
7장 성능 및 비용 최적화(2)
이어서 계속
이전쿼리 결과 캐싱하기
-
빅쿼리의 쿼리 결과를 임시 테이블에 자동으로 캐싱한다. 그리고 약 24시간 이내에 같은 쿼리를 제출하면 연산을 수행하지 않고 임시 테이블에서 결과를 제공한다. 캐시된 결과는 매우 빠르고 비용이 발생하지 않는다.
-
주의해야 할 상황
- 쿼리 캐싱은 정확한 문자열 비교를 기반으로 한다. 따라서 공백 하나만 추가해도 캐시를 활용하지 않는다.
- 비결정적 작동(예를 들면 CURRENT_TIMESTAMP 또는 RAND 사용)이 있는 경우, 쿼리가 수행 중인 테이블 또는 뷰가 변경된 경우, 쿼리가 스트리밍 버퍼와 연관된 경우, 쿼리가 DML 문을 사용하는 경우, 쿼리가 외부 데이터 원본에서 실행하는 경우 모두 그 결과를 캐시하지 않는다.
중간 결과 캐싱
- I/O가 증가해서 비용이 증가할 때에는 임시 테이블와 구체화된 뷰를 활용해서 전체적인 성능을 높일 수 있다.
WITH typical_trip AS (
SELECT
start_station_name
, end_station_name
, APPROX_QUANTILES(duration, 10)[OFFSET(5)] AS typical_duration
, COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name, end_station_name
)- WITH 절(공통 테이블 표현식)은 가독성을 향상시키지만 결과가 캐시되지 않으므로 쿼리 속도나 비용면에서 개선되는 부분은 없다.
- 뷰와 서브쿼리에도 마찬가지이다.
- WITH 절, 뷰 또는 하위 쿼리를 자주 사용한다면 잠재적으로 성능을 높이는 방법 중 하나는 쿼리 결과를 테이블(또는 구체화된 뷰)에 저장하는 것이다.
CREATE OR REPLACE TABLE ch07eu.typical_trip AS
SELECT
start_station_name
, end_station_name
, APPROX_QUANTILES(duration, 10)[OFFSET(5)] AS typical_duration
, COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name, end_station_nameBI 엔진으로 쿼리 가속화
- 집계 및 필터가 있는 대시보드와 같이 비즈니스 인텔리전스 설정에서 자주 사용하는 테이블이 있을 때 쿼리 속도를 높이는 한 가지 방법은 BI 엔진을 사용하는 것이다.
- BI 엔진은 관련 데이터(테이블의 실제 컬럼 또는 쿼리 결과)를 메모리에 자동으로 저장하며 대부분 메모리 상에 저장한 데이터로 작업하도록 튜닝된 특수 쿼리 프로세서를 사용한다.
- BI 엔진은 구글 데이터 스튜디오와 같은 대시보드 도구에서 사용하는 테이블을 위해 주로 사용한다.
- BI 엔진에 메모리를 할당하면 빅쿼리 백엔드에 의존하는 대시보드의 반응 속도를 훨씬 더 높일 수 있다.
효율적으로 조인하기
- 두 테이블을 조인하려면 데이터 조정이 필요하며 슬롯 간의 통신 대역폭에 의해 부과되는 제한이 따른다. 따라서 가능하다면 조인을 피하거나 조인되는 데이터의 양을 줄여야 한다.
- 비정규화
- 읽기 성능을 향상시키고 조인을 피하는 한 가지 방법은 저장의 효율성을 포기하고 불필요한 데이터를 저장하는 것이다. 이것을 비정규화(denormalization)라고 한다.
- 이작업은 미리 조인을 한 테이블을 저장하는 것인데 연산 비용이 높은 조인 대신 더 많은 스토리지를 사용하며 더 많은 데이터를 읽는 트레이드오프를 감수한 것이다.
- 물론 디스크에서 더많은 데이터를 읽는 비용이 조인 비용보다 클수도 있으므로 비정규화가 성능 이점을 줄 수 있는지 반드시 측정해야 한다.
- 큰 테이블의 셀프 조인 피하기
- 셀프 조인은 같은 테이블을 조인하는 것이다.
- 빅쿼리는 셀프 조인을 지원하지만, 셀프 조인하는 테이블이 매우 크면 성능 저하를 초래할 수 있다.
- 집계, 윈도우 함수 등의 SQL 기능을 활용하면 셀프 조인을 피할 수 있는 경우가 많다.
