시작하기 전에...
용어를 헷갈려 하실까봐 spectrum, spectrogram, mel spectrogram, mfcc 의 차이를 간단히 정리하자면 이와 같습니다.
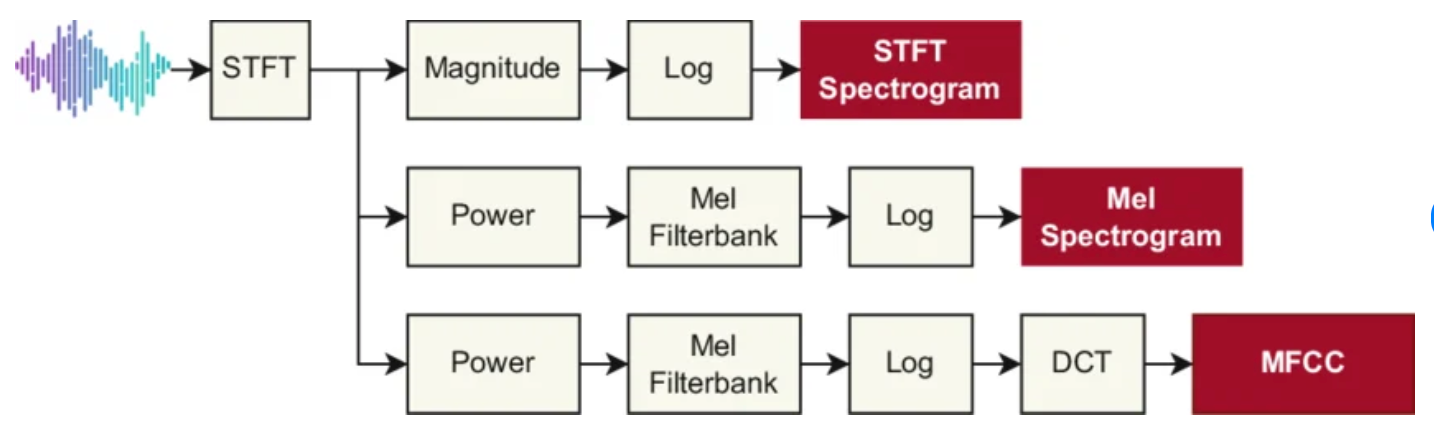
waveform → (pre-emphasis) → STFT(framing(hamming window, overlap, hop size) → 각 프레임에 DFT(실제로는 연산 빠르게 하려고 FFT알고리즘 활용)) → |magnitude|² (power spectrum) → 시간축으로 정렬 (spectrogram) → mel filterbank 적용 (mel spectrogram) → log (log-mel spectrogram) → DCT → MFCC
- spectrum: FT를 통해 frequency domain에서 frequency별 성분이 얼마만큼 있는지 나타낸 것 (복소수 형태로, 크기와 위상 정보를 모두 포함)
- power spectrum: spectrum에서 위상 정보를 버리고 크기의 제곱(|magnitude|²)만 취한 것. frequency별 에너지 분포를 나타낸다.
- spectrogram: power spectrum을 시간축으로 정렬하여 (예를 들어 0~25ms 구간의 power spectrum + 10~35ms 구간의 power spectrum + ...) time-frequency-energy 정보를 나타낸 것
- mel spectrogram: spectrogram에 mel filterbank를 적용한 것. mel filterbank는 사람의 청각 특성을 반영하여 저주파 대역에서는 필터를 촘촘하게, 고주파 대역에서는 넓게 배치한 필터이다. 사람이 저주파에서는 미세한 주파수 차이도 잘 구분하지만 고주파에서는 상대적으로 둔감한 특성을 모사한 것.
- MFCC: log-mel spectrogram에 DCT를 적용한 뒤 낮은 차수의 계수(보통 13개 정도)만 취한 것. 이 낮은 차수의 계수들이 스펙트럼의 전체적인 형태(spectral envelope)를 나타내며, 음성 인식에 유용한 정보를 압축적으로 담고 있다.
- 전통적인 MFCC 추출 과정에서는 pre-emphasis 포함
- 일반적으로 mel spectrogram 구할 때는 pre-emphasis 과정 미포함
배경
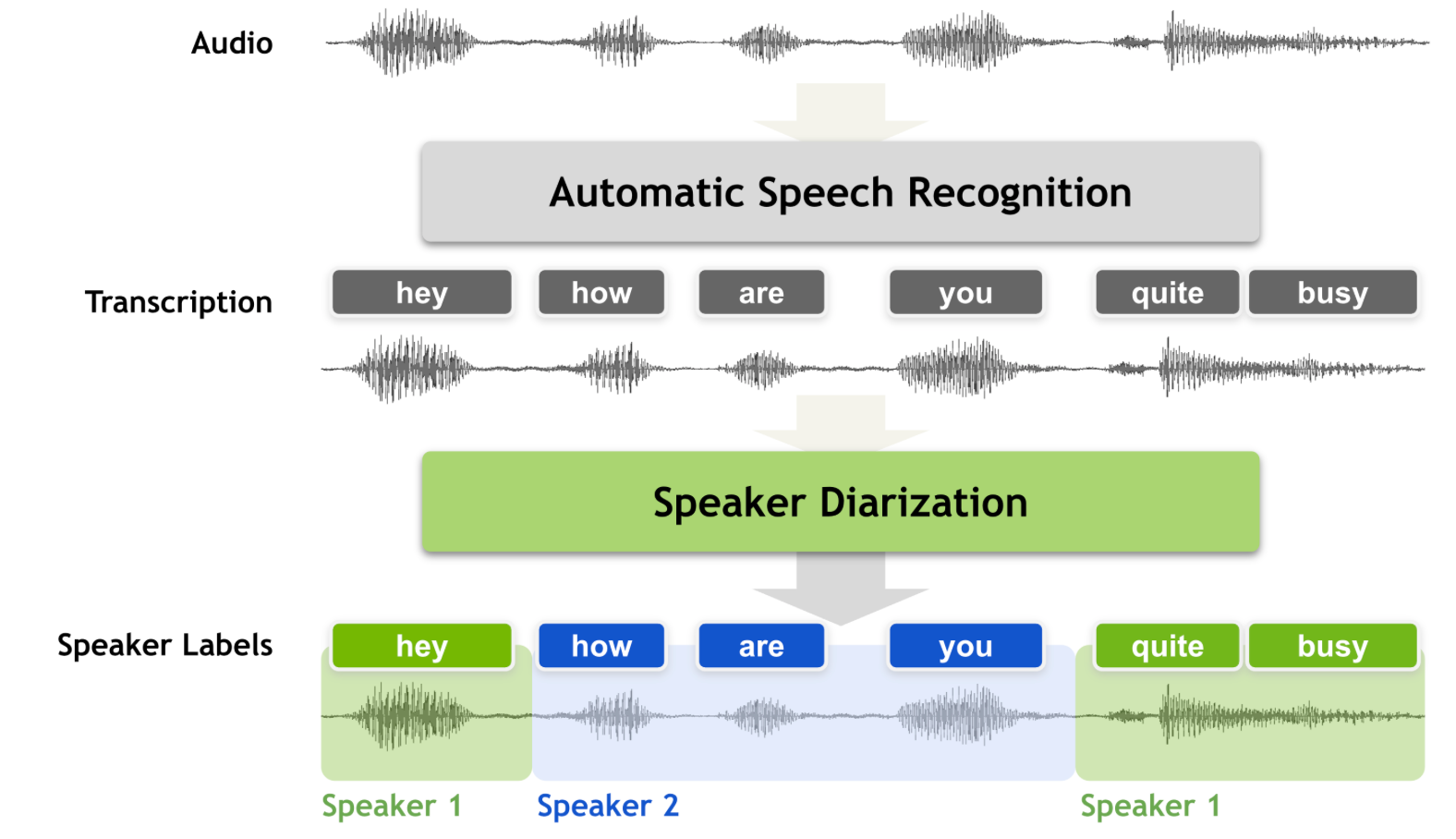
회의록 등을 만들 때 사용되는 화자 분리 기술에 대해서 설명드리고자 합니다. 여러 사람이 의견을 나누는 상황에서는 ASR(음성 인식) 기술로 음성을 텍스트로 바꿔주더라도, 각 발언이 누가 한 말인지 구분이 안되면 회의 내용을 정리하기가 어렵습니다. 실제로 쓸 만한 회의록이 되려면 "00:12~00:47 구간은 화자 A, 00:48~01:23 구간은 화자 B"처럼 발화 구간마다 화자를 자동으로 태깅해 주는 기술이 필요합니다. 이 문제를 푸는 분야가 바로 화자 분리(Speaker Diarization) 기술입니다.
