
Abstract
chit-chat model의 문제점
- lack of specificity : 일관된 personality를 보여주지 않음
- often not very captivating
⇒ chit-chat model에 profile information을 conditioning함으로써 해결
- 주어진 프로필 정보 조건에 맞는 (=condition on their given profile information)
- 이야기하고 있는 대상에 대한 정보를 포함하는 (=information about the person they are talking to)
위 두가지와 관련된 데이터를 수집하여 모델을 학습시킴으로써 다음 utterance 예측을 통해 측정되는 dialogue 생성 능력 향상을 이루고자 함.
그중에서도 2번의 경우 처음에는 알 수 없는 정보이기때문에, 모델은 상대가 개인적인 주제를 이야기 하도록 학습되고, 그 결과인 dialogue는 interlocutor의 프로필 정보를 예측하는데 사용될 수 있다.
1. Introduction
현재 : Neural model들이 chit-chat에 있어 적절히 유의미한 대답을 생성하기 위한 데이터 셋이 구축된지 얼마 되지 않았고, 여전히 그러한 모델들의 약점이 뚜렷함
chit-chat model이 갖고있는 문제점
- lack of consistent personality : 각각 다른 speaker가 이야기한 dialogue를 바탕으로 학습되기 때문
- lack of explicit long-term memory : 최근 dialogue history 만으로 utterance를 생성
- tendency to produce non-specific answers like “I don’t know”
→ 위 세개의 문제들로 인해 대화하는 사람의 전반적인 만족도가 크게 떨어지게 됨
→ 저자는 이러한 문제가 general chit-chat 모델을 위한 public dataset의 부족때문이라고 주장
최근의 대화모델의 낮은 퀄리티와 이러한 모델을 평가하는데 있어 발생하는 어려움 때문에, chit-chat model << task-oriented communication
btw, 사람간 대화의 대부분은 socialization, personal interests 그리고 chit-chat에 집중되어있다.
⇒ configurable, persistent persona를 도입함으로써 더 engaging한 chit-chat dialogue agent를 만들 수 있을 것.
이때, 이러한 persona는 textual descrpition과 profile에서 encoded된 것들
- profile은 memory-augmented NN에 저장되어 persona free model보다 더 personal, specific, consistent, engaging한 답변을 생성할 수 있음 → chit-chat model의 문제 완화
- 마찬가지로, 대화 상대에 대한 정보도 같은 방식으로 활용할 수 있음
⇒ Model은 personal topic에 대한 ask와 answer question모두를 활용해 학습되고, 이는 대화 상대의 persona를 modeling할 수 있도록 함
그러한 모델을 학습시키기 위해, persona-chat dataset을 제시
- a new dialogue dataset consisting of 164,356 utterances between crowdworkers
- each asked to act the part of a given provided persona
- get to know each other during the conversation
Next utterance prediction task during dialogue
→ compare generative & ranking model
- Seq2Seq
- Memory Networks
⇒ generative & ranking model 모두에 있어 persona info가 주어진 모델이 task를 더 잘 수행함
2. Related works
-
Traditional dialogue systems
- dialogue state tracking component와 response genrator로 구성
- user intent가 명확히 정의된 goal-oriented dialogue
- chit-chat setting은 고려되지 않음
- functional goal 달성에 집중
- 이에 따라 task와 dataset도 좁은 domain에 집중됨
- IR base models : 최근 대화 기록으로 response를 matching score기반 retrieve and rank
-
End-to-end neural approach
-
generative recurrent system (ex. seq2seq)
- Sequence to sequence learning with neural networks
- A Neural Conversational Model
- A hierarchical latent variable encoder-decoder model for generating dialogues
- +) produce syntactically coherent novel responses
- -) memory-free → longterm coherence, persistent personality 부족
-
memory-augmented network
-
chit-chat setting
- A persona-based neural conversation model
- Twitter corpus에서 capture한 background history와 speaking styler과 같은 persona를 distributed embedding으로 encapsulate하여 향상된 결과 생성
- 대화 상대를 getting to know하는 과정이 없음⇒ explicit profile information에 집중, getting to know과정 추가
-
3. The PERSONA-CHAT Dataset
Goal
- Facilitate more engaging and more personal chit-chat dialogue
Data collection stages
- Persona
- 1155 Possible persona
- 각각은 최소 5개의 profile sentence를 포함
- 100 never seen before peronas for validation, the other 100 for test
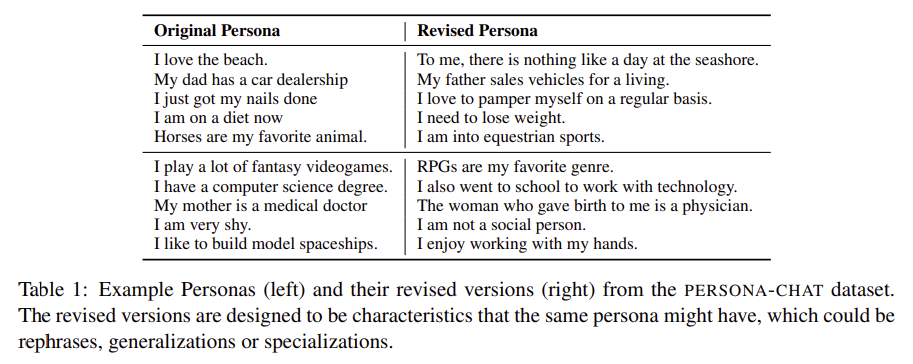
- Revised Persona
- trivial word overlap으로 인해 model이 advantage를 챙기는 것을 방지하기 위해, 1155개의 persona에 대해 rephrases, generalizations or specializations처리된 관련 문장을 크라우드소싱하여 얻음
- Persona chat
- 164,356 utterances over 10,981 dialogs, 15,705 utterances (968 dialogs) of which are set aside for validation, and 15,119 utterances (1000dialogs) for test
3.1 Personas
- persona description 5문장을 활용해 crowdsourced worker들이 character를 만들어 냄.
