
8장 고급 쿼리 (3)
이어서 계속
SQL 이상의 기능
- SQL은 상당히 강력하지만, 적절한 절차 지향 언어로 수행ㅏ는 것이 더 간단한 작업도 있다. 이런 경우에는 자바스크립트 사용자 정의 함수를 사용할 수 있다.
- 많은 데이터 베이스 시스템이 절차적 언어를 SQL 문을 함께 사용하는 방법을 지원한다. 빅쿼리 클라이언트 라이브러리를 사용하면 필요에 따라 SQL 문의 실행을 조율할 수 있지만, 종종 서버에서 전체 작업을 수행해서 장애 처리, 롤백 및 데이터 전송을 단순화하는 것이 더 편리할 수 있다. 이런 기능은 스크립팅 및 저장 프로시저가 제공한다.
자바스크립트 사용자 정의 함수
-
사용자 정의 함수는 가능하면 SQL로 작성하는 것이 바람직이다.
-
빅쿼리는 SQL을 최적화하고 분산 처리해 효율적으로 실행하지만 자바스크립트 사용자 정의 함수는 이런 혜택을 받지 못한다.
-
자바스크립트 사용자 정의 함수에는 코드 크기, 출력의 크기, 한 쿼리에서 사용할 수 있는 자바스크립트 함수 수 등에 제한이 있기 때문이다.
-
자바스크립트 사용자 정의 함수는 SQL로 작성하기 어려운 복잡한 계산을 수행해야 하는 상황에 유용하며, 앞서 언급한 제한 사항에도 불구하고 편리한 대안으로 사용할 수 있다.
CREATE OR REPLACE FUNCTION ch08eu.computePrice(dur INT64)
RETURNS INT64
LANGUAGE js AS """
function factorial(n) {
return (n > 1) ? n * factorial(n - 1) : 1;
}
var nhours = 1 + Math.floor(dur/3600.0);
var f = factorial(nhours);
var discount = 0.8/(1+Math.pow(Math.E, -f));
return 3 + Math.floor(dur * (1-discount) * 0.0023)
""";
SELECT
duration, ch08eu.computePrice(duration) AS price
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT 5- 자바스크립트에서 외부 라이브러리의 함수를 재사용할 수 있다. 이때에는 외부 자바스크립트 패키지의 함수를 내려받아 구글 클라우드 스토리지에 저장하면 해당 함수를 호출 할 수 있다.
CREATE OR REPLACE FUNCTION ch08eu.computePrice(dur INT64)
RETURNS INT64
LANGUAGE js AS """
function factorial(n) {
return (n > 1) ? n * factorial(n - 1) : 1;
}
var nhours = 1 + Math.floor(dur/3600.0);
var f = factorial(nhours);
var discount = 0.8/(1+Math.pow(Math.E, -f));
return 3 + Math.floor(dur * (1-discount) * 0.0023)
""";
SELECT
duration, ch08eu.computePrice(duration) AS price
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT 5스크립팅
- 여러 문장으로 구성된 빅쿼리 스크립트를 작성해 하나의 요청으로 빅쿼리에 보낼 수 있다. 이 스크립트는 결과를 변수에 저장하고 루프를 사용해 동일한 쿼리를 여러 번 실행할 수 있다.
- 연속된 SQL 문
- 스크립트를 작성하는 이유 중 하나는 연속된 쿼리를 차례로 실행하기 위함이다.
- 예를 들어 중간 테이블을 생성하고 조인한 다음 테이블을 삭제한다고 가정했을 때, 스크립트를 사용하면 이런 작동을 실행하는 쿼리를 간단히 작성할 수 있다.