-- 셀프 조인을 사용해 미국 전체의 남녀 아기 모두에게 많이 지어진 이름을 구하는 쿼리
WITH male_babies AS (
SELECT
name
, number AS num_babies
FROM `bigquery-public-data`.usa_names.usa_1910_current
WHERE gender = 'M'
),
female_babies AS (
SELECT
name
, number AS num_babies
FROM `bigquery-public-data`.usa_names.usa_1910_current
WHERE gender = 'F'
),
both_genders AS (
SELECT
name
, SUM(m.num_babies) + SUM(f.num_babies) AS num_babies
, SUM(m.num_babies) / (SUM(m.num_babies) + SUM(f.num_babies)) AS frac_male
FROM male_babies AS m
JOIN female_babies AS f
USING (name)
GROUP BY name
)
SELECT * FROM both_genders
WHERE frac_male BETWEEN 0.3 AND 0.7
ORDER BY num_babies DESC
LIMIT 5
-- 이는 실제 결과와 다르다. 아래의 코드는 테이블을 한 번만 읽고 셀프 조인을 수행하지 않는다.
-- 또한 속도도 2초밖에 걸리지 않았다.
WITH all_babies AS (
SELECT
name
, SUM(IF(gender = 'M', number, 0)) AS male_babies
, SUM(IF(gender = 'F', number, 0)) AS female_babies
FROM `bigquery-public-data.usa_names.usa_1910_current`
GROUP BY name
),
both_genders AS (
SELECT
name
, (male_babies + female_babies) AS num_babies
, SAFE_DIVIDE(male_babies, male_babies + female_babies) AS frac_male
FROM all_babies
WHERE male_babies > 0 AND female_babies > 0
)
SELECT * FROM both_genders
WHERE frac_male BETWEEN 0.3 and 0.7
ORDER BY num_babies DESC
limit 5- 조인할 데이터 줄이기
- 이름과 성별을 기준으로 데이터를 먼저 그룹화해서 조인할 데이터의 양을 줄이면 앞서 살펴본 쿼리를 효율적으로 조인을 수행하도록 수정할 수 있다.
- 데이터를 미리 그룹화하면 쿼리가 조인을 수행하기 전에 데이터를 잘라내는 역할을 한다. 따라서 셔플링 및 기타 복잡한 작업이 훨씬 작은 데이터에서만 실행되어 효율적이다.
with all_names AS (
SELECT name, gender, SUM(number) AS num_babies
FROM `bigquery-public-data`.usa_names.usa_1910_current
GROUP BY name, gender
),
male_names AS (
SELECT name, num_babies
FROM all_names
WHERE gender = 'M'
),
female_names AS (
SELECT name, num_babies
FROM all_names
WHERE gender = 'F'
),
ratio AS (
SELECT
name
, (f.num_babies + m.num_babies) AS num_babies
, m.num_babies / (f.num_babies + m.num_babies) AS frac_male
FROM male_names AS m
JOIN female_names AS f
USING (name)
)
SELECT * from ratio
WHERE frac_male BETWEEN 0.3 and 0.7
ORDER BY num_babies DESC
LIMIT 5- 셀프 조인 대신 윈도우 함수 사용하기
- 윈도우 함수 : 행과 행간의 관계를 쉽게 정의하기 위해 만든 함수이며 이를 활용하면 복잡한 프로그램을 하나의 SQL 문장으로 쉽게 해결할 수 있다.
- 반납한 자전거가 다시 대여되기까지의 시간을 찾는 문제는 행간의 종속 관계에 대한 예제이다. 같은 테이블을 조인해서 어떤 대여 기록의 end_date 컬럼과 그다음 대여 기록의 start_date 컬럼 값의 차이를 계산하는 방법이 유일한 방법으로 생각할 수 있다. 그러나 아래와 같이 윈도우 함수를 사용하면 셀프 조인을 수행할 필요가 없다.
WITH unused AS (
SELECT
bike_id
, start_station_name
, start_date
, end_date
, TIMESTAMP_DIFF(start_date, LAG(end_date) OVER (PARTITION BY bike_id ORDER BY start_date), SECOND) AS time_at_station
FROM `bigquery-public-data`.london_bicycles.cycle_hire
)
SELECT
start_station_name
, AVG(time_at_station) AS unused_seconds
FROM unused
GROUP BY start_station_name
ORDER BY unused_seconds ASC
LIMIT 5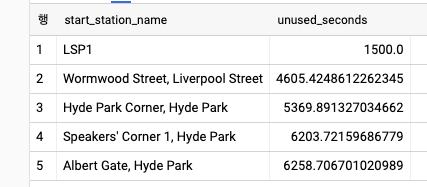
5. 미리 계산된 값과 조인하기
- 종종 작은 테이블에서 함수를 미리 계산한 다음 비싼 연산을 반복하는 대신에 미리 계싼된 값과 조인하는 것이 도움될 수 있다.
