[Paper Review] Moshi - mimi
최근 full-duplex speech-to-speech 모델이 많이 연구되고 있다. 이는 기존의 ASR→LLM→TTS 파이프라인 대신에 음성에서 음성으로 바로 모델링 하는 모델이다. 이와 관련해서는 https://www.youtube.com/watch?v=0_c3bw_x6uU 영상을 추천한다. 오늘은 이 중에서 moshi 에 사용된 audio neural codec 만 간단히 정리해보고자 한다.
기존 STT–LLM–TTS 구조의 한계
- 다단계 처리로 인한 수 초의 지연(latency)
- 비언어적 정보(감정, 억양, 소리 등)를 텍스트 전환 과정에서 손실
- 회화의 자연스러운 흐름(말 겹침, 끼어듦 등)을 표현하지 못함
Mimi

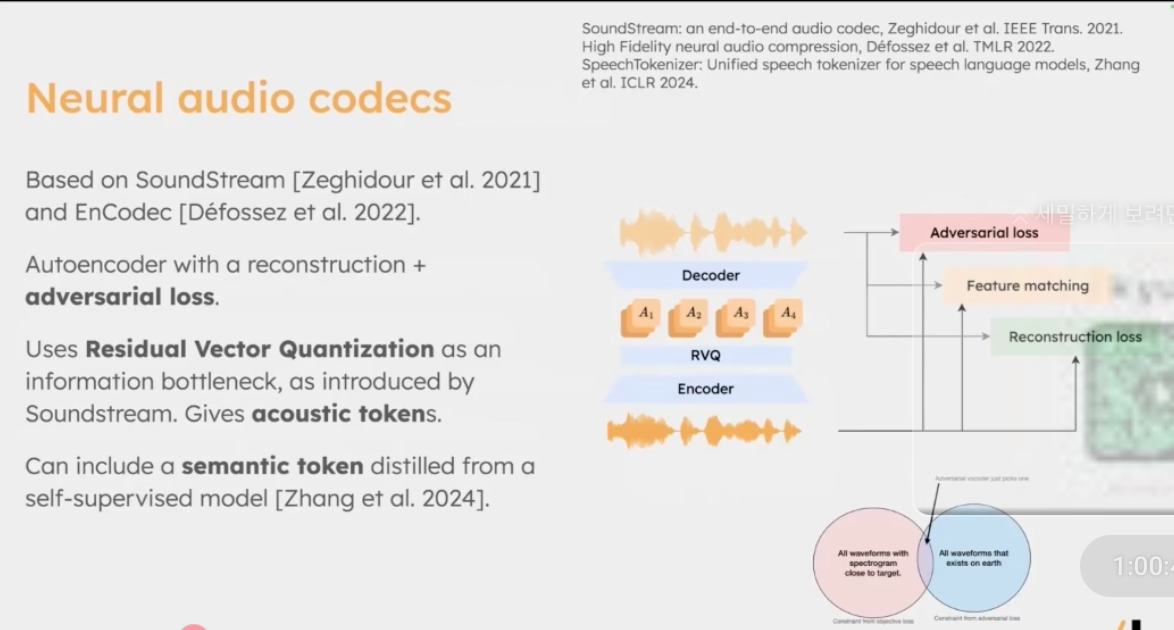
Moshi는 를 mimi 라는 audio neural codec 을 사용한다. 이는 다음의 세 가지 loss 를 사용한다.
- adversarial loss
- feature matching loss
- reconstruction loss
음성 생성 모델을 학습할 때 가장 먼저 떠오르는 접근은 아주 단순하다. 원본 음성과 생성된 음성 사이의 차이를 최대한 줄이는 것이다. 그래서 많은 모델들이 reconstruction loss, 그중에서도 MSE(mean squared error)를 기본으로 사용해 왔다. 이 방식은 직관적이고 학습도 안정적이라는 장점이 있다. 하지만 결정적인 한계가 있다.
