
3장 데이터 타입, 함수, 연산
- 빅쿼리는 숫자, 문자, 시간, 지리 데이터, 정형 데이터, 반정형 데이터등 다양한 데이터 타입을 지원한다.
숫자형과 함수
SUB("hello", 1, 2)
-- 'he'를 반환하며 3개의 파라미터를 사용하는 스칼라 함수표준 규격 부동소수점 분할
- 분모가 0이거나 결과가 오버플로우면 나누기 연산이 실패한다. 따라서 사전에 값이 0인지 확인해서 나눗셈 연산을 보호하는 것보다 분모가 0일 가능성이 있다면 앞의 예제처럼 특수 함수를 사용하는 것이 좋다.
WITH example AS (
SELECT 'Sat' AS day, 1451 AS numrides, 1018 AS oneways
UNION ALL SELECT 'Sun', 2376, 936
UNION ALL SELECT 'Wed', 0, 0
)
SELECT
*, ROUND(IEEE_DIVIDE(oneways, numrides), 2)
AS frac_oneway FROM example- IEEE_DIVIDE 함수는 IEEE(Institute of Electrical and Elctronics Enginneers)에서 설정한 표준을 따르며 0으로 나누려고 하면 NaN라는 특수 부동소수점을 반환단다. 또한 개선하기 전의 쿼리는 표준 나누기 연산자와 SAFE_DEVICE을 사용한다.
SAFE 함수
- 스칼라 함수에 SAFE 접두사를 사용하면 오류를 발생하지 않고 NULL를 사용한다.
SELECT SAFE.LOG(10, -3), LOG(10, 3)- SAFE 접두사는 수학 함수, 문자열 함수 및 시간 함수에 사용할 수 있다.
- 그러나 SAFE 접두사는 스칼라 함수에만 사용할 수 있으며, 집계 함수, 분석 함수 또는 사용자 정의 함수에는 사용할 수 없다.
불(BOOL) 다루기
조건식
- 불리언이 WHERE 절에서만 유용한 것이 아니다. SELECT에서 조건식을 사용하면 쿼리를 단순화 할 수 있다.
WITH catalog AS (
SELECT 30.0 AS costPrice, 0.15 AS markup, 0.1 AS taxRate
UNION ALL SELECT NULL, 0.21, 0.15
UNION ALL SELECT 30.0, NULL, 0.09
UNION ALL SELECT 30.0, 0.30, NULL
UNION ALL SELECT 30.0, NULL, NULL
)
SELECT
*, ROUND(
costPrice *
IF(markup IS NULL, 1.05, 1+markup) *
IF(taxRate IS NULL, 1.10, 1+taxRate)
, 2) AS salesPrice
FROM catalog;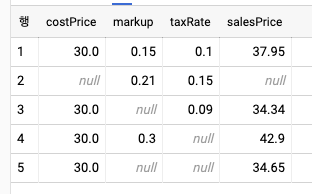
COALESCE로 NULL 값을 깨끗하게 처리하기
- COALESCE 함수를 사용하면 NULL이 아닌 값을 얻을 때까지 표현식을 계속 평가할 수 있어 편리하다.
WITH catalog AS (
SELECT 30.0 AS costPrice, 0.15 AS markup, 0.1 AS taxRate
UNION ALL SELECT NULL, 0.21, 0.15
UNION ALL SELECT 30.0, NULL, 0.09
UNION ALL SELECT 30.0, 0.30, NULL
UNION ALL SELECT 30.0, NULL, NULL
)
SELECT
*, ROUND(COALESCE(
costPrice * (1+markup) * (1+taxrate),
costPrice * 1.05 * (1+taxrate),
costPrice * (1+markup) * 1.10,
NULL
), 2) AS salesPrice
FROM catalog- COALESCE는 가능할 때마다 계산을 단락 평가한다. 즉 NULL이 아닌 결과를 얻은 후에는 식을 평가하지 않는다. 따라서 COALESCE 함수의 마지막 파라미터인 NULL은 필요하지 않지만 그 의도를 더 명확히 표현하기 위한 것이다.
- 아래와 같이 ifnull을 사용하면 단순하게 표현할 수 있다.
