
MASK R-CNN
- detect objects + segmentation mask
- Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN(Mask R-CNN은 mask branh와 FPN, ROI alingn만 추가됨)
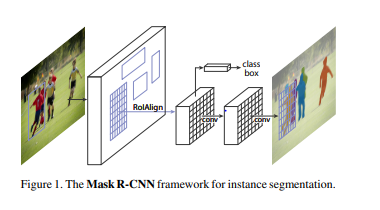
- 이전 방식은 바운딩 박스와 물체 구별만 하였지만, MASK R-CNN은 구별과 동시에 마스크를 생성할 수 있게 됨.
"However, we show that a surprisingly simple, flexible, and fast system can surpass prior state-of-the-art instance segmentation results."
ROI Align
"Mask R-CNN is conceptually simple: Faster R-CNN has two outputs for each candidate object, a class label and a bounding-box offset; to this we add a third branch that outputs the object mask. Mask R-CNN is thus a natural and intuitive idea. But the additional mask output is distinct from the class and box outputs, requiring extraction of much finer spatial layout of an object. Next, we introduce the key elements of Mask R-CNN, including pixel-to-pixel alignment, which is the main missing piece of Fast/Faster R-CNN."
-> fast/faster R-CNN과의 가장 큰 차이점 : ROIAlign
기존의 방식은 object detection을 위한 모델이기에 정확한 위치 정보를 담는 것이 중요하지 않음. 이를 보완하기 위해 ROI Align이 등장함.
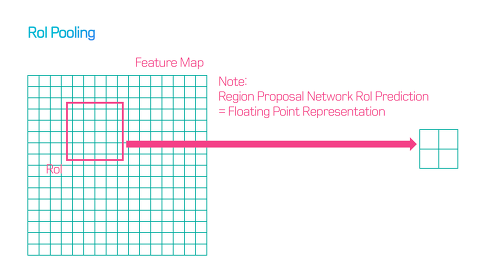
- 기존의 방식
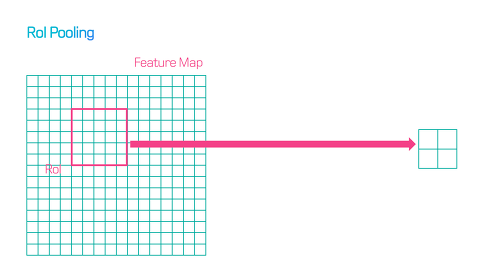
- 변경된 방식

구조

- ResNet-101 : # 추후 정리 예정
- FPN : # 추후 정리 예정
-참고링크 :
1. https://arxiv.org/pdf/1703.06870.pdf
2. http://machinelearningkorea.com/2019/07/18/mask-rcnn-%ED%95%B5%EC%8B%AC%EC%9D%B4%ED%95%B4/
3. https://ganghee-lee.tistory.com/40
4. https://github.com/akTwelve/Mask_RCNN
