
2장 쿼리 필수 요소
- 빅쿼리는 구조화된 데이터와 준구조화(semi-structured)된 데이터(Json 객체 등)를 위한 영구 스토리지를 제공하는 우수한 데이터 웨어하우스다.
- Create
: 새 레코드를 추가한다. SQL의 INSERT문 또는 스트리밍 삽입 API를 활용 - READ **
: 레코드를 검색한다. SQL SELECT 문과 벌크 read API로 구현 - UPDATE
: 기존 레코드를 수정한다. SQL UPDATE 및 MERGE 문으로 구현 - DELETE
: 기존 레코드를 제거한다. SQL DELETE로 구현
- Create
- 쿼리에서 읽는 컬럼이 많을 수록 청구되는 요금은 많아진다.
간단한 쿼리
SELECT로 행 검색하기
-- 간단한 SELECT 문
SELECT
gender, tripduration
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
LIMIT 5;- 쿼리에서 읽는 컬럼이 많을수록 청구되는 요금이 많아진다.
- "-"이 존재할 경우 `을 활용해야 한다.
AS로 컬럼 이름에 별칭 붙이기
-- 컬럼 이름에 별칭 정하기
SELECT
gender, tripduration AS rental_duration
FROM
bigquery-public-data.new_york_citibike.citibike_trips
LIMIT 5;WHERE절에 여러 조건을 사용한 쿼리
SELECT
gender, tripduration
FROM
bigquery-public-data.new_york_citibike.citibike_trips
WHERE tripduration < 600
LIMIT 5;- or, and 사용 가능하다.
- where 절에서는 select 절에서 지정한 별칭을 참조할 수 없다.
SELECT*, EXCEPT, REPLACE
-- EXCEPT 활용
SELECT
* EXCEPT(short_name, last_reported)
FROM
`bigquery-public-data`.new_york_citibike.citibike_stations
WHERE name LIKE '%Riverside%'- 모든 컬럼을 선택하면서 그중 한 컬럼의 값을 변환하고 싶다면 SELECT REPLACE를 사용한다.
SELECT
* REPLACE(num_bikes_available + 5 AS num_bikes_available)
FROM
`bigquery-public-data`.new_york_citibike.citibike_stationsWITH를 사용한 서브쿼리
- 서비쿼리를 사용하면 반복을 줄이고 별칭을 계속 사용할 수 있다.
SELECT * FROM (
SELECT
gender, tripduration / 60 AS minutes
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
)
WHERE minutes < 10
LIMIT 5;- 괄호가 있는 쿼리는 읽기 어려워 이럴 때는 서브 쿼리의 부분을 WITH 절로 감싸는 방법이 더 좋다.
WITH all_trips AS (
SELECT
gender, tripduration / 60 AS minutes
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
)
SELECT * FROM all_trips
WHERE minutes < 10
LIMIT 5;- 빅쿼리에서 WITH 절은 이름이 있는 서브쿼리처럼 작동하며 임시 테이블을 생성하지 않는다. all_trips와 같이 FROM 절에서 사용할 수 있는 객체를 빅쿼리에서는 'from_item'이라 부른다.
- from_item은 테이블은 아니지만 테이블처럼 값을 선택할 수 있는 모든 데이터베이스 객체를 이르는 용어다.
집계
GROUP BY로 집계하기
SELECT
gender, AVG(tripduration/60) AS avg_trip_duration
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
WHERE
tripduration is not NULL
GROUP BY
gender
ORDER BY
avg_trip_duration;HAVING으로 그룹화된 항목 필터링하기
- HAVING 절을 사용하면 그룹화 연산 이후에 필터링을 할 수 있다.
SELECT
gender, AVG(tripduration / 60) AS avg_trip_duration
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
WHERE tripduration IS NOT NULL
GROUP BY
gender
HAVING avg_trip_duration > 14
ORDER BY
avg_trip_duration;배열과 구조체 기초
- ARRAY(아래의 예제 쿼리에서 대괄호 부분)와 UNNEST를 함께 사용하면 쿼리, 함수 및 데이터 타입을 빠르게 실험할 수 있다.