WITH catalog AS (
SELECT 30.0 AS costPrice, 0.15 AS markup, 0.1 AS taxRate
UNION ALL SELECT NULL, 0.21, 0.15
UNION ALL SELECT 30.0, NULL, 0.09
UNION ALL SELECT 30.0, 0.30, NULL
UNION ALL SELECT 30.0, NULL, NULL
)
SELECT
*, ROUND(
costPrice *
(1 + IFNULL(markup, 0.05)) *
(1 + IFNULL(taxrate,0.10))
, 2) AS salesPrice
FROM catalog타입 변환과 타입 강제
- 숫자 타입이 아닌 문자열일 경우 SUM이 실행되지 않는다.
- 올바른 값을 얻으러면 집계를 수행하기 전에 컬럼을 INT64로 명시적으로 변환해야 한다.
- 명시적 타입 변환을 캐스팅(casting)이라고 하며 CAST() 함수를 명시적으로 사용해야 한다.
- 캐스팅에 실패하면 빅쿼리는 오류를 반환한다. 오류 대신 NULL을 반환하려면 SAFE_CAST를 사용한다.
-- 오류 발생
SELECT CAST("true" AS bool), CAST("invalid" AS bool)
-- 정상 출력
SELECT CAST("true" AS bool), SAFE_CAST("invalid" AS bool) 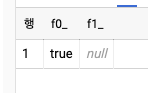
- 암시적 변환을 타입 강제(coercion)라고 하며, 사용하는 데이터 타입과 필요한 데이터 타입이 다르면 자동으로 타입 강제가 이뤄진다.
- 단순히 아래의 예시처럼 모든행이 숫자로 표현하는 문자열로 저장된 경우라면 간단하게 CAST를 사용할 수 있다.
WITH example AS (
SELECT 'John' AS employee, '0' AS hours_worked
UNION ALL SELECT 'Janaki', '35'
UNION ALL SELECT 'Jian', '0'
UNION ALL SELECT 'Jose', '40'
)
SELECT SUM(CAST(hours_worked AS INT64)) FROM example;불리언 변환을 피하기 위해 COUNTIF 사용하기
- SUM, AVG 등은 불리언 값과는 작동하지 않는다. 따라서 다음과 같이 집계를 수행하기 전에 불리언 값을 INT64로 변환해야 한다.
WITH example AS (
SELECT true AS is_vowel, 'a' AS letter, 1 AS position
UNION ALL SELECT false, 'b', 2
UNION ALL SELECT false, 'c', 3
)
SELECT CAST(is_vowel AS INT64) AS num_vowels FROM example- 하지만 가능하면 타입 변환은 피하는 것이 좋다. 이 예제에서는 불리언 값에 IF문을 사용하는것이 더 깔끔하고 더 나아가 COUNTIF를 사용할 수 있다.
-- IF 활용
WITH example AS (
SELECT true AS is_vowel, 'a' AS letter, 1 AS position
UNION ALL SELECT false, 'b', 2
UNION ALL SELECT false, 'c', 3
)
SELECT SUM(IF(is_vowel, 1, 0)) AS num_vowels FROM example;
-- COUNTIF 활용
WITH example AS (
SELECT true AS is_vowel, 'a' AS letter, 1 AS position
UNION ALL SELECT false, 'b', 2
UNION ALL SELECT false, 'c', 3
)
SELECT COUNTIF(is_vowel) AS num_vowels FROM example;문자열 함수
WITH example AS (
SELECT * FROM UNNEST([
'Seattle', 'New York', 'Singapore'
]) AS city
)
SELECT
city
, LENGTH(city) AS len
, LOWER(city) AS lower
, STRPOS(city, 'or') AS orpos
FROM example;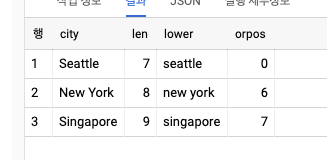
- STRPOS : 문자열의 위치 찾기
- 문자열 조작에는 특히 유용한 두 가지 기능은 SUBSTR 및 CONCAT이다.