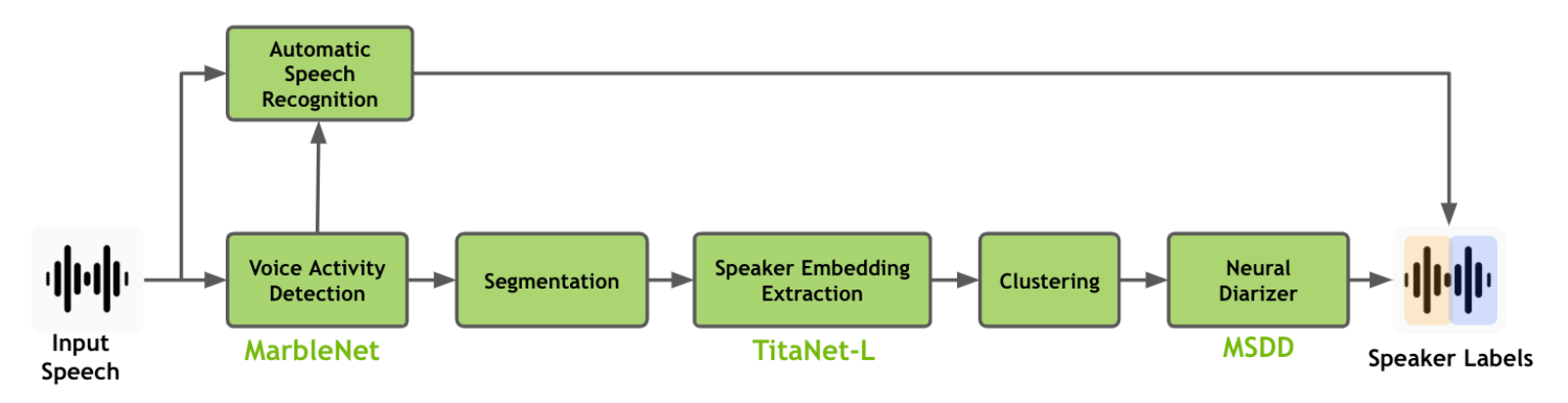
화자 분리를 이해하기 위해서는 데이터에서 어떻게 음성 신호를 캐치하고 음성 특성을 뽑아낼 것인가(VAD, MFCC), 그 특성을 어떻게 저차원 벡터로 압축할 것인가(i-vector, x-vector), 벡터 간 유사도를 어떻게 정의하고 클러스터링할 것인지(LDA, PLDA, AHC), 그리고 결과를 어떻게 정량 평가할 것인지(EER, minDCF, DER)를 알아야합니다.
이 글에서는 화자 분리의 각 요소들을 간단히 소개하고자 합니다.
관련 개념: MFCC, VAD, UBM, i-vector, x-vector, LDA, PLDA, EER, minDCF
화자 분리란 무엇인가
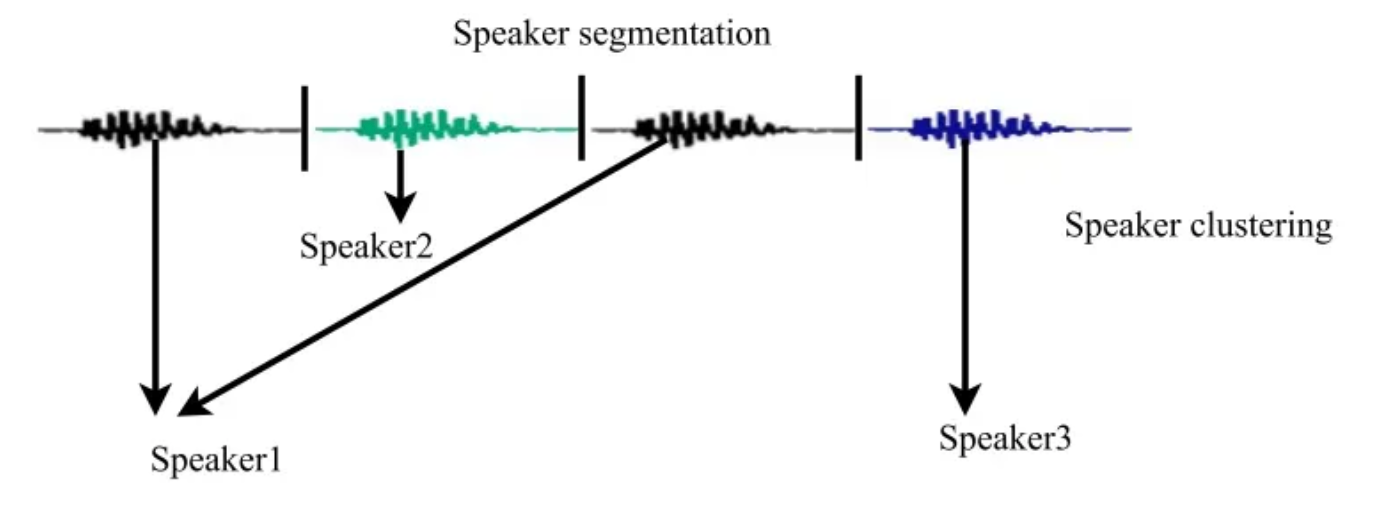
화자 분리(Speaker Diarization)는 여러 사람의 목소리가 섞인 오디오에서 각 발화 구간에 화자 레이블을 붙이는 기술입니다. 회의 녹음, 전화 통화, 팟캐스트 등에서 "이 구간은 화자 A, 저 구간은 화자 B"를 자동으로 알아냅니다.
여기서 중요한 구분이 있습니다. 많이들 헷갈려 하시는데, 화자 분리는 화자 인식(Speaker Recognition)과 목적이 다릅니다.
| 구분 | 화자 인식 (Recognition) | 화자 분리 (Diarization) |
|---|---|---|
| 질문 | "이 사람이 누구인가?" | "몇 명이 말하고, 각각 언제 말하는가?" |
| 사전 등록 | 필요 (등록된 화자 DB 존재) | 불필요 (미지의 화자들) |
| 출력 | 화자 ID 또는 수락/거부 | 시간 구간 + 화자 레이블 (spk_0, spk_1, …) |
화자 분리는 보통 화자의 수조차 사전에 알 수 없는 상황에서 동작해야 합니다. 임베딩 추출기(i-vector, x-vector)와 스코어링 모델(PLDA)은 별도의 레이블 데이터로 사전 학습하지만, 최종적으로 테스트 오디오에서 화자를 나누는 단계는 정답 레이블 없이 유사도 기반으로 묶는 비지도 클러스터링입니다. 이런 점에서 화자 분리는 화자 인식과 다르다고 할 수 있습니다.
MFCC
MFCC(Mel-Frequency Cepstral Coefficients)란
오디오 신호 그 자체(waveform)는 샘플 수가 방대하고, 화자 정보와 무관한 잡음 등의 정보도 뒤섞여 있습니다. 우리가 원하는 것은 오로지 화자 정보를 알 수 있는 간결한 표현이고, 이러한 표현 중 하나로 사용되는 것이 MFCC입니다.
MFCC는 파형 전체를 그대로 사용하지 않고 인간의 청각 특성(mel scale)을 모방하여 스펙트럼 포락(spectral envelope)을 소수의 계수로 압축합니다. 그래서 성도(vocal tract) 특성, 채널 특성, 발성 습관 같은 정보는 어느 정도 남기되, 원 신호의 세밀한 위상 정보 등은 직접 다루지 않습니다. 다시 말해 MFCC는 화자를 구별하는 데 유용한 음향 단서들을 추출하는 단계입니다.
참고로 간단히 말하면, log-mel spectrogram에 DCT를 적용해 얻은 계수가 MFCC입니다.
