
9장 머신러닝
회귀 모델 생성하기
피처를 찾ㅣ 위한 데이터 탐색
- 대여소의 영향
SELECT
EXTRACT(dayofweek FROM start_date) AS dayofweek
, AVG(duration) AS duration
FROM `bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY dayofweek- 예측 시점에 알 수 없는 컬럼을 피처로 사용하면 안 된다는 사실을 염두에 둬야 한다.
- 사용할 수 있는 피처는 시간과 인과성에 제약을 받는다.
- 요일
SELECT
EXTRACT(dayofweek FROM start_date) AS dayofweek
, AVG(duration) AS duration
FROM `bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY dayofweek- 주중보다 주말의 대여시간이 더길며, 아침과 이른 오후에 대여 시간이 더 길다. -> 적절한 피처
- 자전거 수
SELECT
bikes_count
, AVG(duration) AS duration
FROM `bigquery-public-data`.london_bicycles.cycle_hire
JOIN `bigquery-public-data`.london_bicycles.cycle_stations
ON cycle_hire.start_station_name = cycle_stations.name
GROUP BY bikes_count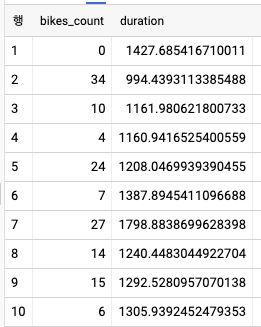
- 특별히 눈에 띄는 문제가 없음에도 데이터가 들쭉날쭉하다. 이는 좋은 피처가 아님을 의미한다.
- 피어슨 상관 계를 계산하면 자전거 수가 좋은 피처가 아님을 정량적으로 증명할 수 있다.
SELECT
CORR(bikes_count, duration) AS corr
FROM `bigquery-public-data`.london_bicycles.cycle_hire
JOIN `bigquery-public-data`.london_bicycles.cycle_stations
ON cycle_hire.start_station_name = cycle_stations.name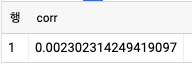
- 피어슨 상관계수는 선형 의존성이 있으면 1.0의 절대값을 가지며, 선형적으로 독립적이면 0.0을 가진다. 따라서 0.0023이라는 결과는 bickes_count와 duration 컬럼 사이의 관계가 서로 독립적임을 뜻한다.
- 피어슨 상관 계수는 선형 의존성만 보기 때문에 변수가 유용한지 확인하기 위한 테스트로는 완벽하다고 할 수 없다. 때로는 피처가 레이블과 비선형 의존성을 가질 수 있다.
- 그럼에도 피어슨 상관계수를 따져보는 것부터 시작하는 것이 좋다. 머신러닝 과학자들은 레이블에 대한 피처의 무작위성을 더 정교한 통계 테스트를 자주 사용하곤 한다.
학습 데이터셋 생성하기
SELECT
duration
, start_station_name
, CAST(EXTRACT(dayofweek FROM start_date) AS STRING) as dayofweek
, CAST(EXTRACT(hour FROM start_date) AS STRING) AS hourofday
FROM `bigquery-public-data`.london_bicycles.cycle_hire
- 피처 컬럼은 숫자(INT64, FLOAT64 등) 또는 범주형(STRING)이어야 한다.
- 피처가 숫자형이지만 범주형으로 처리되어야 할 때는 그 값을 STRING 타입으로 캐스팅해야 한다.
- 그래서 이 쿼리에서는 1에서 7까지의 정수를 가진 dayofweek 컬럼과 0에서 23까지의 정수를 가진 hourofday 컬럼을 문자열로 변환하고 있다.
모델 학습 및 평가
CREATE OR REPLACE MODEL `smart-ruler-315411`.test.bicycle_model
OPTIONS(input_label_cols=['duration'], model_type='linear_reg')
AS
SELECT
duration
, start_station_name
, CAST(EXTRACT(dayofweek FROM start_date) AS STRING) AS dayofweek
, CAST(EXTRACT(hour FROM start_date) AS STRING) AS hourofday
FROM `bigquery-public-data`.london_bicycles.cycle_hire- 레이블 컬럼과 모델 유형은 OPTIONS에 작성한다. 이 예제에서는 레이블은 숫자이므로 이 모델이 해결하려고 하는 문제는 회귀 문제다.