CREATE OR REPLACE TABLE ch08eu.typical_trip AS
SELECT
start_station_name
, end_station_name
, APPROX_QUANTILES(duration, 10)[OFFSET(5)] AS typical_duration
, COUNT(*) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name, end_station_name
;
CREATE OR REPLACE TABLE ch08eu.unusual_days AS
SELECT
EXTRACT (DATE FROM start_date) AS trip_date
, APPROX_QUANTILES(duration / typical_duration, 10)[OFFSET(5)] AS ratio
, COUNT(*) AS num_trips_on_day
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS hire
, ch08eu.typical_trip AS trip
WHERE
hire.start_station_name = trip.start_station_name
AND hire.end_station_name = trip.end_station_name
AND num_trips > 10
GROUP BY trip_date
HAVING num_trips_on_day > 10
ORDER BY ratio DESC
;
DROP TABLE ch08eu.typical_trip;- 스크립트에서 유일하게 특이한 점은 아마도 모든 문장이 세미클론으로 끝난다는 점이다. 이 스크립트를 단일 요청으로 제출할 수 있다.
사실 스크립트가 필요한 상황의 상당 부분은 WITH 절, 조인, 상관된 서브 쿼리 또는 GROUP BY 절을 사용해도 해결할 수 있다. 스크립트를 작성하기 전에 단일 쿼리를 사용해 문제점을 해결할 수 있는지 고려해야한다. 대부분의 경우 단일 쿼리가 훨씬 효율적이다.
- 임시테이블
- 앞서 살펴본 스크립트는 테이블을 생성하고 삭제하는 대신, 임시 테이블을 사용하면 더 간단하게 작성할 수 있다.
CREATE TEMPORARY TABLE typical_trip AS
SELECT
start_station_name
, end_station_name
, APPROX_QUANTILES(duration, 10)[OFFSET(5)] AS typical_duration
, COUNT(*) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name, end_station_name
;
CREATE OR REPLACE TABLE ch08eu.unusual_days AS
SELECT
EXTRACT (DATE FROM start_date) AS trip_date
, APPROX_QUANTILES(duration / typical_duration, 10)[OFFSET(5)] AS ratio
, COUNT(*) AS num_trips_on_day
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS hire
, typical_trip AS trip
WHERE
hire.start_station_name = trip.start_station_name
AND hire.end_station_name = trip.end_station_name
AND num_trips > 10
GROUP BY trip_date
HAVING num_trips_on_day > 10
ORDER BY ratio DESC
;- 임시 테이블은 스크립트가 실행 중인 동안에만 존재하며 스크립트가 완료되면 자동으로 정리된다. 영구 테이블과 달리 임시 테이블은 데이터셋과는 무관하다.
- 간단한 스크립트 구조
-- 변수
DECLARE PATTERN STRING DEFAULT '%Hyde%';
DECLARE stations ARRAY<STRING>;
DECLARE MIN_TRIPS_THRESH INT64 DEFAULT 100;
-- 쿼리 결과를 변수에 저장하는 쿼리
SET stations = (
SELECT
ARRAY_AGG(name)
FROM
`bigquery-public-data`.london_bicycles.cycle_stations
WHERE
name LIKE PATTERN
);
-- 대여 시간이 가장 긴 대여 건의 반납 대여소를 찾는 쿼리
SELECT
start_station_name
, end_station_name
, AVG(duration) AS avg_duration
, COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
, UNNEST(stations) AS station
WHERE
start_station_name = station
GROUP BY start_station_name, end_station_name
HAVING num_trips > MIN_TRIPS_THRESH
ORDER BY avg_duration DESC
LIMIT 5- 이 코드는 SET 구문을 이용해 stations 변수를 배열로 설정하고 PATTERN 변수를 사용해 데이터를 필터링한다. stations 변수는 배열이므로 SELECT 구문에서 ARRAY_AGG 함수를 호출해 모든 행의 name 컬럼 값을 집계한다.
- 반복문
- 스크립팅은 IF 조건 및 다양한 반복문을 통한 제어 흐름도 지원한다. 앞서 예제에서 100개의 대여소 쌍이 아닌 여러개의 값을 루프를 돌릴 수 있다.
