지난번에 이어서 화자 분리에서 사용되는 Voice Acticity Detection(VAD)와 kaldi 에서 사용되는 UBM에 대해서 다뤄보고자 합니다.
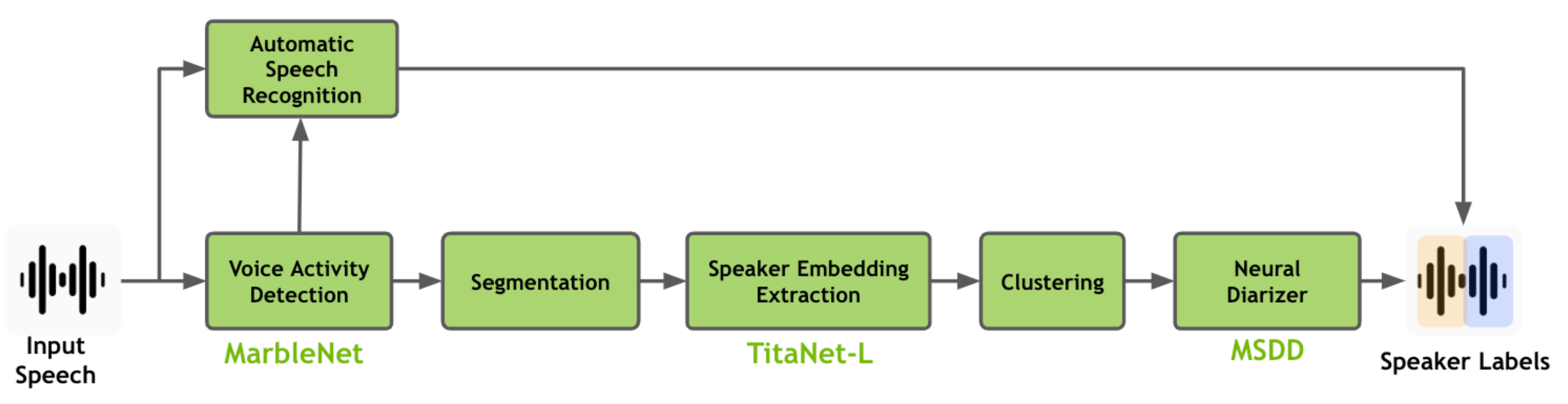
이미지는 엔비디아의 니모를 가져오기는 했는데... kaldi 기반으로 기본 과정을 정리하고 있기 때문에 그림과는 약간 차이가 있습니다 ^^;
1. 시작하며 — 화자 분리 파이프라인에서 VAD와 UBM의 위치
화자 분리(Speaker Diarization)란, 하나의 오디오 녹음에서 "누가, 언제 말했는가?" 를 자동으로 판별하는 기술입니다. 회의 녹취, 콜센터 통화 분석, 미디어 자막 생성 등 수많은 실용 시나리오에서 핵심 전처리 역할을 합니다.
전통적인 화자 분리 시스템의 파이프라인을 크게 그려 보면 다음과 같습니다.
[VAD] → [특징 추출] → [UBM / i-vector] → [클러스터링] → [리세그먼테이션]이 파이프라인에서 VAD(Voice Activity Detection) 는 가장 첫 번째 관문입니다. 전체 오디오에서 사람의 음성이 실제로 존재하는 구간만을 골라내는 역할을 합니다. 음성이 없는 구간 — 침묵, 배경 소음, 음악 등 — 을 하류(downstream) 모듈에 넘기면 불필요한 계산이 늘어날 뿐 아니라, 클러스터링 결과 자체를 심각하게 오염시킵니다.
UBM(Universal Background Model) 은 그 다음 단계에서 등장합니다. "모든 화자의 목소리가 공유하는 일반적인 음향 공간"을 모델링한 것으로, 개별 화자의 특징을 뽑아내기 위한 기준점(reference point) 역할을 합니다. i-vector, supervector 등 화자 표현(speaker representation)을 추출하는 거의 모든 전통적 방법론이 UBM 위에 세워져 있습니다.
이번 글에서는 이 두 모듈을 하나씩 깊이 파고들겠습니다.
2. VAD는 왜 필요한가?
오디오 파일을 떠올려 보세요. 1시간짜리 회의 녹음이라면, 그 안에는 발화 구간뿐 아니라 침묵, 에어컨 소리, 키보드 타이핑 소리, 웃음 소리, 기침 등 다양한 비음성(non-speech) 구간이 뒤섞여 있습니다. 만약 이 전체 신호를 그대로 화자 클러스터링에 넣으면 어떤 일이 벌어질까요?
