[Speech AI] Neural Codec
Background
Speech 분야에서는 사람의 음성을 있는 그대로의 파형(raw waveform)으로 바로 사용하는 경우는 거의 드뭅니다. 대신, 음성 신호에서 중요한 정보만 골라낸 표현(feature)을 만들어 모델의 입력으로 사용합니다. 이는 음성을 그대로 쓰는 것이 생각보다 많은 문제를 안고 있기 때문입니다.
먼저, 음성 파형은 너무 세밀합니다. 사람이 1초 동안 말하면, 컴퓨터에는 그 소리가 초당 수만 개의 숫자로 저장됩니다. (예를 들어, 16k sampling rate 의 음성은 1초에 16000개의 신호를 숫자를 저장합니다.) 이렇게 세부적인 정보가 지나치게 많으면, 컴퓨터는 중요한 패턴을 배우기보다 사소한 변화에 휘둘리게 됩니다. (리소스 문제도 있고 학습도 비효율적)
또한 음성 파형은 인간이 소리를 인식하는 방식과 차이가 있습니다. 사람은 소리를 들을 때 고음과 저음을 구분하고, 발화의 리듬이나 말의 의미를 중심으로 인식하지만, 음성 파형은 이러한 인식 단위를 반영하지 않은 단순한 물리적 신호의 나열입니다.
이러한 이유로 speech 연구에서는 음성을 그대로 사용하는 대신, 인간이 소리를 이해하는 방식에 더 가까운 표현 공간으로 변환하는 전처리 과정을 핵심적인 단계로 여겨 왔습니다. 이 과정은 음성을 보다 압축적이고 구조적인 형태로 재표현함으로써, 모델이 의미 있는 패턴에 집중할 수 있도록 돕는 역할을 합니다.
Mel Spectrogram과 한계
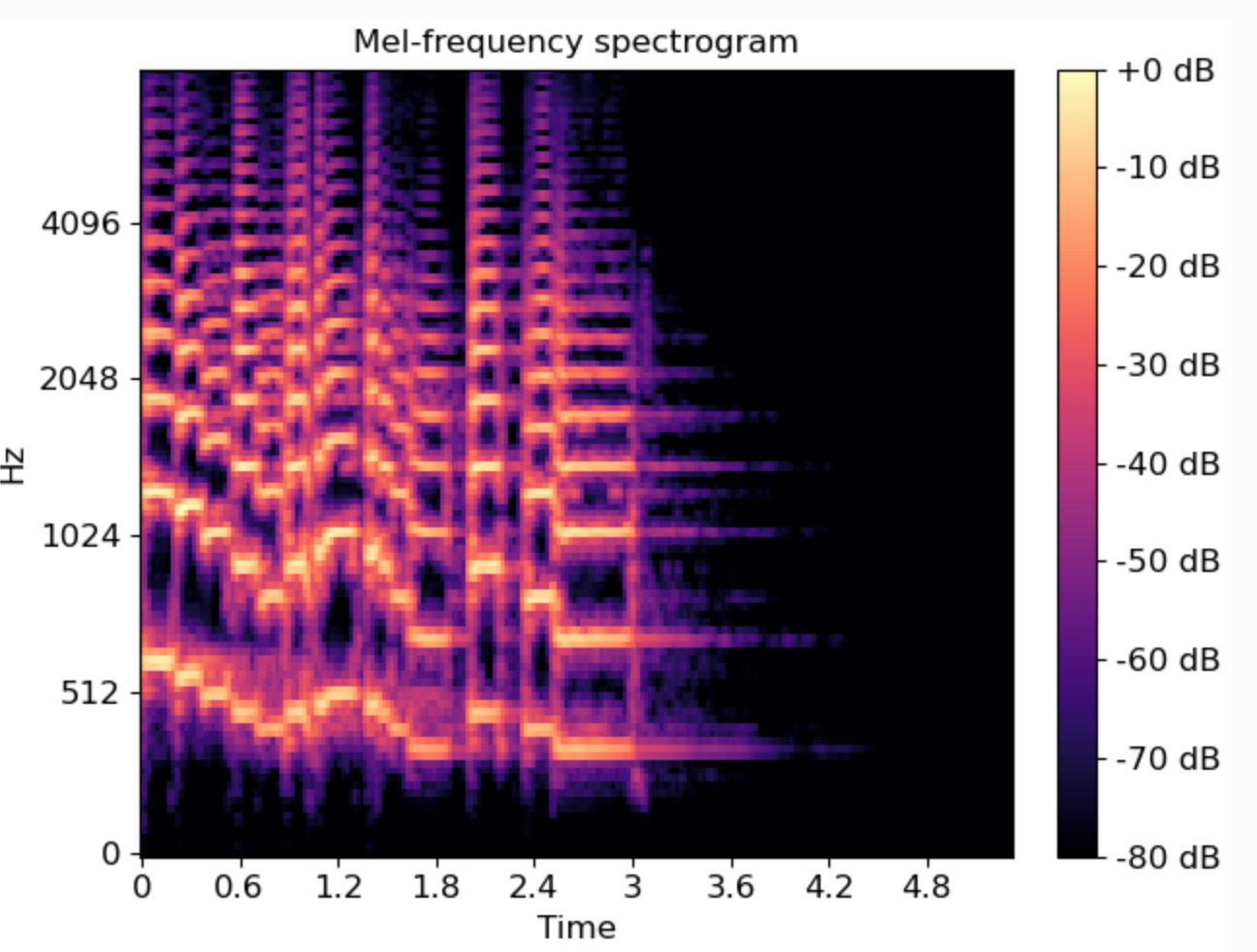
이러한 목적에서 가장 널리 사용되어 온 표현이 mel spectrogram입니다. Mel spectrogram은 음성을 시간에 따라 분석하면서, 어떤 주파수 성분이 얼마나 강한지를 그림처럼 나타낸 표현입니다.(시간-주파수 표현) 특히 사람의 귀가 낮은 소리에는 민감하고 높은 소리에는 상대적으로 둔감하다는 점을 반영해, 인간의 청각 특성에 맞게 주파수 축을 조정합니다.(Mel scale 적용)
이 표현을 사용하면 음성의 높낮이 변화, 말의 리듬, 발화의 강약 같은 특징이 비교적 잘 드러납니다. 그래서 음성 인식, 음성 합성, 음성 변환 등 다양한 분야에서 사실상의 표준 입력으로 오랫동안 활용되어 왔습니다. 또한 이미지처럼(1D가 아닌 2D 데이터여서) 다룰 수 있기 때문에, 컴퓨터 비전에서 발전한 딥러닝 모델들과도 잘 어울린다는 장점이 있습니다.
하지만 mel spectrogram에도 한계는 존재합니다. Mel spectrogram은 소리를 잘 요약해 주지만, 이 소리가 무슨 뜻인지, 누가 말하는지, 어떤 감정으로 말하는지와 같은 고수준 정보는 따로 분리되어 있지 않습니다. 이런 정보들은 모두 모델이 스스로 추론해야 합니다. 또한 잡음이 많은 환경이나 새로운 말투, 새로운 화자에 대해서는 성능이 쉽게 떨어질 수 있습니다. 더 나아가, 언어 모델과 직접적으로 결합해 “말을 이해하고 생성하는 시스템”을 만들기에는 표현 자체가 아직 충분히 추상화되어 있지 않다는 한계도 있습니다.
