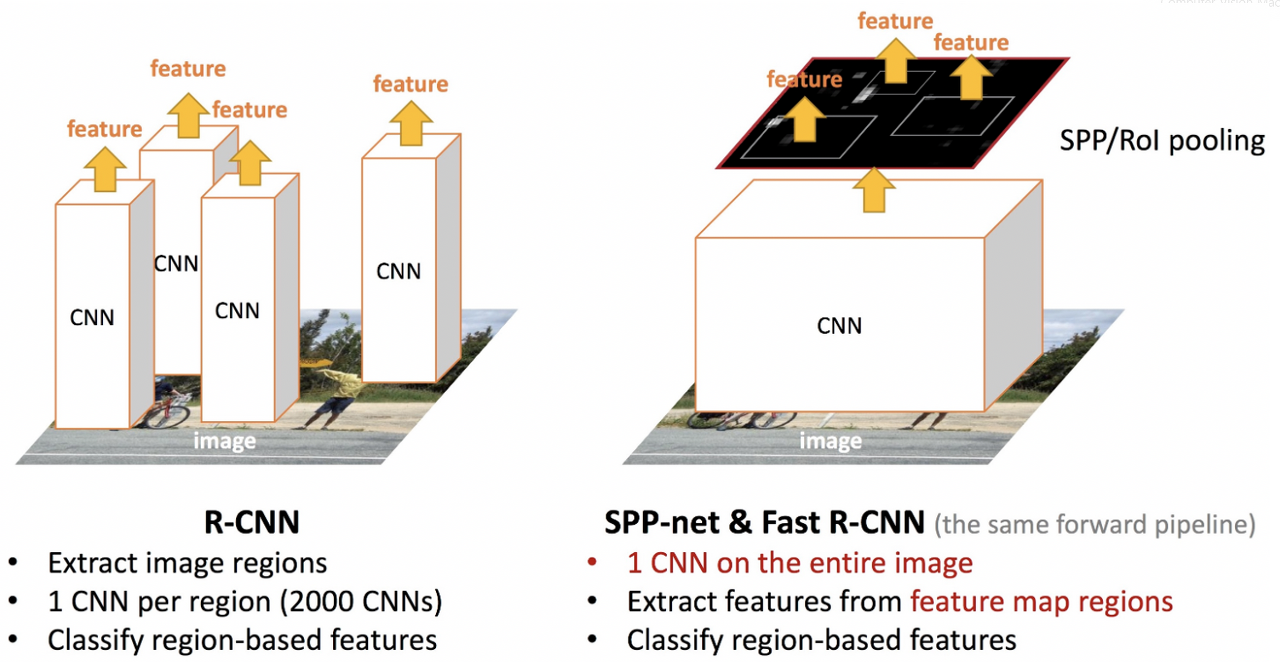
R-CNN & SPPnet의 한계
- 합성곱 신경망의 입력을 위한 고정된 크기를 위해 warping / crop(이미지 크기 조절)을 사용하므로 정보 손실 발생
- 학습 시간이 길며(2천개의 영역) 공간을 많이 차지함
- detection 속도가 느림
-> 이를 보완하기 위해 Fast R-cnn이 등장함
SPPNet 간단한 요약 :
https://velog.io/@suminwooo/SPPNet-%EB%85%BC%EB%AC%B8-%EB%B0%8F-%EC%A0%95%EB%A6%AC
논문 링크 : https://arxiv.org/pdf/1504.08083.pdf
Fast R-CNN 특징
- Higher detection quality (mAP) than R-CNN, SPPnet : 이전(R-CNN, SPPnet)보다 좋은 성능
- Training is single-stage, using a multi-task loss : single-stage로 진행되는 학습
- Training can update all network layers : 전체 네트워크 업데이트 가능
- No disk storage is required for feature caching : 저장 공간 필요X
Fast R-CNN 과정

1. 이미지를 통해 conv feature map을 생성(SPPnet적용방식과 동일)
(Conv Feature Map : Convolution Layer의 입력 데이터를 필터가 순회하며 합성곱을 통해서 만든 출력을 Feature Map 또는 Activation Map이라고 한다.)
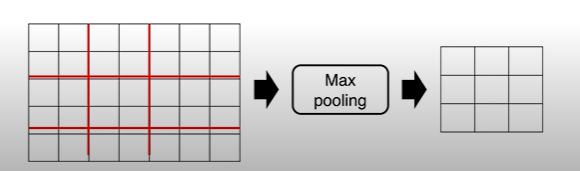
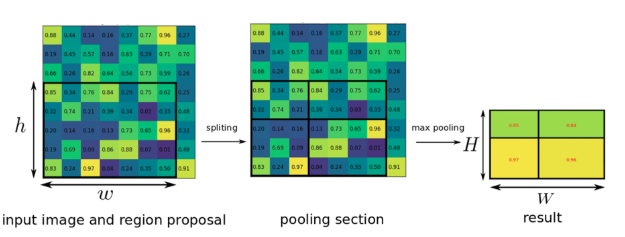
*** 2. 각 object proposal로부터 RoI pooling layer(SPPnet과의 차이점의 차이점)을 통해 고정된 feature vector 생성
- ROI 영역에 해당하는 부분만 max pooling을 통해 feature map으로부터 고정된 길이의 저차원 벡터로 축소
- 각각의 ROI는 (r, c, h, w)의 튜플 형태 (r,c): top-left cornet의 좌표
- hw ROI 사이즈를 HW의 작은 윈도우 사이즈로 나눔 -> h/H * w/W
- SPPnet의 spp layer의 한 pyramid level만을 사용하는 형태와 동일

3. FCN을 통해 object class를 판별/bounding box를 조절
4-1. 하나의 브랜치는 softmax를 통과하여 해당 RoI가 어떤 물체인지 classification을 실시함(더 이상 SVM은 사용되지 않음)
4-2. bouding box regression을 통해서 selective search로 찾은 박스의 위치를 조정
Multi Task Loss

-
classfication Loss에는 Log Loss를 사용
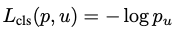
- p : softmax를 통해서 얻어낸 K+1 (K개의 object + 1개의 배경, 아무 물체도 아님을 나타내는 클래스)개의 확률 값
- u : 해당 RoI의 ground truth 라벨 값 -
Bbox Regression Loss에는 Smooth L1 Loss를 사용함
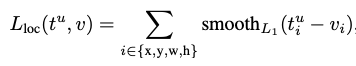
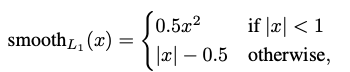
참고 링크 :
1. https://www.youtube.com/watch?v=Jo32zrxr6l8
2. https://nuggy875.tistory.com/33
3. https://yeomko.tistory.com/15

데이터 분석하고 있습니다