MSE는 여러 가능한 해답 중에서 항상 평균적인 결과를 선택하도록 만든다. 문제는 음성이 본질적으로 평균적인 신호가 아니라는 점이다. 실제 음성에는 미세한 흔들림, 불규칙한 발성, 순간적인 변화들이 끊임없이 섞여 있다. 그런데 MSE로 학습하면 이런 요소들이 평균화 과정에서 자연스럽게 사라진다. 그 결과 수치적으로는 잘 맞는데, 사람 귀에는 무언가 부족한 음성이 만들어진다. reconstruction loss만으로 고퀄리티 음성을 만들기 어려운 이유가 바로 여기에 있다.
이 한계를 넘기 위해 등장한 것이 adversarial loss다. adversarial loss를 통해 합성음을 좀더 실제음과 비슷하게 만들면서 단순히 평균적인 복원을 넘어, 말로 설명하기 어려운 음성의 질감과 자연스러움까지 학습하게 된다.
추가적으로, feature matching loss는 판별기의 중간 feature 공간에서 진짜 음성과 생성 음성이 비슷한 표현을 갖도록 유도한다. 그 결과 학습은 훨씬 안정되고, 음질과 자연스러움이 한층 좋아진다
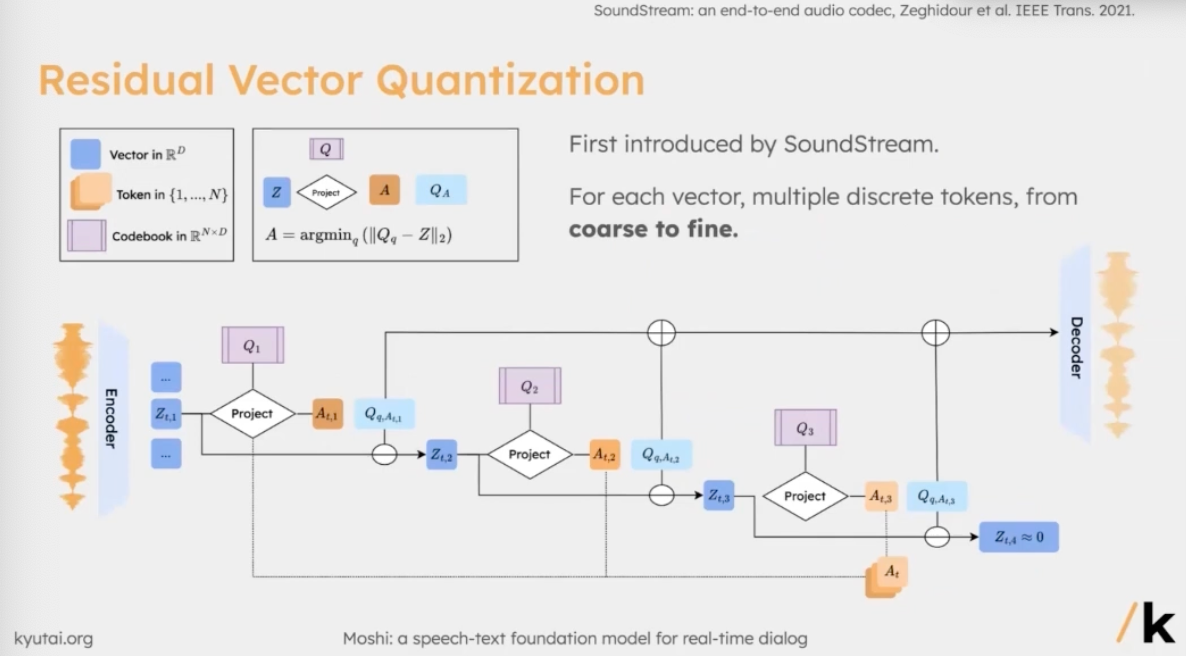
Residual Vector Quantization(RVQ)은 neural audio codec에서 연속적인 음향 표현을 이산 토큰으로 바꾸기 위해 사용하는 핵심 기법이다. 다만 RVQ만 사용한다고 해서 자동으로 “의미 있는” 토큰이 만들어지는 것은 아니다. self-supervised 모델을 이용해 semantic token을 distillation하지 않으면, 모델은 주로 local acoustic feature에 머무르게 된다. 재구성 관점에서는 그럴듯한 음성이 나오지만, 이 토큰을 언어 모델링이나 장기 구조 학습에 쓰려 하면 문제가 생긴다. 의미 정보를 거의 담고 있지 않기 때문에, 모델 크기를 극단적으로 키우지 않는 이상 유의미한 결과를 얻기 어렵다.