더 나은 표현을 향한 두 가지 흐름
이러한 한계를 극복하기 위해, 최근에는 mel spectrogram보다 speech의 정보를 더 풍부하게 담을 수 있는 새로운 표현 방식들이 제안되고 있습니다. 대표적인 접근 방식은 크게 self-supervised learning(SSL) 기반 feature와 neural codec 기반 표현으로 나눌 수 있습니다.
Self-supervised Learning 기반 표현 (음성 이해)
먼저, self-supervised learning(SSL) 기반 방법들은 대규모 음성 데이터를 이용하여 라벨 없이 학습된 연속적인 latent representation을 활용합니다. wav2vec 2.0이나 WavLM과 같은 모델은 연속값 기반의 표현을 생성하며, HuBERTs는 k-means와 같은 방법을 통해 이산적인(discrete) content representation으로 사용되는 경우가 많습니다. 이러한 SSL 기반 표현들은 masked prediction이나 contrastive learning을 통해 음성의 발음 정보, 언어적 구조, 화자 특성, 그리고 주변 맥락 정보를 효과적으로 인코딩할 수 있습니다.
이러한 특성으로 인해 SSL 기반 표현은 음성 인식, 화자 인식, 감정 인식과 같은 speech understanding 중심의 task에서 기존의 mel spectrogram 대비 의미적으로 풍부하고 잡음에 강인한 표현을 제공하는 경우가 많으며, 다양한 downstream task에서 성능 향상을 이끌어 왔습니다. 더 나아가, voice conversion과 같이 음성을 입력으로 받아 다시 음성을 생성하는 task에서도 SSL 기반 표현은 중요한 역할을 수행해 왔습니다. 이 경우 SSL 기반 표현은 음성 생성의 최종 목표가 아니라, 발화의 언어적 내용(content)과 화자 정체성(speaker identity)을 분리하기 위한 중간 표현으로 활용됩니다. 예를 들어, HuBERT나 contentvec 계열의 표현은 발화 내용 정보를 상대적으로 화자 정보로부터 분리해 모델링하는 데 사용되고, WavLM과 같은 표현은 화자 특성을 포착하는 데 활용됩니다. 최종적인 음성 파형의 생성은 여전히 mel spectrogram을 기반으로 vocoder를 통해 수행되는 경우가 일반적이며, 이는 voice conversion이 본질적으로 음성 이해와 음성 합성이 결합된 형태의 task라는 점과 밀접한 관련이 있습니다.
