랙션에 적합합니다
기존 TTS 모델들은 대부분 문장 전체를 입력받은 뒤 음성을 생성하는 구조를 가지고 있어, 스트리밍 환경에서는 구조적인 한계를 가졌습니다. 특히 사용자가 텍스트를 입력한 후 첫 음성이 출력되기까지 걸리는 시간, 즉 first-packet latency는 사용자 경험에 결정적인 요소임에도 불구하고, 이를 본격적으로 해결한 모델은 많지 않았습니다.
--> VoXtream은 이러한 문제를 해결하기 위해 텍스트가 단어 단위로 입력되는 상황에서도 첫 단어만으로 즉시 음성 생성을 시작할 수 있도록 설계되었습니다. 이를 위해 3단계 Transformer 파이프라인을 구축했습니다.
모델 아키텍처
최신 TTS 연구의 흐름인
텍스트 → 음소(Phoneme) → Semantic Token → Acoustic Token → 파형(Waveform)구조를 사용하되, 이를 스트리밍에 최적화하여 재설계했습니다.
- Phoneme Transformer: 입력된 텍스트를 실시간으로 음소화합니다.
- Temporal Transformer: 음성 데이터의 시간적 흐름을 처리합니다.
- Depth Transformer: 음성 데이터의 세부적인 특징(Acoustic)을 계층적으로 생성합니다.
주요 기술적 특징
- Monotonic Alignment: 텍스트와 음성 간의 순차적 정렬을 통해 지연을 최소화합니다.
- Dynamic Look-ahead: 필요한 만큼의 미래 정보만 참조하여 효율성을 높입니다.
- Low-latency Decoding: 텍스트가 완성되지 않은 상태에서도 끊김 없는 음성 생성을 지원합니다.
Main Problem and Key Approach
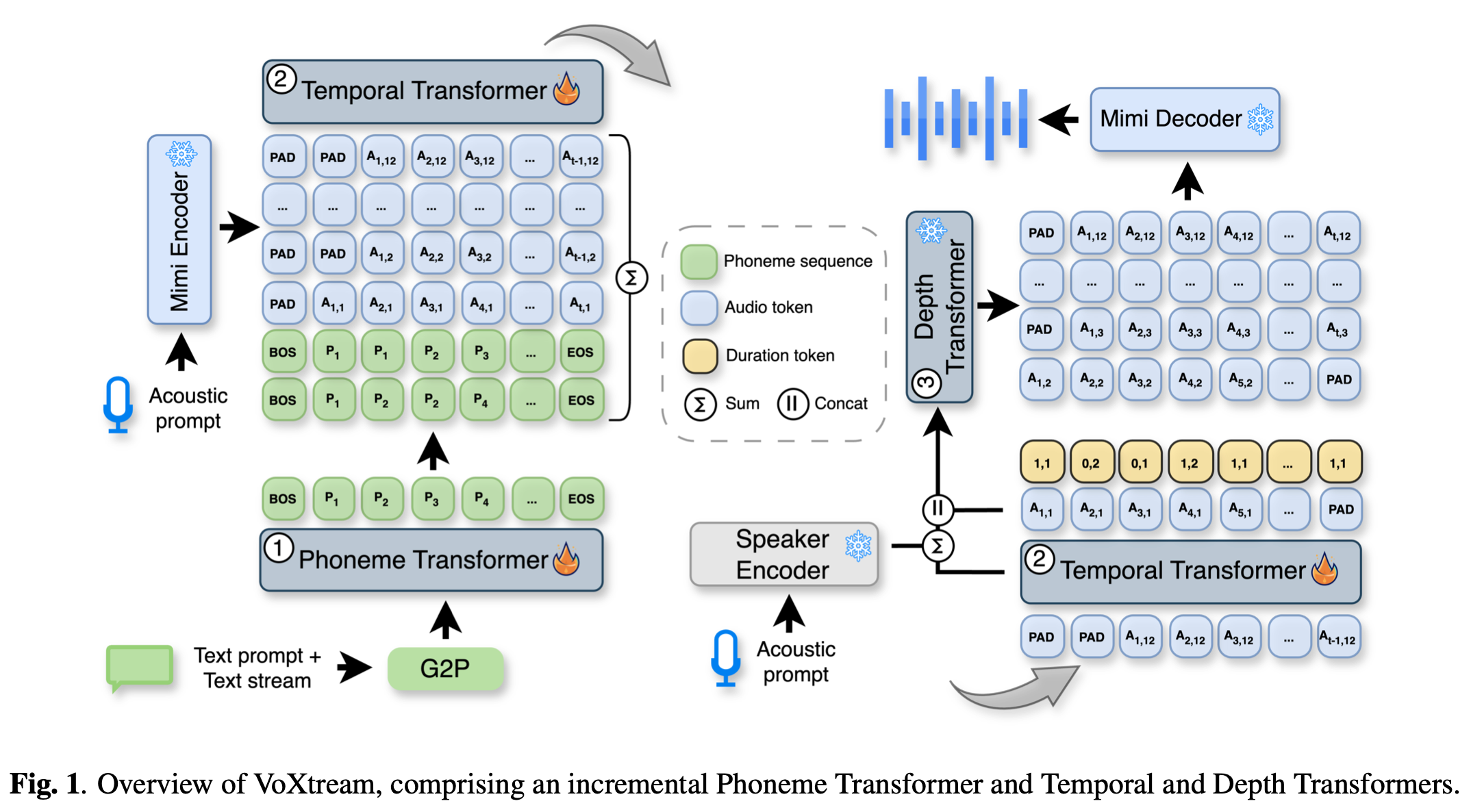
입력 전처리
기존 TTS와 달리 VoXtream은 문장 전체를 한 번에 처리하지 않습니다.
