[ 논문리뷰 ] Object-Aware Query Perturbation for Cross-Modal Image-Text Retrieval
2024, Sogi et al.
https://github.com/NEC-N-SOGI/query-perturbation
1. 선행연구의 동향 및 한계
동향
- Vision-and-Language(V&L) 모델은 이미지와 텍스트의 관계를 학습하며 BLIP2, COCA, InternVL과 같은 최신 모델은 zero-shot 학습과 일반화 성능에서 우수한 성능을 보임.
- Cross-modal image-text retrieval에서는 transformer 기반 cross-attention 구조를 사용해 텍스트와 이미지의 정렬(alignment)을 강화.
한계
- 기존 V&L 모델은 작은 객체(small objects)에 대한 텍스트-이미지 정렬이 부정확해 검색 성능이 저하됨.
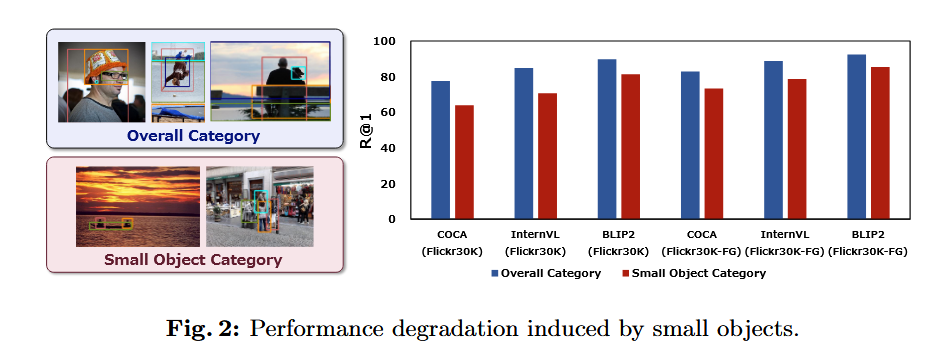
2. 연구 필요성 및 차별성
연구 필요성
- 기존 V&L 모델의 작은 객체 처리 한계를 극복하기 위해, 인간 인지(human cognition)의 object-centric 특성을 반영한 새로운 프레임워크 필요.
- 작은 객체를 보다 정확히 검색함으로써, 실제 응용에서의 활용도를 높여야 함.
차별성
- "Object-Aware Query Perturbation(Q-Perturbation)" 프레임워크를 제안:
- 작은 객체 중심 성능 향상: 작은 객체 정보를 강조해 검색 정확도 개선.
- 기존 모델의 강점 유지: fine-tuning 없이 적용 가능.
- 다양한 모델에 범용적 적용: BLIP2, COCA, InternVL 등 최신 모델과 호환.
3. 연구 질문
- 작은 객체 정보를 효과적으로 검색하기 위해 V&L 모델에 어떤 개선이 필요할까?
- Q-Perturbation이 BLIP2, COCA, InternVL 등 최신 V&L 모델에 어떻게 적용되며, 어떤 성능 향상을 제공할까?
4. 사용 이론
PCA 기반 Subspace Theory
- Principal Component Analysis(PCA)를 사용해 이미지 내 객체의 주요 정보를 담고 있는 K-subspace를 생성.
- 객체 탐지를 통해 얻어진 bounding box 영역에서 핵심 토큰만 추출한 뒤, 이를 PCA로 분석해 객체의 주요 정보만을 반영.
- 생성된 K-subspace는 해당 객체의 핵심 정보(essential information)를 표현하며, 이를 쿼리와 결합해 검색 성능을 강화.
Query Decomposition and Reconstruction
- 쿼리(query)를 K-subspace(객체 정보 성분)와 Complementary Subspace(나머지 성분)로 분해.
- 객체 정보 성분:
q∥i = ΦΦT qi - 나머지 성분:
q⊥i = (I − ΦΦT)qi
- 객체 정보 성분:
- 쿼리를 분해한 뒤, 객체 정보 성분만 강조(perturb)하여 새로운 쿼리
qˆi를 생성:- 공식:
qˆi = qi + αq∥i - 여기서
α는 강화 정도를 조절하는 파라미터.
- 공식:
- 이 과정을 통해 작은 객체와 관련된 정보를 효과적으로 강화하며 검색 성능을 향상.