Neural Codec 기반 표현 (음성 압축 및 복원)
반면, 텍스트를 입력으로 받아 음성을 처음부터 생성해야 하는 text-to-speech(TTS)와 같은 순수 생성 task에서는 neural codec 기반 표현이 최근 들어 중요한 대안으로 부상하고 있습니다. Neural codec은 음성 신호를 이산적인(discrete) 토큰 시퀀스로 변환하고, 이를 다시 음성으로 복원할 수 있도록 설계된 모델입니다. 전통적인 audio codec이 압축과 전송 효율을 목적으로 했다면, neural codec은 생성 모델과 언어 모델이 다루기 쉬운 음성 표현을 제공하는 것에 초점을 둡니다.
Neural codec은 설계 목적에 따라 크게 세 가지로 구분할 수 있습니다.
첫째, acoustic codec은 음질과 복원 정확도에 초점을 맞추며, 화자의 음색, 프로소디, 배경 환경과 같은 저수준 음향 정보를 정밀하게 표현하는 데 강점을 가집니다. 이는 고품질 음성 합성이나 오디오 생성 task에서 주로 활용됩니다.
둘째, semantic codec은 음성의 언어적 내용, 즉 발화의 의미와 음소 구조를 표현하는 데 중점을 둡니다. 이들은 음질 복원보다는 언어적 일관성과 의미 보존에 강점을 가지며, 언어 모델과의 결합에 유리합니다.
셋째, 최근에는 text-aware 또는 LLM-oriented codec이 제안되고 있는데, 이는 semantic 정보와 acoustic 정보를 균형 있게 담아 speech를 언어 모델의 토큰 공간으로 자연스럽게 연결하는 것을 목표로 합니다.
이러한 특성 덕분에 neural codec 기반 접근은 음성을 더 이상 연속적인 파형이나 스펙트럼이 아니라, '토큰의 시퀀스' 로 바라보는 관점을 가능하게 합니다. 이는 텍스트 토큰과 오디오 토큰을 동일한 시퀀스 모델링 문제로 다룰 수 있게 하며, speech와 language modeling을 하나의 통합된 프레임워크로 결합하려는 최근의 연구 흐름과도 직접적으로 연결됩니다.
Acoustic Codec
Acoustic codec은 neural codec 중에서도 음질과 복원 정확도를 최우선으로 설계된 계열입니다. 이들은 화자의 음색, 발화의 미세한 억양, 배경 환경과 같은 저수준 음향 정보를 가능한 한 손실 없이 이산 토큰으로 압축하고, 다시 자연스러운 파형으로 복원하는 것을 목표로 합니다. 따라서 acoustic codec은 고품질 음성 합성, 오디오 생성, 그리고 speech-to-speech 변환과 같은 생성 중심 task에서 핵심적인 역할을 수행합니다.