RVQ의 동작 과정을 보면 먼저 인코더에서 일정한 프레임 속도(예를 들어 12.5Hz)에 맞춰 연속적인 잠재 표현을 추출한다. 이 잠재 벡터는 보통 256차원 공간에 놓인다. 이후 코드북 Q에서 입력 latent (Z)와 L2 거리 기준으로 가장 가까운 행(row)을 찾는다. 이때 선택된 행에는 하나의 인덱스가 부여되는데, 이것이 바로 이산 양자화 토큰이다.
하지만 여기서 끝이 아니다. 선택된 양자화 벡터를 입력 (Z)에서 빼서 첫 번째 residual을 계산한다. 이 residual을 다시 다음 코드북에 넣어 같은 과정을 반복한다. 즉, 첫 번째 코드북은 가장 큰 구조를 설명하고, 남은 오차를 두 번째 코드북이 보완하고, 이런 식으로 점점 더 작은 잔차를 처리해 나간다. 아래 코드북으로 갈수록 더 미세한 음향 디테일을 다루게 되는 구조다. 최종적으로는 각 단계에서 얻은 모든 양자화 벡터를 더한 값을 decoder에 입력해 음성을 복원한다.
코드북 자체는 지수 이동 평균(EMA)을 이용해 학습된다. 어떤 latent 벡터 (Z)가 특정 코드북 행에 할당되면, 그 행은 (Z)의 방향으로 조금씩 업데이트된다. 동시에 입력 latent가 선택된 양자화 벡터에 너무 멀어지지 않도록 강제하는 commitment loss도 함께 사용된다. 이 loss는 인코더가 코드북에 잘 맞는 표현을 내도록 유도하는 역할을 한다.
SoundStream 논문에서 흥미로운 아이디어로 제안된 것이 바로 코드북 깊이를 훈련 중에 확률적으로 샘플링하는 방식이다. 예를 들어 전체 코드북이 32개라면, 매 스텝마다 32개를 모두 쓰기도 하고, 16개나 8개, 혹은 4개만 쓰기도 한다. 이렇게 학습하면 모델은 “코드북이 몇 개만 주어져도 복원할 수 있는 방법”을 자연스럽게 배우게 된다. 그 결과 추론 시점에서는 재훈련 없이도 비트레이트를 조절할 수 있다. 코드북을 많이 쓰면 고음질, 적게 쓰면 저비트레이트 음성을 만들 수 있다는 의미다.
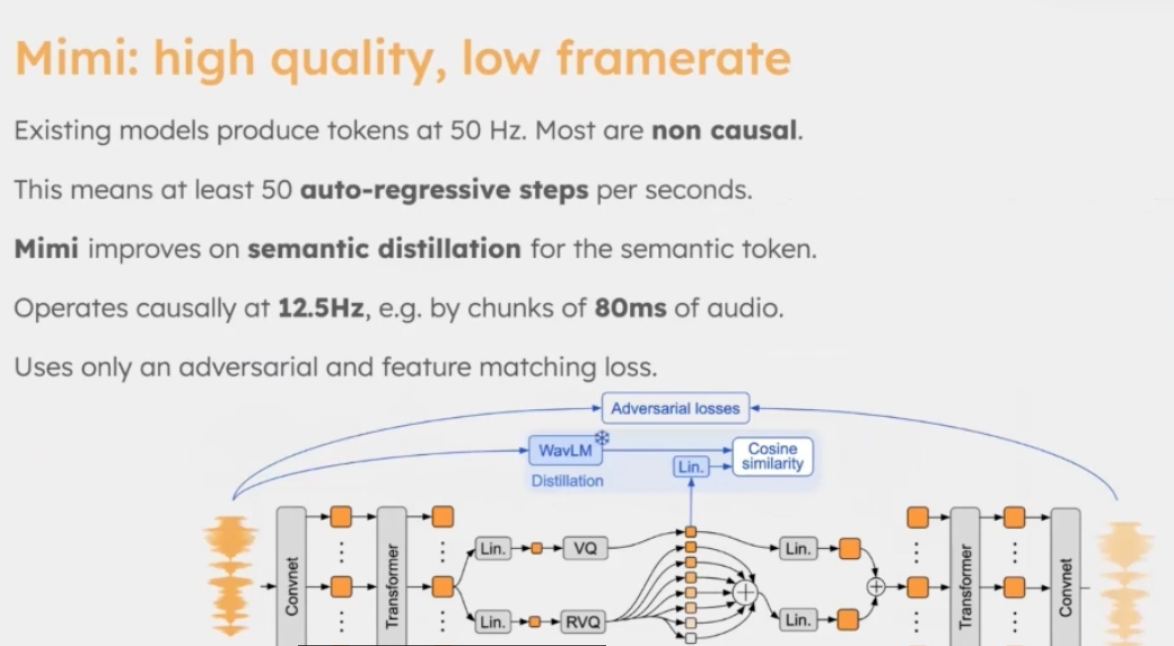
Mimi에서는 기존 neural audio codec보다 프레임 속도를 크게 줄이는 방향을 선택했다. 초기 실험에서 음질과 정보 보존 측면에서 최적의 프레임 속도는 약 50Hz 수준이었지만, 이를 12.5Hz까지 낮추는 데 성공했다. 프레임 수를 줄이면 토큰 수 자체가 감소하기 때문에, 이후 언어 모델링이나 스트리밍 환경에서 훨씬 유리해진다. 이 과정에서 bottleneck 전후에 transformer 레이어를 추가해, 정보 손실을 최소화하면서도 전체 성능을 소폭 개선했다.
