[ 논문리뷰 ] Composing Object Relations and Attributes for Image-Text Matching
2024, Pham et al
https://github.com/vkhoi/cora_cvpr24
1. 선행연구의 동향 및 한계
Cross-attention 방식
- 이미지와 텍스트 간 관계를 학습하기 위해 대부분의 연구에서 cross-attention 메커니즘 사용함.
- Q와 K/V 가 서로 다른 데이터에서 오며, 세밀한 유사도를 계산 가능함.
- 단점 : 모든 이미지-텍스트 쌍을 비교해야 하기 때문에 계산량이 매우 크고, 대규모 데이터셋에서는 비효율적임.
Dual-encoder 방식
- 두 모달리티를 각각 독립적으로 인코딩한 뒤, joint embedding 공간에서 표현.
- 한 번 임베딩한 image를 캐시(cache)해 재사용할 수 있어 연산 효율성이 뛰어나 real-world retrieval에 적합함.
- 단점 : cross-attention 방식에 비해 정밀도가 떨어질 수 있음.
2. 연구 필요성 및 차별성
- 기존 방식( BERT, CLIP 등)은 대량의 데이터를 사용하면서도 object-attribute binding 성능이 부족, 별도의 scene graph 생성기 사용해 정확도 떨어짐.
- 본 연구는 scene graph를 활용해 object/attribute/relation semantics를 캡처하는 dual-encoder 기반의 새로운 접근법을 제안.
- Global (image-caption)과 Local (image-object entity) 레벨에서 contrastive loss로 학습된 2-step graph encoding 방식을 사용해 효과적인 학습을 수행함.
3. 연구 질문
-
Scene graph를 활용한 dual-encoder 접근법이 기존 cross-attention 방식의 성능을 능가할 수 있는가?
-
Image-text, Image-entity 간의 관계를 효율적이고 의미적으로 정렬하는 최적의 방법은 무엇인가?
4. 사용 이론
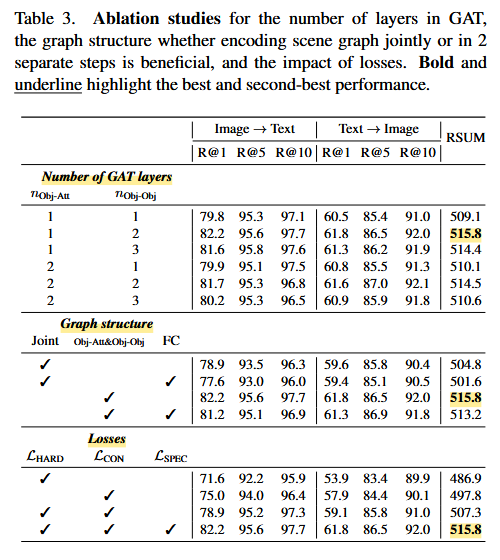
Graph Attention Network(GAT)
- Object-attribute 및 Object-object 관계 모델링에 사용함.
Contrastive Loss 및 Triplet Loss
- Image-text/entity 간 정렬 및 학습 안정성 보장함.
Specificity Loss
- Image-caption의 유사도를 Image-entity 간 유사도보다 높게 유지해 semantic alignment 강화.
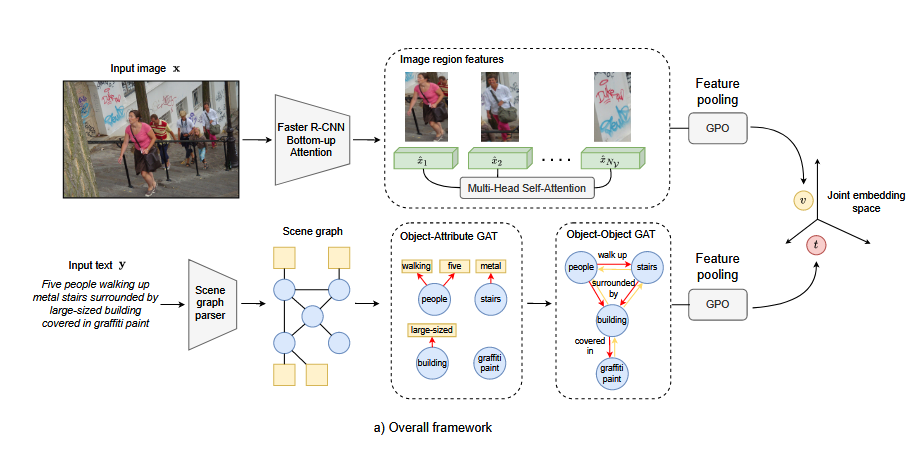
5. 연구 방법
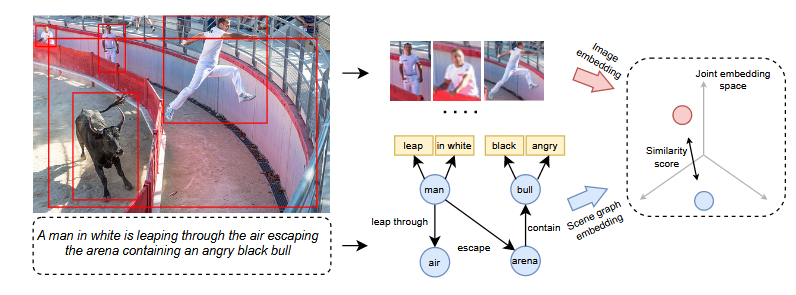
Visual feature extractor
- ResNet-101을 백본으로 하는 Faster R-CNN을 사용해 이미지에서 salient regions( top-36 )를 탐색.