Example.
“I am a vegetarian. I like swimming. My father used to work for Ford. My favorite band is Maroon5. I got a new job last month, which is about advertising design.”
→ 이러한 프로필은 사람간 대화에 있어 나올 수 있는 전형적인 관심사를 자연스럽게 묘사하는데 초점을 둠
- 각 문장들이 최대 15단어 정도인 짧은 문장으로 구성
3.2 Revised Personas
Issue of textual persona :
- 프로필 정보를 unwittingly 반복하게 되어 엄청난 단어 중복이 발생할 수 있음
→ 이로 인해 모델이 단어 중복 만으로 답을 맞추는 상황이 발생
- 잘 알려진 QA데이터셋인 SQuAD의 경우, 단순한 단어 overlap만으로 맞출 수 있는 케이스가 다수 있음
해결 :
- 기존의 프로필 문장을 재작성 및 재구성 하도록
- “a related characteristic that the same person may have” : 같은 것을 의미하는 것 뿐 아니라 같은 persona가 두가지 특징을 모두 포함 할 수 있음
- generalizations or specializations
- ex. “I like basketball” → “I am a big fan of Michael Jordan”
- Not just trivially rephrase the sentence by copying the original word
- ex. “My father worked for Ford.”
- “My dad was employed by Ford.” (X)
- “My dad worked in the car industry” (O)
- ex. “My father worked for Ford.”
3.3 Persona Chat
- 수집한 persona를 crowdworkers에게 랜덤하게 부여한 후, getting to know 과정의 대화를 하도록 함.
- turn base
- max 15 words per message
- 페르소나 프로필 내용을 조금만 변형하여 발화하지 않도록 지시
- Minimum dialogue length : 6~8 turns
Evaluation
Standard dialogue task
- given the dialogue history, predict the next utterance
- with/ without profile information
Goal :
- enabling intersting directions for future research (persona를 도입함으로써 the engaging한 대화가 만들어지는지
Possible Scenarios
conditioning on
- No persona
- Your own persona
- Their persona
- Both
- original, revised ver.모두
Metrics
-
log likelihood of the correct sequence, measured via perplexity
-
F1 score
-
next utterance classification loss
: N개(N=19)의 random distractor(오답)와 정답들 사이에서 정답을 고를경우 1점을 부여하는 방식
4. Models
Next utterance prediction을 수행하기 위한 두가지 class의 모델
- ranking model : training set의 가능한 답변 후보들을 생성하고, 각 reply에 순위를 매김
- generative model : dialogue history와 persona에 따라 word-by-word로 novel sentence를 생성해냄
- 특정 후보 생성 확률을 계산하고 해당 점수로 후보 순위를 매긴다는 점에서 ranking model과 유사하게 평가할 수 있음
4.1 Baseline ranking models
- IR baseline - 다양한 variant가 있지만, 가장 단순한 것으로 적용
- training set에서 가장 유사한 메세지를 찾고, 해당 exchange에서 그 응답을 output.
