06-1 군집 알고리즘
비지도 학습
- 타겟이 없을 때 사용하는 머신러닝 알고리즘
마무리
키워드
- 비지도 학습
머신러닝의 한 종류로 훈련 데이터에 타깃이 없다.
타깃이 없기 때문에 외부의 도움 없이 스스로 유용한 무언가를 학습해야 함.
대표적인 비지도 학습: 군집, 차원 축소 - 히스토그램
구간별로 값이 발생한 빈도를 그래프로 표시한 것
보통 x축의 값이 구간(계급)이고, y축은 발생 빈도(도수) - 군집
비슷한 샘플끼리 하나의 그룹을 모으는 대표적인 비지도 학습 작업
군집알고리즘으로 모은 샘플 그룹을 클러스터라고 부른다.
확인 문제
- 히스토그램을 그릴 수 있는 맷플롯립 함수는?
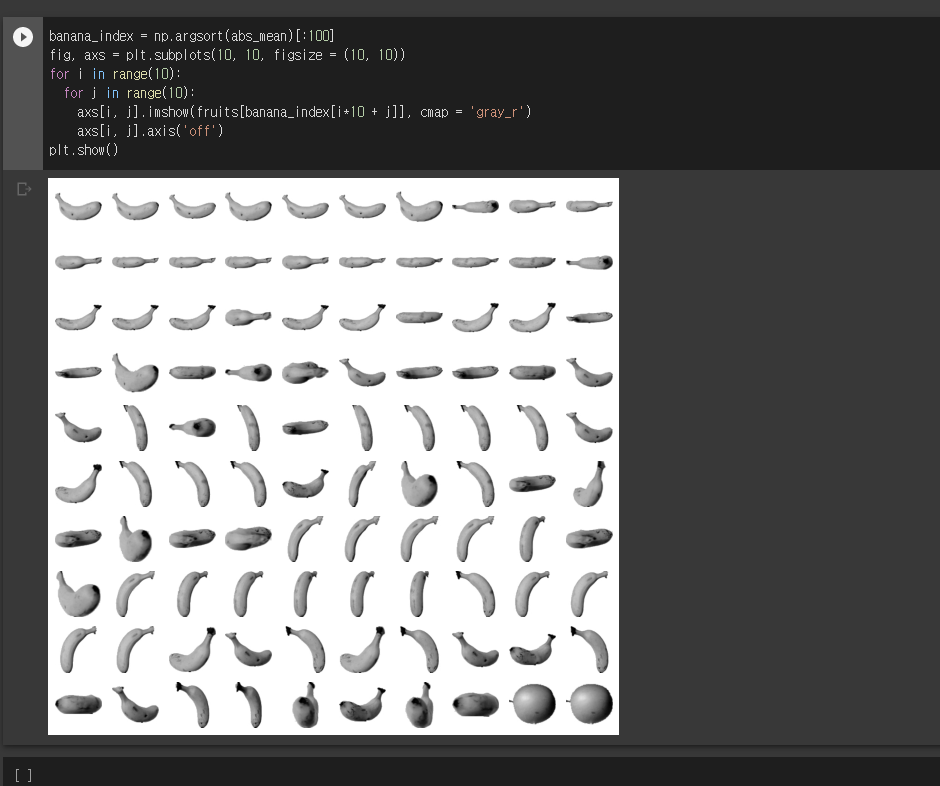
hist() - 바나나 사진 100장 출력하기
06-2 k-평균
k-평균 군집 알고리즘
- 비지도학습에서 평균값을 구할 수 있는 방법
- 클러스터 중심
- 센트로이드
k-평균 알고리즘 소개
- 무작위로 k개의 클러스터 중심을 정한다.
- 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
- 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
- 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복한다.
-> 처음에는 랜덤하게 클러스터 중심을 선택하고 점차 가까운 샘플의 중심으로 이동하는 비교적 간단한 알고리즘
마무리
키워드
- k평균 알고리즘
처음에 랜덤하게 클러스터 중심을 정하고 클러스터를 만든다.
그 다음 클러스터의 중심을 이동하고 다시 클러스터를 만든다.
반복해서 최적의 클러스터를 구성한다. - 클러스터 중심
k-평균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값
= 센터로이드
가장 가까운 클러스터 중심을 샘플의 또 다른 특성으로 사용하거나 새로운 샘플에 대한 예측으로 활용할 수 있다. - 엘보우 방법
최적의 클러스터 개수를 정하는 방법 중 하나.
이니셔: 클러스터 중심과 샘플 사이 거리의 제곱 합.
클러스터 개수에 따라 이너셔 감소가 꺾이는 지점이 적절한 클러스터 개수 k가 된다.
그래프의 모양이 엘보우 같아서 엘보우 방법
핵심 패키지와 함수
scikit-learn
Kmeans- n_cluster : 클러스터 개수, 기본값은 8
- n_init : 반복회수
- max_iter : 한 번 실행에서 최적의 센트로이드를 찾기 위해 반복할 수 있는 최대 횟수. 기본값은 200
확인문제
-
k-평균 알고리즘에서 클러스터를 표현하는 방법이 아닌 것은?
4번 클러스터에 속한 샘플 개수 -
k-평균에서 최적의 클러스터 개수는 어떻게 정할 수 있나요?
1번 엘보우 방법을 사용해 이너셔의 감소 정도가 꺾이는 클러스터의 개수를 찾습니다.
4주차부터 약간 미션 해내는 것에 의의를 두고 있는 것 같다. 뒤로 갈수록 내용이 어려워지는데 더 시간 투자를 하지 않으니까 코드치면서 이해안되는 부분이 있어도, 이해하고 넘어가는게 아니라 일단 넘어가는 식ㅜㅜ
그래도 이해를 못하고 넘어가더라도 남는 부분은 있으니까 중단하지 말고 끝까지 마무리 해보쟈!
그리고... 꼭 시간내서 다시 보기..!