워커의 과도한 작업 피하기
1. 큰 정렬 제한하기
2. 데이터 왜도
- ARRAY_AGG 함수나 GROUP BY 절에서 사용하는 키 중 특정 키가 다른 키보다 월등히 많이 나오면 워커의 과부화 문제(이때는 메모리 문제)가 발생할 수 있다.
- 사용자 정의 함수 최적화 하기
근사 집계 함수 사용하기
- 빅쿼리는 빠르고 메모리를 적게 사용하는 근사 집계 함수를 제ㅇ한다.
- 결과에 작은 통계적 불확실성을 허용할 수 있다면 큰 데이터 스트림에 COUNT(DISTINCT ...)를 사용하는 대신 APPROX_COUNT_DISTINCT를 사용해도 된다.
- 근사 카운트
SELECT
COUNT(DISTINCT repo_name) AS num_repos
FROM `bigquery-public-data`.github_repos.commits, UNNEST(repo_name) AS repo_name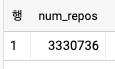
- 이 쿼리는 정확한 결과를 계산하는데 5.5초가 걸린다. 한편, 아래의 코드는 3.3초로 근사치를 출력해 준다.
SELECT
APPROX_COUNT_DISTINCT(repo_name) AS num_repos
FROM `bigquery-public-data`.github_repos.commits, UNNEST(repo_name) AS repo_name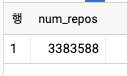
- 하지만 소규모 데이터셋에서는 아무런 이점이 없을 수 있다.
- 근사치 알고리즘은 대형 데이터셋에서만 정확한 알고리즘보다 훨씬 효율적이며 약 1%의 오류는 허용 가능한 사용 사례에서 권장한다.
- 근사 최상위 함수
- 기타 이용 가능한 근사 함수는 백분위 수를 계산하는 APPROX_QUANTILES, 최상위 요소를 찾는
APPROX_TOP_COUNT, 요소의 합계를 기반으로 상위 요소를 계산하는 APPROX_TOP_SUM 등이 있다.
- HLL 함수
- 빅쿼리는 2번의 APPROX_* 함수외에도 HyperLogLog++ 알고리즘을 지원하므로 고윳값을 카운트하는 문제를 세 단계의 별도 작업으로 세분화할 수 있다.
- HLL_COUNT.INIT를 사용해 요소를 추가하여 HLL 스케치라고 하는 셋을 초기화한다.
- HLL_COUNT를 사용해 HLL 스케치의 카디널리티(카운트)를 찾는다.
- HLL_COUNT.MERGE_PARTIAL을 사용해 2개의 HLL 스케치를 단일 스케치로 병합한다.
WITH sketch AS (
SELECT
HLL_COUNT.INIT(start_station_name) AS hll_start
, HLL_COUNT.INIT(end_station_name) AS hll_end
FROM `bigquery-public-data`.london_bicycles.cycle_hire
)
SELECT
HLL_COUNT.MERGE(hll_start) AS distinct_start
, HLL_COUNT.MERGE(hll_end) AS distinct_end
, HLL_COUNT.MERGE(hll_both) AS distinct_station
FROM sketch, UNNEST([hll_start, hll_end]) AS hll_both;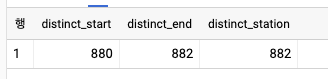
- 위의 식은 APPROX_COUNT_DISTINCT를 직접 사용할 수 있다.
SELECT
APPROX_COUNT_DISTINCT(start_station_name) AS distinct_start
, APPROX_COUNT_DISTINCT(end_station_name) AS distinct_end
, APPROX_COUNT_DISTINCT(both_stations) AS distinct_station
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
, UNNEST([start_station_name, end_station_name]) AS both_stations- 이 쿼리는 같은 결과를 반환하지만 읽고 이해하기는 더 쉽다. 그러므로 APPROX_ 류의 함수를 사용하는 것이 좋다.
- HLL 함수를 사용하는 한 가지 이유는 수동 집계를 사용하거나 특정 컬림이 스토리지를 사용하는 것을 방지해야 하기 때문이다.
뒤에서 이어짐

데이터 분석하고 있습니다