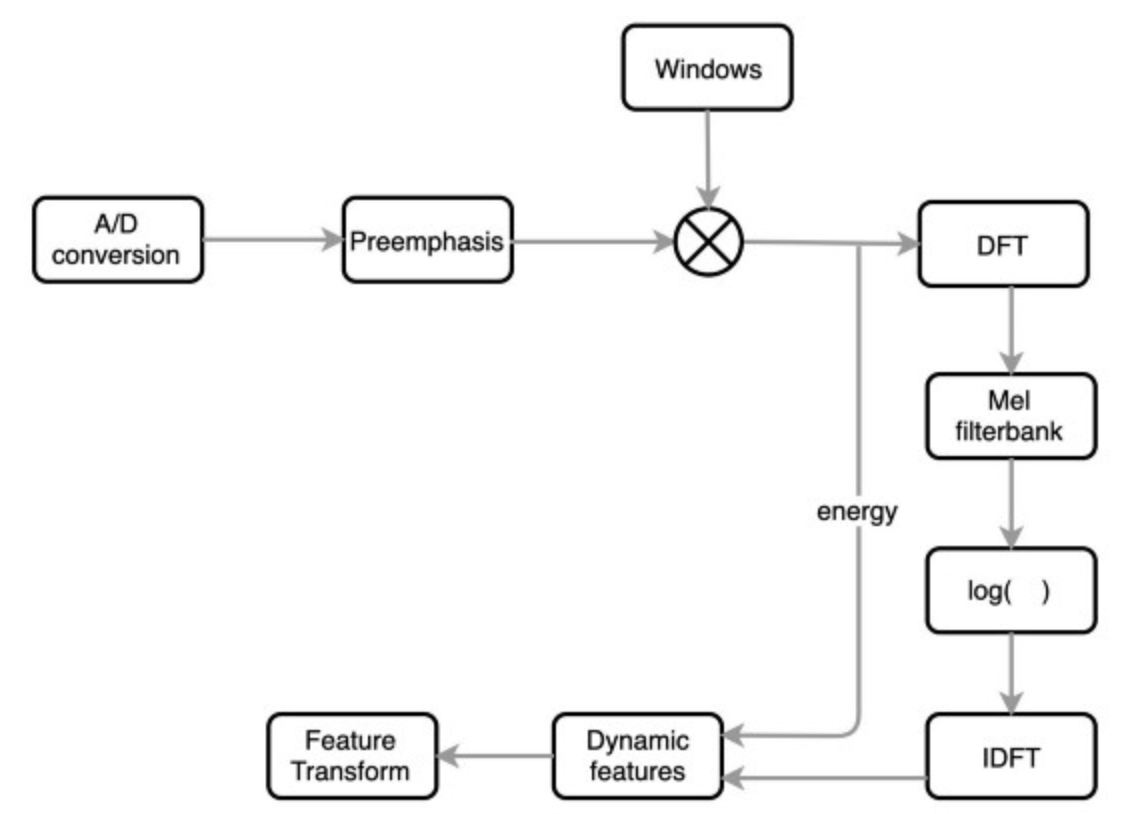
음성 신호에서 MFCC를 추출하는 과정은 다음과 같습니다.
① Pre-emphasis (고주파 강조)
사람의 발성은 고주파로 갈수록 에너지가 감쇠하는 특징을 가지고 있습니다. 이를 보상하기 위해 1차 고역 통과 필터(high-pass filter)를 적용합니다. 필터의 수식은 다음과 같습니다.
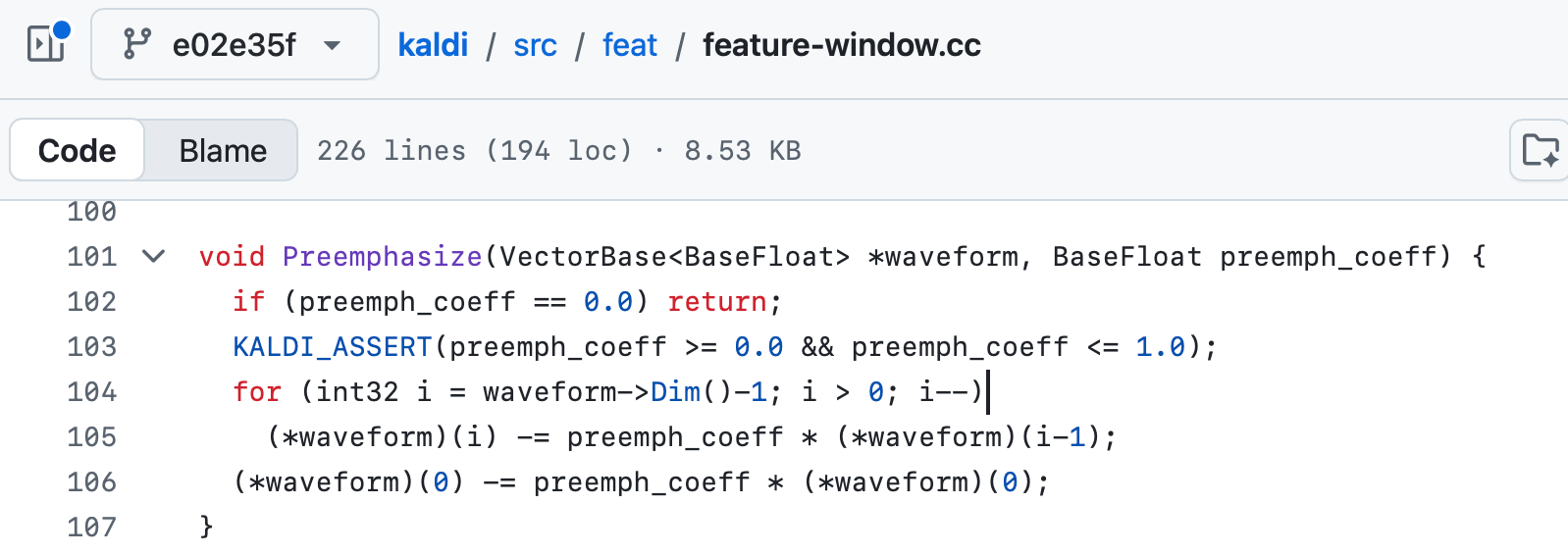
쉽게 말하면, 현재 샘플과 직전 샘플의 차이를 계산하는 연산입니다. x[n]은 원래 오디오의 n번째 샘플, x[n-1]은 바로 직전 샘플, y[n]은 필터를 거친 결과입니다.
이게 왜 고역 통과 필터가 되는지, 예시로 확인해 봅시다. 다음처럼 똑같이 100~130 사이를 오가는 두 가지 신호가 있다고 가정해봅니다,
신호 A — 천천히 올라갔다 내려오는 저주파 (방향 전환 1번):
[100, 110, 120, 130, 120, 110, 100]
신호 B — 빠르게 올라갔다 내려갔다를 반복하는 고주파 (방향 전환 5번):
[100, 130, 100, 130, 100, 130, 100]
같은 필터(α = 0.97)를 적용하면:
| 신호 A (저주파) | 신호 B (고주파) | |
|---|---|---|
| y[1] | 110 − 0.97 × 100 = 13.0 | 130 − 0.97 × 100 = 33.0 |
| y[2] | 120 − 0.97 × 110 = 13.3 | 100 − 0.97 × 130 = −26.1 |
| y[3] | 130 − 0.97 × 120 = 13.6 | 130 − 0.97 × 100 = 33.0 |
| y[4] | 120 − 0.97 × 130 = −6.1 | 100 − 0.97 × 130 = −26.1 |
| y[5] | 110 − 0.97 × 120 = −6.4 | 130 − 0.97 × 100 = 33.0 |
| y[6] | 100 − 0.97 × 110 = −6.7 | 100 − 0.97 × 130 = −26.1 |
| 절댓값 범위 | 6 ~ 14 | 26 ~ 33 |
같은 100~130 범위의 신호인데, 필터 통과 후 고주파 쪽이 더 큽니다. 저주파 신호는 연속된 샘플이 비슷해서 빼면 상쇄되고, 고주파 신호는 매번 방향이 뒤집히니까 빼기가 오히려 차이를 키워주는 겁니다. 결국 이 연산은 변화량을 강조하는 방식이며, 그 결과, 샘플 간 변화가 작으면(저주파) 값이 작아져 저주파가 억제되고, 샘플 간 변화가 크면(고주파) 값이 크게 남아 고주파가 상대적으로 부각됩니다.
이걸 왜 하느냐면, 사람의 발성 원리 때문입니다. 성대(glottal pulse)가 만든 원래 신호는 고주파로 갈수록 감쇠합니다. 그대로 분석하면 저주파에 에너지가 쏠려서 고주파 대역의 정보가 묻히게 되는데, 이 필터로 미리 고주파를 끌어올려서 전 대역의 에너지 밸런스를 맞춰 주는 겁니다. 그래야 이후 FFT → Mel Filterbank 단계에서 고주파 대역의 성도(vocal tract) 특성까지 제대로 포착할 수 있습니다.