SoundStream
- https://arxiv.org/abs/2107.03312
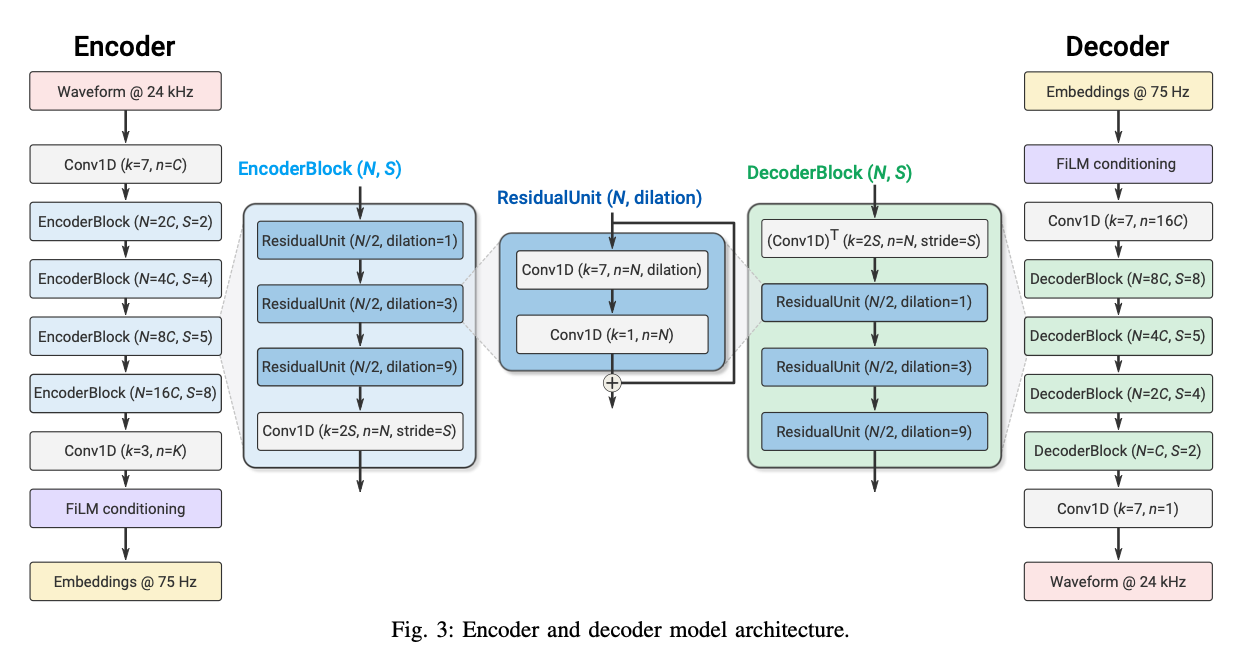
--> end-to-end로 학습되는 encoder–RVQ–decoder 구조를 통해 음성을 이산 토큰으로 압축
SoundStream은 neural audio codec의 대표적인 초기 모델로, waveform을 직접 입력으로 받아 end-to-end로 학습되는 구조를 제안했습니다. 기존의 전통적인 audio codec이 사람이 설계한 신호 처리 규칙에 의존했다면, SoundStream은 신경망이 음성 압축과 복원을 스스로 학습하도록 설계되었다는 점에서 중요한 전환점을 만들었습니다.
SoundStream의 핵심 아이디어는 음성 파형을 직접 입력으로 받아 residual vector quantization(RVQ)을 통해 이산 토큰으로 변환하고, adversarial loss를 활용해 고품질 음성을 복원합니다. SoundStream은 저비트레이트 환경에서도 기존 신호처리 기반 코덱을 능가하는 음질을 보이며, neural codec 연구의 출발점을 마련했습니다.
EnCodec
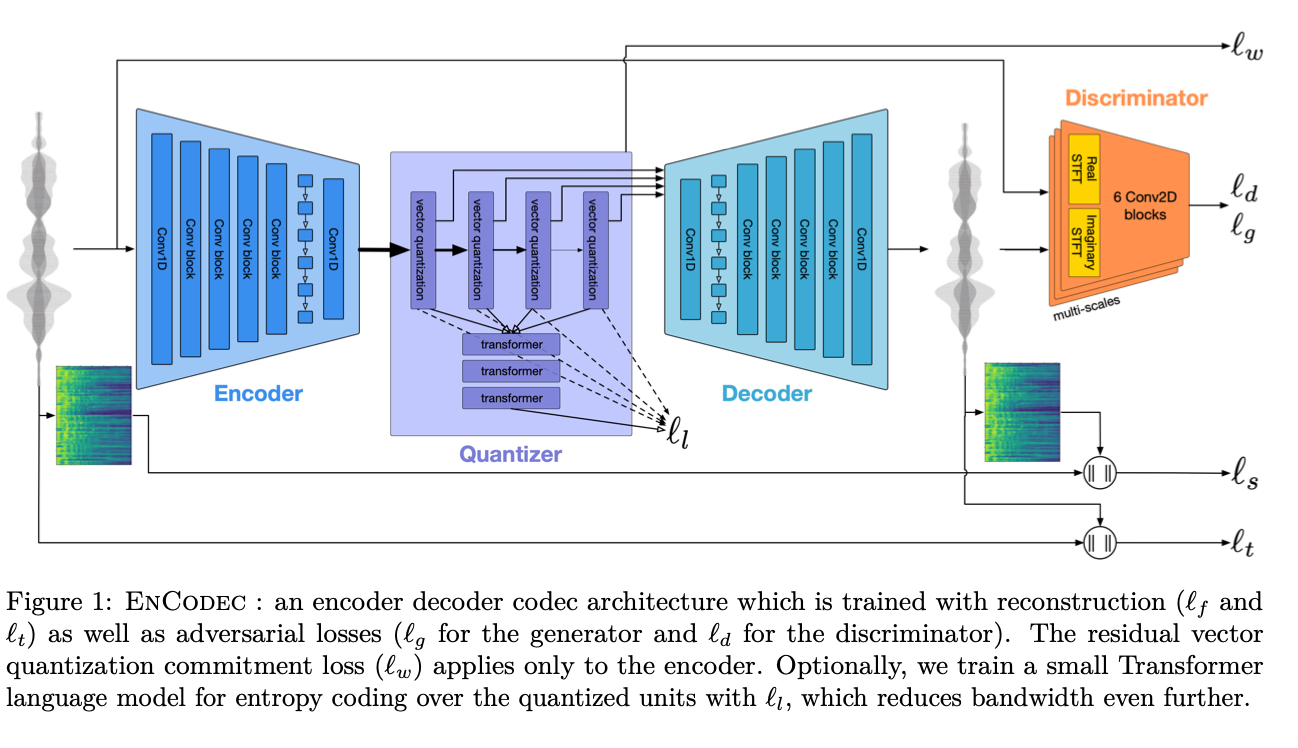