semantic distillation을 위해서는 WavLM을 teacher 모델로 사용한다. 구체적으로는 RVQ의 첫 번째 코드북이 담당하는 표현이, 주어진 오디오 프레임에 대한 WavLM의 latent representation을 근사하도록 학습된다. 즉, 가장 상위 코드북이 단순한 음향 세부 정보가 아니라, 상대적으로 의미에 가까운 정보를 담도록 유도하는 구조다.
흥미로운 점은 WavLM 자체는 non-causal 모델이지만, Mimi 전체는 causal 구조를 유지한다는 것이다. 이는 실제 음성 대화형 에이전트를 염두에 둔 설계다. 사용자가 다음에 어떤 말을 할지는 알 수 없기 때문에, 오디오는 항상 과거 정보만을 기반으로 처리되어야 한다. Mimi는 입력 오디오를 causal하게 처리하면서도, 학습 시에는 non-causal teacher(WavLM)의 표현을 distillation하는 방식을 취함으로써, 실시간 스트리밍 환경과의 호환성을 확보한다.
또 하나 인상적인 점은 reconstruction loss를 완전히 제거할 수 있다는 것이다. 객관적인 metric(MSE, SDR 등) 기준으로는 성능이 다소 떨어지지만, 주관적인 청취 평가에서는 오히려 음질이 개선되는 결과를 보였다. 앞서 언급한 feature matching loss와 adversarial loss가 충분히 강력하다면, 굳이 reconstruction loss에 묶일 필요가 없다는 것을 보여준다. 이 경우 모델은 평균적인 복원보다, 실제로 더 자연스럽게 들리는 음성을 만드는 방향으로 학습된다.
훈련 설정을 보면 Mimi는 약 10만 번의 업데이트로 학습되며, adversarial discriminator는 약 2만 5천 번 정도 업데이트된다. adversarial 기반 모델의 장점은 학습은 다소 까다롭지만, 일단 학습이 끝나면 inference가 매우 빠르다는 점이다. 이런 특성 덕분에 Mimi는 diffusion이나 flow matching 기반 모델에 비해 추론 속도 면에서 훨씬 유리하며, 실시간 음성 생성이나 대화형 시스템에 더 적합한 선택지가 된다.
