[ 논문리뷰 ] Long-CLIP: Unlocking the Long-Text Capability of CLIP
2024, Zhang et al.
https://github.com/beichenzbc/Long-CLIP
1. 선행연구의 동향 및 한계
-
CLIP 모델의 한계:
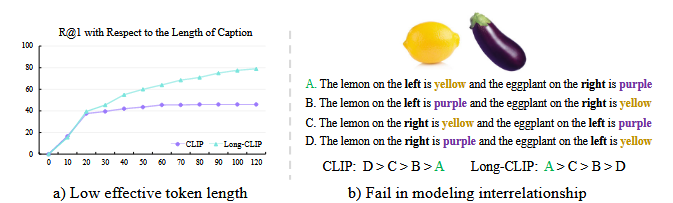
- Text token 길이가 77로 제한되며, 실제 효과적인 길이는 약 20 토큰에 불과
- Primary attributes만 학습하고, 다양한 세부 attributes는 무시하는 구조
-
기존 접근법의 한계:
- 긴 텍스트 지원을 위한 단순 positional embedding 확장 시도는 기존 short-text 성능 저하 유발
- 모든 attributes를 균등하게 학습하려다 보니 중요 정보와 비중요 정보의 구분 실패
- 추가적인 적응 비용 발생
2. 연구 필요성 및 차별성
- 필요성
- 긴 텍스트는 풍부한 정보와 속성 간 상호 관계를 담고 있어 이미지-텍스트 관계를 강화 가능
- CLIP의 한계를 극복하여 long-text capability 확보 필요
- Long-CLIP의 차별점
- CLIP 성능을 유지하며 긴 텍스트를 효과적으로 처리 가능
- Positional embedding 재구성(knowledge-preserved stretching)으로 token 길이 제한 극복
- 이미지-텍스트 정보를 정교히 align(primary component matching)

3. 연구 질문
- 기존 CLIP 모델에서 긴 텍스트를 효율적으로 처리하려면 어떻게 해야 하는가?
- 긴 텍스트의 세부 정보를 유지하면서도 short-text와의 alignment를 보장할 방법은?
- Long-CLIP이 retrieval 성능에서 실제로 개선을 가져왔는가?
4. 사용 이론
Knowledge-preserved stretching
- Lower positional embedding(20개)은 유지하고 나머지 (57개) poorly trained high embedding을 long text data로 학습시켜 interpolate
- Token 길이를 77에서 248로 확장하면서 기존 representation의 무결성 보존
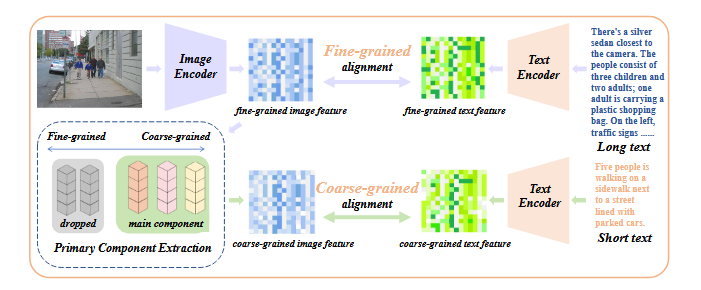
Primary component matching
- Fine-grained 및 coarse-grained features를 추출
5. 연구 방법
- Positional embedding 확장:
- Lower embedding은 보존, high embedding을 효과적으로 stretching
- Fine-tuning 전략:
- 3단계 모듈 도입
- Decomposition: 이미지를 attribute vector로 분해
- Filtration: 덜 중요한 attribute 제거
- Reconstruction: 중요 attribute를 결합하여 새로운 이미지 feature 생성
- 3단계 모듈 도입
- Urban-200 dataset 구축 및 실험: 긴 텍스트와 이미지를 연결해 성능 평가
6. 연구 핵심
- Positional embedding 재구성: 긴 텍스트를 처리하면서도 기존 short-text 성능 유지
- Primary component matching: 긴 텍스트의 detail과 short-text 핵심 요소를 동시 처리
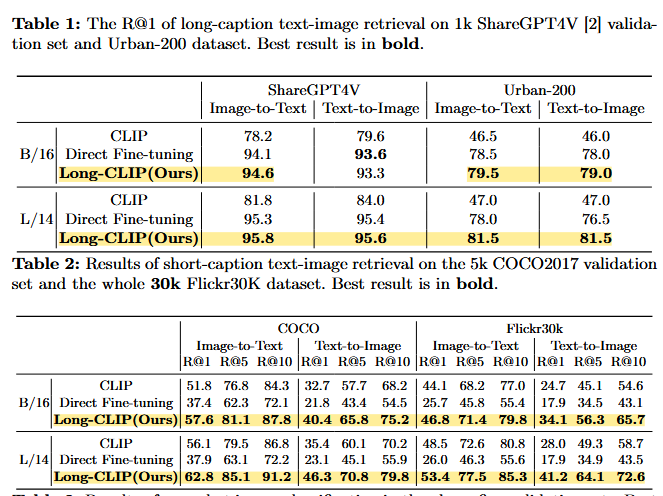
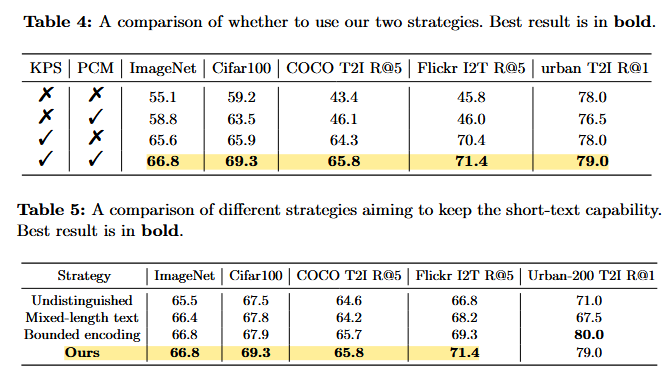
- 성능 개선 결과:
- Long caption retrieval에서 CLIP 대비 20% 성능 향상
- 일반 retrieval에서도 6% 개선
7. 연구 의의 및 한계
의의
- CLIP의 한계를 극복해 short 및 long-text 처리 능력 확보
- Paragraph-level 텍스트 생성 가능
- Retrieval 성능에서 대폭적인 개선

한계
- 여전히 token 길이 제한(248) 존재
- Long text-image pair 데이터 부족으로 scaling-up에 한계

반갑습니다!