🚨 핵심 문제
비음성 구간에서 추출된 특징 벡터(feature vector)는 어떤 화자에도 속하지 않지만, 클러스터링 알고리즘은 이 벡터들도 "어딘가에는 할당해야" 합니다. 결과적으로 비음성 프레임들이 하나의 유령 화자(phantom speaker)로 뭉치거나, 기존 화자 클러스터에 섞여 들어가 클러스터 경계를 왜곡합니다.
VAD가 해결하는 것은 단순히 "침묵 제거"가 아닙니다. 더 정확히 말하면, VAD는 다음 세 가지를 동시에 수행합니다.
첫째, 계산 효율. 음성이 없는 구간을 조기에 제거하면, 이후의 특징 추출·UBM 적응·클러스터링 단계에서 처리해야 할 프레임 수가 줄어듭니다. 실시간 시스템에서는 이 차이가 지연(latency) 요구를 충족하느냐 마느냐를 결정짓습니다.
둘째, 화자 표현의 순도. 화자 임베딩(embedding)이나 i-vector를 추출할 때, 비음성 프레임이 섞이면 해당 벡터의 화자 판별력(discriminability)이 떨어집니다. VAD는 "깨끗한 음성 프레임만" 화자 모델링에 투입되도록 보장합니다.
셋째, 세그먼트 경계(segment boundary)의 정확도. 화자 분리의 최종 출력은 "0.0초–3.2초: 화자 A, 3.2초–5.1초: 화자 B …"와 같은 타임스탬프입니다. VAD가 발화의 시작(onset)과 끝(offset)을 정확히 잡지 못하면, 다운스트림에서 아무리 좋은 클러스터링을 해도 경계가 어긋납니다.
3. VAD의 입력: 음성 신호에서 특징 추출까지
VAD가 판단을 내리려면, 원시 파형(raw waveform)을 그대로 보는 것이 아니라 적절한 특징(feature) 으로 변환해야 합니다. 이 과정은 화자 분리 전체에서도 공유되는 단계이므로 한 번 확실히 짚고 넘어갑시다.
프레이밍(Framing)과 윈도잉(Windowing)
음성 신호는 시간에 따라 계속 변하지만, 아주 짧은 구간(약 20~30ms)에서는 상대적으로 안정적입니다. 이것을 준정상(quasi-stationary) 가정이라 합니다. 이 가정에 따라 신호를 짧은 프레임(frame)으로 잘라서 분석합니다.
💡 실무 관례
일반적으로 프레임 길이(frame length) 25ms, 프레임 이동(frame shift) 10ms가 가장 널리 쓰입니다. 이 경우 1초의 오디오에서 약 100개의 프레임이 생성됩니다. 프레임 간에 15ms가 겹치는데(overlap), 이 중첩이 시간적 연속성을 보존해 줍니다.
각 프레임에는 윈도우 함수(window function) 를 곱해 줍니다. 가장 흔히 쓰이는 것은 해밍 윈도우(Hamming window) 입니다. 윈도우를 곱하는 이유는 프레임의 양 끝을 부드럽게 감쇠시켜, 이후 FFT(Fast Fourier Transform)를 적용할 때 발생하는 스펙트럼 누출(spectral leakage)을 줄이기 위함입니다.
에너지(Energy)와 영교차율(Zero-Crossing Rate)
가장 단순한 VAD에서는 프레임 단위의 단기 에너지(short-time energy) 와 영교차율(zero-crossing rate, ZCR) 만으로도 판단합니다.
단기 에너지는 프레임 내 샘플 값의 제곱합입니다. 음성 구간은 배경 소음보다 에너지가 높으므로, 임계값(threshold)을 설정해서 그 위를 음성으로 판단할 수 있습니다. 다만, 이 방법은 SNR(Signal-to-Noise Ratio)이 낮은 환경에서 급격히 성능이 떨어집니다.
영교차율은 신호가 양→음 또는 음→양으로 부호가 바뀌는 횟수입니다. 무성 자음(unvoiced consonant, 예: /s/, /f/)은 에너지는 낮지만 ZCR이 높고, 묵음(silence)은 에너지도 ZCR도 낮다는 특성을 이용합니다.
스펙트럼 특징: MFCC와 Filter Bank
현대적인 VAD는 에너지나 ZCR 같은 시간 영역(time-domain) 특징 대신, 주파수 영역(frequency-domain) 특징을 사용합니다. 그 중 가장 대표적인 것이 MFCC(Mel-Frequency Cepstral Coefficients) 와 Log Mel Filter Bank(log-mel filterbank energy) 입니다.