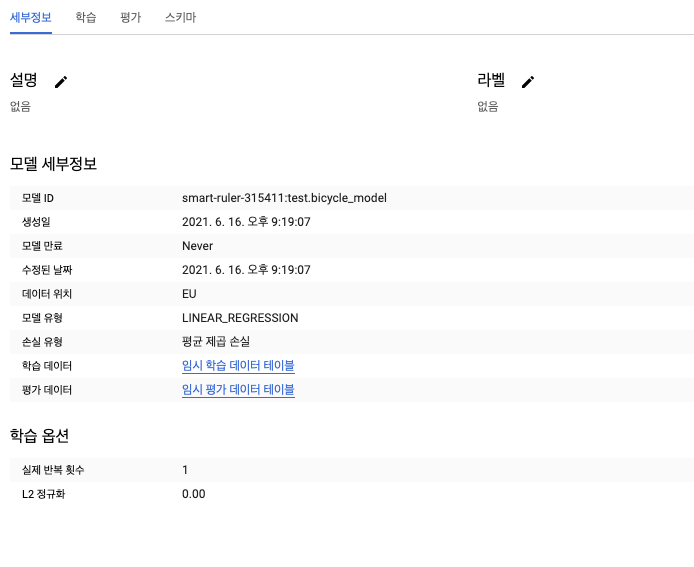
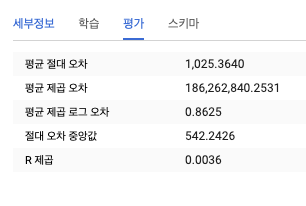
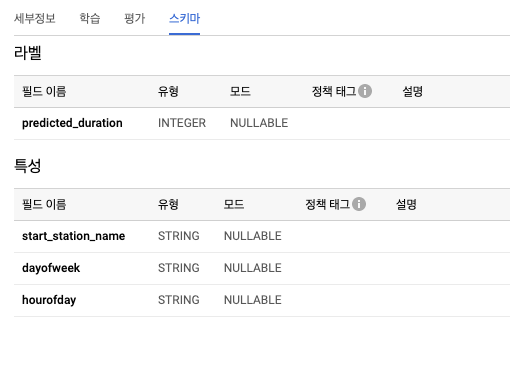
- 모델 평가하기
- 평가 탭을 보는 방법외에도 다음 SQL 쿼리를 실행해서 평가 결과를 볼 수 있다.
SELECT * FROM ML.EVALUATE(MODEL ch09eu.bicycle_model)
- 요일 결합하기
- 이미 확보한 피처는 다른 방법으로 표현할 수도 있다. 예를 들어 요일과 대여 시간 사이의 관계를 조사했을 때 주말이 평일보다 더 길다는 것을 발견했다.
- 그러므로 이 사실을 모델에 적용하기 위해 앞서 정의했던 요일의 기본값을 피처로 취급하는 대신에 여러 개의 dayofweek 값을 weekday범위에 결합할 수 있다.
CREATE OR REPLACE MODEL `smart-ruler-315411`.test.bicycle_model_weekday
OPTIONS(input_label_cols=['duration'], model_type='linear_reg')
AS
SELECT
duration
, start_station_name
, IF(EXTRACT(dayofweek FROM start_date) BETWEEN 2 AND 6, 'weekday', 'weekend') as dayofweek
, CAST(EXTRACT(hour FROM start_date) AS STRING) AS hourofday
FROM `bigquery-public-data`.london_bicycles.cycle_hire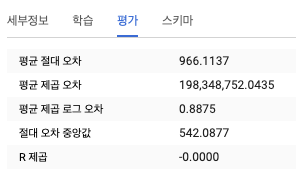
- 시간을 버킷팅하기
- 다시 한 번, hourofday 피처와 대여 시간 간의 관계에 따라 (-inf, 5), [5,10), [10, 17), [17, inf) 등 4개의 구간에 피처를 버킷팅하는 실험을 할 수 있다.
CREATE OR REPLACE MODEL ch09eu.bicycle_model_bucketized
OPTIONS(input_label_cols=['duration'], model_type='linear_reg')
AS
SELECT
duration
, start_station_name
, IF(EXTRACT(dayofweek FROM start_date) BETWEEN 2 AND 6, 'weekday', 'weekend') as dayofweek
, ML.BUCKETIZE(EXTRACT(hour FROM start_date), [5, 10, 17]) AS hourofday
FROM `bigquery-public-data`.london_bicycles.cycle_hire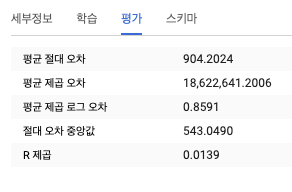
모델로 예측하기
- TRANSFORM 절의 필요성
- TRANSFORM 절은 빅쿼리가 학습 시점에 수행했던 병행 작업을 기억하고 예측 시점에 이를 자동으로 적용시켜준다.