5. 연구 방법
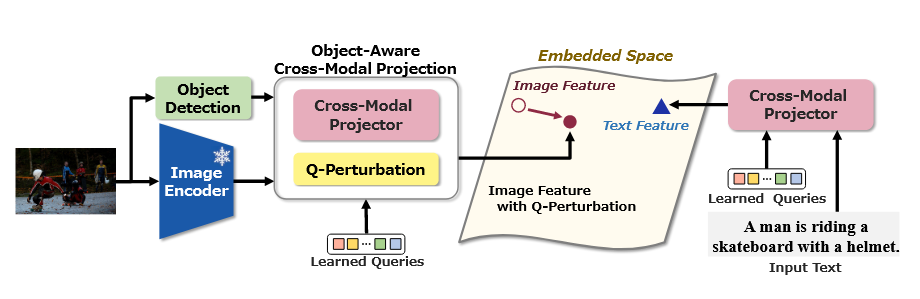
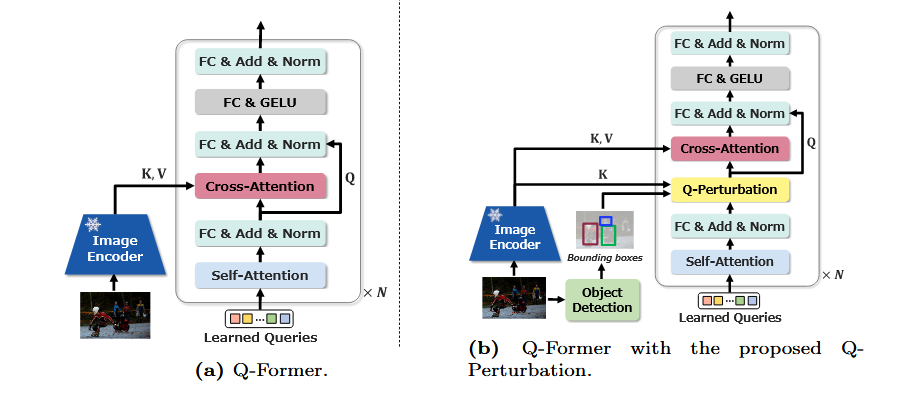
(a) 기존 Q-Former는 Cross-Attention을 통해 이미지 특징(K, V)과 쿼리(Q)를 연결하며 텍스트-이미지 정렬을 수행함.
(b) 개선된 Q-Former는 Q-Perturbation 모듈을 추가하여 Object Detection-Bounding box에서 얻은 객체 정보를 활용, 쿼리를 객체 중심으로 보정( Learned queries에 힌트 주기 )한 후 Cross-Attention에 전달하여 작은 객체나 중요한 디테일을 강화함.
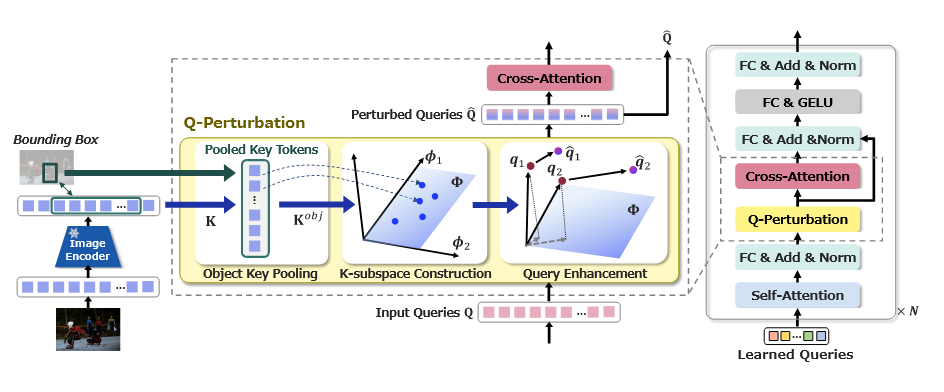
Q-Perturbation 모듈 설계
- Object Key Pooling
- 객체 탐지(bounding box)를 통해 각 객체의 이미지를 대표하는 토큰을 추출.
- ROI pooling 방식으로 수행되며, 라는 객체 이미지 토큰 세트 생성.
- K-Subspace Construction
- PCA를 사용해 각 객체에 대해 K-subspace를 생성.
- 해당 subspace는 객체의 핵심 정보를 표현.
- Query Enhancement
- 쿼리
qi를 두 가지 성분으로 분해:q∥i: 객체와 관련된 성분 (K-subspace에 투영).q⊥i: 객체와 무관한 나머지 성분.
- 최종적으로 쿼리
qi에 객체 성분을 강조해 강화된 쿼리qˆi생성:
- 공식:qˆi = qi + αq∥i
- 쿼리
다중 객체 확장 (Extension to Multiple Objects)
- 각 객체에 대해 K-subspace 생성(Φb).
- 모든 객체 정보를 반영해 최종 쿼리 강화:
- 공식:
qˆi = qi + α Σb w(Sb) q∥i,b - w(Sb)는 객체 크기를 고려한 중요도 가중치.
- 작은 객체도 중요도를 부여하여 균형 잡힌 성능 제공.