1단계: FFT (Fast Fourier Transform)
프레임에 윈도우를 곱한 뒤, FFT를 적용하여 시간 영역 신호를 주파수 영역으로 변환합니다. 결과물은 각 주파수 성분의 크기(magnitude)와 위상(phase)인데, 보통 크기 스펙트럼(magnitude spectrum)만 사용합니다.
2단계: 파워 스펙트럼 (Power Spectrum)
크기 스펙트럼의 각 값을 제곱하여 파워 스펙트럼을 구합니다. 이것이 각 주파수 대역의 에너지를 나타냅니다.
3단계: 멜 필터뱅크 (Mel Filter Bank) 적용
인간의 청각 시스템은 저주파에서는 주파수 변화에 민감하고, 고주파에서는 둔감합니다. 이 비선형적 감각을 모사하기 위해, 주파수 축을 멜 스케일(mel scale) 로 변환합니다. 보통 20~40개의 삼각 필터(triangular filter)를 멜 스케일 위에 균등 간격으로 배치하여, 파워 스펙트럼에 적용합니다.
4단계: 로그 압축
필터뱅크 출력에 로그를 취합니다. 로그 압축은 두 가지 목적이 있습니다. 첫째, 인간의 음량 인지가 로그적이라는 점을 반영합니다. 둘째, 이후 DCT를 적용할 때 convolution을 곱셈으로 분리하는 효과(cepstral deconvolution)를 가능하게 합니다. 여기까지가 log-mel filterbank feature입니다.
5단계: DCT (Discrete Cosine Transform) → MFCC
로그 멜 필터뱅크 출력에 DCT를 적용하면 MFCC를 얻습니다. DCT는 필터뱅크 간의 상관관계(correlation)를 제거하여, 서로 독립에 가까운 계수(coefficient)를 만들어 줍니다. 보통 첫 13개의 계수를 사용합니다(c₀ 또는 에너지 + c₁~c₁₂).
💡 MFCC vs. Log-Mel Filterbank, 무엇을 쓸까?
전통적인 GMM 기반 시스템에서는 MFCC가 선호되었습니다. GMM은 입력 특징이 서로 독립이라고 가정하는 대각 공분산(diagonal covariance) 행렬을 많이 쓰는데, DCT가 이 독립 가정을 도와주기 때문입니다. 반면, 딥러닝 기반 시스템에서는 신경망이 스스로 특징 간 상관관계를 학습할 수 있으므로 DCT를 생략하고 log-mel filterbank를 직접 입력하는 것이 더 일반적입니다. 최근의 뉴럴 VAD는 대부분 log-mel filterbank를 사용합니다.
델타(Delta)와 델타-델타(Delta-Delta)
정적(static) 특징만으로는 시간에 따른 변화를 포착하지 못합니다. 그래서 인접 프레임 간의 1차 시간 미분(delta) 과 2차 시간 미분(delta-delta, 또는 acceleration) 을 추가합니다. 예를 들어 13차원 MFCC에 delta 13차원, delta-delta 13차원을 붙이면 총 39차원의 특징 벡터가 됩니다.
여기서 는 번째 프레임의 정적 특징, 는 전후로 참조하는 프레임 수(보통 2)입니다. Delta-delta는 delta 시퀀스에 같은 공식을 한 번 더 적용하면 됩니다.
4. VAD의 핵심 방법론들
VAD는 결국 각 프레임(또는 짧은 구간)에 대해 "음성(speech)인가, 비음성(non-speech)인가?" 라는 이진 분류(binary classification) 문제를 푸는 것입니다. 이 문제를 풀기 위한 방법론은 크게 세 가지 계보로 나눌 수 있습니다.
4.1. 에너지 기반 VAD (Energy-based / Threshold-based)
가장 고전적인 방식입니다. 앞서 설명한 단기 에너지와 ZCR에 임계값을 설정합니다. ITU-T G.729B는 전화 통신에서 오랫동안 사용된 표준 VAD로, 풀밴드 에너지(full-band energy), 저밴드 에너지(low-band energy), ZCR, 스펙트럼 차이(spectral difference)의 네 가지 특징을 사용합니다.
장점: 계산량이 극도로 적어 임베디드 기기에서도 실시간 동작 가능합니다.
한계: 배경 소음이 조금만 커져도(SNR < 15dB) 급격히 성능이 떨어집니다. 에너지가 높은 소음(TV 소리, 음악)과 에너지가 낮은 음성(속삭임, 무성 자음)을 구분하지 못합니다.