입력 텍스트는 단어(word) 단위로 들어오며, 각 단어가 들어오는 즉시 g2p(grapheme-to-phoneme) 를 통해 발음 정보인 phoneme 시퀀스로 변환됩니다
오디오 토큰 - Mimi codec
VoXtream은 waveform을 직접 예측하지 않습니다.
대신 Mimi codec을 사용해 음성을 토큰 시퀀스로 표현합니다.
- Mimi는 음성을 12.5Hz 프레임레이트의 토큰으로 변환
- 즉, 1초 ≈ 12.5 프레임
한 프레임은 약 80ms 음성 조각
- 즉, 1초 ≈ 12.5 프레임
중요한 점은 Mimi의 토큰 구조입니다.
- 첫 번째 codebook: semantic token
→ 말의 내용, 발음의 큰 흐름 - 나머지 codebook들: acoustic token
→ 음색, 질감, 세부 음향 정보
VoXtream은 이 semantic / acoustic 분리 구조를 적극 활용합니다.
Phoneme Transformer (PT)
Phoneme Transformer는 decoder-only Transformer로, 지금까지 입력된 phoneme들을 토큰처럼 임베딩하여 텍스트 컨텍스트 표현을 생성합니다.
- 이 모듈에서는 Dynamic Look-Ahead가 사용이 됩니다.
Dynamic Look-Ahead
스트리밍 환경에서 가장 어려운 점은 미래 정보를 모른다는 것입니다.
하지만 자연스러운 억양과 리듬을 위해서는 약간의 미래 정보가 도움이 됩니다.
VoXtream은 이를 위해 Dynamic Look-Ahead를 사용합니다.
- 미래 phoneme을 최대 10개까지 볼 수 있음
- 그러나 N개가 쌓일 때까지 기다리지 않음
첫 단어가 들어오자마자 음성 생성 시작 - 현재 버퍼에 들어와 있는 만큼만 동적으로 look-ahead
즉, 미래가 있으면 그만큼 활용하고 없으면 없는 대로 바로 생성하도록 합니다.
Temporal Transformer (TT)
지금까지 생성된 오디오 토큰들과, 지금까지 들어온 phoneme들을 보고, 다음 80ms 프레임에서
(1) 무슨 소리를 낼지(semantic)와
(2) phoneme을 어떻게 진행할지(duration)를 결정합니다.
이 때, semantic token 는 음소처럼 이번 프레임에서 어떤 발음 소리를 낼지 결정하는 토큰입니다.
그리고 duratio token 다음의 2차원 정보를 담고 있는데,
(1) Shift flag: stay / go
- stay
→ 다음 프레임에서도 같은 phoneme 계속 - go
→ 다음 프레임에서 다음 phoneme으로 이동
(2) Phoneme count: 1 or 2
80ms 프레임은 꽤 길기에 어떤 발음은 한 프레임에 phoneme 2개를 처리해도되어 2까지 허용합니다.
- 1 → 천천히 말함
- 2 → 빠르게 말함
Depth Transformer (DT)
이제 지금까지 어떤 말을 하고 어떤 길이로 말할 것인지 결정했으니 이제 음색, 세부 음향, 화자 특성은 depth transformer 에서 처리합니다.