α는 0.95~0.97이 관례적으로 사용됩니다.
② Sampling & Windowing (프레임 분할 + 윈도우)
Pre-emphasis된 신호를 20~40 ms 단위의 프레임으로 분할합니다. 음성 신호는 이 정도 짧은 구간에서는 특성이 크게 변하지 않는 '준정상(quasi-stationary)' 상태라고 가정할 수 있기 때문입니다. Kaldi 기본 설정은 25 ms 프레임, 10 ms 시프트로, 1초에 약 100개의 프레임이 생성됩니다.
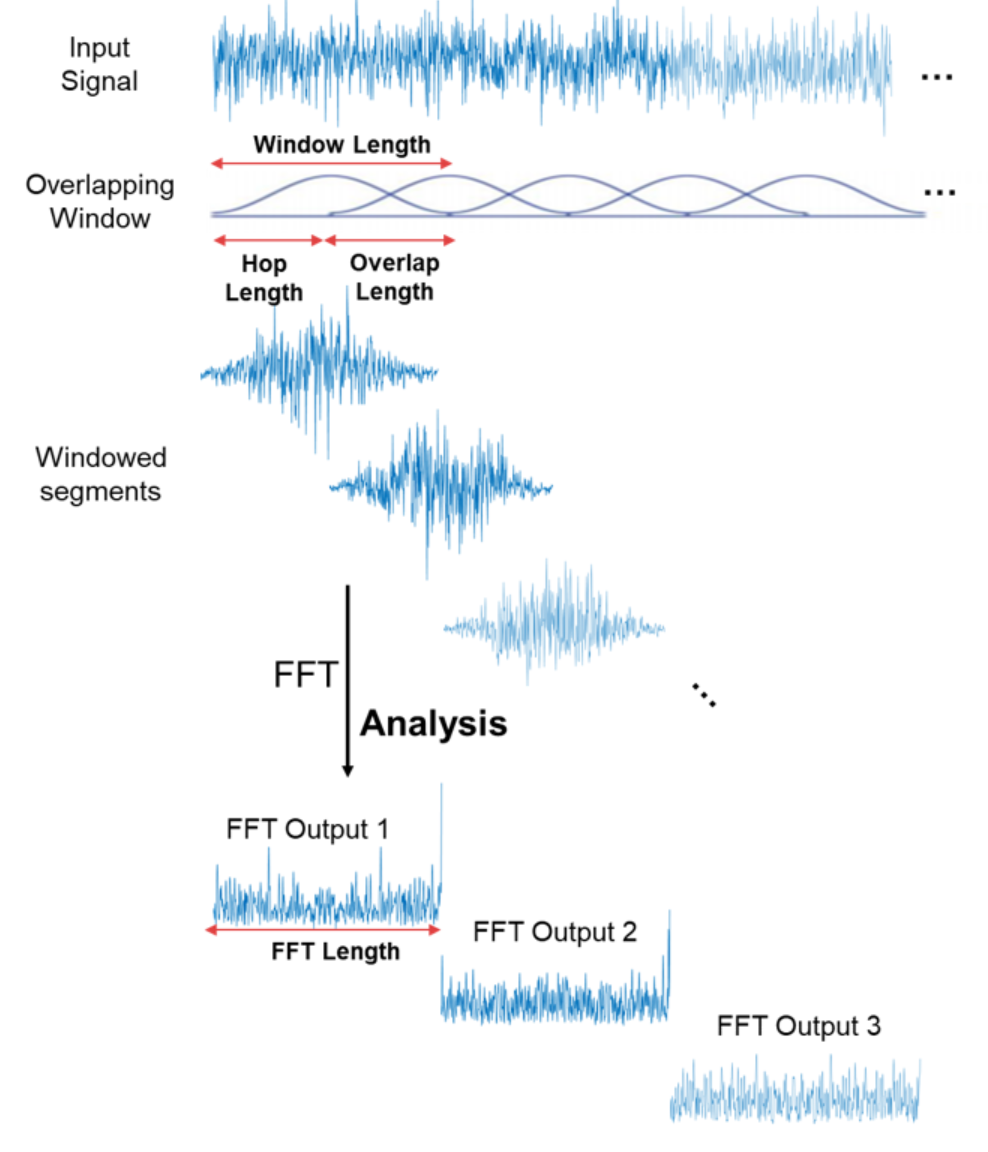
여기서 중요한 점은, 일반적으로 프레임을 겹치게(overlap) 분할한다는 것입니다. 10 ms 시프트에 25 ms 프레임이면 약 60%가 겹칩니다. 겹침 없이 프레임을 분할하면 인접 프레임 간에 공유하는 샘플이 없어 시간적 연속성이 떨어지고, 특히 아래에서 설명할 해밍 윈도우를 적용하면 프레임 양쪽 끝의 에너지가 감쇠되는데, overlap이 없으면 그 감쇠된 구간의 정보가 아예 유실될 수 있습니다. 겹침은 이러한 정보 손실을 보완하기 위한 것입니다.
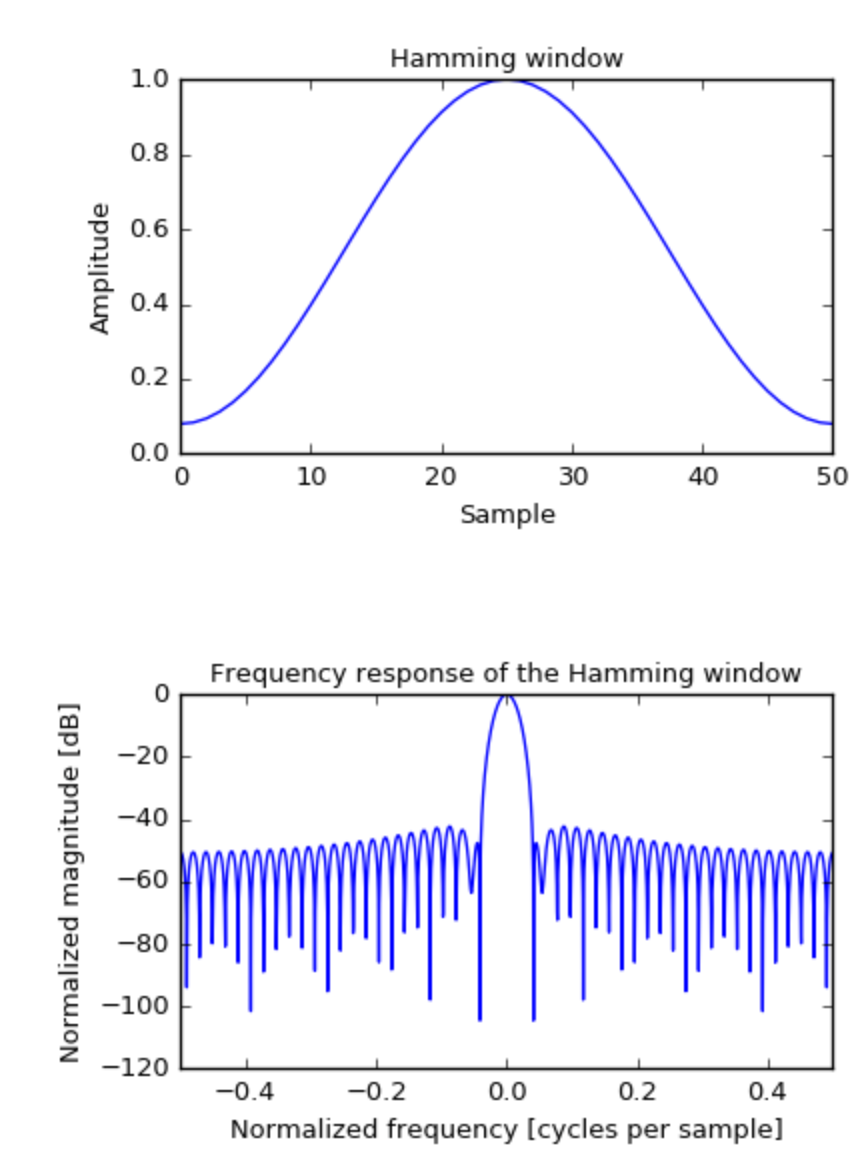
이후 각 프레임에 윈도우 함수(window function)를 곱합니다. 보통 해밍(Hamming) 윈도우를 사용합니다.