4.2. 통계 모델 기반 VAD (Statistical Model-based)
소음과 음성을 각각 확률 분포로 모델링하고, 프레임마다 우도비(likelihood ratio) 를 계산하여 판단합니다.
대표적인 방법이 Sohn et al. (1999) 의 통계적 VAD입니다. 이 방법은 DFT(Discrete Fourier Transform) 계수의 각 주파수 빈(bin)이 복소 가우시안(complex Gaussian) 분포를 따른다고 가정합니다.
여기서 는 번째 주파수 빈의 DFT 계수입니다. 가설(음성 존재)과 가설(비음성) 각각에서의 우도를 계산하고, 그 비율이 임계값을 넘으면 음성으로 판정합니다. 실제로는 각 주파수 빈의 우도비를 곱하거나 로그를 취해 전체 프레임의 판정치를 구합니다.
소음의 분산(variance)은 비음성 구간에서 추정하고, 음성 구간에서는 고정합니다. 이를 위해 소음 추정(noise estimation) 알고리즘이 필요한데, MCRA(Minimum Controlled Recursive Averaging) 같은 방법이 병행됩니다.
통계 모델 기반 VAD는 HMM(Hidden Markov Model)과 결합하여, 프레임 단위 결정에 시간적 연속성(temporal continuity)을 부여하기도 합니다. 음성-비음성 간 전이 확률(transition probability)을 모델링하면, 단발성 오판(짧은 비음성을 음성으로, 또는 그 반대)을 효과적으로 줄일 수 있습니다.
4.3. 딥러닝 기반 VAD (Neural VAD)
최근의 VAD는 신경망을 사용하는 것이 주류입니다. 프레임 단위(또는 짧은 세그먼트 단위)로 음성/비음성 확률을 출력하는 이진 분류 네트워크를 학습합니다.
DNN/LSTM 기반 VAD
Google의 WebRTC VAD 이후, 소규모 DNN이나 LSTM(Long Short-Term Memory) 네트워크를 사용한 VAD가 등장했습니다. 입력으로 log-mel filterbank를 받고, 출력으로 각 프레임의 음성 확률을 내보냅니다. 컨텍스트 윈도우(context window)를 통해 현재 프레임 전후의 몇 개 프레임도 함께 보기 때문에, 시간적 문맥을 반영할 수 있습니다.
pyannote.audio의 VAD
화자 분리 연구에서 가장 널리 쓰이는 오픈소스 툴킷 중 하나인 pyannote.audio는 SincNet/LSTM/Transformer 기반의 뉴럴 VAD를 제공합니다. 이 모델은 단순한 음성/비음성 분류를 넘어, "겹침 음성(overlapped speech)" 구간까지 검출합니다. 겹침 음성 검출은 화자 분리에서 특히 중요한데, 겹침 구간에서는 단일 화자를 가정하는 클러스터링이 실패하기 때문입니다.
Silero VAD
Silero VAD는 경량화에 초점을 맞춘 모델로, ONNX 포맷으로 제공되어 다양한 환경에서 빠르게 추론(inference)할 수 있습니다. 모델 크기가 작지만, 다양한 언어와 소음 환경에서 준수한 성능을 보여 실무에서 많이 활용됩니다.
🔑 방법론 선택 가이드
임베디드/실시간 저지연 시스템에서는 에너지 기반 또는 소규모 뉴럴 VAD를, 오프라인 대용량 처리에서는 pyannote.audio 같은 더 무거운 모델을 사용하는 것이 일반적입니다. 핵심은 VAD 오류가 전체 파이프라인에 전파(error propagation)된다는 점입니다 — VAD에서의 missed speech는 해당 발화가 영영 분석되지 못함을 의미하고, false alarm은 비음성을 음성으로 넘겨 화자 모델을 오염시킵니다.
5. VAD 실전 — 출력 형태와 후처리
VAD의 출력: 프레임 레벨 vs. 세그먼트 레벨
VAD 모델은 보통 각 프레임에 대해 음성 확률(speech probability) 을 출력합니다. 예를 들어, 10ms 프레임 시프트를 사용하면 1초에 100개의 확률값이 나옵니다.
이 연속적인 확률값을 이산적인 음성/비음성 판정으로 바꾸기 위해서는 임계값(threshold) 이 필요합니다. 보통 0.5를 기본으로 쓰지만, 용도에 따라 조정합니다. 임계값을 낮추면(예: 0.3) 더 많은 구간을 음성으로 잡아 missed speech를 줄이는 대신 false alarm이 늘고, 높이면(예: 0.7) 그 반대입니다.