- 여기서 유사도는 tf-idf weighted cosine similarity between the bags
of words로 측정됨
- Starspace( = supervised embedding model)
- IR
- margin ranking loss와 k-negative sampling을 사용해 해당 작업에 대한 임베딩을 직접 최적화하여 dialog와 next utterance의 유사성 학습
- (dialogue+persona)와 next utterance사이 유사도를 단어 임베딩의 합 벡터의 cosine similarity( = )를 이용해 측정 후, 제일 유사한 utterance를 선택 → : query, : candidate
- : dictionary of word embeddings, x matrix, indexes ith word(row)
- , 를 임베딩하는 d-dimenional embedding
- profile을 포함하기 위해 query vector bag of word에 단순 concatenate
4.2 Ranking Profile Memory Network
두가지 이전 모델들 모두 profile info를 dialogue history와 합쳐 사용
→ model이 다음 utterance를 결정하는데 있어 두가지를 구분하지 못함
- Dialogue history를 inqut query로 입력하는 memory network를 사용하고, 각 profile sentence에 대한 attention을 학습
- 유사도 : input q와 profile sentence
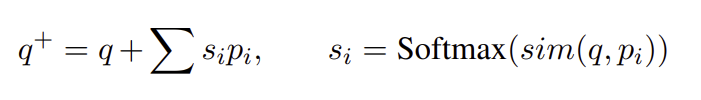
- candidates와 의 유사도 기반 랭킹
4.3 Key-Value Profile Memory Network
- improvement to the memory network by performing attention over keys and outputting the values
- Dialogue history를 keys, next dialogue utterance(=reply of speaking partner)를 value로 하는 메모리 네트워크 → 모델이 past dialogue에 대한 memory를 갖고, 직접적으로 prediction에 사용할 수 있게됨
- Ranking profile Memory network에서 구해진 를 이용해 각 key에 대한 attention값을 구하고, value의 가중합을 만들어 새로운 query embedding q^++를 만들어냄
- q^++는 candidate 들을 유사도 기반 ranking했던 거처럼 마찬가지로 ranking하는데 사용
- 매우 큰 key-value쌍은 학습을 매우 느리게 만들 수 있어, 실험에서는 profile memory network를 학습시키고 같은 모델의 가중치를 활용해 test시 적용하였음
4.4 Seq2Seq
- LSTM encoder, decoder를 갖는 단순 deq2seq
- 각 timestep t에 대해 decoder는 word j의 발생 확률을 softmax로 구함
- negative log likelihood
- GloVe word embedding
- persona는 input sequence에 concat해 입력
4.5 Generative Profile Memory Network
- 각 profile이 memory network의 individual memory representation으로
- seq2seq 모델에서 decoding할때 각 step에서 memory(=profile sentences)에 attend하여 persona context vector를 생성하고, 이 벡터를 추가로 입력
5. Experiments
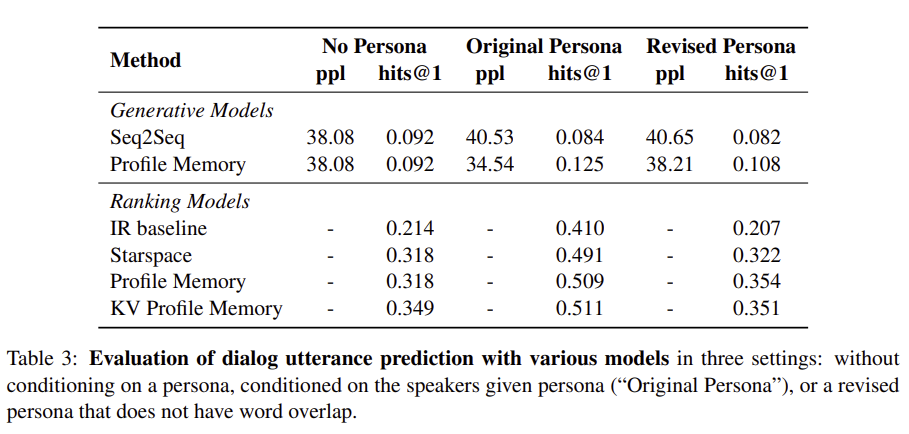
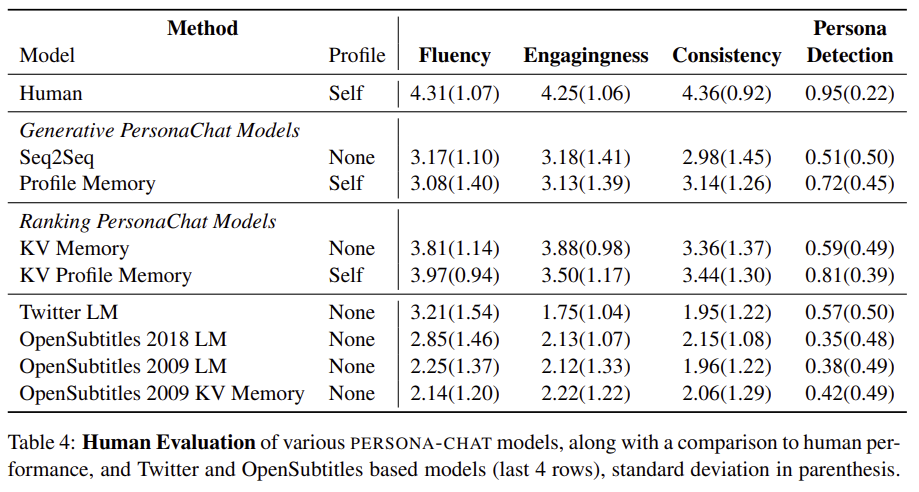
- persona정보를 이용했을떄 더 좋은 성능을 보임
- original 보다 revised ver.이 더 도전적인 데이터셋
- hits@1에 의한 성능비교시 Ranking model이 generation model보다 좋은 성능을 보임
- 사람이 직접 scoring했을 때에도 ranking model이 generation model보다 좋은 성능을 보임