Encodec은 acoustic codec을 범용 오디오 표현으로 확장한 모델로, 음성뿐 아니라 음악과 환경음까지 폭넓게 다룰 수 있도록 설계되었습니다. SoundStream과 마찬가지로 RVQ 기반 구조를 사용하지만, 다양한 오디오 도메인에 대해 안정적인 복원 성능을 보이도록 학습되었습니다.
Encodec의 가장 큰 기여는 neural codec을 실제 생성 모델에서 표준적인 오디오 표현 단위로 정착시켰다는 점입니다. 이후 많은 audio generation 및 TTS 모델들이 waveform이나 mel spectrogram 대신 Encodec 토큰을 직접 예측하는 방식으로 전환하였고, 이러한 흐름은 음성을 연속 신호가 아닌, 이산 토큰 시퀀스로 다루는 관점을 본격적으로 확산시키는 계기가 되었습니다.
DAC
DAC(Discrete Audio Codec)은 acoustic fidelity를 극대화하는 데 초점을 둔 모델로, 특히 자연스러운 음색과 미세한 질감 표현에서 강점을 보입니다. 상대적으로 높은 bitrate를 사용하지만, 그만큼 원음에 가까운 복원을 목표로 설계되었습니다.
DAC은 언어적 의미를 추상화하기보다는, 음성의 세부적인 음향 특성을 최대한 보존하는 데 중점을 두기 때문에, 언어 모델과 직접 결합되기보다는 고품질 음성 합성이나 음악 생성과 같은 음질 중심 pipeline에서 주로 활용됩니다.
Mimi