- 공식:
실험 설계
- 데이터셋
- Flickr-30K, MSCOCO, Flickr-FG, COCO-FG 사용.
- 평가 메트릭
- Recall@K (R@K): 검색 상위 K개 중 정답 비율.
- mean Recall@K (mR@K): 객체 크기에 따른 성능을 조화평균으로 평가.
- 적용 모델
- BLIP2, COCA, InternVL 등 최신 V&L 모델.
6. 연구 핵심
Object-Aware Query Perturbation의 역할
- 작은 객체 정보를 강조함으로써 기존 모델의 검색 성능을 크게 향상.
- Cross-attention 구조에 최소한의 변경만으로 효과적인 성능 개선.
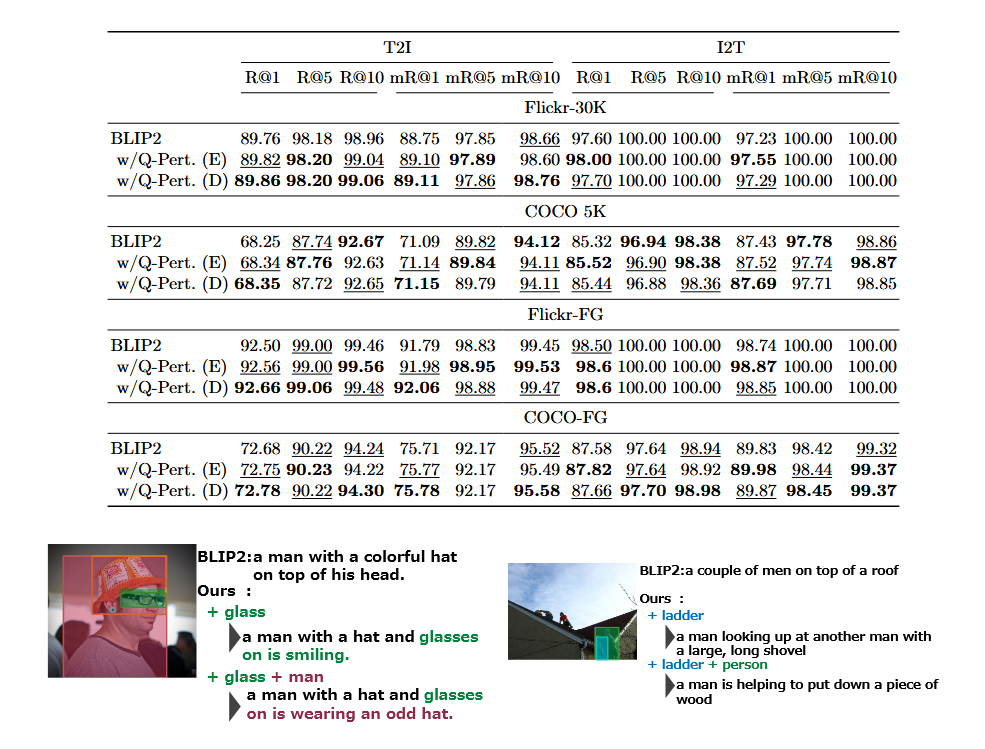
주요 결과
-
작은 객체 검색 성능 대폭 향상
- 기존 BLIP2, COCA, InternVL 모델이 간과했던 작은 객체 정보를 효과적으로 활용.
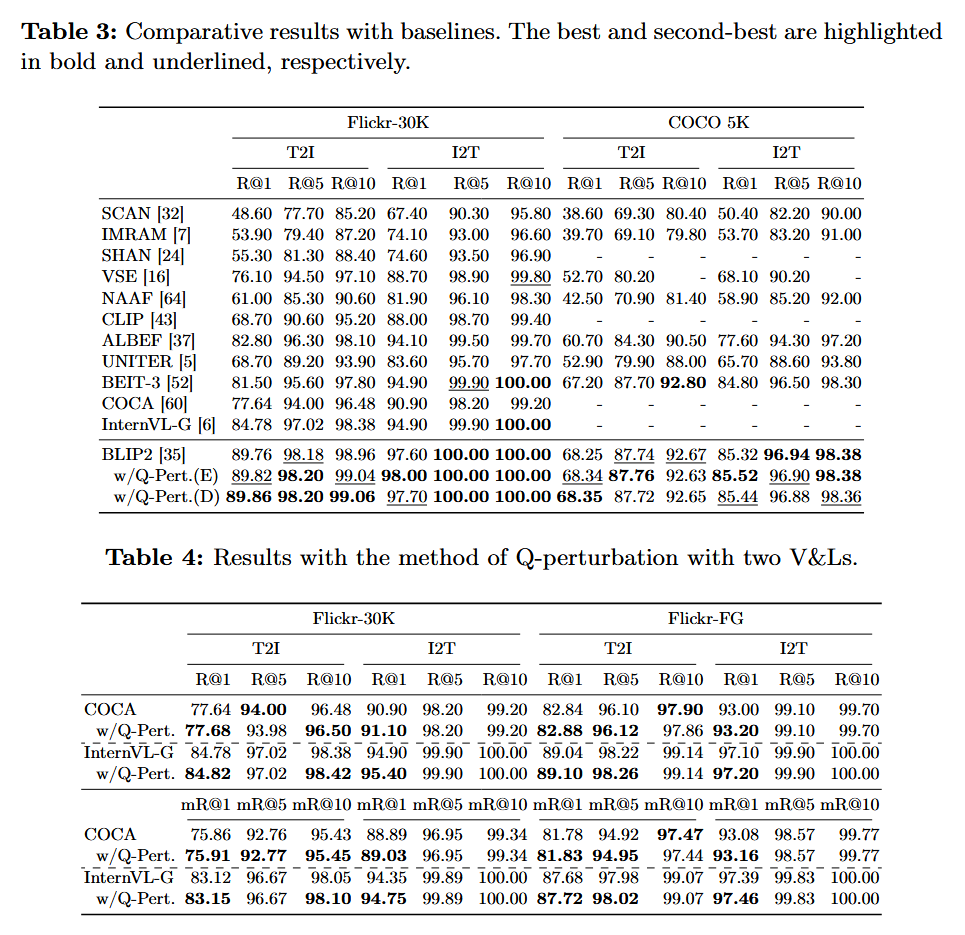
- Flickr-30K와 같은 데이터셋에서 mR@K 성능 대폭 향상.
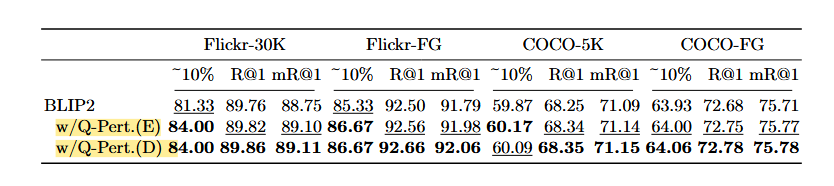
-
다양한 V&L 모델과의 결합