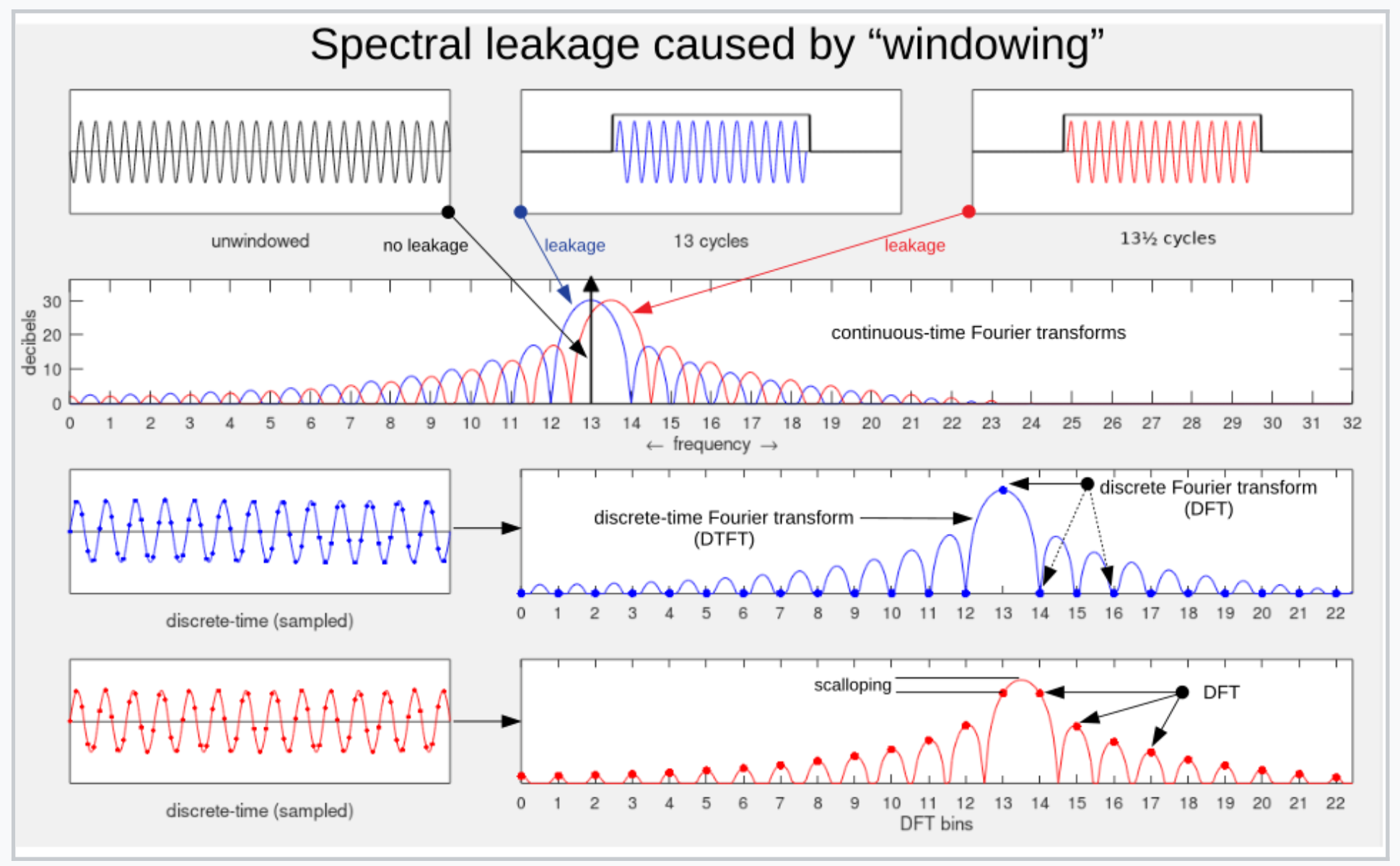
왜 해밍 윈도우를 사용할까요? 프레임을 잘라내는 행위는 사실상 사각형 윈도우(rectangular window)를 곱한 것과 같습니다. 이 경우 프레임 양쪽 끝에서 신호가 갑자기 뚝 끊기면서 불연속점이 생기는데, 이 상태로 FFT를 하면 원래 신호에는 없는 주파수 성분이 가짜로 나타납니다. 이를 spectral leakage라고 합니다. (위 그림에서 원래는 검정색 화살표가 원 신호인데, 프레임을 잘라내면서 파랑색이나 빨간색처럼 원하지 않은 ripple 신호가 생긴 것을 볼 수 있습니다.)
해밍 윈도우는 프레임의 양 끝을 부드럽게 감쇠시켜 이러한 불연속의 급격함을 완화함으로써, spectral leakage를 줄이는 역할을 합니다. 한편, 윈도우를 적용하면 프레임 가장자리의 에너지가 줄어들면서 정보가 손실되는데, 이는 프레임을 겹치게(overlap) 분할하는 것으로 보완합니다. 즉, spectral leakage는 해밍 윈도우로 보완하고, 정보 손실은 overlap으로 보완하는 것입니다.
③ DFT / FFT (이산 푸리에 변환)
각 프레임에 FFT(Fast Fourier Transform)를 적용하여 시간 영역 신호를 주파수 영역으로 변환합니다. 이를 통해 해당 프레임에 어떤 주파수 성분이 얼마나 포함되어 있는지 분석할 수 있습니다.
참고로 DFT(Discrete Fourier Transform)는 시간 영역의 이산 신호를 주파수 성분으로 변환하는 수학적 정의이며, FFT는 DFT를 효율적으로 계산하기 위한 알고리즘입니다. FFT는 DFT의 구조적 대칭성과 주기성을 이용하여 연산량을 줄임으로써 빠른 계산을 가능하게 합니다.
이렇게 FFT를 적용한 결과는 복소수(크기 + 위상)입니다. 여기서 위상 정보를 버리고 크기의 제곱(|magnitude|²)을 취하면 power spectrum이 됩니다. 이는 각 주파수 대역에 에너지가 얼마나 분포하는지를 나타냅니다.
이후 각 프레임에서 구한 power spectrum을 시간축으로 정렬하면 spectrogram이 됩니다. Spectrogram은 시간-주파수-에너지 세 가지 정보를 동시에 나타내는 표현입니다.
④ Mel Filterbank
MFCC 추출에서 가장 핵심적인 단계입니다. 인간의 달팽이관(cochlea)은 주파수에 대해 비선형적인 해상도를 가집니다. 약 1000 Hz 이하에서는 주파수를 선형적으로 구분하지만, 그 이상에서는 로그적으로 인식합니다. 즉 낮은 주파수 대역에서는 미세한 차이도 잘 구분하지만, 높은 주파수 대역에서는 뭉뚱그려서 듣는 것입니다. 이 특성을 모델링한 것이 Mel 스케일입니다.