- https://huggingface.co/kyutai/mimi
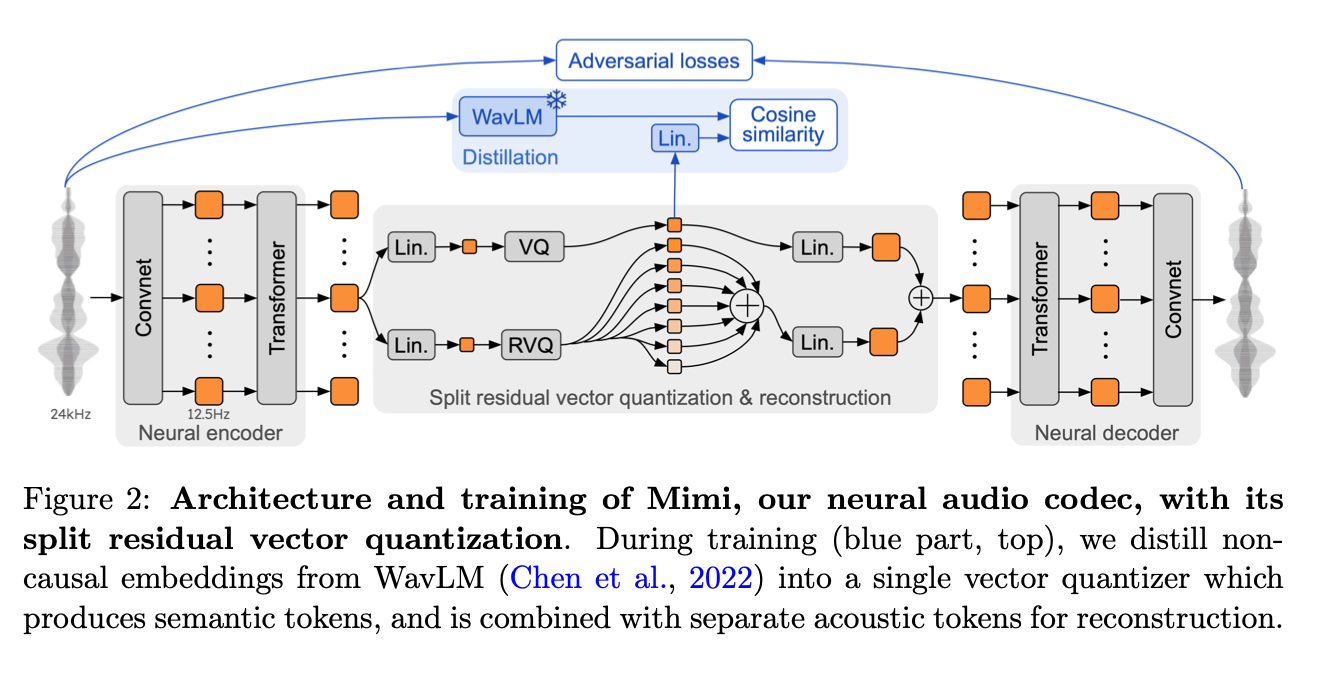
Mimi는 Kyutai에서 제안한 neural audio codec으로, Moshi 시스템에서 사용되기 위해 설계되었습니다. Mimi의 주요 설계 목표는 최고 수준의 음질보다는, 실시간(streaming) 환경에서 안정적으로 동작하는 저지연 음성 토큰화를 가능하게 하는 것입니다. 특히 실시간 음성 생성이나 양방향 음성 대화와 같은 시나리오를 염두에 두고, 인코딩과 디코딩 과정에서의 지연(latency)과 시간적 안정성을 중요하게 고려합니다.
Mimi는 RVQ(residual vector quantization) 기반의 acoustic codec 구조를 사용하며, SoundStream 및 EnCodec 계열과 구조적으로 유사한 neural codec에 속합니다. 다만 Mimi는 일반적인 음성 압축이나 범용 오디오 복원을 목표로 하기보다는, 실시간 speech-to-speech 및 speech LLM 파이프라인에서 사용 가능한 acoustic token 생성에 초점을 둡니다.
