
1장 구글 빅쿼리
데이터 처리 아키텍처
-
구글 빅쿼리(Google BigQuery)는 쿼리 엔진이 내장된 서버리스(serverless) 서비스로, 확장성이 높은 데이터 웨어하우스다.
-
내자된 쿼리 엔진은 수 테라바이트의 데이터에 대한 SQL 쿼리를 단 몇 초만에 처리할 뿐 아니라, 수 페타바이트의 데이터는 불과 몇 분이면 처리한다. 게다가 인프라를 별도로 관리하지 않고도 인덱스를 만들거나 재구성하지 않아도 이런 성능을 얻을 수 있다.
-
두 단계 : 키/값 쌍을 처리해 중간 키/값 쌍을 생성하는 map함수, 동일한 키와 연관된 모든 중간 값을 병합하는 reduce 함수이다.
-
맵리듀스(MapReduce)라고 알려진 이 패러다임은 엄청난 영향력을 갖게 되었고 아파치 하둡(Apache Hadoop)의 발전을 이끌었다.
-
단점 : HDFS에 데이터를 저장하기 위해서는 클러스터가 충분히 커야한다. 그리고 맵리듀스 아키텍처에서는 일반적으로 컴퓨팅 노드가 로컬에 있는 데이터에 접근해야 한다는 점을 간과하는데, 반드시 HDFS는 클러스터의 컴퓨팅 노드에 샤딩(shading)되어야 한다. 게다가 데이터 크기와 분석 요구사항 모두 많이 증가하지만 독립적으로 증가해서 클러스터가 부족하거나 과도하게 프로비저닝 되는 경우가 종종 있다.
** 샤딩(shading) : 샤딩은 "조각내다"라는 뜻으로 데이터베이스 저장기법 중 하나이며, 전체 네트워크를 분할한 뒤 트랜잭션을 영역별로 저장하고 이를 병렬적으로 처리하여 블록체인에 확장성을 부여하는 온체인 솔루션으로 데이터를 샤드라는 단위로 나눠서 저장 및 처리한다.
** 프로비저닝 : 사용자의 요구에 맞게 시스템 자원을 할당, 배치, 배포해 두었다가 필요 시 시스템을 즉시 사용할 수 있는 상태로 미리 준비해 두는 것을 말한다.
- 빅쿼리는 서비리스 서비스이므로 인프라를 관리할 필요 없이 쿼리를 실행 할 수 있다.
- 수 테라바이트나 수 페타바이트에 이르는 데이터를 집계할 때도 서비스가 잘 확장된다. 이 확장성은 서비스가 즉각적으로 수천의 워커(worker)에게 쿼리 처리를 분산하기 때문에 가능하다.
빅쿼리로 작업하기
- SQL:2011
- 각 부서가 빅쿼리에 데이터셋을 저장하고 회사 내 다른 조직, 심지어 파트너 조직과 데이터를 쉽게 공유할 수 있다.
- 빅쿼리에서는 컴퓨팅과 스토리지가 분리되어 있어서 구글 클라우드 스토리지에 현재 저장된 CSV(또는 JSON, 아브로) 파일에 빅쿼리 SQL 쿼리를 실행할 수 있으며, 이 기능을 통합 쿼리(federated query)라고 한다. 이 통합 쿼리를 사용해서 구글 클라우드 스토리지에 저장된 데이터로부터 SQL 쿼리로 데이터를 추출하고 해당 데이터를 변환한 다음, 그 결과를 빅쿼리 테이블로 저장할 수 있다.
- ETL, EL 워크플로우 외에도 빅쿼리는 ELT 워크플로우를 구현할 수 있다.
** ELT 워크플로우 : 원시 데이터를 그대로 추출해 로드한 다음 빅쿼리 뷰로 해당 데이터를 즉시 변환하는 방법이다.
-
빅쿼리와 주로 SQL로 상호작용하고 빅쿼리가 SQL 엔진이라서 태블로, 루커, 구글 데이터 스튜디오같은 다양한 비즈니스 인텔리전스 도구로 빅쿼리에 저장된 데이터를 영향력 있는 분석, 시각화, 보고서로 만들 수 있다.
-
머신러닝 모델 생성과 배치 예측 작업을 지원한다.
-
다양한 유형의 데이터를 저장할 수 있다.(지리 공간 데이터, 계층 데이터 등)
-
배치 데이터와 스트리밍 데이터 수집 모두 지원한다. REST API를 통해 빅쿼리로 직접 데이터를 스트리밍할 수 있다.
-
인프라스트럭처를 직접 구축하지 않아도 되므로 보안을 신경 써야 하는 번거로움도 줄어든다. 빅쿼리의 데이터는 저장 및 전송 시 자동으로 암호화된다.
빅쿼리는 어떻게 만들어졌는가
- 컬럼 스토어를 사용
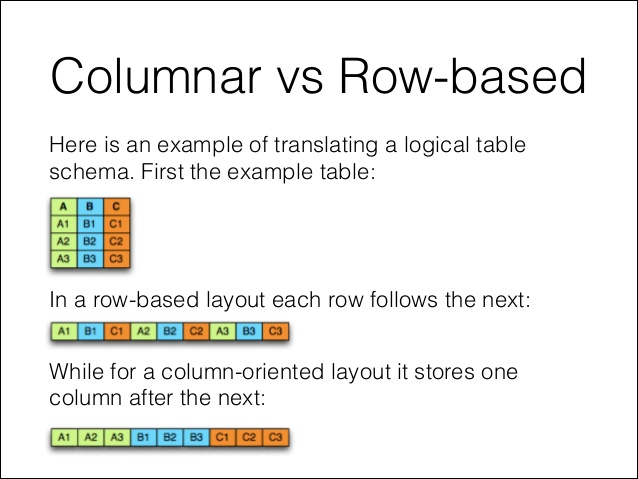
- 분산 컴퓨팅 사용