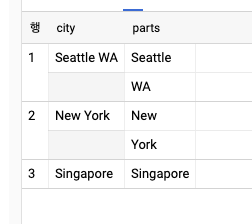
-- sqlit 함수가 작동되는 원리
SELECT
city, SPLIT(city, ' ') AS parts
FROM (
SELECT * FROM UNNEST([
'Seattle WA', 'New York', 'Singapore'
]) AS city
)
- SQL 쿼리에 배열을 하드코딩할 수 있으므로 쿼리를 작성할 때 데이터셋을 찾거나 시간이 오래 걸리는 쿼리를 실행할 필요 없이 배열과 데이터 타입을 사용해 필요한 쿼리를 작성할 수 있다.(비용 무료)
WITH example AS (
SELECT 'Sat' AS day, 1451 AS numrides, 1018 AS oneways
UNION ALL SELECT 'Sun', 2376, 936
UNION ALL SELECT 'Mon', 1476, 736
)
SELECT * FROM example
WHERE numrides < 2000; 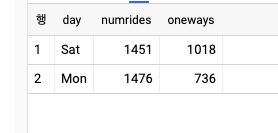
ARRAY_AGG로 배열 만들기
SELECT
gender
, EXTRACT(YEAR from starttime) AS year
, COUNT(*) AS numtrips
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
WHERE gender != 'unknown' and starttime IS NOT NULL
GROUP BY gender, year
HAVING year > 2016- 다음의 결과는 아래와 같다.
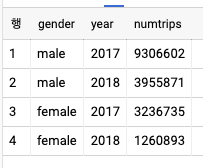
- 여러 해에 걸쳐 성별에 관련된 대여 횟수를 얻으려면 횟수의 배열을 만들어야 한다. ARRAY 타입을 사용해 해당 배열을 SQL로 표시하고 ARRAY_AGG 함수로 배열을 생성하면 된다.
SELECT
gender
, ARRAY_AGG(numtrips order by year) AS numtrips
FROM (
SELECT
gender
, EXTRACT(YEAR FROM starttime) AS year
, COUNT(1) AS numtrips
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
WHERE gender != 'unknown' AND starttime IS NOT NULL
GROUP BY gender, year
HAVING year > 2016
)
GROUP BY gender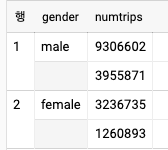
테이블 조인
- 데이터 웨어하우스 스키마는 종종 이벤트를 포함한 기본 '팩트' 테이블과 느리게 변경되는 정보를 포함하는 위성 테이블인 '차원' 테이블에 의존한다.
- 때론 조인을 피하는 것이 더 빠를 수 있지만, 빅쿼리는 거의 모든 크기의 테이블을 효율적으로 조인할 수 있다.
조인의 작동 원리
WITH bicycle_rentals AS (
SELECT
COUNT(starttime) AS num_trips,
EXTRACT(DATE FROM starttime) AS trip_date
FROM `bigquery-public-data`.new_york_citibike.citibike_trips
GROUP BY trip_date
),
rainy_days AS
(
SELECT
date,
(MAX(prcp) > 5) AS rainy
FROM (
SELECT
wx.date AS date,
IF (wx.element = 'PRCP', wx.value/10, NULL) AS prcp
FROM
`bigquery-public-data.ghcn_d.ghcnd_2016` AS wx
WHERE
wx.id = 'USW00094728'
)
GROUP BY
date
)
SELECT
ROUND(AVG(bk.num_trips)) AS num_trips,
wx.rainy
FROM bicycle_rentals AS bk
JOIN rainy_days AS wx
ON wx.date = bk.trip_date
GROUP BY wx.rainy이너 조인(= inner join, join)
- 값을 선택할 수 있는 공통 행의 집합을 생성한다.
크로스 조인(= cross join)
- 조인 조건이 없다. 즉 2개의 from_item의 모든 행이 결합된다. 이 조인은 INNER JOIN의 조인 조건이 항상 참으로 평가되면 얻을 수 있는 조인이다.
SELECT from_item_a.*, from_item_b.*
FROM from_item_a
CROSS JOIN from_item_b
-- 위아래 두개의 두식은 같음
SELECT from_item_a.*, from_item_b.*
FROM for_item_a, for_item_b- 이런 이유로 크로스 조인(CROSS JOIN)은 쉼표 크로스 조인이라고도 한다.
아우터 조인(= outer join)
- 조인 조건이 충족되지 않을 때 발생하는 상황을 제어한다.

데이터 분석하고 있습니다