또한 Mimi는 음성을 프레임 단위로 처리하면서도, 스트리밍 환경에서 토큰이 시간적으로 불안정해지지 않도록 설계되었습니다. 이러한 특성은 생성 과정에서 프레임 간 불연속성이나 음질 흔들림을 줄이는 데 기여하며, 실시간 speech-to-speech 시스템이나 streaming TTS 파이프라인에서 안정적인 acoustic backbone으로 활용될 수 있는 기반을 제공합니다.
Semantic Codec
Semantic codec은 acoustic codec과 달리, 음질 자체보다는 발화의 언어적 의미와 구조를 안정적으로 표현하는 데 초점을 둡니다. 이들은 화자의 음색이나 세부 음향 정보를 과감히 버리는 대신, “무슨 말을 하고 있는가”를 중심으로 음성을 이산 토큰으로 표현합니다. 이러한 특성 덕분에 semantic codec은 언어 모델과의 결합에 특히 적합합니다.
RepCodec
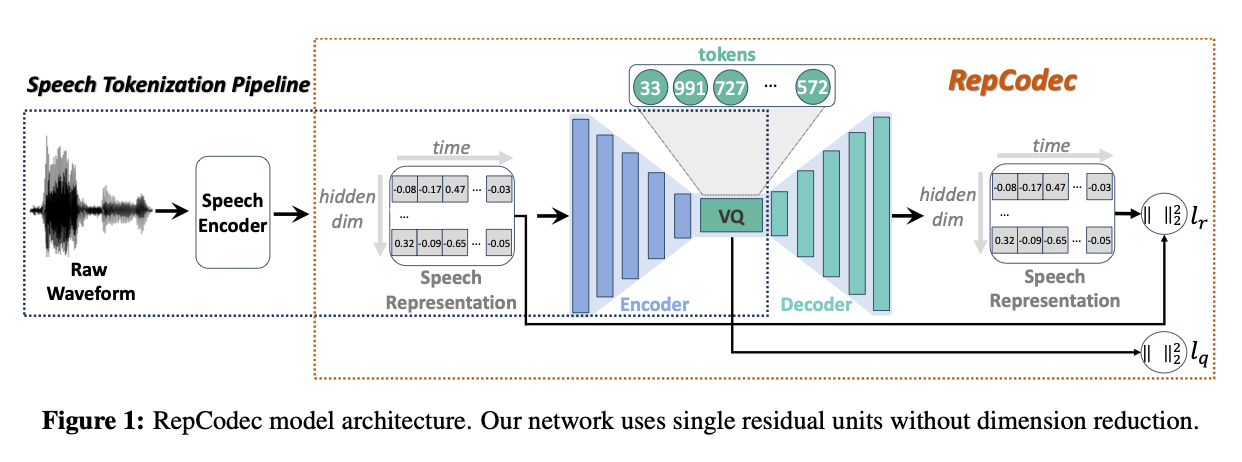
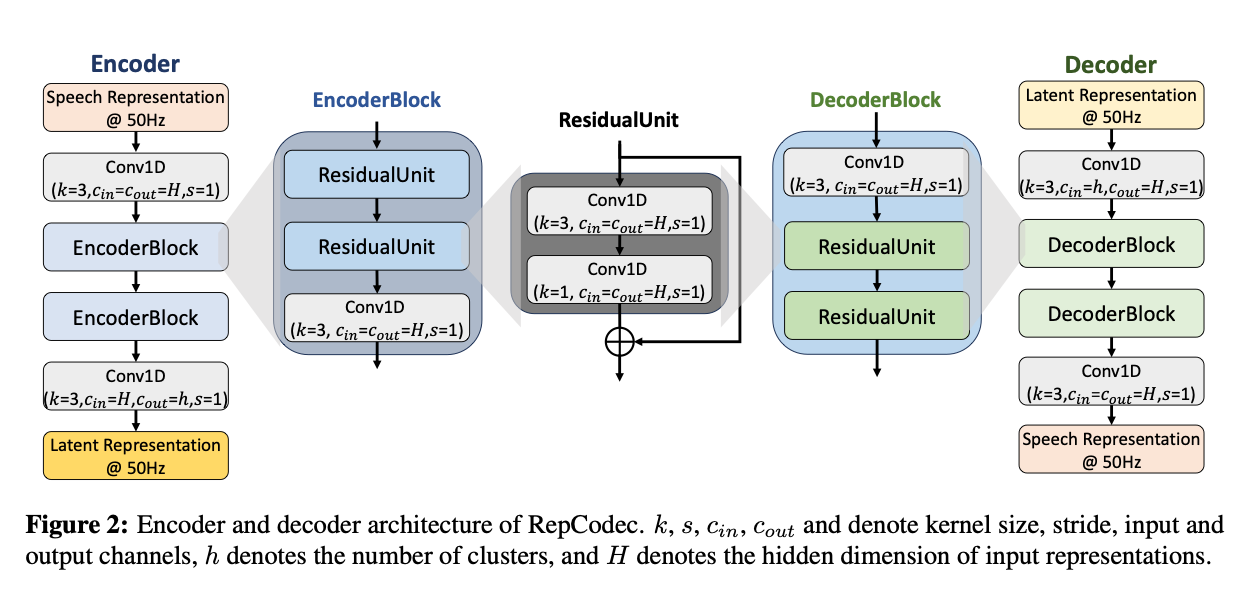
RepCodec은 self-supervised speech model의 latent representation을 이산화하여, 발화의 언어적 내용을 중심으로 표현하는 semantic codec입니다. 음질 복원보다는 content 보존에 초점을 맞추며, 언어 모델과의 정렬이 우수합니다. 다만 단독으로는 자연스러운 음성 생성을 수행할 수 없으며, 별도의 acoustic decoder가 필요합니다.