후처리: 스무딩과 최소 길이 제약
프레임 단위 판정을 그대로 쓰면 아주 짧은 음성/비음성 구간이 산발적으로 나타나는 문제가 있습니다. 이를 방지하기 위한 후처리 기법들이 있습니다.
미디언 필터링(median filtering) 은 연속된 N개의 프레임 판정값에 대해 중앙값을 취해서 산발적인 토글을 제거합니다. 최소 발화 길이(minimum speech duration) 제약은 너무 짧은 음성 세그먼트(예: 100ms 미만)를 비음성으로 전환합니다. 반대로 최소 묵음 길이(minimum silence duration) 제약은 너무 짧은 비음성 구간(예: 200ms 미만)을 음성으로 채워서, 단어 사이의 짧은 쉼(pause)으로 발화가 조각나는 것을 방지합니다.
출력 포맷: RTTM
VAD의 최종 출력은 보통 RTTM(Rich Transcription Time Marked) 파일이나 이와 유사한 시간 구간 리스트로 표현됩니다.
SPEAKER meeting01 1 0.500 3.200 <NA> <NA> speech <NA> <NA>
SPEAKER meeting01 1 4.100 2.800 <NA> <NA> speech <NA> <NA>
SPEAKER meeting01 1 8.300 5.100 <NA> <NA> speech <NA> <NA>각 줄은 "어느 파일에서, 몇 초부터, 몇 초 동안 음성이 존재한다"를 뜻합니다. 이 음성 구간 리스트가 다음 단계인 특징 추출과 UBM 기반 화자 모델링으로 넘어갑니다.
6. UBM은 왜 필요한가?
VAD가 음성 구간을 골라냈다면, 이제 그 구간에서 "이 목소리가 누구의 것인지" 를 판별할 수 있는 표현(representation)을 만들어야 합니다.
가장 직관적인 접근은 각 화자마다 별도의 모델을 학습하는 것입니다. 그러나 화자 분리에서는 근본적인 문제가 있습니다 — 화자가 누구인지 사전에 알 수 없고, 각 화자의 데이터도 아주 적습니다. 회의 녹음에서 한 사람이 말한 구간이 총 30초에 불과할 수도 있는데, 이 30초로 음향 모델을 바닥부터 학습하는 것은 현실적으로 불가능합니다.
🔑 UBM의 핵심 아이디어
"먼저 수천 명의 음성으로 '보편적인 목소리 지도(universal voice map)'를 만들어 놓자. 그리고 새로운 화자의 짧은 음성이 들어오면, 이 지도 위에서 어느 방향으로 얼마나 벗어나는지(deviation)를 계산하자." — 이것이 UBM의 핵심 발상입니다.
즉, UBM은 화자 독립적(speaker-independent) 인 배경 모델입니다. "인간의 음성이라면 대체로 이런 음향적 분포를 가진다"를 포착한 모델이며, 개별 화자의 특성을 잡으려는 것이 아닙니다. 개별 화자의 특성은 UBM으로부터의 편차(deviation) 로 표현됩니다.
7. UBM의 수학적 기반: Gaussian Mixture Model
UBM은 GMM(Gaussian Mixture Model) 으로 구현됩니다. GMM을 먼저 이해해야 UBM을 이해할 수 있으므로, GMM의 수학을 차근차근 풀어보겠습니다.
GMM이란?
GMM은 데이터의 분포를 여러 개의 가우시안(정규분포)의 가중합(weighted sum)으로 모델링하는 확률 모델입니다. 왜 하나의 가우시안이 아니라 여러 개가 필요할까요?
음성 신호의 특징 벡터 분포를 생각해 보세요. 모음 /a/를 발음할 때의 MFCC와 모음 /i/를 발음할 때의 MFCC는 특징 공간(feature space) 상에서 서로 다른 영역에 모여 있습니다. 자음 /s/는 또 다른 곳에 위치합니다. 이런 다봉성(multi-modal) 분포는 단일 가우시안으로는 절대 포착할 수 없습니다. 여러 개의 가우시안을 섞으면, 각 가우시안이 특징 공간의 한 영역(하나의 음소 클래스, 또는 조음 방식의 한 유형)을 담당하여 전체 분포를 유연하게 모델링할 수 있습니다.
GMM의 수학적 정의
D차원 특징 벡터 x에 대한 GMM의 확률밀도함수는 다음과 같습니다.