- Multi-Head Self-Attention으로 contextualize하고 GPO( SOTA pooling operator ) 사용해 전체 이미지 표현 생성.
Scene graph parser & Semantic concept encoder
- Scene graph parser : 텍스트를 파싱해 object/attribute 노드를 생성하고, relation을 edge로 구성.
- Semantic concept Encoder : GloVe( get L*300 dimensional vector sequence ), Bi-GRU( get 대표 final hidden states ), BERT( after averaging all tokens' output hidden states ) 활용해 텍스트를 벡터로.
Scene Graph Embedding
Bottom-up 방식의 2단계 GAT 적용:
- Object-attribute 관계를 먼저 모델링한 뒤, object-object 관계를 모델링.
- 초기 노드 표현은 .
1단계: Object-Attribute GAT (Bottom Level)
-
목표 : Object가 연결된 attribute와의 관계를 모델링하여 semantic representation에 반영.
-
Subgraph : , 여기서 는 object와 attribute 노드, 는 object-attribute 간 edge.
-
GAT 적용 과정
-
Object 와 Attribute 간의 관계 중요도 계산:
-
중요도 정규화:
-
주변 노드 정보(Attributes) 결합해 Object 표현 업데이트:
-
-
결과
GAT 적용 결과, Object와 Attribute 관계가 반영된 새로운 Object 임베딩 생성.Object는 attribute와의 관계를 반영하여 Entity embedding으로 변환됨:
2단계: Object-Object Relation GAT (Top Level)
-
목표 : Object 간의 관계를 모델링하여 semantic contextualization 수행.
-
Subgraph : , 여기서는 object 노드, 는 object 간 relation edge.
-
GAT 적용 과정
-
Relation 정보 결합:
- 기존 연구와 달리, relation edge 를 passive entity 에만 연결해 relation의 방향성이 잘 반영된 더 명확한 semantic contextualization 가능.
-
Entity embedding 업데이트: 주변 object들과의 관계를 포함하게 됨
- Active(i): 관계에서 주체로 작용하는 경우, 사용( 자기가 주체로 작용하는 관계들)
- Passive(i): 관계에서 대상으로 작용하는 경우, 사용( 자기가 대상이 되는 관계들 )
-
-
결과
GAT 적용 결과, Object와 Object간 관계가 반영된 새로운 Object 임베딩 생성.
최종 Scene Graph Embedding 결과
- Object-attribute와 object-object 관계를 반영한 최종 scene embedding을 학습.
- 이 embedding은 object, attribute, relation 정보를 모두 포함하며 semantic representation을 강화.
Training Objectives
- Triplet Loss, Contrastive Loss, Specificity Loss 결합한 총합 손실 함수로 학습 진행.
Triplet loss with hardest negatives
- 이미지-텍스트 매칭 학습시 hardest negative sample 사용해 학습 신호 강화.
- 모든 이미지 텍스트-쌍을 대상으로 손실 계산.
- 첫번째 항: 이미지와 정답 텍스트 간 유사도 기준으로 hard negative text 찾음. 모델이 정답 텍스트 와의 유사도를 음성 텍스트보다 크게 만들도록 학습함.
- 두번째 항: 이미지와 정답 텍스트 간 유사도 기준으로 hard negative image 찾음. 모델이 정답 이미지 와의 유사도를 음성 이미지보다 크게 만들도록 학습.
Contrastive loss
- 초기 training epochs에서는 위 triplet loss 방식 결과값이 불안정함. contrastive loss 사용하면 더 안정적인 학습 가능.
- 이미지, 텍스트, 객체 엔티티 간 관계를 정렬하는 역할.