-- Variables
DECLARE PATTERN STRING DEFAULT '%Hyde%';
DECLARE MIN_TRIPS_THRESH INT64 DEFAULT 100;
DECLARE stations ARRAY<STRING>;
-- Find stations of interest
SET stations = (
SELECT
ARRAY_AGG(name)
FROM
`bigquery-public-data`.london_bicycles.cycle_stations
WHERE
name LIKE PATTERN
);
-- Loop through a number of thresholds
WHILE MIN_TRIPS_THRESH < 1000 DO
SELECT
start_station_name
, end_station_name
, AVG(duration) AS avg_duration
, COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
, UNNEST(stations) AS station
WHERE
start_station_name = station
GROUP BY start_station_name, end_station_name
HAVING num_trips > MIN_TRIPS_THRESH
ORDER BY avg_duration DESC
LIMIT 5;
SET MIN_TRIPS_THRESH = MIN_TRIPS_THRESH * 2;
END WHILE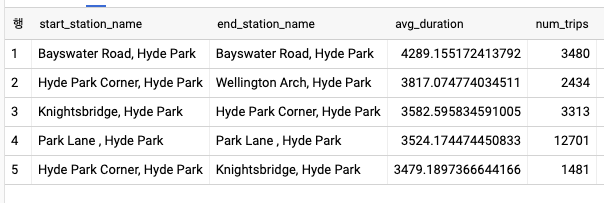
- 조건이 필요 없는 조금 더 간단한 형태의 반복문도 지원한다.
LOOP
IF MIN_TRIPS_THRESH >= 1000 THEN
BREAK;
END IF;
SELECT MIN_TRIPS_THRESH;
SET MIN_TRIPS_THRESH = MIN_TRIPS_THRESH * 2;
END LOOP;- 이 예제에서는 항상 true 조건을 갖는 WHILE 반복과는 유사하게 작동하는 LOOP 구문을 사용했다. 앞서 예제와 같이 BREAK 문을 사용하면 반복문을 중단할 수 있고, CONTINUE을 사용하면 반복문의 나머지 실행을 건더뛸 수 있다.
- 예외
- 예외를 처리하려면 원하는 구문을 BEGIN ... EXCEPTION 블록 안에서 실행하면 된다.
BEGIN
DECLARE stations ARRAY<INT64>;
SET stations = (
SELECT
ARRAY_AGG(CAST(name AS INT64)) names
FROM
`bigquery-public-data`.london_bicycles.cycle_stations
WHERE
name LIKE '%Kings%'
);
EXCEPTION WHEN ERROR THEN
SELECT
@@error.message, -- 작동이 안됨.
@@error.stack-trace;
END;고급 함수
- 고급 함수는 지리 데이터 분석, 통계, 해싱 및 고유 번호 생성 함수 등이 있다.
유용한 통계 함수들
- 빅쿼리는 페타바이트 규모의 데이터셋에 대한 통계 계산을 지원한다. 컬럼에서 평균, 표준 편차 및 백분위 수뿐만 아니라 컬럼 간의 피어슨 상관계수를 계산할 수 있다.
- 통계치
SELECT
MIN(duration) AS min_dur
, MAX(duration) AS max_dur
, COUNT(duration) AS num_dur
, AVG(duration) AS avg_dur
, SUM(duration) AS total_dur
, STDDEV(duration) AS stddev_dur
, VARIANCE(duration) AS variance_dur
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
- 분위수
- 이상치가 큰 컬럼에서는 중앙값을 사용하는 것이 더 안전하게 중심 추세를 구하는 방법이다. 빅쿼리에서는 APPROX_QUANTILES 함수를 사용해 분위수를 구할 수 있다.
SELECT
APPROX_QUANTILES(duration, 3)
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
- 위의 결과는 (-3540, 600), (600, 1080), (1080, 2674020)

데이터 분석하고 있습니다