[ 논문리뷰 ] Cross-Modal Implicit Relation Reasoning and Aligning for Text-to-Image Person Retrieval
2023, Jiang et al.
https://github.com/anosorae/IRRA
1. 선행 연구의 동향 및 한계
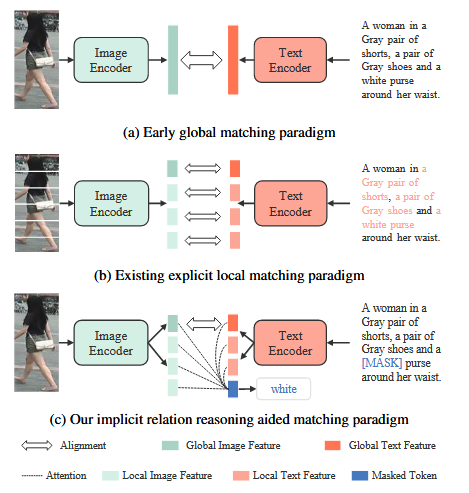
Global Matching 방식
- Cross-modal matching loss functions를 네트워크 끝단에만 적용하여 feature-level 갭을 줄이는 middle-level 층에서 충분한 modality interaction이 부족함.
- 이는 cross-modal interaction이 적어 최적의 feature alignment를 보장하지 못함.
Local Matching 방식
- Body parts와 textual entities간 연관을 짓는 방식으로 비교적 높은 정밀도를 제공.
- 하지만 노이즈와 불확실성 문제, resource-demanding으로 비효율적임.
2. 연구 필요성 혹은 차별성
- 기존 방식의 한계 극복을 위해 IRRA(Cross-modal Implicit Relation Reasoning and Aligning framework) 제안
- 추가적인 supervision 없이 local visual-textual 관계를 학습해 global matching 성능 향상
- Full CLIP 모델을 성공적으로 transfer하고, local relation 학습을 통해 discriminative feature 추출.
3. 연구 질문
- 어떻게 cross-modal interaction을 강화하고 discriminative feature을 효과적으로 추출할 수 있는가?
- Global alignment 성능을 향상하면서 추가적인 supervision 없이 modality간 관계를 학습할 수 있는가?
- CLIP 기반 접근법으로 text-image person retrieval problem에서 SOTA를 달성할 수 있는가?
4. 사용 이론
Implicit Relation Reasoning (IRR)
- Masked Language Model( MLM )을 통해 modality 간 관계 학습
- Self-attention 및 cross-attention 메커니즘으로 이미지와 텍스트 간 관계를 생성
Similarity Distribution Matching (SDM)
- KL divergence으로 image-text representation 간의 distribution 정렬
- Temperature hyperparameter로 matching 쌍간 유사도 강화, non-matching 쌍간 분산 증대
Identity Loss (ID Loss)
- 같은 identiy를 가진 이미지-텍스트를 클러스터링
5. 연구 방법
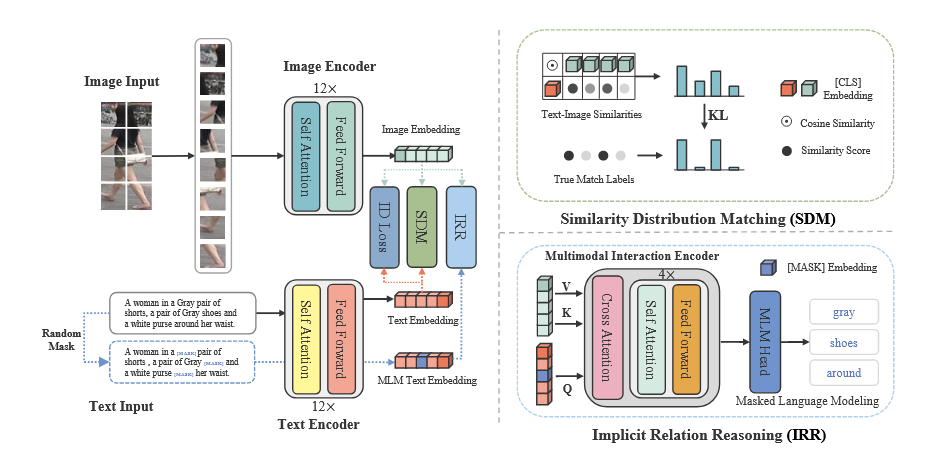
Image Encoder
- CLIP pre-trained ViT 모델 사용
- 이미지를 패칭하고 토큰화한 뒤 L-layer transformer 블록에 입력
- Joint image-text embedding space로 linear projection을 통해 global image representation 생성
Text Encoder
- CLIP text encoder 사용
- BPE로 토큰화된 텍스트를 transformer에 입력하여 masked self-attention으로 correlation 모델링
- Joint image-text embedding space로 linear projection을 통해 global text representation 생성
IRR 모듈( Local Alignment )
- MLM 사용하여 masked textual tokens를 이미지와 다른 텍스트 토큰으로 예측
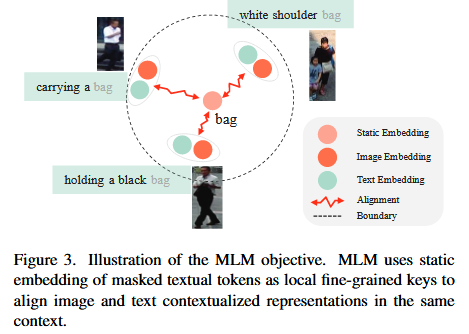
stating embedding( 고정된 임베딩 )을 앵커로 사용해 이를 기준으로 이미지와 텍스트 정렬하고 모든 임베딩이 균형 잡히게 학습.