SpeechTokenizer
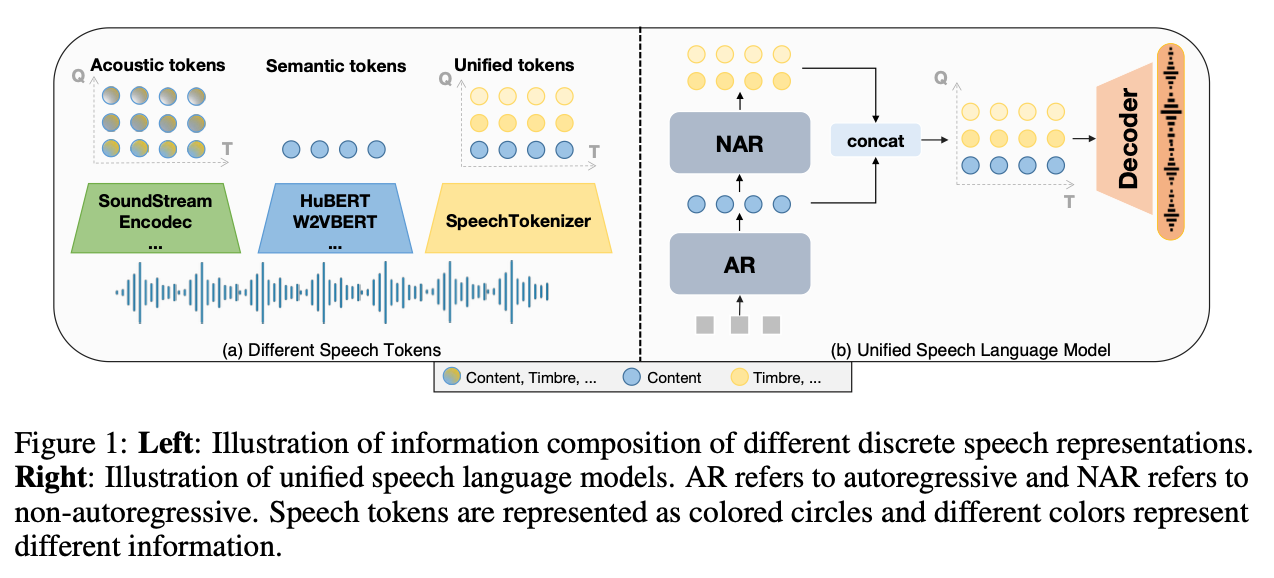
SpeechTokenizer는 semantic token과 acoustic token의 이분법 자체를 문제로 정의합니다. RVQ 구조 내에서 첫 quantizer는 semantic teacher의 도움을 받아 content 정보를 담당하고, 이후 quantizer들은 음향 정보를 계층적으로 보완합니다. 이를 통해 단일 tokenizer로 의미와 음질을 동시에 다루며, Speech LLM을 위한 이상적인 token interface를 제안합니다.
Text-aware Codec
Semantic codec과 acoustic codec의 장점을 동시에 취하려는 시도로, 최근에는 text-aware 또는 LLM-oriented codec이 등장하고 있습니다. 이들은 음성의 의미 정보와 음향 정보를 균형 있게 담아, speech를 언어 모델의 토큰 공간으로 자연스럽게 연결하는 것을 목표로 합니다.
TadiCodec
TadiCodec은 speech token이 텍스트와 시간적·구조적으로 정렬되도록 학습하는 text-aware codec입니다. 음성 토큰을 언어 모델의 attention 공간에 직접 투영하는 것을 목표로 하며, speech와 text를 동일한 생성 문제로 통합하는 데 중점을 둡니다.
마무리
현재 다양한 음성 task에서 neural codec이 핵심 표현으로 사용되고 있으며, 특히 최근 speech-to-speech 모델과 Speech LLM이 부상하면서 그 중요성은 더욱 커지고 있습니다. 과거에는 codec이 단순히 음성을 압축·복원하는 도구로 인식되었다면, 이제는 모델이 음성을 어떤 단위로 이해하고 생성할 것인가를 결정하는 표현 계층으로 자리 잡고 있습니다.
SoundStream과 EnCodec은 neural codec이 기존 신호처리 기반 표현을 대체할 수 있음을 보여주었고, DAC은 음질과 fidelity를 극대화하는 방향에서 acoustic codec의 상한을 끌어올렸습니다. 한편 Mimi는 음질보다 시간적 안정성과 저지연성을 우선시함으로써, 실시간 speech-to-speech 및 full-duplex Speech LLM 환경에서 codec이 충족해야 할 새로운 요구사항을 제시했습니다. 이러한 흐름은 codec의 목표가 더 이상 “얼마나 잘 복원하는가”에만 머물러 있지 않음을 분명히 보여줍니다.
Semantic codec과 text-aware codec의 등장은 이러한 변화가 더욱 근본적인 수준으로 확장되고 있음을 시사합니다. RepCodec과 SpeechTokenizer는 음성을 언어 모델이 다룰 수 있는 의미 단위로 재구성하려는 시도이며, TadiCodec은 아예 codec 자체를 language modeling을 위한 인터페이스로 재정의합니다. 이는 speech representation이 전처리 단계가 아니라, 모델 구조와 학습 목표를 규정하는 핵심 설계 요소로 이동하고 있음을 의미합니다.
결국 mel spectrogram에서 SSL feature, 그리고 neural codec으로 이어지는 흐름은 단순한 표현의 교체가 아니라, speech를 연속 신호로 볼 것인가, 토큰 시퀀스로 볼 것인가라는 패러다임 전환을 반영합니다. 앞으로의 연구에서 중요한 질문은 어떤 표현이 주어진 task와 모델 구조에 가장 적합한 추상화 수준을 제공하는가가 될 것입니다. 이러한 관점에서 neural codec은 단순한 음성 처리 기술을 넘어, speech와 language를 하나의 모델 안에서 통합하기 위한 핵심 기반으로 자리매김하고 있습니다.