- SUBSTR : 부분 문자열을 추출
- CONCAT : 입력값을 연결
WITH example AS (
SELECT 'armin@abc.com' AS email, 'Annapolis,, MD' AS city
UNION ALL SELECT 'boyan@bca.com', 'Boulder, CA'
UNION ALL SELECT 'carrie@cab.com', 'Chicago, IL'
)
SELECT
CONCAT(
SUBSTR(email, 1, STRPOS(email, '@')-1), --username
' from ', city) AS callers
FROM example;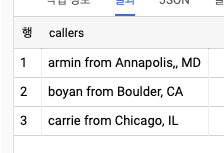
출력 및 파싱
- 문자열을 파싱할 때는 간단히 INT64나 FLOAT64 타입으로 변환하면 되지만, 어떤 값을 원하는 형태의 문자열로 표현하려면 FORMAT 함수를 사용해야 한다.
SELECT
CAST(42 AS STRING)
, CAST('42' AS INT64)
, FORMAT('%03d', 42)
, FORMAT('%5.3f', 32.45123213)
, FORMAT('%5.3f', 32.4)
, FORMAT('**%s**', 'H')
, FORMAT('%s-%03d', 'Agent', 7);
문자열 조작 함수
- 문자열 조작은 ETL 파이프라인에서 일반적으로 필요하므로, 다음 편의 함수(convenience function)를 기억해두면 유용하다.
SELECT
ENDS_WITH('Hello', 'o') -- true
, ENDS_WITH('Hello', 'h') -- false
, STARTS_WITH('Hello', 'h') -- false
, STARTS_WITH('Hello', 'H') -- true
, STRPOS('Hello', 'e') -- 2
, STRPOS('Hello', 'f') -- 0 for not-found
, SUBSTR('Hello', 2, 4) -- 1-based
, CONCAT('Hello', 'World') -- Hello World- SUBSTR()의 파라미터중 첫번째 파라미터는 시작 위치(파이썬은 0, sql은 1부터 시작)이며, 두번째 파라미터는 하위 문자열에서 원하는 문자수다.
변환 함수
SELECT
LPAD('Hello', 10, '*') -- 왼쪽에 *가 추가된다
, RPAD('Hello', 10, '*') -- 오른쪽에 *가 추가된다
, LPAD('Hello', 10) -- 왼쪽에 공백이 추가된다
, LTRIM(' Hello ') -- 왼쪽의 공백이 제거된다
, RTRIM(' Hello ') -- 오른쪽의 공백이 제거된다
, TRIM (' Hello ') -- 양쪽의 공백이 제거된다
, TRIM ('***Hello***', '*') -- 양쪽의 *이 제거된다
, REVERSE('Hello') -- 문자열이 뒤바뀐다- LPAD : 지정한 길이 만큼 왼쪽부터 특정문자로 채워준다.
- RPAD : 지정한 길이 만큼 오른쪽부터 특정문자로 채워준다.
타임스탬프 다루기
- 타임스탬프는 위치와 관계없이 절대 시점의 시각을 나타낸다.
SELECT t1, t2, TIMESTAMP_DIFF(t1, t2, MICROSECOND)
FROM (SELECT
TIMESTAMP "2021-06-01 21:34:00.00" AS t1,
TIMESTAMP "2021-11-16 13:30:00.00" AS t2
);
Date, Time, DateTime
- 빅쿼리에서는 시간을 나타낼 때는 DATE, TIME, DATETIME의 3가지 타입을 사용할 수 있다.
- DATE : 어떤일이 발생하는 날만 추적하며 정밀도가 그리 많이 필요하지 않은 경우에 유용하다.
- TIME : 어떤 일이 발생한 시각을 나타내며 수학적 연산을 수행해야 할 경우에 유용하다.
- DATETIME : 특정 시간대를 기준으로 렌더링한 TIMESTAMP이므로 이벤트가 발생한 명확한 시간대가 있을때 유용하며 시간대 변환이 필요하지 않다.
SELECT
EXTRACT(DATETIME FROM CURRENT_TIMESTAMP()) AS dt
, CAST(CURRENT_TIMESTAMP() AS TIMESTAMP) AS ts;
- DATETIME의 정규표현에는 날짜 부분과 시간 부분을 구분하는 T 문자가 있고, TIMESTAMP의 표현에는 공백이 사용된다. 또한 TIMESTAMP는 명시적으로 시간대를 포함하고 있는 반면, DATETIME은 시간대가 내포되어 있다.(빅쿼리에서는 상호 교환 사용가능)

데이터 분석하고 있습니다