- 입력 : semantic token + TT output embedding + speaker embedding (ReDimNet)
- 출력 : Mimi 2~12번째 codebook (acoustic detail)
Decoder
token 을 다시 waveform 의 형태로 바꿔줍니다.
Dataset & Evaluation
데이터셋
훈련 데이터셋으로는 Emilia, HiFiTTS-2를 사용하였습니다. (총 9000시간)
그리고
- 한 문장 안에 여러 화자가 섞인 경우
- ASR 전사가 오류가 심한 경우
- NISQA로 음질이 낮음 음성
은 학습에서 제외하였습니다.
평가방법
WER ↓ (Word Error Rate)
- 음성 → 텍스트로 다시 인식했을 때 오류율
- 낮을수록 발음 정확
SPK-SIM ↑
- 화자 유사도
- zero-shot speaker 유지 능력
UTMOS ↑
- 자동 음질 평가 점수
Naturalness (MUSHRA) ↑
- 사람이 듣고 평가한 자연스러움
- 제일 중요
FPL (First-Packet Latency, ms) ↓
- 텍스트 입력 → 첫 음성 조각이 나올 때까지 시간
- 작을수록 좋음
- 실시간 대화에서는 가장 중요한 지표
RTF (Real-Time Factor) ↓
- 음성 1초 생성하는 데 걸리는 시간 비율
- RTF < 1 → 실시간 가능
- 작을수록 빠름
Results
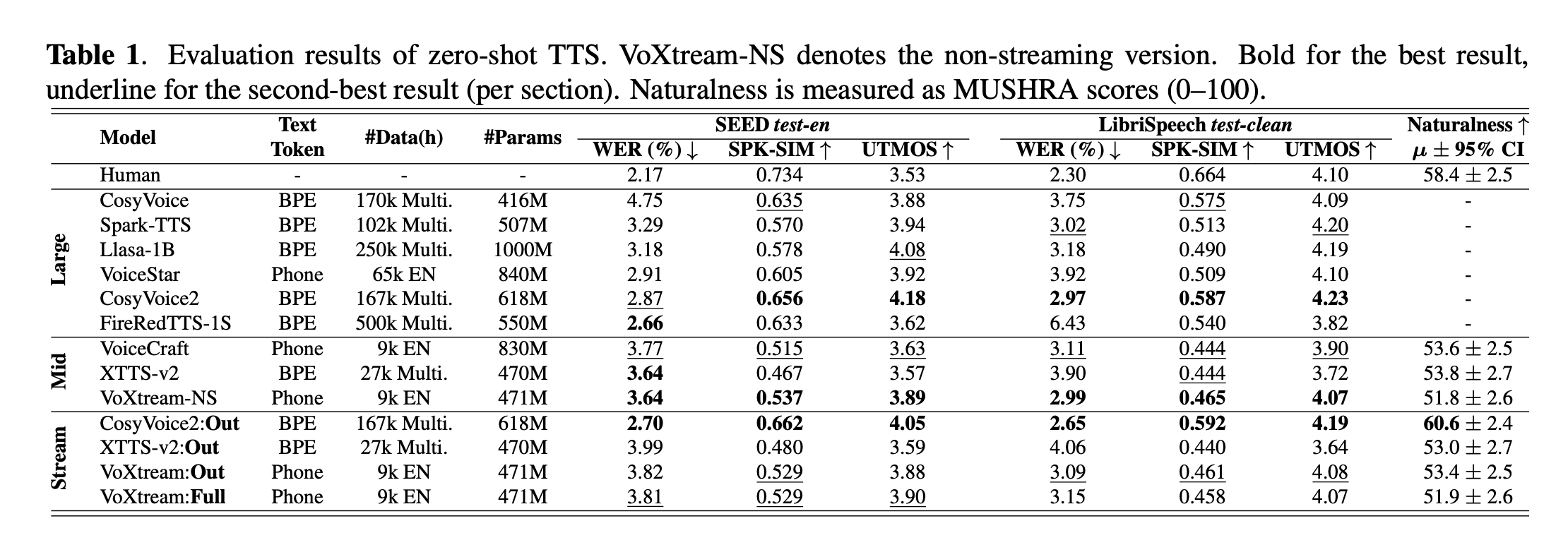
기존 non-streaming TTS 모델들은 높은 음질을 보이지만, 문장 전체를 입력으로 가정하기 때문에 first-packet latency가 커 실제 streaming 환경에는 적합하지 않습니다.