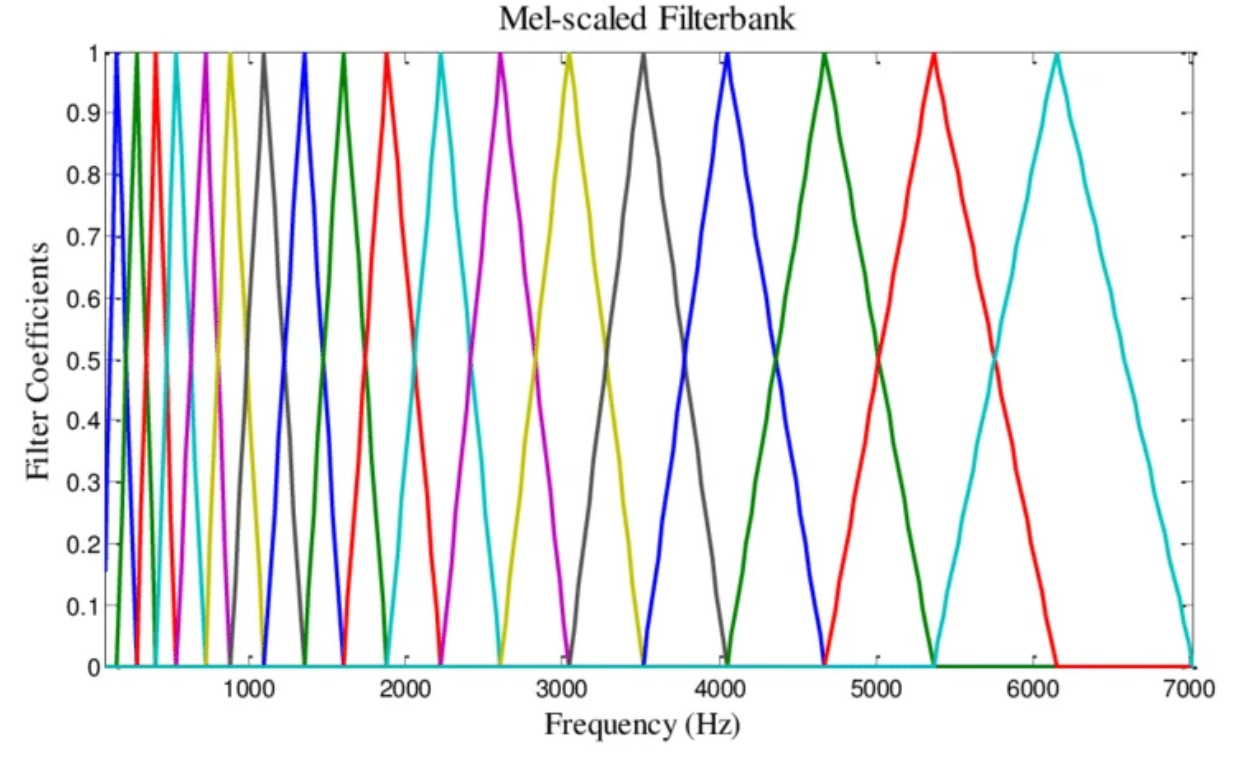
이 Mel 스케일 위에 삼각형 필터(triangular filters) 배치합니다. 달팽이관의 특성을 반영하여, 저주파 대역에는 좁은 삼각형 필터가, 고주파 대역으로 갈수록 넓은 삼각형 필터가 놓입니다. 이 삼각형 필터들의 집합이 바로 Mel Filterbank입니다. 이 필터를 앞에서 구해놓은 spectrogram에 적용한 것을 mel spectrgoram 이라고 부릅니다.
⑤ Log 압축
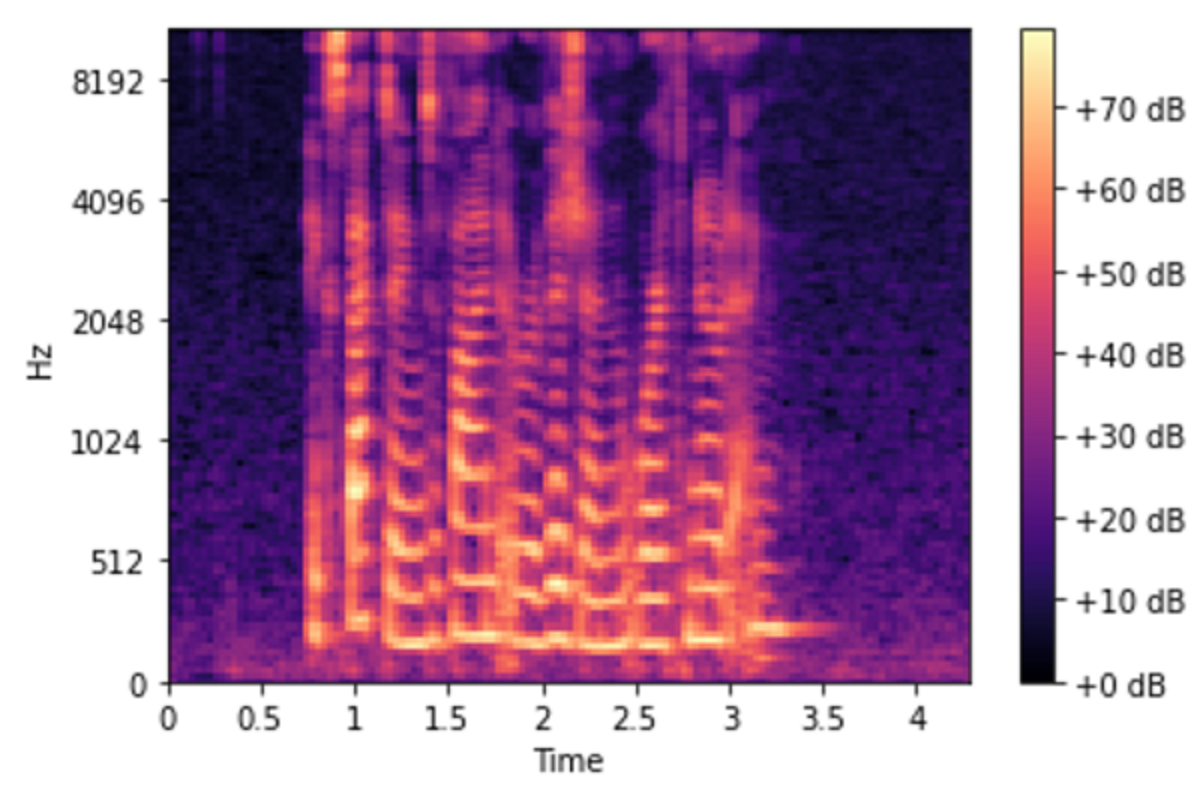
mel spectrogram에 로그를 취합니다. 이를 log-mel spectrogram이라 합니다.
여기에는 두 가지 이유가 있습니다.
첫째, 인간의 음량 인식 자체가 로그적(Weber's law)이기 때문에, 로그를 취하면 사람의 청각 인지에 더 가까운 표현이 됩니다.
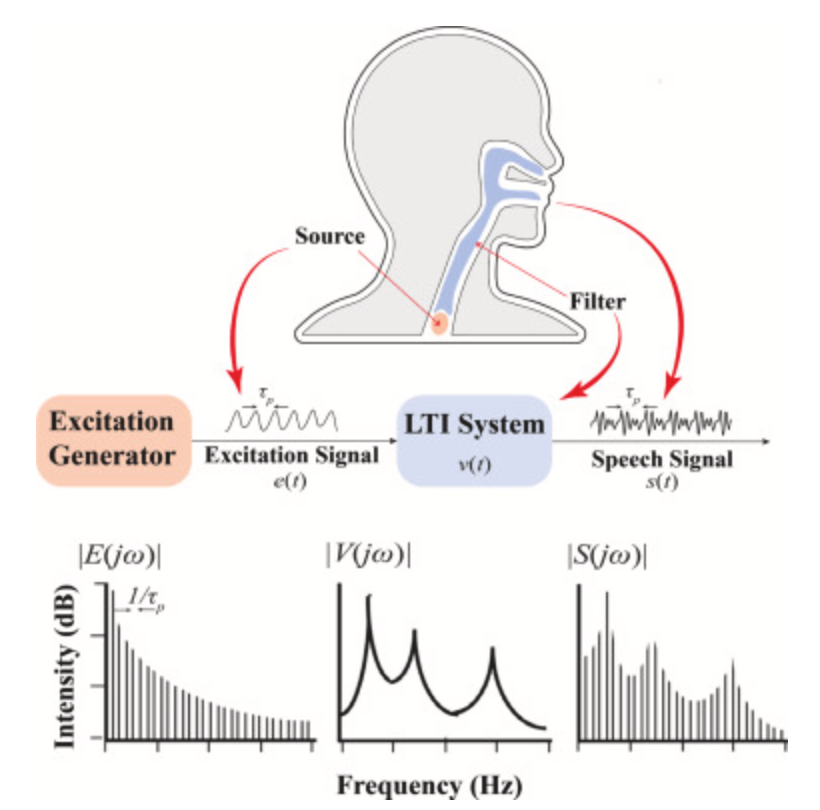
둘째, 위 그림처럼 음성 신호는 음원(source)과 필터(filter)의 결합으로 만들어집니다.
-
음원(source): 성대(vocal cords)가 진동하며 만들어내는 excitation signal입니다. 유성음(voiced sound, 성대가 진동하는 소리 — 모음이나 ㄴ, ㅁ, ㄹ 등)의 경우 기본 주파수(F0)의 배수인 harmonics로 구성되며 고주파로 갈수록 에너지가 감소하고, 무성음(unvoiced sound, 성대가 진동하지 않는 소리 — ㅅ, ㅎ, ㅍ 등)의 경우 비주기적 신호가 됩니다.
