Chaper 01-2 확인 문제
- 구글에서 제공하는 웹 브라우저 기반의 파이썬 실행환경은?
코랩 - 코랩 노트북에서 쓸 수 있는 마크다운 중 기울임 꼴로 쓰는 것은?
혼공머신
혼공머신
: 글자 양 쪽에 _(언더바) 또는 * - 코랩 노트북은 어디에서 실행되나요?
구글 클라우드~
기본 미션 - 코랩 실습 화면 캡쳐 하기
마무리
키워드로 끝내는 핵심 포인트
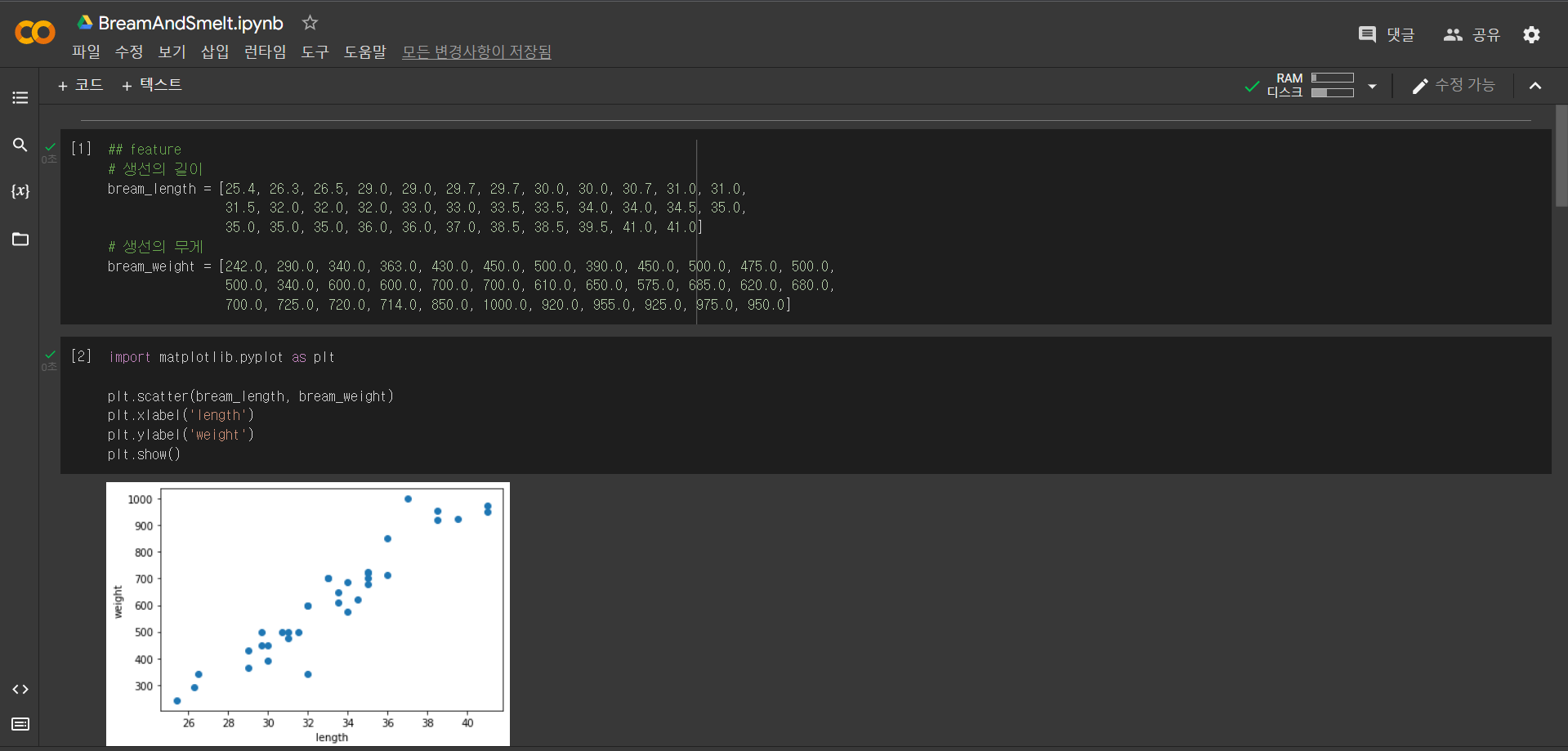
- 특성: 데이터를 표현하는 하나의 성질 (생선 데이터 길이와 무게의 특성)
- 훈련: 머신러닝 알고리즘에서 규칙을 찾는 과정 (
fit()메서드가 하는 역할) k-최근접 이웃 알고리즘: 가장 간단한 머신러닝 알고리즘 중 하나. 어떤 규칙을 찾기보다는 전체 데이터를 메모리에 가지고 있는 것이 전부.- 모델: 머신러닝 프로그램에서 알고리즘이 구현된 객체 / 알고리즘 자체
- 정확도: 정확한 답을 몇 개 맞혔는지를 백분율로 나타낸 값. 사이킷런에서는 0~1사이의 값으로 출력
정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)핵심 패키지와 함수
matplotlib
scatter(): 산점도를 그리는 맷플롯립 함수.