- 이미지 와 텍스트/엔티티 u간의 유사도 점수 를 높게 유지하고 u와 연관 없는 음성 텍스트/엔티티 또는 음성 이미지 와의 유사도는 낮춤.
Specificity loss
- 이미지와 캡션 간 유사도를 이미지와 엔티티 간 유사도보다 높게 유지
- 와 의 similarity가 와 모든 엔티티 {}간의 similarity 보다 크도록 해야함. 항상 caption은 entity보다 더 많은 semantic information을 담고있기 때문임.
최종 Loss
6. 연구 의의 및 한계
의의
- 기존 cross attention 방식 대비 계산 효율성이 높고 대규모 데이터셋에서도 실용적임.
- Object-Attribute 및 Object-Object 관계를 명시적으로 모델링해 기존 dual-encoder 연구를 확장.
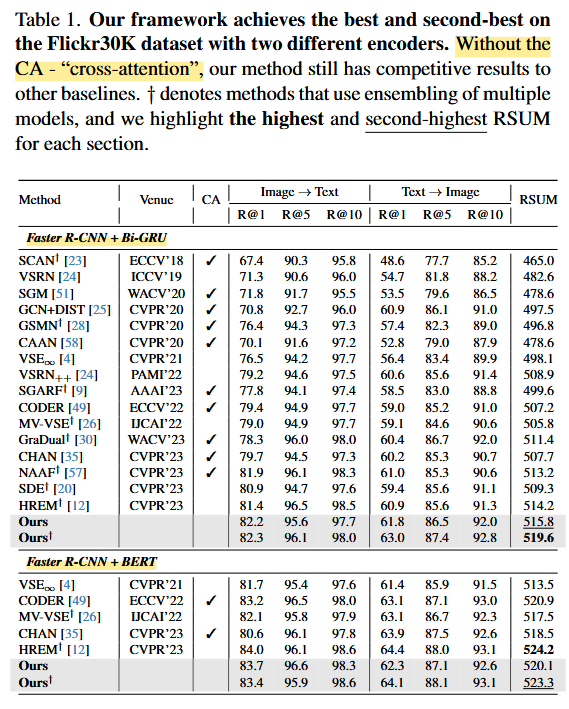
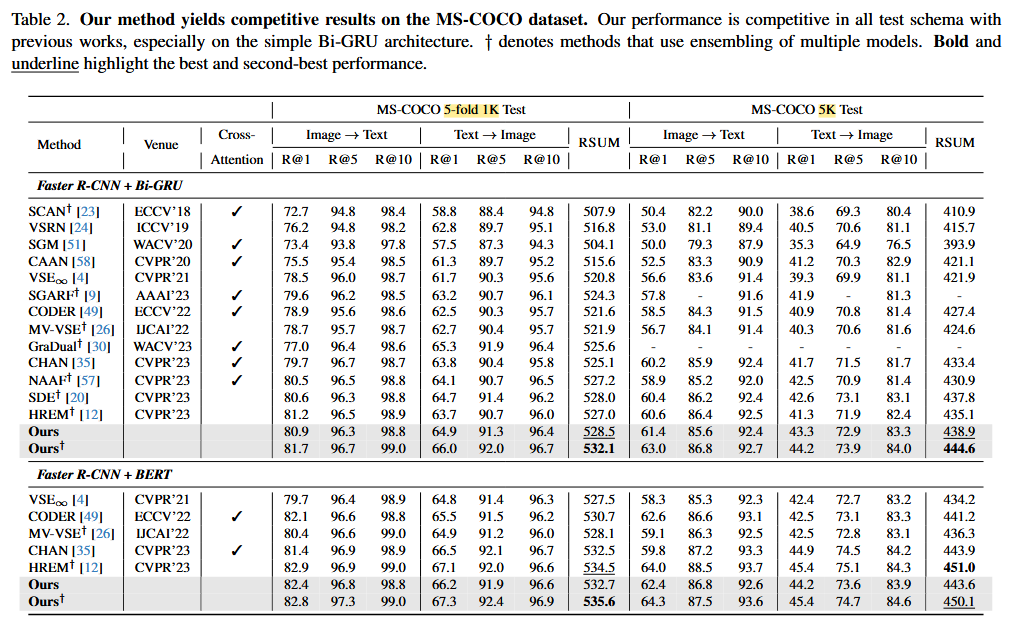
- Flickr30K 및 MS-COCO 데이터셋에서 기존 SOTA 방식을 능가하는 성능 달성.
한계
- Scene graph 품질에 의존적이며, 감탄문같은 명시적이지 않은 문장에서 실패 가능성 존재.
- Image-text, Image-object entity alignment에 더 똑똑한 메커니즘 개발 필요