여기서 각 기호의 의미는 다음과 같습니다.
K는 혼합 성분(mixture component)의 개수입니다. UBM에서는 보통 512, 1024, 또는 2048개를 사용합니다.
는 번째 성분의 혼합 가중치(mixture weight)입니다. 모든 의 합은 1이고, 각각은 0 이상이어야 합니다. 직관적으로 "전체 데이터에서 이 성분이 차지하는 비율"로 이해할 수 있습니다.
는 평균 벡터 와 공분산 행렬 를 가지는 D차원 가우시안 분포입니다.
따라서 GMM의 모든 파라미터를 한데 모으면 로 표현됩니다.
대각 공분산 vs. 전체 공분산
이론적으로 공분산 행렬 는 D×D의 전체 행렬(full covariance)이지만, 실무에서 UBM에는 거의 항상 대각 공분산(diagonal covariance) 을 사용합니다. 이유는 두 가지입니다.
첫째, 계산 효율. 전체 공분산 행렬은 개의 파라미터를 가지지만, 대각 공분산은 개만 있으면 됩니다. , (39차원 MFCC)일 때, 전체 공분산은 성분당 개인데 비해 대각은 39개이므로 약 40배 차이입니다.
둘째, MFCC의 특성. 앞서 설명했듯이 DCT가 필터뱅크 간 상관관계를 상당 부분 제거하므로, MFCC의 차원 간 상관이 작아 대각 공분산의 가정이 크게 위배되지 않습니다. 성분 수 K를 충분히 크게 잡으면, 대각 공분산 GMM이 전체 공분산 GMM에 근사할 수 있다는 것도 알려져 있습니다.
8. UBM은 어떻게 학습되는가?
UBM을 학습한다는 것은, 대규모 음성 데이터셋에서 GMM 파라미터 를 추정하는 것입니다. 이 추정에는 EM(Expectation-Maximization) 알고리즘이 사용됩니다.
EM 알고리즘의 직관
EM은 "관측되지 않은 잠재 변수(latent variable)가 있는 상황에서 최대우도추정(MLE)을 수행하는" 반복적(iterative) 알고리즘입니다. GMM에서 잠재 변수는 "각 데이터 포인트가 어느 가우시안 성분에서 생성되었는가?" 입니다. 이 정보를 안다면 파라미터 추정은 단순한 통계량 계산이 되지만, 모르기 때문에 EM이 필요합니다.
EM은 두 단계를 번갈아 반복합니다.
E-step (Expectation step): 사후 확률 계산
현재 파라미터 하에서, 각 데이터 포인트 가 번째 성분에 속할 사후 확률(posterior probability), 즉 responsibility 를 계산합니다.
직관적으로, 는 "현재 모델이 보기에, 이 프레임 를 번째 가우시안이 생성했을 가능성이 얼마나 되는가?"를 뜻합니다. 분자는 번째 성분이 를 생성할 결합 확률이고, 분모는 모든 성분에 대해 합산한 값으로 정규화 상수 역할을 합니다.
M-step (Maximization step): 파라미터 갱신
E-step에서 구한 responsibility를 이용하여, 각 성분의 파라미터를 갱신합니다.
는 번째 성분에 할당된 "유효 데이터 수(effective count)"입니다. 하드 할당이 아니라 소프트 할당이므로 정수가 아닌 실수입니다.
는 유효 데이터 수의 비율로 갱신됩니다 — 데이터가 많이 몰리는 성분은 가중치가 커집니다.
는 로 가중된 데이터의 가중 평균입니다.
는 로 가중된 공분산입니다.
이 두 단계를 로그 우도(log-likelihood)가 수렴할 때까지(또는 정해진 반복 횟수만큼) 반복하면, 데이터의 분포를 가장 잘 설명하는 GMM 파라미터가 얻어집니다.
UBM 학습 시 실무적 고려사항
학습 데이터의 다양성
UBM은 "보편적인" 음성 분포를 모델링해야 하므로, 학습 데이터는 가능한 한 다양한 화자, 언어, 채널, 환경을 포함해야 합니다. NIST SRE 데이터, VoxCeleb, LibriSpeech 등의 대규모 코퍼스가 흔히 사용됩니다. 성별 균형, 연령 분포, 전화/마이크/원거리 등 다양한 채널 조건을 포함시키는 것이 중요합니다.