-
필터(filter): 성도(vocal tract) — 목, 입, 코 등의 공간 — 의 공명 특성입니다. 혀의 위치, 입술 모양, 입의 개폐 등 성도의 형태 변화에 따라 다양한 모음과 자음이 만들어집니다. 스펙트럼에서 봉우리(formant)로 나타나며, 특히 모음의 경우 formant의 위치가 음소 구분의 핵심 단서가 됩니다.
이 둘은 시간 영역에서 컨볼루션으로 결합되어 있고, 이는 주파수 영역에서 곱셈 관계에 해당합니다. 로그를 취하면 이 곱셈 관계가 덧셈 관계로 변환되어, 이후 DCT 단계에서 음원과 필터 성분을 분리할 수 있는 전제 조건이 됩니다. 또한 마이크나 채널 등에 의한 곱셈적 왜곡(convolutional distortion)도 덧셈으로 전환되어, CMVN(Cepstral Mean and Variance Normalization) 같은 정규화 기법으로 쉽게 제거할 수 있게 됩니다.
참고로 CMVN이란 cepstral 계수의 평균을 0, 분산을 1로 정규화하여 녹음 환경이나 채널 차이로 인한 왜곡을 보상하는 기법입니다.
⑥ DCT (Discrete Cosine Transform)
마지막으로 log-mel spectrogram에 DCT(이산 코사인 변환)를 적용합니다.
이 단계를 이해하기 위해, 먼저 일반적인 스펙트럼에서 cepstrum이 어떻게 만들어지는지 살펴보겠습니다.

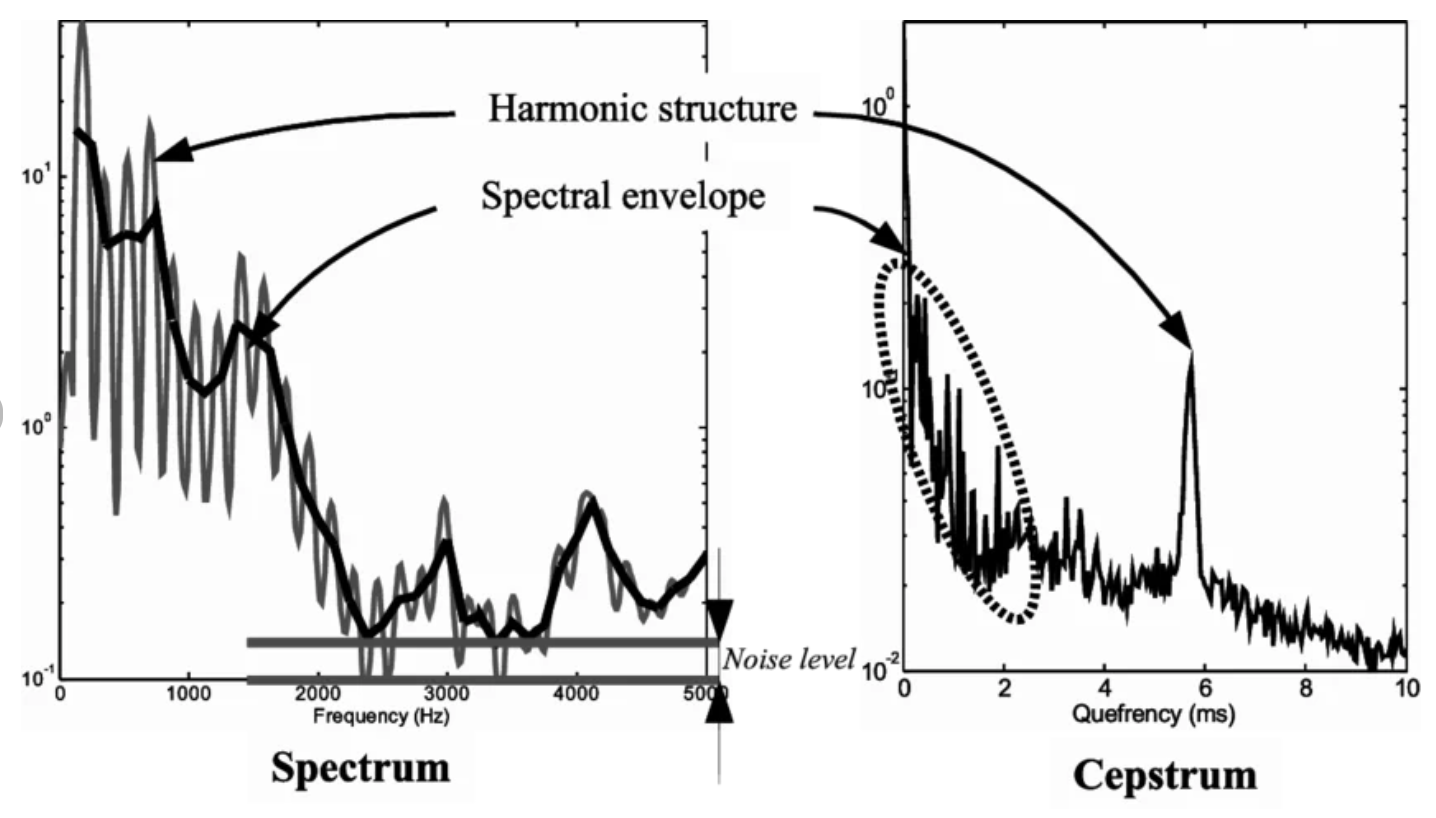
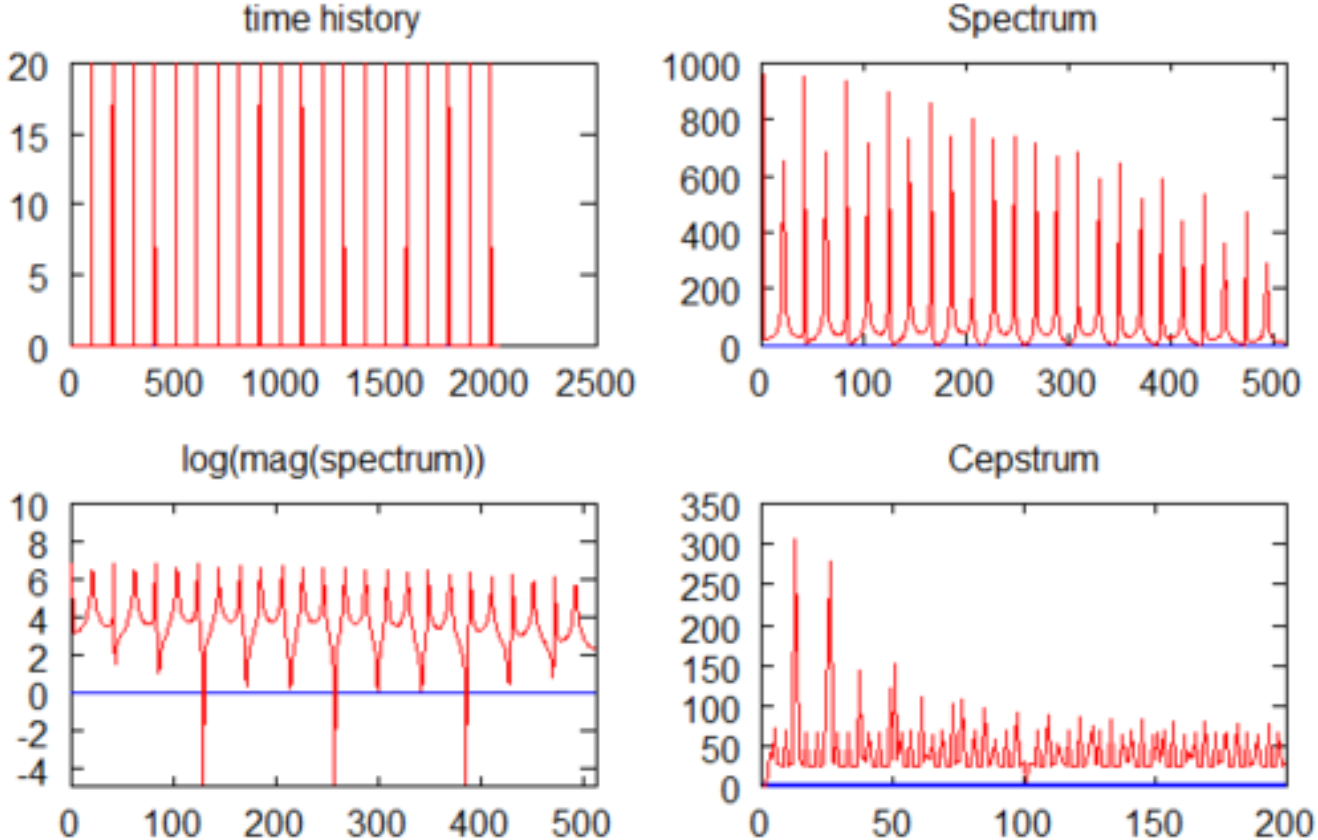
위 그림의 Spectrum을 보면, 봉우리(harmonics)가 일정 간격으로 빽빽하게 반복되고 있고, 그 봉우리들을 감싸는 부드러운 윤곽선(spectral envelope)이 있습니다. 앞서 설명한 source-filter 모델로 보면, 빽빽한 반복 패턴은 성대(source)의 피치 정보이고, 부드러운 윤곽선은 성도(filter)의 형태 정보입니다.