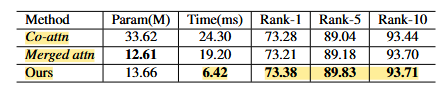
- Multi-head cross-attention(MCA)와 4-layer transformer 블록으로 융합
-
마스킹된 텍스트 토큰 처리
- Text description T의 토큰을 랜덤하게 [MASK]로 마스킹하여 마스킹된 T^를 생성
- 마스킹된 T^는 text transformer에 입력되며, 마지막 hidden state이 multimodal interaction encoder로 전달됨.
-
MCA를 통한 이미지-텍스트 융합
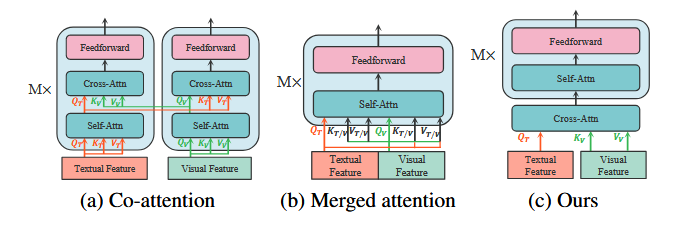
- Masked text representation은 Q, image representation은 K, V로 설정
- MCA와 4-layer Transformer 블록들로 이미지와 텍스트 간의 관계를 학습하고 융합
- MCA의 연산
-
MLP 분류기를 통한 마스크된 단어 예측
- MCA의 출력을 로 나타내며, 이를 MLP분류기에 입력해 마스크된 단어의 예측 점수 계산
- 예측 점수:
-
IRR 손실 함수
- 마스크된 단어 예측의 정확도 높이기 위해 설계된 손실 함수
- 모든 마스크된 단어의 예측 결과를 고려해 평균 손실 계산
- IRR 손실 공식: 정답 단어에 높은 확률 할당, 확률 높을수록 손실 작아짐.
- : 마스크된 토큰 집합의 크기, : 단어장의 크기.
- : 번째 단어가 정답일 때 1, 아닐 때 0인 원-핫 벡터.
- : 모델이 번째 마스크된 단어가 번째 단어일 가능성으로 예측한 점수
SDM 손실( Global Alignment )
- Cosine similarity distribution과 KL divergence로 모델 예측과 정답 분포 간 차이 최소화.
- Bidirectional SDM loss를 통해 양방향 정렬 성능 향상
- : 이미지-텍스트 매칭 확률( 모델이 예측한 값 ), : 이미지-텍스트 매칭의 정답 확률( ground truth )
최종 손실 함수
- : Local alignment 학습
- : Global alignment 학습
- : 같은 그룹을 가까이 모음
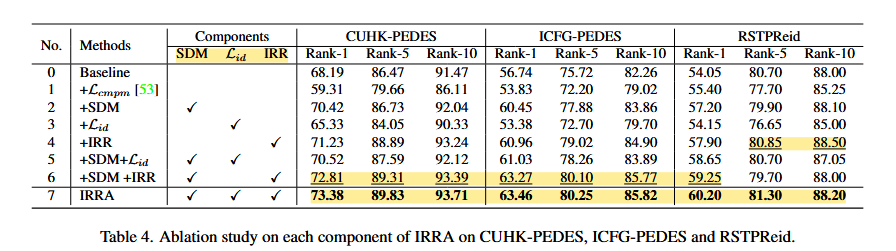
6. 연구 핵심
- IRR(Local) 과 SDM(Global)손실을 결합해 local-global alignment 수행
- Full CLIP 모델 transfer를 강력한 이미지-텍스트 임베딩 학습
- Masked token을 anchor로 사용해 세밀한 관계 학습
7. 연구 의의 및 한계
- 의의
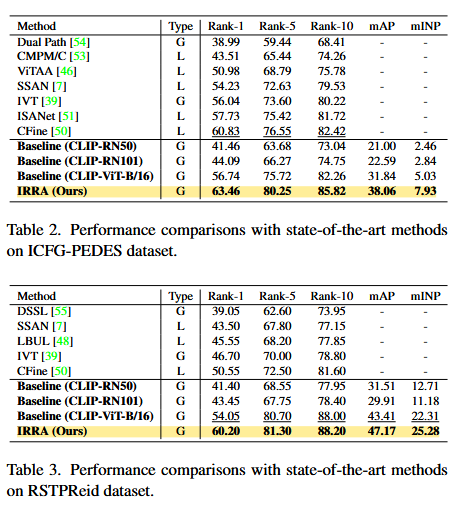
- Text-to-image person retrieval에서 SOTA 달성
- 추가적인 supervision 없이 cross-modal 관계 학습해 효율성 증대
- Local 및 global feature alignment 를 결합해 높은 정밀도 구현
- 한계
Word level에서는 semantic information 효과적으로 습득하나, phrase level에서는 부족( MLM에서 단일 토큰만 마스킹하고 phrase-level 정보 학습하지 않아서 )

Rank-k metrics 사용해 평가. text description query 주어졌을 때 top-k candidate list 중 matching image 있는 확률.

반갑습니다!