처음 2개의 매개변수로 x축 값과 y축 값을 전달. 이 값은 파이썬 리스트 또는 넘파이 배열.
c매개변수로 색깔 지정.
marker매개변수로 마커 스타일 지정
sckit-learn
-
KNeighborsClassifier(): k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스.
n_neighbors매개변수로 이웃의 개수 지정. 기본값은 5.
p매개변수로 거리를 재는 방법 지정. 1일 경우 맨해튼 거리, 2일 경우 유클리디안 거리. 기본값은 2.
n_jobs매개변수로 사용할 CPU 코어 지정. -1로 설정하면 모든 CPU 코어를 사용. 이웃 간의 거리 계산 속도를 높일 수 있지만fit()메서드에는 영향 없다. 기본값은 1 -
fit(): 사이킷런 모델을 훈련할 때 사용하는 메서드.
처음 2개의 매개변수로 훈련에 사용할 특성과 정답 데이터를 전달 -
predict(): 사이킷런 모델을 훈련하고 예측할 때 사용하는 메서드.
특성데이터 하나만 매개변수로 받는다. -
score(): 훈련된 사이킷런 모델의 성능을 측정.
처음 2개의 매개변수로 특성과 정답 데이터를 전달.
먼저predict()메서드로 예측을 수행한 다음 분류 모델일 경우 정답과 비교하여 올바르게 예측한 개수의 비율을 반환
확인 문제
- 데이터를 표현하는 하나의 성질
특성 - 가장 가까운 이웃을 참고하여 정답을 예측하는 알고리즘이 구현된 사이킷런 클래스는
KNeighborsClassifier - 사이킷런 모델을 훈련할 때 사용하는 메서드는
fit() - 본문에서 n_neighbors를 49로 설정했을 때 점수가 1.0보다 작았다. 즉 정확도가 1000%가 아니다. n_neighbors의 기본값인 5부터 49까지 바꾸어 가며 점수가 1.0아래로 내려가기 시작하는 이웃의 개수를 찾아보자.
### 확인문제 4번 (책 코드)
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
for n in range(5, 50):
# k-최근접 이웃 개수 설정
kn.n_neighbors = n
# 점수 계산
score = kn.score(fish_data, fish_target)
# 100% 정확도에 미치지 못하는 이웃 개수 출력
if score < 1:
print(n, score)
break02-1 마무리
키워드로 끝내는 핵심 포인트
- 지도 학습: 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측
- 비지도 학습: 타깃 데이터가 없다. 무엇을 예측하는 것이 아니라 입력 데이터에서 어떤 특징을 찾는 데 주로 활용
- 훈련 세트: 모델을 훈련할 때 사용하는 데이터. 보통 훈련 세트는 클수록 좋다.
- 테스트 세트: 전체 데이터에서 20~30%를 테스트 세트로 사용. 전체 데이터가 아주 크다면 1%만 덜어내도 충분.
핵심 패키지와 함수
numpy
seed(): 넘파이에서 난수를 생성하기 위한 정수 초깃값을 지정. 초깃값이 같으면 동일한 난수를 뽑을 수 있다.arange(): 일정한 간격의 정수 또는 실수 배열을 만든다.
기본 간격은 1.
매개변수가 하나이면 종료 숫자를 의미. 0~종료숫자. 종료숫자는 배열에 포함되지 않는다.
매개변수가 두개이면 시작숫자~종료숫자를 의미.
매개변수가 3개이면 마지막 매개변수는 간격을 의미.shuffle(): 주어진 배열을 랜덤하게 섞는다.
다차원 배열일 경우 첫번째 축(행)에 대해서만 섞는다.
선택 미션 - Ch.02(02-1) 확인문제 풀고 풀이과정 정리하기
확인 문제
- 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은?
지도 학습 - 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상은?
샘플링 편향 - 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
행: 샘플, 열: 특성
