k-최근접 이웃 회귀
회귀
- 두 변수 사이의 상관관계를 분석하는 방법.
- 임의의 어떤 숫자를 예측하는 문제.
k-최근접 이웃 회귀
예측하려는 샘플에 가장 가까운 샘플 k개를 선택.
이웃한 샘플의 타깃은 어떤 클래스가 아니라 임의의 수치(분류일 때는 클래스)
이웃 샘플의 수치를 평균내어 새로운 샘플의 예측 타깃값 도출.
마무리
키워드
- 회귀: 임의의 수치를 예측하는 문제. 타깃값도 임의의 수치가 된다.
- k-최근접 이웃 회귀: k-최근접 이웃 알고리즘을 사용해 회귀 문제를 푼다. 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃값을 평균하여 예측으로 삼는다.
- 결정계수(): 대표적인 회귀 문제의 성능 측정 도구. 1에 가까울수록 좋고, 0에 가깝다면 성능이 나쁜 모델이다.
- 과대적합: 모델의 훈련 세트 성능이 테스트 세트 성능보다 훨씬 높을 때. 모델이 훈련 세트에 너무 집착해서 데이터에 내재된 거시적인 패턴을 감지하지 못한다.
- 과소적합: 훈련 세트와 테스트 세트 성능이 모두 동일하게 낮거나 테스트 세트 성능이 오히려 더 높을 때. 더 복잡한 모델을 사용해 훈련 세트에 잘 맞는 모델을 만들어야 한다.
핵심 패키지와 함수
KNeighborsRegressor: k-최근접 이웃 회귀 모델을 만드는 사이킷런 클래스. n_neighbors 매개변수로 이웃의 개수를 지정. 기본값은 5
mean_absolute_error(): 회귀 모델의 평균 절댓값 오차를 계산. 첫 번째 매개변수는 타깃, 두번째 매개변수는 예측값을 전달.
비슷한 함수 mean_squared_error()
확인문제
- k-최근접 이웃 회귀에서는 새로운 샘플에 대한 예측을 어떻게 만드나요?
->이웃 샘플의 타깃값의 평균
기본 미션🔥
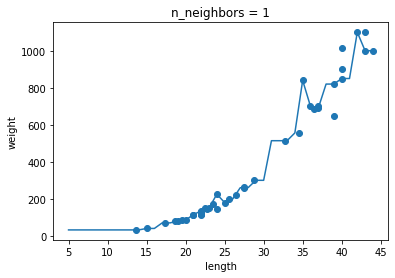
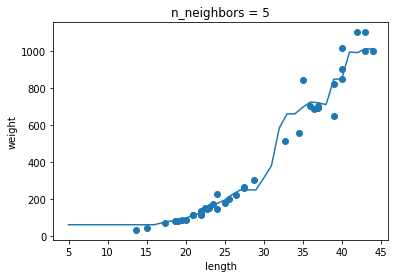
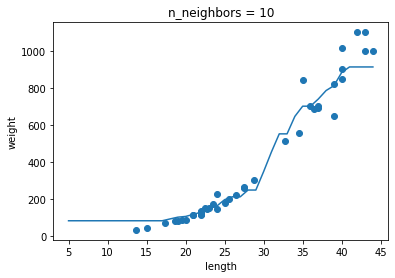
- 과대적합과 과소적합에 대한 이해를 돕기 위해 복잡한 모델과 단순한 모델을 만들겠습니다. 앞서 만든 k-최근접 이웃 회귀 모델의 k값을 1, 5, 10으로 바꿔가며 훈련해보세요. 그다음 농어의 길이를 5에서 45까지 바꿔가며 예측을 만들어 그래프로 나타내보세요. n이 커짐에 따라 모델이 단순해지는 것을 볼 수 있나요?