- 시간과 요일을 추출하는 코드를 TRANSFORM 절로 옮기면 클라이언트 코드는 자전거를 대여한 시점을 표현하는 타임스캠프 값만 전달해도 된다.
CREATE OR REPLACE MODEL test.bicycle_model_bucketized
TRANSFORM(* EXCEPT(start_date)
, IF(EXTRACT(dayofweek FROM start_date) BETWEEN 2 AND 6, 'weekday', 'weekend') as dayofweek
, ML.BUCKETIZE(EXTRACT(HOUR FROM start_date), [5, 10, 17]) AS hourofday
)
OPTIONS(input_label_cols=['duration'], model_type='linear_reg')
AS
SELECT
duration
, start_station_name
, start_date
FROM `bigquery-public-data`.london_bicycles.cycle_hire- TRANSFORM 절을 추가하면 모델은 TRANSFORM 절의 출력을 학습하게 된다.
- 이 변형 작업은 모델에 저장되며, 제공된 기본 데이터로부터 모델에 필요한 입력 피처를 만들어낸다.
SELECT * FROM ML.PREDICT(MODEL ch09eu.bicycle_model_bucketized,
(SELECT 'Park Lane , Hyde Park' AS start_station_name
, CURRENT_TIMESTAMP() AS start_date)
)
2. 배치 예측 생성하기
- 배열 생성 함수를 이용하면 모든 대여소에서 다음날 오전 3시 이후의 모든 시간대별 예측 테이블을 생성할 수 있다.
DECLARE tomorrow_3am TIMESTAMP;
SET tomorrow_3am = TIMESTAMP_ADD(
TIMESTAMP(DATE_ADD(CURRENT_DATE(), INTERVAL 1 DAY)),
INTERVAL 3 HOUR);
WITH generated AS (
SELECT
name AS start_station_name
, GENERATE_TIMESTAMP_ARRAY(tomorrow_3am, TIMESTAMP_ADD(tomorrow_3am, INTERVAL 24 HOUR), INTERVAL 1 HOUR) AS dates
FROM
`bigquery-public-data`.london_bicycles.cycle_stations
),
features AS (
SELECT
start_station_name
, start_date
FROM
generated
, UNNEST(dates) AS start_date
)
SELECT * FROM ML.PREDICT(MODEL ch09eu.bicycle_model_bucketized,
(SELECT * FROM features)
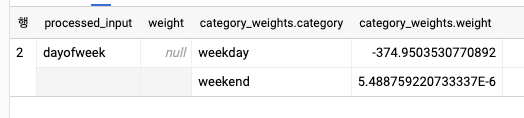
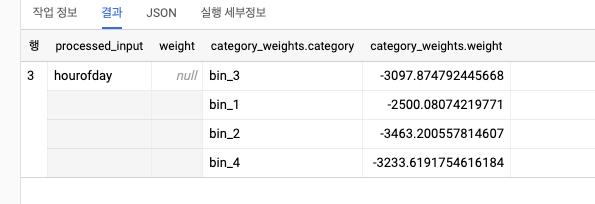
)모델 가중치 검사하기
- 선형 회귀 모델은 입력에 대한 가중치 합으로 예측을 수행한 결과를 출력한다. 다음 쿼리를 사용해 이 가중치는 확인할 수 있다.
SELECT * FROM ML.WEIGHTS(MODEL test.bicycle_model_bucketized)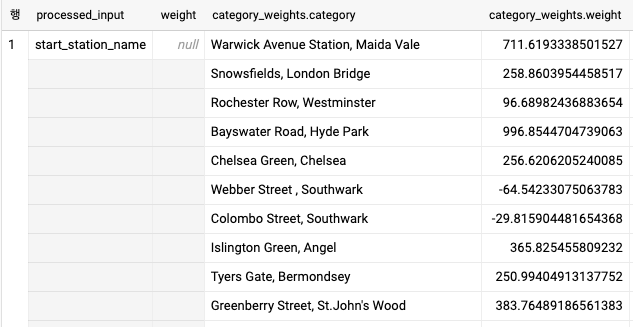

더 복잡한 회귀 모델
-
빅쿼리는 dnn_regressor 및 xgboost 모델도 지원한다.
-
ARIMA 지원한다.
-
이후 9장, 10장 생략

데이터 분석하고 있습니다