이 두 성분은 주파수 영역에서 곱셈으로 결합되어 있습니다(S = E × V). 우리는 이걸 분리하고 싶습니다. 어떻게 할 수 있을까요?
핵심 아이디어: log로 곱셈을 덧셈으로 바꾼 뒤, IDFT로 분리한다.
- spectrum에 log를 취하면: log(S) = log(E × V) = log(E) + log(V)
이제 log spectrum이라는 숫자 배열 안에는 두 성분이 덧셈으로 나란히 존재합니다.
- log(V) = 주파수 축에서 천천히 변하는 부드러운 윤곽선(envelope)
- log(E) = 주파수 축에서 빠르게 반복되는 harmonics 패턴
이 log spectrum에 IDFT(역 푸리에 변환)를 적용하면, IDFT는 입력 배열 안에 있는 주기적 패턴을 분해해줍니다. 천천히 변하는 성분은 결과의 앞쪽(낮은 index)에, 빠르게 반복되는 성분은 뒤쪽(높은 index)에 나타납니다. log가 없으면 spectrum = E × V (곱셈 상태)이므로 IDFT를 해도 그냥 원래 시간 신호로 복원될 뿐, 두 성분이 깔끔하게 분리되지 않습니다. log를 취해야 덧셈 상태가 되고, 그래야 IDFT가 느린 성분과 빠른 성분을 양쪽으로 분리할 수 있습니다.
위 Cepstrum 그림(오른쪽 아래)으로 보면, 천천히 변하는 성분(envelope)은 낮은 쪽(x축 0~50 부근)에, 빠르게 반복되는 성분(harmonics)은 높은 쪽(x축 50~200 부근의 뾰족한 피크)에 나타납니다. 이 결과가 바로 cepstrum입니다. spectrum의 철자를 뒤집어 cepstrum이라 부릅니다. cepstrum의 x축은 quefrency라 부릅니다(frequency의 철자를 뒤집은 것).
정리하면 cepstrum 그림에서:
- 왼쪽(낮은 quefrency): 스펙트럼에서 천천히 변하는 성분 = 부드러운 윤곽선 = spectral envelope = 성도의 공명 특성
- 오른쪽(높은 quefrency): 스펙트럼에서 빽빽하게 반복되는 성분 = harmonics = 성대의 피치 정보
왜 DFT가 아니라 IDFT를 쓰는가?
실제 수식을 보면 DFT와 IDFT의 차이는 매우 작습니다.
차이는 지수의 부호(+/-)와 1/N 스케일링뿐입니다. 둘 다 본질적으로 "입력 배열을 주기적 성분으로 분해하는 연산"입니다. 첫 번째 DFT로 시간 영역 → 주파수 영역으로 변환했으므로, 다시 주파수 영역 → 시간과 같은 차원(quefrency)으로 돌아가는 방향이라서 IDFT라고 부르는 것입니다. 실제로 real cepstrum의 경우(log magnitude를 입력으로 사용하여 실수이고 대칭인 경우) IDFT를 적용하는 것과 DFT를 적용하는 것은 동일합니다.
그러면 MFCC에서 왜 DCT를 쓰는가?
DFT/IDFT는 코사인과 사인 성분을 모두 사용하여 복소수 결과가 나오지만, DCT는 코사인 성분만 사용하여 실수 결과만 나옵니다. 위에서 구한 Log mel spectrogram은 실수 배열이기 때문에, 복소수 출력이 나오는 DFT/IDFT 대신 실수 출력만 나오는 DCT를 쓰는 것이 더 효율적입니다.
정리하면:
- 전통적 cepstrum: spectrum → log → IDFT (수학적 정의)
- MFCC: mel spectrum → log → DCT (IDFT의 실용적 대체)
이것이 일반적인 cepstrum의 원리입니다. MFCC에서는 원래 스펙트럼을 그대로 쓰는 것이 아니라, 이미 mel filterbank를 적용한 mel spectrogram에서 출발합니다. 여기에 log를 취한 뒤 DCT를 적용하여 cepstrum을 구합니다.
이 DCT 연산의 핵심 목적은 cepstral analysis를 통한 source-filter 분리입니다. 낮은 quefrency의 계수만 취하면 성도의 형태 정보만 추출할 수 있고, 동시에 차원도 압축됩니다. 전통적인 MFCC 시스템에서는 보통 8~13개의 cepstral 계수를 사용하며, 0번째 계수(c₀)는 입력 신호의 평균 log-energy를 나타내기 때문에 (이 프레임이 전체적으로 얼마나 큰 소리인가를 알려줄 뿐 스펙트럼의 형태 정보는 담고 있지 않아서) 제외하는 경우가 많습니다.
또한 부수적으로 상관관계 제거(de-correlation) 효과도 있습니다. 인접한 Mel 필터 대역끼리는 삼각형 필터가 서로 겹치기 때문에 에너지가 상관(correlation)되어 있는데, DCT는 직교 변환(orthogonal transform)이므로 변환 후 계수들이 서로 독립적이 됩니다. 덕분에 이후 GMM 등에서 대각 공분산 행렬만으로도 효과적인 모델링이 가능해집니다.
여기까지의 결과물이 바로 MFCC(Mel-Frequency Cepstral Coefficients)입니다.
왜 하위 계수만 쓰나?
위 Cepstrum 그림에서 볼 수 있듯이, 낮은 quefrency 영역에는 스펙트럼의 완만한 변동 성분, 즉 spectral envelope가 주로 나타나며, 이는 성도의 공명 특성과 밀접하게 관련됩니다. 반면 높은 quefrency 영역에는 스펙트럼의 빠른 주기적 변동 성분이 나타나고, 여기에는 pitch period 및 이에 따른 조화구조(harmonic structure) 정보가 반영됩니다.
음성 인식에서 중요한 것은 화자의 높낮이 자체보다 음소를 구별하는 성도 필터의 특성, 즉 formant를 포함한 spectral envelope입니다. 같은 음소는 피치가 달라져도 동일한 음소로 인식되어야 하므로, 음성 인식용 특징에서는 pitch보다 envelope 정보가 더 필요합니다.
화자 인식이나 화자 분리에서도 성도의 길이, 구강 및 비강 구조와 같은 화자 고유의 생리적 특성이 spectral envelope에 반영되므로, 이는 비교적 안정적인 화자 구분 단서로 활용될 수 있습니다. 다만 pitch 역시 화자 특성을 일부 담고 있어 완전히 불필요한 정보는 아니지만, 발화 상황, 감정, 억양, 문맥에 따라 변동성이 크기 때문에 단독으로는 안정적인 특징이라 보기 어렵습니다.
이러한 이유로 MFCC는 cepstral 계수 중 저차 계수, 즉 주로 spectral envelope를 반영하는 성분을 중심으로 사용하여 성도 정보를 강조하고, pitch와 관련된 고차 quefrency 성분은 상대적으로 억제합니다. 필요에 따라서는 pitch 정보가 별도의 F0 특징으로 추가되어 보완적으로 사용됩니다.
지금까지 화자 분리의 기본이 되는 음성 특징 추출, 그 중 MFCC에 대해 알아보았습니다. 다음 글에서는 이 MFCC를 입력으로 사용하여 화자를 구분하는 임베딩 기법인 i-vector와 x-vector에 대해 다루겠습니다.