이를 보완하기 위해 기존 모델을 잘라 사용하는 output streaming 방식이 제안되었으나, 이러한 접근은 구조적으로 미래 텍스트를 이미 알고 있는 상태에서 출력을 분할하는 방식으로, 진정한 의미의 streaming TTS라고 보기는 어렵습니다.
실제로 일부 output streaming 모델은 표면적으로 우수한 객관 지표를 보이기도 하지만, prompt 재합성과 같은 구현상의 이슈(CosyVoice2는 target text가 prompt보다 짧으면 prompt를 다시 합성해버림)로 평가 지표가 왜곡될 수 있으며, 이러한 결과는 fully streaming 설정과 직접 비교하기에는 한계가 있다고 저자들은 주장합니다.
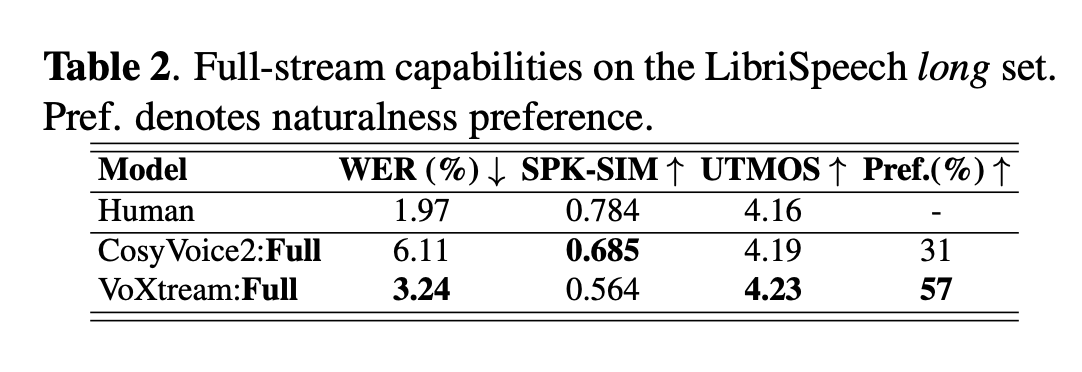
그래서 target text가 긴 세팅에 대해서 성능을 측정하였으며 더 나은 성능을 보였다고 주장합니다.
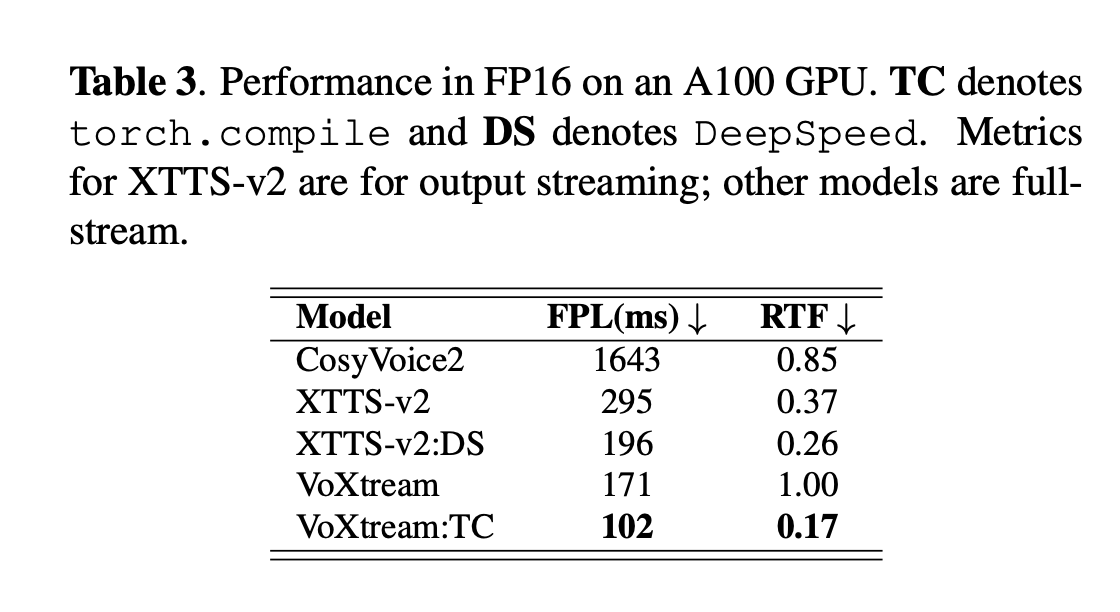
VoXtream가 베이스라인에 비해서 inference speed가 빠른 것을 볼 수 있습니다.
🔗 Resources