성분 수 K의 선택
K가 클수록 더 세밀한 음향 공간을 표현할 수 있지만, 파라미터 수도 비례하여 늘어나며 학습과 추론에 더 많은 연산이 필요합니다. 전통적으로 K = 512 ~ 2048이 화자 인식/분리에서 사용됩니다. K가 너무 작으면 음향 공간의 세밀한 구조를 놓치고, 너무 크면 일부 성분이 데이터 부족으로 불안정해집니다.
초기화: K-means + EM
EM 알고리즘은 초기값에 민감합니다. 실무에서는 먼저 K-means 클러스터링으로 데이터를 K개의 클러스터로 나누고, 각 클러스터의 평균과 분산으로 GMM 파라미터를 초기화한 뒤 EM을 돌리는 것이 표준적인 접근입니다.
분산 플로어링 (Variance Flooring)
학습 과정에서 일부 가우시안 성분의 분산이 0에 가까워지면 수치적 불안정(numerical instability)이 발생합니다. 이를 방지하기 위해 분산의 최소값(floor)을 설정합니다. 보통 전체 분산의 일정 비율(예: 0.01배)로 잡습니다.
9. UBM이 화자 분리에서 하는 역할
UBM이 학습된 뒤에는, 새로운 음성 데이터가 들어올 때 개별 화자를 어떻게 표현할 것인가의 문제가 남습니다. 여기서 UBM은 두 가지 대표적인 방식으로 활용됩니다.
9.1. MAP 적응을 통한 화자별 GMM
MAP(Maximum A Posteriori) 적응은 Reynolds et al. (2000)이 제안한 방법으로, UBM-GMM 기반 화자 모델링의 핵심입니다.
아이디어는 이렇습니다. UBM은 이미 "인간 음성의 일반적 분포"를 잘 학습하고 있습니다. 새로운 화자 s의 짧은 음성 데이터가 주어졌을 때, 이 데이터만으로 GMM을 바닥부터 학습하는 대신, UBM의 파라미터를 이 화자의 데이터 방향으로 조금 밀어주는(adapt) 것입니다.
여기서 는 화자 s의 데이터에서 번째 성분에 할당된 프레임들의 가중 평균이고, 은 UBM에서의 번째 평균 벡터입니다. 는 적응 계수(adaptation coefficient)로, 해당 성분에 할당된 데이터가 많을수록 1에 가까워져 데이터 쪽을 더 신뢰하고, 적으면 0에 가까워져 UBM 쪽을 더 신뢰합니다.
여기서 은 관련 인자(relevance factor)로, 사전에 설정하는 하이퍼파라미터입니다(보통 16 정도). 가 보다 훨씬 크면 이 되어 데이터를 거의 그대로 반영하고, 가 작으면 UBM의 사전 정보(prior)에 의존합니다. 이것이 바로 Bayesian 적응의 아름다움입니다 — 데이터가 적을 때 자동으로 사전 분포(UBM)로 회귀합니다.
💡 왜 평균만 적응하는가?
실무에서는 대부분 평균 벡터(μ)만 적응하고, 가중치(w)와 공분산(Σ)은 UBM의 값을 그대로 사용합니다. 이유는 두 가지입니다. 첫째, 실험적으로 평균만 적응해도 화자 판별력의 대부분이 확보됩니다. 둘째, 가중치와 공분산까지 적응하면 파라미터 수가 크게 늘어나 적은 데이터로 안정적인 추정이 어렵습니다.
9.2. Supervector와 i-vector
MAP 적응으로 얻은 화자별 GMM에서, 모든 K개 성분의 적응된 평균 벡터 를 하나로 이어붙이면(concatenate), GMM 슈퍼벡터(supervector) 가 됩니다.
, (39차원 MFCC)이면 슈퍼벡터의 차원은 차원입니다. 이 고차원 벡터가 한 화자의 음향적 특성을 담고 있습니다. 같은 화자의 서로 다른 발화에서 추출한 슈퍼벡터는 가까이 모이고, 다른 화자의 슈퍼벡터와는 멀어지는 것이 이상적입니다.
하지만 39,936차원은 너무 고차원입니다. 여기에 Total Variability(전체 가변성) 모델이 등장하여 이 슈퍼벡터를 저차원 공간(보통 400차원 내외)으로 사영(project)합니다. 이 저차원 벡터가 바로 i-vector입니다.
은 UBM 슈퍼벡터(모든 화자의 평균), 는 전체 가변성 행렬(total variability matrix), 가 바로 화자 s의 i-vector입니다. 는 대규모 데이터에서 Factor Analysis로 학습됩니다.
i-vector 추출 과정에서 UBM은 두 가지 역할을 합니다. 첫째, 기준점() 을 제공합니다. 둘째, i-vector를 추출할 때 각 프레임의 Baum-Welch 통계량(zeroth-order와 first-order statistics) 을 UBM의 성분별로 계산하는데, 이때 UBM의 성분 구조가 그대로 사용됩니다.