- COCA에서는 Image Encoder와 Cross-Attention 사이에 적용되어 쿼리를 객체 중심으로 보정해 Cross-Attention 단계에서 더 정확한 text-image 매칭을 지원.
- InternVL에서는 Image Encoder 이후( 이미지 특징을 객체 중심으로 보정 )와 QLLaMA로 넘어가는 단계( 객체 중심 쿼리를 다시 업데이트해 텍스트 생성 디테일 강화 )에서 두 번 적용.
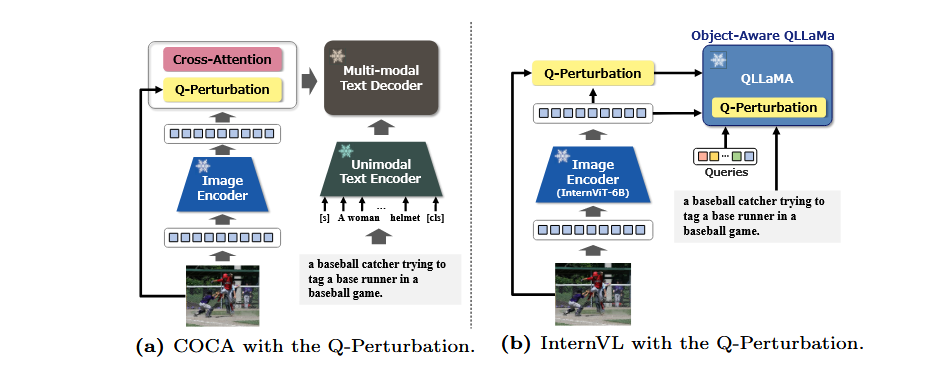
7. 연구 의의 및 한계
의의
- 작은 객체 인식 강화
- 기존 V&L 모델이 놓쳤던 작은 객체의 정보를 효과적으로 학습하고 활용.
- 범용성 및 확장 가능성
- BLIP2, COCA, InternVL 등 다양한 모델에 손쉽게 적용 가능.
- 추가 학습 없이 성능 개선
- 기존 모델의 구조와 가중치를 변경하지 않고 성능을 강화.
한계
- 이미지 인코더 의존성
- 객체 정보가 이미지 인코더에서 손실될 경우 성능 저하 가능.
- 모든 Bounding Box 사용
- 필터링 및 세밀한 가중치 조정 필요.
- 계산량 증가
- Q-Perturbation 적용으로 추가 연산이 필요하며, 실시간 응용에서 부담이 될 수 있음.

반갑습니다!