여기서 는 UBM에서 계산된 프레임 의 번째 성분에 대한 사후 확률입니다. 이 통계량이 주어지면, i-vector 는 사후 분포의 기대값으로 구해집니다.
10. VAD → UBM: 두 모듈의 연결
지금까지 VAD와 UBM을 각각 살펴봤습니다. 이제 이 둘이 화자 분리 파이프라인 안에서 어떻게 연결되는지 전체 흐름을 정리해 보겠습니다.
① 원시 오디오 입력
WAV 파일(또는 실시간 오디오 스트림)이 시스템에 들어옵니다. 보통 16kHz 샘플링, 16비트 양자화의 단일 채널(mono)을 가정합니다.
② VAD 적용
전체 오디오에 VAD를 적용하여, 음성이 존재하는 구간의 타임스탬프를 추출합니다.
출력: [(0.5s, 3.7s), (4.1s, 6.9s), (8.3s, 13.4s), …]
③ 음성 구간만 특징 추출
VAD가 음성으로 판정한 구간에서만 MFCC(또는 log-mel filterbank) 특징을 추출합니다. 비음성 구간은 아예 건너뜁니다.
④ 세그먼테이션
음성 구간을 일정 길이(예: 1~3초)의 짧은 세그먼트로 나눕니다. 각 세그먼트는 "한 화자가 말한 짧은 조각"으로 가정됩니다. 이 가정이 성립하려면 세그먼트가 너무 길지 않아야 합니다(화자 전환 포함 가능성 ↑).
⑤ UBM 기반 화자 표현 추출
각 세그먼트의 특징 벡터들을 UBM에 넣어 Baum-Welch 통계량을 구하고, MAP 적응 또는 i-vector 추출을 통해 해당 세그먼트의 화자 표현(embedding)을 생성합니다.
⑥ 클러스터링
세그먼트별 화자 표현들을 AHC(Agglomerative Hierarchical Clustering), Spectral Clustering, 또는 다른 클러스터링 알고리즘으로 묶어, 같은 화자의 세그먼트들을 하나의 그룹으로 모읍니다.
⑦ 최종 출력
각 세그먼트에 화자 라벨이 할당되고, 이를 시간축에 펼치면 "누가 언제 말했는가"의 최종 결과가 됩니다.
🚨 VAD 오류의 전파
이 파이프라인에서 VAD의 중요성이 한 번 더 드러납니다. VAD가 놓친 음성 구간(missed speech) 은 이후 단계에서 영영 복구할 수 없습니다. 반대로 비음성을 음성으로 잘못 판정한 구간(false alarm) 은 해당 프레임의 특징 벡터가 UBM에 넘어가 화자 표현을 오염시킵니다. 따라서 VAD의 성능은 전체 화자 분리 성능의 상한(upper bound)을 결정짓는 요인 중 하나입니다.
11. 정리
이번 글에서 다룬 내용을 요약합니다.
| 모듈 | 역할 | 핵심 개념 |
|---|---|---|
| VAD | 음성 존재 구간 검출 | 에너지/ZCR, 통계적 우도비 검정, 뉴럴 VAD (DNN/LSTM/Transformer), 후처리 (미디언 필터, 최소 길이 제약) |
| UBM | 화자 독립적 배경 음향 모델 | GMM, EM 알고리즘, MAP 적응, Supervector, i-vector, Baum-Welch 통계량 |
VAD는 화자 분리의 첫 관문으로, 이후 모든 단계에 넘겨줄 데이터의 순도를 결정합니다. 단순한 에너지 임계값부터 딥러닝 모델까지 다양한 스펙트럼이 존재하며, 시스템의 요구 사항(실시간 여부, 소음 환경, 계산 자원)에 맞게 선택합니다.
UBM은 "모든 화자의 평균적 목소리"를 모델링한 GMM으로, 개별 화자의 특성을 추출하기 위한 기준점입니다. MAP 적응을 통해 소량의 데이터로도 화자별 모델을 안정적으로 구축할 수 있으며, 이를 확장한 i-vector는 화자 표현의 표준으로 오랫동안 자리잡았습니다.
다음 파트에서는 이 i-vector 위에서 화자를 군집화하는 클러스터링 기법과, 딥러닝 기반 화자 임베딩(d-vector, x-vector)에 대해 다루겠습니다.
